《ORANGE’S:一个操作系统的实现》读书笔记(三十五)内存管理(三)
内存管理到目前为止实现了fork()、exit()和wait(),而我们的目标是实现一个可以执行命令的shell,可无论Init进程fork出多少进程,它也都只是Init而已。所以我们还需要一个系统调用,它就是exec(),这篇文章就来记录exec()的实现。
目录
exec
认识exec
exec的语义很简单,它将当前的进程映像替换成另一个。也就是说,我们可以从硬盘上读取另一个可执行的文件,用它替换掉刚刚被fork出来的子进程,于是被替换的子进程摇身一变,就成了彻头彻尾的新鲜进程了。
以shell中常见的echo命令为例。我们输入“echo hello world”,shell就会fork出一个子进程A,这时A跟shell一模一样,fork结束后父进程和子进程分别判断自己的fork()返回值,如果是0则表明当前进程为子进程A,这时A马上执行一个exec(),于是进程A的内存映像被echo替换,它就变成echo了。这一过程可用如下代码表示。
代码 kernel/main.c,exec()的执行过程,
void Init()
{
...
int pid = fork();
if (pid != 0) { /* parent process */
printf("parent is running, child pid:%d\n", pid);
int s;
int child = wait(&s);
printf("child (%d) exited with status: %d.\n", child, s);
} else { /* child process */
execl("/echo", "echo", "hello", "world", 0);
}
...
}上述代码中用到的execl()是exec的一种形式,我们下文会进行说明。无论如何,这一过程看上去很简单,但是我们面临两个问题,一是要实现exec(),二是我们还没有一个可执行的程序echo呢。在这两个问题中,要顺利执行exec()依赖于可执行程序的存在。所以我们先需要写一个echo,下面就来做这项工作。
为自己的操作系统编写应用程序
echo将以操作系统中普通应用程序的身份出现,它跟操作系统的接口是系统调用。其实本质上,一个应用程序只能调用两种东西:属于自己的函数,以及中断(系统调用其实就是软中断)。可是根据我们写程序的经验,一个应用程序通常都会调用一些现成的函数,很少见写程序时里面满是中断调用的。这是因为编译器偷偷地为我们链接了C运行时库(CRT),库里面有已经编译好的可函数代码。这样两者链接起来,应用程序就能正确运行了。
假如我们要写一个echo,最笨的方法就是将send_recv()、printf()、write()等所有用到的系统调用的代码都复制到源文件中,然后编译一下。这肯定是能成功的,但更优雅的做法是制作一个类似C运行时库的东西。我们把之前已经写好的应用程序可以使用的库函数单独链接成一个文件,每次写应用程序的时候直接链接起来就好了。
到目前为止,可以被用来链接成库的文件及其包含的主要函数有这些(文件位置有改变,以下是改变后文件的存放位置):
- 两个真正的系统调用:sendrec和printx
- lib/syscall.asm
- 字符串操作:memcpy、memset、strcpy、strlen
- lib/string.asm
- FS的接口
- lib/open.c
- lib/read.c
- lib/write.c
- lib/close.c
- lib/unlink.c
- MM的接口
- lib/fork.c
- lib/exit.c
- lib/wait.c
- SYS的接口
- lib/getpid.c
- 其它
- lib/misc.c(send_recv()函数被移动到该文件中)
- lib/vsprintf.c
- lib/printf.c
我们就把这些函数单独链接成一个库,把它起名为orangescrt.a(也可以命名为其它名字),表明这是我们的C运行时库。做这样一个库的方法非常简单:
ar rcs lib/orangescrt.a lib/syscall.o lib/printf.o lib/vsprintf.o \
lib/string.o lib/misc.o lib/open.o lib/read.o lib/write.o lib/close.o \
lib/unlink.o lib/getpid.o lib/fork.o lib/exit.o lib/wait.o有了库,我们就可以放心地写一个应用程序了,先写一个最简单的echo,代码如下所示。
代码 command/echo.c。
#include "stdio.h"
int main(int argc, char * argv[])
{
int i;
int num = argc;
char **t = argv;
for (i = 1; i < num; i++) {
printf("%s%s", (i == 1 ? "" : " "), t[i]);
}
printf("\n");
return 0;
}没有考虑任何异常情况,这个程序写得极为简单。我们对它进行编译链接:
gcc -I ../include/ -m32 -c -fno-builtin -o echo.o echo.c
ld -m elf_i386 -s -Ttext 0x30400 -o echo echo.o ../lib/orangescrt.a输入命令后,你会发现,编译没有问题,但是链接出现了问题(如下所示):
ld: warning: cannot find entry symbol _start; defaulting to 00030400这个问题是说找不到符号 _start。你可能想起来了,链接器需要找到 _start 作为入口,没关系,我们马上写一个,代码如下所示。
代码 command/start.asm。
extern main
extern exit
bits 32
[section .text]
global _start
_start:
push eax
push ecx
call main
; need not clean up the stack here
push eax
call exit
hlt ; should never arrive here千万不要小看_start,虽然只有寥寥几行,但它肩负三项使命:
- 为main()函数准备参数:argc和argv
- 调用main()
- 将main()函数的返回值通过exit()传递给父进程
怎么样?了不起吧,五行代码就做三件事情。之所以小小的start.asm要肩负如此多且重大的使命,原因就在于main()函数本质上只不过是个普通函数,在编译器的眼里,它跟其它任何函数没什么两样。既然是个普通函数,那么自然需要别人为它准备参数,调用它,以及做清理工作。这个角色便是由_start来扮演了。
好了,下面再来链接一下,这次别忘了加上start.o:
gcc -I ../include/ -m32 -c -fno-builtin -o echo.o echo.c
nasm -f elf -o start.o start.asm
ld -m elf_i386 -s -Ttext 0x30400 -o echo echo.o start.o ../lib/orangescrt.a成功了!我们有了自己的应用程序!可是高兴之后,又一个问题摆在面前:如何将这个程序放进我们的操作系统中呢?
“安装”应用程序
我们还记得,在FS进程启动时,会调用mkfs()创建一个简单的文件系统,里面创建了四个特殊文件:“.”以及“dev_tty[012]”。既然可以创建特殊文件,那么普通文件也是可以创建的,所以我们完全可以在mkfs()中多加几行代码,创建一个普通文件,然后在Linux中用dd命令将文件内容写入磁盘映像文件,一切就大功告成了。
不过这样一来有个明显的缺点,就是以后我们每写一个程序,就得改造mkfs(),很费事,而且容易出错。所以我们可以将这个方法稍作改进,将所有的应用程序文件打成一个tar包,做成一个文件,然后放进去,在操作系统启动时将这个包解开,问题就解决了。这个改进方法需要我们额外付出的努力,就是需要写一小段程序来解开tar包。
总结一下,要想“安装”一些应用程序到我们的文件系统中,需要做如下工作:
- 编写应用程序,并编译链接。
- 将链接好的应用程序打成一个tar包:inst.tar。
- 将inst.tar用工具dd写入磁盘(映像)的某段特定扇区(假设这一段的首扇区的扇区号为X)。
- 启动系统,这时mkfs()会在文件系统中建立一个新文件cmd.tar,它的inode中的i_start_sect成员会被设为X。
- 在某个进程中——比如Init——将cmd.tar解包,将其中包含的文件存入文件系统。
这个方法算不上好,如果可以通过软盘或光盘来安装应用程序肯定更好,但那需要写相应的驱动程序,你也看到了,我们现在非常想在我们的操作系统中使用自己编写的应用程序,所以使用这个空降兵硬塞的方法来“安装”应用程序。其实这个方法也没有那么差,我们也可以学习一下如何解开tar包。
我们首先来改造mkfs(),在其中增加一个文件,代码如下所示。
代码 fs/main.c,在mkfs()中增加文件cmd.tar。
/**
* <Ring 1> Make a available Orange'S FS in the disk. it will
* - Write a super block to sector 1.
* - Create three special files: dev_tty0, dev_tty1, dev_tty2
* - Create a file cmd.tar
* - Create the inode map
* - Create the sector map
* - Create the inodes of the files
* - Create '/' the root directory
*/
PRIVATE void mkfs()
{
...
/* inode map */
memset(fsbuf, 0, SECTOR_SIZE);
for (i = 0; i < (NR_CONSOLES + 3); i++) {
fsbuf[0] |= 1 << i;
}
assert(fsbuf[0] == 0x3F); /* 0011 1111 :
* || ||||
* || |||`--- bit 0 : reserved
* || ||`---- bit 1 : the first inode,
* || || which indicates `/'
* || |`----- bit 2 : /dev_tty0
* || `------ bit 3 : /dev_tty1
* |`-------- bit 4 : /dev_tty2
* `--------- bit 5 : /cmd.tar
*/
WR_SECT(ROOT_DEV, 2);
/* sector map */
...
/* cmd.tar */
int bit_offset = INSTALL_START_SECT - sb.n_1st_sect + 1; /* sect M <-> bit (M - sb.n_1st_sect + 1) */
int bit_off_in_sect = bit_offset % (SECTOR_SIZE * 8);
int bit_left = INSTALL_NR_SECTS;
int cur_sect = bit_offset / (SECTOR_SIZE * 8);
RD_SECT(ROOT_DEV, 2 + sb.nr_imap_sects + cur_sect);
while (bit_left) {
int byte_off = bit_off_in_sect / 8;
/* this line is ineffecient in a loop, but I don't care */
fsbuf[byte_off] |= 1 << (bit_off_in_sect % 8);
bit_left--;
bit_off_in_sect++;
if (bit_off_in_sect == (SECTOR_SIZE * 8)) {
WR_SECT(ROOT_DEV, 2 + sb.nr_imap_sects + cur_sect);
cur_sect++;
RD_SECT(ROOT_DEV, 2 + sb.nr_imap_sects + cur_sect);
bit_off_in_sect = 0;
}
}
WR_SECT(ROOT_DEV, 2 + sb.nr_imap_sects + cur_sect);
/* inodes */
/* inode of '/' */
memset(fsbuf, 0, SECTOR_SIZE);
struct inode * pi = (struct inode*)fsbuf;
pi->i_mode = I_DIRECTORY;
pi->i_size = DIR_ENTRY_SIZE * 5; /* 5 files:
* '.'
* 'dev_tty0', 'dev_tty1', 'dev_tty2',
* 'cmd.tar'
*/
pi->i_start_sect = sb.n_1st_sect;
pi->i_nr_sects = NR_DEFAULT_FILE_SECTS;
...
/* inode of '/cmd.tar' */
pi = (struct inode*)(fsbuf + (INODE_SIZE * (NR_CONSOLES + 1)));
pi->i_mode = I_REGULAR;
pi->i_size = INSTALL_NR_SECTS * SECTOR_SIZE;
pi->i_start_sect = INSTALL_START_SECT;
pi->i_nr_sects = INSTALL_NR_SECTS;
WR_SECT(ROOT_DEV, 2 + sb.nr_imap_sects + sb.nr_smap_sects);
/* '/' */
memset(fsbuf, 0, SECTOR_SIZE);
struct dir_entry * pde = (struct dir_entry *)fsbuf;
pde->inode_nr = 1;
strcpy(pde->name, ".");
/* dir entries of '/dev_tty0~2' */
for (i = 0; i < NR_CONSOLES; i++) {
pde++;
pde->inode_nr = i + 2; /* dev_tty0's inode_nr is 2 */
sprintf(pde->name, "dev_tty%d", i);
}
(++pde)->inode_nr = NR_CONSOLES + 2;
strcpy(pde->name, "cmd.tar");
WR_SECT(ROOT_DEV, sb.n_1st_sect);
}除了写sector-map的一段代码有点丑,其它都还好。注意其中我们引入的两个宏:
代码 include/config.h,两个宏。
/**
* Some sector are reserved for us (the gods of the os) to copy a tar file
* there, which will be extracted and used by the OS.
*/
#define INSTALL_START_SECT 0x8000
#define INSTALL_NR_SECTS 0x800INSTALL_START_SECT便是cmd.tar的首扇区的扇区号,注意它不要越过分区的边界。INSTALL_NR_SECTS这里设置成了0x800,也就是说cmd.tar最多1MB。
好了,下面是时候将应用程序打包并降到磁盘映像了:
打包的命令很简单。我们除了将echo打入包中,还加入了另一个简单的程序pwd(程序代码位于command/pwd.c中,里面只是输出了一个“/”)。之所以又加入一个文件,是因为这样可以更好地理解生成的tar文件结构。
写入磁盘的dd命令稍微复杂一点,其实它是在一个命令中嵌入了其它命令,所以显示很凌乱。其中
egrep -e '^ROOT_BASE' ../boot/include/load.inc | sed -e 's/.*0x//g' | sed -e 's/^M//g'的作用是从load.in中找出ROOT_BASE的定义,并取出其十六进制的值,所以其输出位“6000”(ROOT_BASE需要根据你硬盘映像的划分进行设置,我的是6000)。这是根设备的开始扇区号。其中的
sed -e 's/^M//g'是用来处理Windows文件下行尾的标识。在Windows机器上编译,然后拿到Linux上运行,有一个隐藏问题,就是格式不对,就是文件每一行末尾都有一个 ^M,但是要处理这个 ^M,不能使用键盘直接打印,需要使用 ctrl+v,ctrl+m 打印出来。如果是在Linux环境下进行的编辑,则不用加这个处理。
这一部分:
egrep -e '#define[[:space:]]*INSTALL_START_SECT' ../include/config.h | sed -e 's/.*0x//g' | sed -e 's/^M//g'的作用是从config.h中找到INSTALL_START_SECT的定义,并取出其十六进制值,其输出位“8000”。这是cmd.tar的开始扇区号。
有了这两个值,命令通过工具bc计算cmd.tar的字节偏移:
echo "obase=10;ibase=16;(6000+8000)*200" | bc这是cmd.tar相对于这个磁盘映像的字节偏移。
另外,这一部分:
ls -l inst.tar | awk -F " " '{print $5}'得到的是inst.tar的文件大小(以字节为单位)。
有了这些,我们就可以用dd命令来写入了,所以最终上面那个负载的命令到最后执行的是:
dd if=inst.tar of=../hd.img seek=29360128 bs=1 count=20480 conv=notrunc通过这个复杂的命令行,我们也可以管窥shell的威力——命令可以组合起来,完成复杂功能,一个命令抵得上一个小程序。
好了,材料都已齐备,下面就该开始动手做了。我们改造一下Init,让它可以读取cmd.tar,并且将包解开,代码如下所示。
代码 kernel/main.c,解包。
/**
* @struct posix_tar_header
* Borrowed from GNU 'tar'
*/
struct posix_tar_header
{ /* byte offset */
char name[100]; /* 0 */
char mode[8]; /* 100 */
char uid[8]; /* 108 */
char gid[8]; /* 116 */
char size[12]; /* 124 */
char mtime[12]; /* 136 */
char chksum[8]; /* 148 */
char typeflag; /* 156 */
char linkname[100]; /* 157 */
char magic[6]; /* 257 */
char version[2]; /* 263 */
char uname[32]; /* 265 */
char gname[32]; /* 297 */
char devmajor[8]; /* 329 */
char devminor[8]; /* 337 */
char prefix[155]; /* 345 */
/* 500 */
};
/**
* Extract the tar file and store them.
*
* @param filename The tar file.
*/
void untar(const char * filename)
{
printf("[extract '%s'\n", filename);
int fd = open(filename, O_RDWR);
assert(fd != -1);
char buf[SECTOR_SIZE * 16];
int chunk = sizeof(buf);
while (1) {
read(fd, buf, SECTOR_SIZE);
if (buf[0] == 0) {
break;
}
struct posix_tar_header * phdr = (struct posix_tar_header *)buf;
/* calculate the file size */
char * p = phdr->size;
int f_len = 0;
while (*p) {
f_len = (f_len * 8) + (*p++ - '0'); /* octal */
}
int bytes_left = f_len;
int fdout = open(phdr->name, O_CREAT | O_RDWR);
if (fdout == -1) {
printf(" failed to extract file: %s\n", phdr->name);
printf(" aborted]\n");
return;
}
printf(" %s (%d bytes)\n", phdr->name, f_len);
while (bytes_left) {
int iobytes = min(chunk, bytes_left);
read(fd, buf, ((iobytes - 1) / SECTOR_SIZE + 1) * SECTOR_SIZE);
write(fdout, buf, iobytes);
bytes_left -= iobytes;
}
close(fdout);
}
close(fd);
printf(" done]\n");
}
void Init()
{
int fd_stdin = open("/dev_tty0", O_RDWR);
assert(fd_stdin == 0);
int fd_stdout = open("/dev_tty0", O_RDWR);
assert(fd_stdout == 1);
printf("Init() is running ...\n");
/* extract 'cmd.tar' */
untar("/cmd.tar");
...
}打成tar包的过程,是在每个文件前面加一个512字节的文件头,并把所有文件叠放在一起。所以解包的过程,就是读取文件头,根据文件头里记录的文件大小读出文件,然后是下一个文件头和下一个文件,如此循环。tar文件的文件头定义是从GUN tar的源代码中借过来的,我们只用到了其中两项:name和size。需要注意的是size一项存放的不是个整数,而是个字符串,而且用的是八进制,这需要我们读出来之后转换一下。
好了,我们运行一下,效果如下图所示。
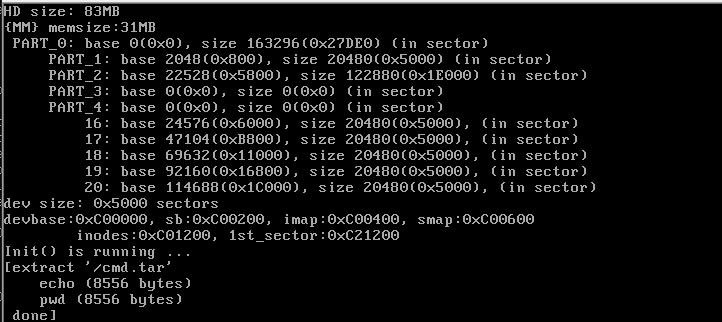
看上去一切良好,通过直接观察磁盘映像,我们可以看到如下内容:

一眼就看到,我们的文件系统多了两个文件。细心又耐心的你可以通过inode等数据结构的值来手工验证文件写入的正确性,此处不再赘述。
实现exec
应用程序已经齐备,终于可以写一个exec()了,我们还是先完成库函数,但这次跟之前不同,因为exec()通常有若干变体,比如你查看exec的manpage,会看到这样的解释:

一阵眩晕,眼花缭乱。不要怕,这些命令是有规律的,其中:
- l?表示函数直接接收来自命令行的参数(可变参数)
- p?表示使用PATH环境变量来寻找要执行的文件
- e?表示指向环境变量的指针直接传递给了子进程
- v?表示以字符指针的方式传递来自命令行的参数
在这里我们不去实现所有的变体,只选其中的execl()和execv()来实现,代码如下所示。
代码 lib/exec.c,exec(),这是新建的文件。
PUBLIC int execl(const char * path, const char * arg, ...)
{
va_list parg = (va_list)(&arg);
char **p = (char**)parg;
return execv(path, p);
}
PUBLIC int execv(const char * path, char * argv[])
{
char ** p = argv;
char arg_stack[PROC_ORIGIN_STACK];
int stack_len = 0;
while (*p++) {
assert(stack_len + 2 * sizeof(char*) < PROC_ORIGIN_STACK);
stack_len += sizeof(char*);
}
*((int*)(&arg_stack[stack_len])) = 0;
stack_len += sizeof(char*);
char ** q = (char**)arg_stack;
for (p = argv; *p != 0; p++) {
*q++ = &arg_stack[stack_len];
assert(stack_len + strlen(*p) + 1 < PROC_ORIGIN_STACK);
strcpy(&arg_stack[stack_len], *p);
stack_len += strlen(*p);
arg_stack[stack_len] = 0;
stack_len++;
}
MESSAGE msg;
msg.type = EXEC;
msg.PATHNAME = (void*)path;
msg.NAME_LEN = strlen(path);
msg.BUF = (void*)arg_stack;
msg.BUF_LEN = stack_len;
send_recv(BOTH, TASK_MM, &msg);
assert(msg.type == SYSCALL_RET);
return msg.RETVAL;
}execl()最终调用execv()。而execv()所做的其实只是一件事,那就是向MM提供最终供调用exec的进程使用的堆栈。我们知道,main()函数接受两个参数:argc和argv,其中的argv看上去像个细绳,实际上另一端栓着一头牛呢。通过一个argv,我们可以得到用户输入的所有参数,我们来看一下这个过程,请看下图。
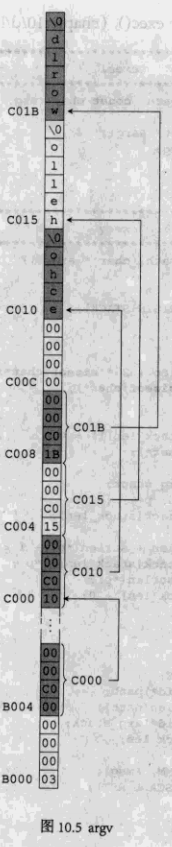
这个图描述的是echo的main()函数执行前堆栈的情形(假设我们输入了命令“echo hello world”)。argv是个指向指针数组的指针,图中argv的值为0xC000,这是个地址。在0xC000处是个指针数组,也就是说,数组内放着另外一些指针。图中可以看到,数组内有0xC010,0xC015和0xC01B三个指针。这三个指针分别指向三个字符串:“echo”、“hello”和“world”。这就是echo的main()函数开始执行时内存应该有的样子。换句话说,在将控制权交给main()之前,MM应该先将内存准备成上图所示的样子。
execv()完成的就是这么一件事情,它先准备好一块内存arg_stack[],然后完成以下工作:
- 遍历其调用者(比如execl())传递给自己的参数,数一数参数的个数
- 将指针数组的末尾赋零
- 遍历所有字符串
- 将字符串复制到arg_stack[]中
- 将每个字符串的地址写入指针数组的正确位置
这项工作做完之后,它将arg_stack[]的首地址以及其中有效内容的长度等内容通过消息发送给MM,MM就可以进行实际的exec操作了。
我们下面在MM中用do_exec()来处理EXEC消息。代码如下所示。
代码 mm/exec.c,do_exec(),这是新建的文件。
/**
* Perform the exec() syscall call.
*
* @return Zero if successfule, otherwise -1.
*/
PUBLIC int do_exec()
{
/* get parameters from the message */
int name_len = mm_msg.NAME_LEN; /* length of filename */
int src = mm_msg.source; /* caller proc nr. */
assert(name_len < MAX_PATH);
char pathname[MAX_PATH];
phys_copy((void*)va2la(TASK_MM, pathname),
(void*)va2la(src, mm_msg.PATHNAME),
name_len);
pathname[name_len] = 0; /* terminate the string */
/* get the file size */
struct stat s;
int ret = stat(pathname, &s);
if (ret != 0) {
printl("{MM} MM::do_exec()::stat() returns error. %s", pathname);
return -1;
}
/* read the file */
int fd = open(pathname, O_RDWR);
if (fd == -1) {
return -1;
}
assert(s.st_size < MMBUF_SIZE);
read(fd, mmbuf, s.st_size);
close(fd);
/* overwrite the current proc image with the new one */
Elf32_Ehdr * elf_hdr = (Elf32_Ehdr*)(mmbuf);
int i;
for (i = 0; i < elf_hdr->e_phnum; i++) {
Elf32_Phdr * prog_hdr = (Elf32_Phdr*)(mmbuf + elf_hdr->e_phoff + (i * elf_hdr->e_phentsize));
if (prog_hdr->p_type == PT_LOAD) {
assert(prog_hdr->p_vaddr + prog_hdr->p_memsz < PROC_IMAGE_SIZE_DEFAULT);
phys_copy((void*)va2la(src, (void*)prog_hdr->p_vaddr),
(void*)va2la(TASK_MM, mmbuf + prog_hdr->p_offset),
prog_hdr->p_filesz);
}
}
/* setup the arg stack */
int orig_stack_len = mm_msg.BUF_LEN;
char stackcopy[PROC_ORIGIN_STACK];
phys_copy((void*)va2la(TASK_MM, stackcopy),
(void*)va2la(src, mm_msg.BUF),
orig_stack_len);
u8 * orig_stack = (u8*)(PROC_IMAGE_SIZE_DEFAULT - PROC_ORIGIN_STACK);
int delta = (int)orig_stack - (int)mm_msg.BUF;
int argc = 0;
if (orig_stack_len) { /* has args */
char ** q = (char**)stackcopy;
for (; *q != 0; q++, argc++) {
*q += delta;
}
}
phys_copy((void*)va2la(src, orig_stack),
(void*)va2la(TASK_MM, stackcopy),
orig_stack_len);
proc_table[src].regs.ecx = argc; /* argc */
proc_table[src].regs.eax = (u32)orig_stack; /* argv */
/* setup eip & esp */
proc_table[src].regs.eip = elf_hdr->e_entry;
proc_table[src].regs.esp = PROC_IMAGE_SIZE_DEFAULT - PROC_ORIGIN_STACK;
strcpy(proc_table[src].p_name, pathname);
return 0;
}代码分为九部分:
- 从消息体中获取各种参数。由于调用者和MM处在不同的地址空间,所以对于文件名这样的一段内存,需要通过获取其物理地址并进行物理地址复制。
- 通过一个新的系统调用stat()获取被执行文件的大小。
- 将被执行文件全部读入MM自己的缓冲区(MM的缓冲区有1MB),我们姑且假设这个空间足够了。等有一天真的不够了,会触发一个assert,到时我们再做打算)。
- 根据ELF文件的程序头(Program Header)信息,将被执行文件的各个段放置到合适的位置。
- 建立参数栈——这个栈在execv()中已经准备好了,但由于内存空间发生了变化,所以里面所有的指针都需要重新定位,这个过程并不难,通过一个delta变量即可完成。
- 为被执行程序的eax和ecx赋值——还记得_start中我们将eax和ecx压栈码?压的就是argv和argc。它们是在这里被赋值的。
- 为程序的eip赋值,这是程序的入口地址,即 _start 处。
- 为程序的esp赋值。注意要闪出刚才我们准备好的堆栈的位置。
- 最后是将进程的名字改成被执行程序的名字。
现在我们在MM中加上EXEC的消息处理。
代码 mm/main.c。
/* <Ring 1> The main loop of TASK MM. */
PUBLIC void task_mm()
{
...
case EXEC:
mm_msg.RETVAL = do_exec();
break;
...
}现在我们来看一下获取文件信息的函数stat()。
代码 lib/stat.c,stat(),这是新建的文件。
/**
* @param path
* @param buf
*
* @return On success, zero is returned. On error, -1 is returned.
*/
PUBLIC int stat(const char *path, struct stat *buf)
{
MESSAGE msg;
msg.type = STAT;
msg.PATHNAME = (void*)path;
msg.BUF = (void*)buf;
msg.NAME_LEN = strlen(path);
send_recv(BOTH, TASK_FS, &msg);
assert(msg.type == SYSCALL_RET);
return msg.RETVAL;
}我们下面在FS中用do_stat()来处理STAT消息。代码如下所示。
代码 fs/misc.c,do_stat()。
/*
* Perform the stat() syscall.
*
* @return On success, zero is returned. On error, -1 is returned.
*/
PUBLIC int do_stat()
{
char pathname[MAX_PATH]; /* parameter from the caller */
char filename[MAX_PATH]; /* directory has been stipped */
/* get parameters from the message */
int name_len = fs_msg.NAME_LEN; /* length of filename */
int src = fs_msg.source; /* caller proc nr. */
assert(name_len < MAX_PATH);
phys_copy((void*)va2la(TASK_FS, pathname), /* to */
(void*)va2la(src, fs_msg.PATHNAME), /* from */
name_len);
pathname[name_len] = 0; /* terminate the string */
int inode_nr = search_file(pathname);
if (inode_nr == INVALID_INODE) { /* file not found */
printl("FS::do_stat():: search_file() returns invalid inode: %s\n", pathname);
return -1;
}
struct inode * pin = 0;
struct inode * dir_inode;
if (strip_path(filename, pathname, &dir_inode) != 0) {
/* theoretically never fail here
* (it would have failed earlier when
* search_file() was called)
*/
assert(0);
}
pin = get_inode(dir_inode->i_dev, inode_nr);
struct stat s; /* the thing requested */
s.st_dev = pin->i_dev;
s.st_ino = pin->i_num;
s.st_mode= pin->i_mode;
s.st_rdev= is_special(pin->i_mode) ? pin->i_start_sect : NO_DEV;
s.st_size= pin->i_size;
put_inode(pin);
phys_copy((void*)va2la(src, fs_msg.BUF), /* to */
(void*)va2la(TASK_FS, &s), /* from */
sizeof(struct stat));
return 0;
}结构体stat的定义在type.h中:
/**
* @struct stat
* @brief File status, returned by syscall stat();
*/
struct stat {
int st_dev; /* major/minor device number */
int st_ino; /* i-node number */
int st_mode; /* file mode, protection bits, etc. */
int st_rdev; /* device ID (if special file) */
int st_size; /* file size */
};最后在FS中加上STAT的消息处理。
代码 fs/main.c,STAT消息处理。
/**
* <Ring 1> The main loop of TASK FS.
*/
PUBLIC void task_fs()
{
...
case STAT:
fs_msg.RETVAL = do_stat();
break;
...
}好了,我们现在可以编译运行了,不忘忘记更改Makefile,运行效果如下图所示。
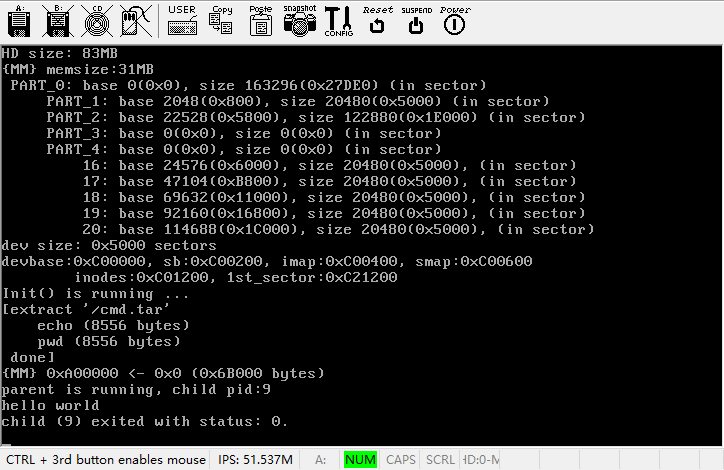
“hello world”出现了!虽然你可能已经写过很多个hello world,但估计没有一次可以和这次相比。这是我们在自己操作系统上用自己的应用程序打印的hello world。
欢迎关注我的公众号

?
公众号中对应文章附有当前文章代码下载说明。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 云端开炉,线上训练,Bert-vits2-v2.2云端线上训练和推理实践(基于GoogleColab)
- 路由时权重和优先级的区别
- Led驱动实验之Led灯初始化
- 鸿蒙开发之崩溃信息收集FaultLogger
- 【ZooKeeper高手实战】ZooKeeper应用背景及分布式架构设计
- 【ArcGIS微课1000例】0087:经纬度格式转换(度分秒转度、度转度分秒)
- 从复杂数据到直观洞察:山海鲸助你一臂之力
- 数据结构图算法
- Verilog HDL数据类型
- React导航守卫(V6路由)