【ZooKeeper高手实战】ZooKeeper应用背景及分布式架构设计
🌈🌈🌈🌈🌈🌈🌈🌈
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术 的推送
发送 资料 可领取 深入理解 Redis 系列文章结合电商场景讲解 Redis 使用场景、中间件系列笔记和编程高频电子书!
文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁
深入理解 ZooKeeper

ZooKeeper 笔记开始整理了,目前已经整理好了 Redis、JVM、RocketMQ 系统性学习的笔记,以及编程常用高频电子书,可以关注公众号【11来了】,发送 资料免费获取!
接下来从 ZooKeeper 运行原理、客户端工具 Curator、分布式架构中应用场景、生产案例几个方面来全面了解 ZooKeeper!关注我,及时收到最新推送!
ZooKeeper 运行原理
ZooKeeper 到底用来做什么?
当需要学习 ZooKeeper 的时候,我们去搜索学习资料的时候,通常会发现对于 ZooKeeper(以后简称 zk) 的介绍是这样的:
ZooKeeper 是一个开源的分布式协调服务,它提供了一个中心化的服务,用于管理和协调分布式应用中的各种配置、信息和事件
那么知道了 zk 是一个 分布式协调的服务,他是怎么协调的呢?
就比如在 Kafka 中,如果 Kafka 的 Broker 挂掉之后,是如何被其他节点感知到的呢?这就是通过 zk 的 监听机制 来实现的,具体怎么实现的会在后边具体讲解
那么一般用 ZooKeeper 去做什么事情呢?
主要就是 4 件事情:分布式锁、元数据管理、分布式协调、Master 选举,接下来逐个细说:
分布式锁:这个就不介绍了,就是多台机器同时访问一个资源时,需要对资源添加分布式锁,其实大多还都是使用的 Redis 的分布式锁,这是由于 zk 架构的原因,导致 zk 的分布式锁性能不如 Redis 的分布式锁元数据管理:zk 的这个功能使用的是最频繁的了,比如 Kafka、Canal,都是分布式架构,在分布式集群运行的时候,就需要有一个地方去集中式的存储和管理整个分布式集群的核心元数据,zk 就作为一个存放元数据的角色存在分布式协调:如果分布式集群中某个节点对 zk 中的数据做了更改,之后 zk 会去通知其他监听这个数据的人,告诉别人这个数据更新了,就利用到了 zk 的监听机制选举 Master:利用 zk 选举 Master 的原理其实和分布式锁是相似的,都是通过顺序临时节点来实现的,具体如何实现,之后也会讲到
zk 在哪些系统中会使用呢?
- 在
分布式 Java 业务系统中需要使用到分布式锁的功能,虽然 zk 提供了分布式锁,但是大多数开发者还是会选择 Redis 的分布式锁,因为由于 zk 架构的原因,导致无法承载太高的写并发 - 在
开源的分布式系统中,如 Dubbo、HBase、HDFS、Kafka、Canal、Solr- Dubbo 中使用 zk 作为注册中心,使用到了 zk 中
元数据存储的功能 - HDFS 中使用 zk 的
Master 选举实现 HA(高可用) 架构 - Kafka 中使用
元数据存储、分布式协调和通知的功能
- Dubbo 中使用 zk 作为注册中心,使用到了 zk 中
为什么需要使用 zk 集群呢?单机版 zk 不可以吗?
单机版 zk 当然不行,可用性很差,如果单机 zk 挂掉了,就会导致所有依赖于 zk 的系统全部瘫痪,所以只能将 zk 集群部署!
在 zk 集群中,可以保证 zk 的高可用性,同时又需要注意在 zk 集群之间如何保证 数据的一致性问题
ZooKeeper 集群图如下:
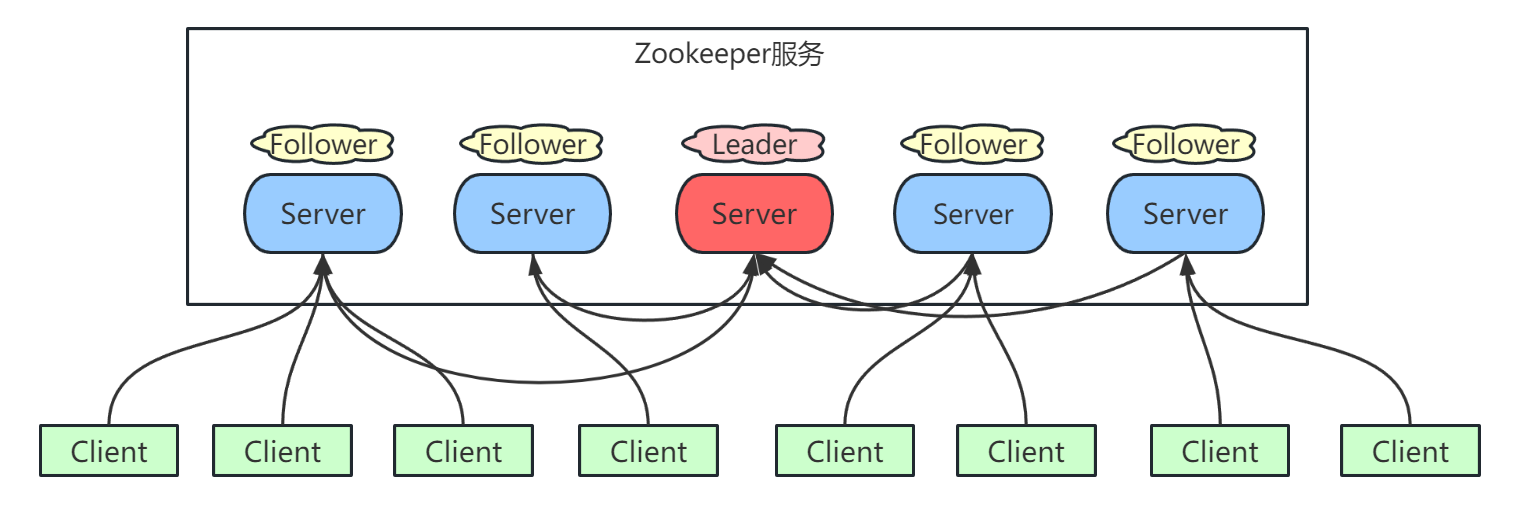
为什么要选择 zk 呢?
zk 发展至今,经过了长达十多年的磨练,功能很全面并且存在的 bug 也很少,因此经常用在工业级的大规模分布式系统中:HDFS、Kafka、HBase 需要使用到 元数据存储 以及 分布式协调 的一些功能,都是引入了 zk!
ZooKeeper 架构设计
zk 应用于分布式架构中所需要具备的特性
- 可以集群部署
- 顺序一致性:需要保证所有请求全部有序
- 原子性:在 zk 中写数据,要么都写成功,要么都失败
- 数据一致性:保证 zk 集群中所有机器的数据一致性
- 高可用:某台机器宕机,保证数据不丢失
- 实时性:一旦数据发生变更,要通知其他节点可以实时感知到
zk 中的架构设计
集群化部署:3 台或 5 台机器组成一个集群,每台机器都在内存中保存了 zk 的全部数据,机器之间互相通信同步数据,客户端连接任何一台机器都可以树形结构的数据模型:znode,在内存中保存顺序写请求:所有写请求都会分配一个在 zk 集群中唯一的递增 id 编号,保证各种客户端发起的写请求都是有顺序的高性能:每台 zk 机器都是在内存中存放数据的,因此 zk 集群的性能是是很高的,如果让 zk 集群部署在高配置物理机上,一个 3 台机器的集群每秒抗下几万请求都是可以的数据一致性:任何一台机器收到了写请求都会将数据同步给其他机器,保证数据的一致性高可用:只要集群中没有超过一半的机器挂掉,都可以保证 zk 集群可用,例如 3 台机器可以挂 1 台、5 台机器可以挂 2 台
在 zk 集群中存在着三种角色:
Leader:Leader 可以读写Follower:Followe 只能读,当 Follower 收到写请求的时候会转发给 Leader,还是通过 Leader 来写Observer:Observer 不能读也不能写,可以通过扩展 Observer 节点来提升 zk 集群的可读性(后边会细说)
客户端是如何和 zk 集群建立连接的呢?
当 zk 集群启动之后,分配好角色,客户端就可以和 zk 建立 TCP 长连接了,也就是建立了一个会话,可以通过心跳感知到会话是否存在,会有一个 sessionTimeout 的超时时间,如果客户端和 zk 之间的连接断开了,在这个时间之内可以重新连接上,就可以继续保持会话,否则,session 就超时了,会话会被关闭
zk 中的数据模型
zk 的核心数据模型就是 znode 树,写入 zk 内存中的就是一个一个的 znode
znode 的节点类型分为 3 种:
持久节点:创建之后一直存在临时节点:只要客户端断开连接,节点就会被删除顺序节点:创建节点时,会添加全局递增的序号,经典应用场景是分布式锁(顺序节点既可以是持久节点也可以是临时节点)
zk 中最核心的一个机制就是 Watcher 监听回调
通过该功能,客户端可以对 znode 进行 watcher 监听,当 znode 改变的时候,回调通知客户端,这个功能在 分布式协调 中是很有必要的
分布式系统的协调需求:分布式架构中的系统 A 监听一个数据的变化,如果分布式架构中的系统 B 更新了那个数据/节点,zk 会反过来通知系统 A 这个数据的变化
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【现代密码学】笔记 补充7-- CCA安全与认证加密《introduction to modern cryphtography》
- Flink实战之运行架构
- 【Jmeter】Jmeter基础7-Jmeter元件介绍之后置处理器
- cargo设置国内源 windows+linux
- 数据截取处理、富文本去除所有标签
- git推送前HOOK pre-push判断版本号增加再推送
- 原来岳云鹏背后的女人竟然是她?有她,岳云鹏红遍大江南北。
- Network:use `--host` to expose
- 【日常笔记】阿里云ECS - 挂载新购云盘
- 为什么 C 语言没有被 C++ 取代?