Database__进阶
文章目录
😊 @ 作者:Lion J
💖 @ 主页: https://blog.csdn.net/weixin_69252724?spm=1000.2115.3001.5343
🎉 @ 主题: 数据库mysql(高级部分)
?? @ 创作时间:2024年01月24日
————————————————
文章目录
提示:以下是本篇文章正文内容,下面案例可供参考
一、mysql的服务架构?
服务架构是mysql的骨架结构, 分为连接层, 服务层, 引擎层, 数据文件层
1. 连接层
连接层主要用于处理与客户的连接,授权认证,以及安全认证
2. 服务层
完成sql服务的核心服务, 如相关的sql接口, 以及数据的缓存, sql的分析, 以及内置函数的执行, 是否利用索引查询
3. 引擎
负责与文件层进行交互操作, 是否支持索引, 锁定水平…
4. 物理文件层
在文件系统(硬盘)上存储数据, 日志
二、引擎
1. 概述
在mysql中用到的存储机制, 是否支持索引, 支持的锁定水平等各种功能技术, 不同的技术与配置方式叫做引擎
2. 两种主要引擎
●InnoDB
●MyISAM
三、索引
在数据量大(万级数据)可以高效的查询数据
1.概念
数据库中维护的特定查找算法的数据结构叫做索引, 他是一种排好序的快速查找的数据结构
2.索引的原理
类似与书上的目录, 不用再寻找书中的数据时每次一页一页的翻, 可以直接通过目录来减小数据的范围,逐渐筛选出结果, 做到高效查找自己想要的数据;
图例:
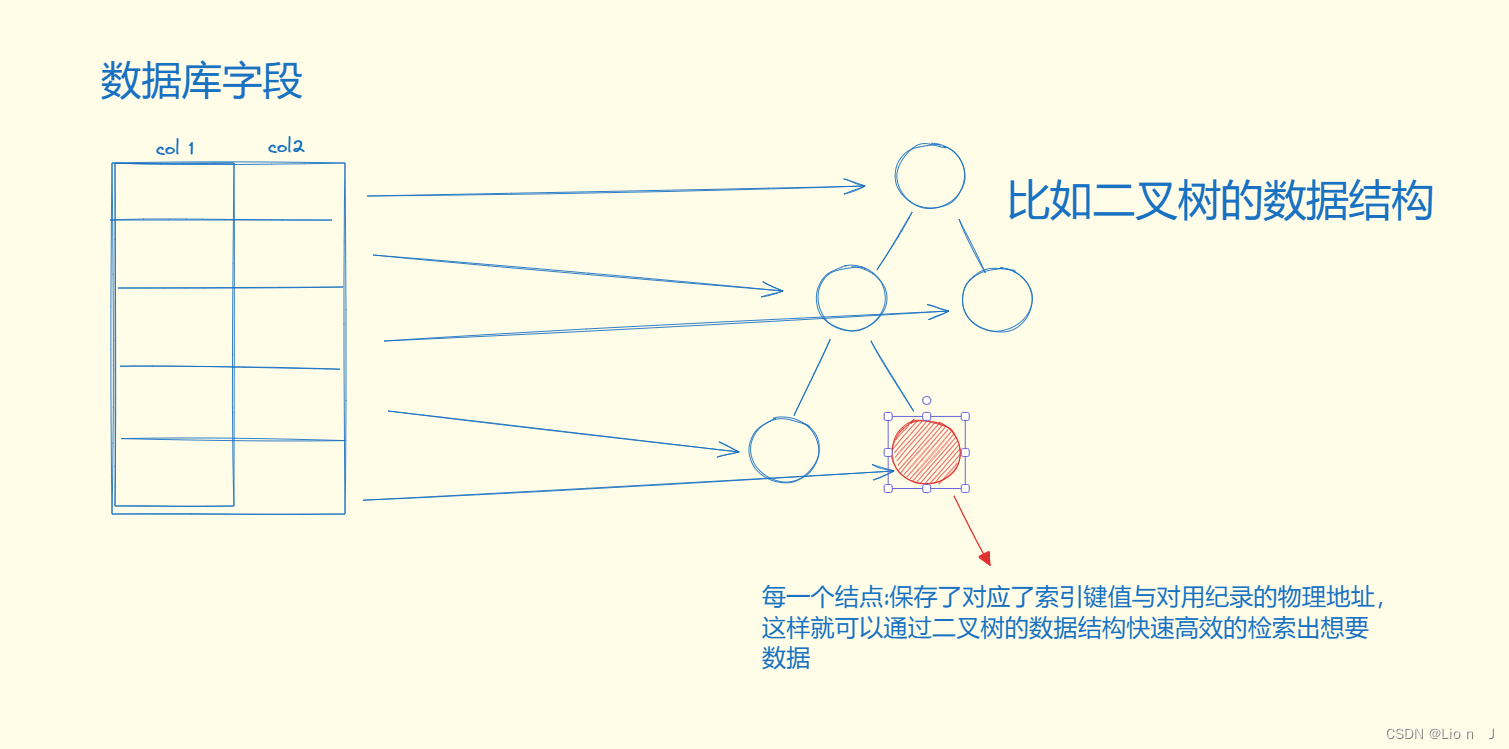
将数据库中的数据与索引库中的数据一一对应, 提高检索效率
3. 索引的优劣势
●优势
- 索引可以快速的提高检索效率,降低数据库的IO成本(从系统文件上读取)
- 索引对查询纪录结果进行排序, 分组, 降低原本mysql结果排序对CPU的消耗
●劣势
- 由于创建索引之后, 索引相当一张表, 保存主键与索引字段,以及指向实体表的纪录的物理地址, 会占用磁盘空间
- 数据的增删改不仅会改变实体表的纪录, 还会改变索引关系表(索引树)的纪录, 所以会降低更新表数据的速度,造成实际业务的拖延,增加数据库压力
4. 索引的分类
这里以mysql数据库为例
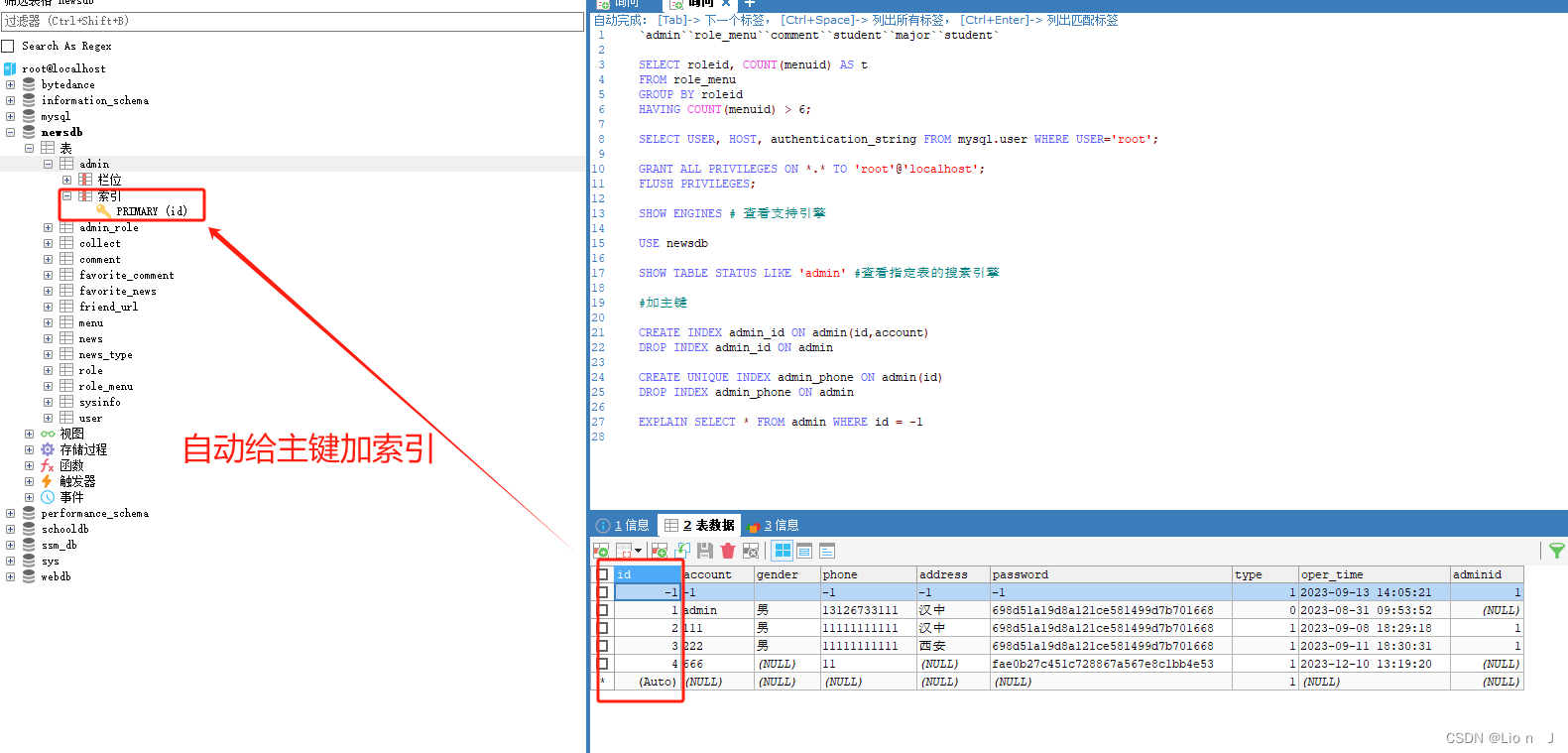
1> 主键索引
顾名思义就是将表中的主键当作索引列, 数据库会自动再主键上添加索引
语句
#增加
alter table [表名] add primary key
#删除
alter table [表明] drop primary key
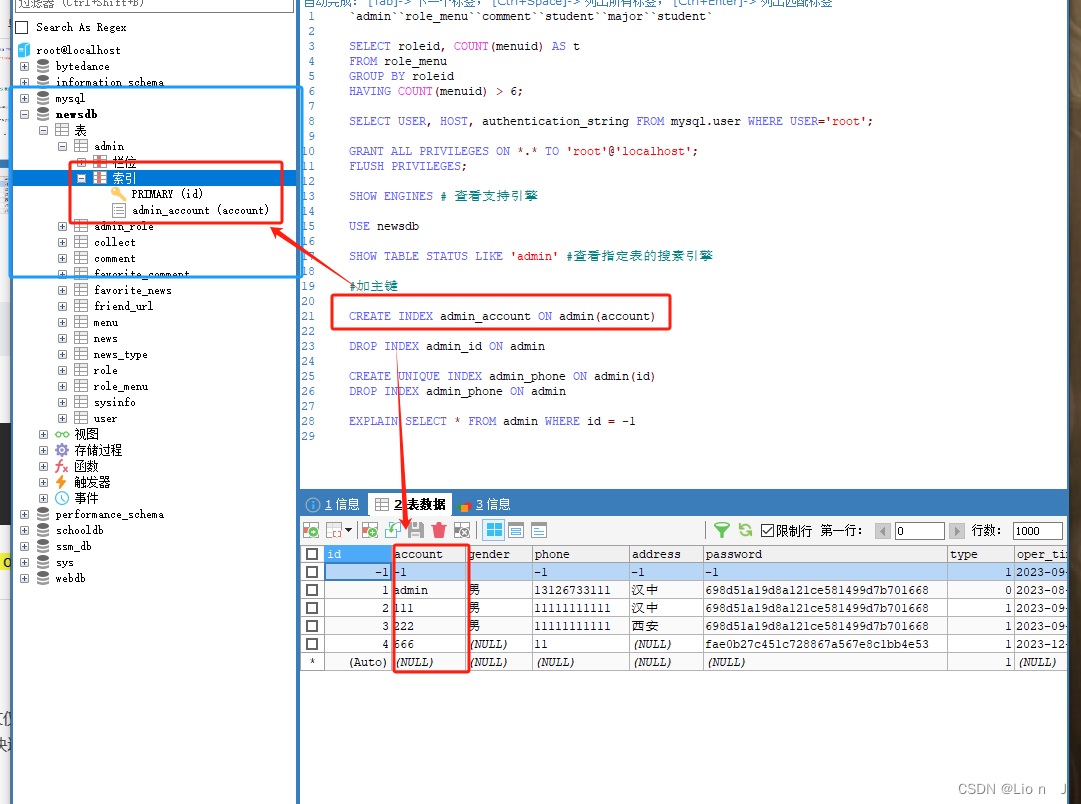
2>单值索引
可以给某一列添加索引, 就是最常用索引
语句
#添加
create index 索引名 on 表名(列名)
#删除
drop index 索引名 on 表明
如:create idnex admin_account_index on admin(account)
单值索引查询效率比主键索引性能低
原因: 主键索引的值在整个表中必须是唯一的,这使得数据库可以更快地定位到特定的行。相比之下,单值索引可能不保证唯一性,因此查询可能需要检查更多的行
3>唯一索引
唯一索引这里的唯一指的是这一列的纪录是唯一的, 可以想象成主键索引的低配版, 列里的值允许null
语句
create unique index on 表名(列名)
drop index 索引名 on 表名
唯一索引与前面例子类似,唯一就是要求
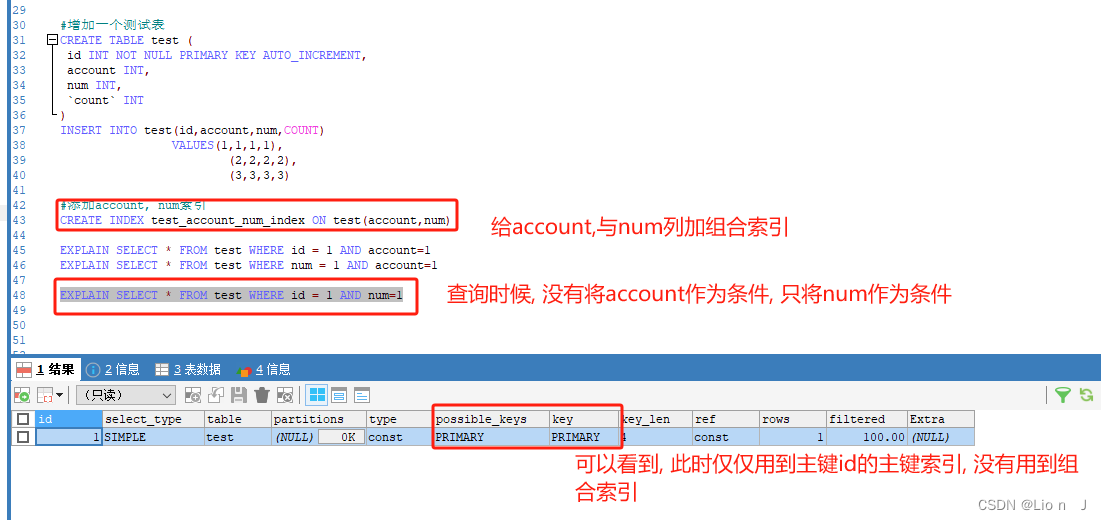
4>组合索引(复合索引)
●概念
组合索引可以想象为多个单值索引, 但是总体来说, 组合索引比多个单值索引的开销更小, 当行数远远大于列数时候, 可以适当的添加组合索引
语句
create index on 表名(列名,列名,列名)
drop index on 表明
●组合索引最左前缀原
假如有三个列abc,添加组合索引ab, 那么在将组合索引的列作为查询条件时, 必须要出现最左侧列, 不然组合索引不生效
演示
(应该叫组合索引, 图中口误🤣)
这是组合索引生效例子

组合索引失效
5>全文索引
由于mysql在模糊查询时候, 一般的索引都不生效, 所以有专门应对该问题产生了全文索引
语法
CREATE FULLTEXT INDEX 索引名 ON 表名(字段名) WITH
create fulltext index 索引名 on 表明(列) preset
图示:
先使用单值索引, 索引列名name
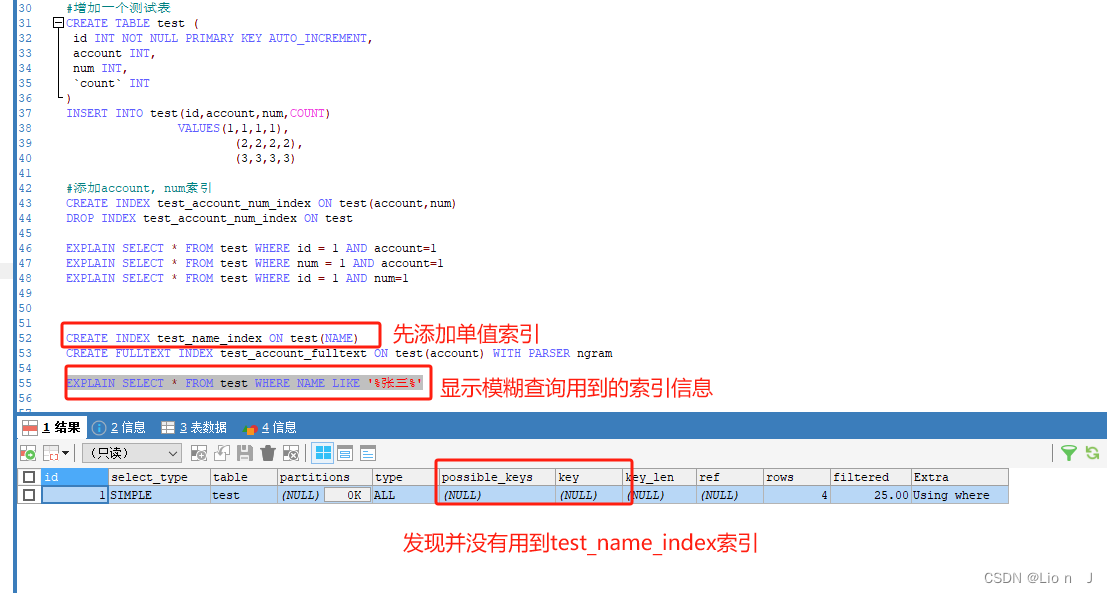
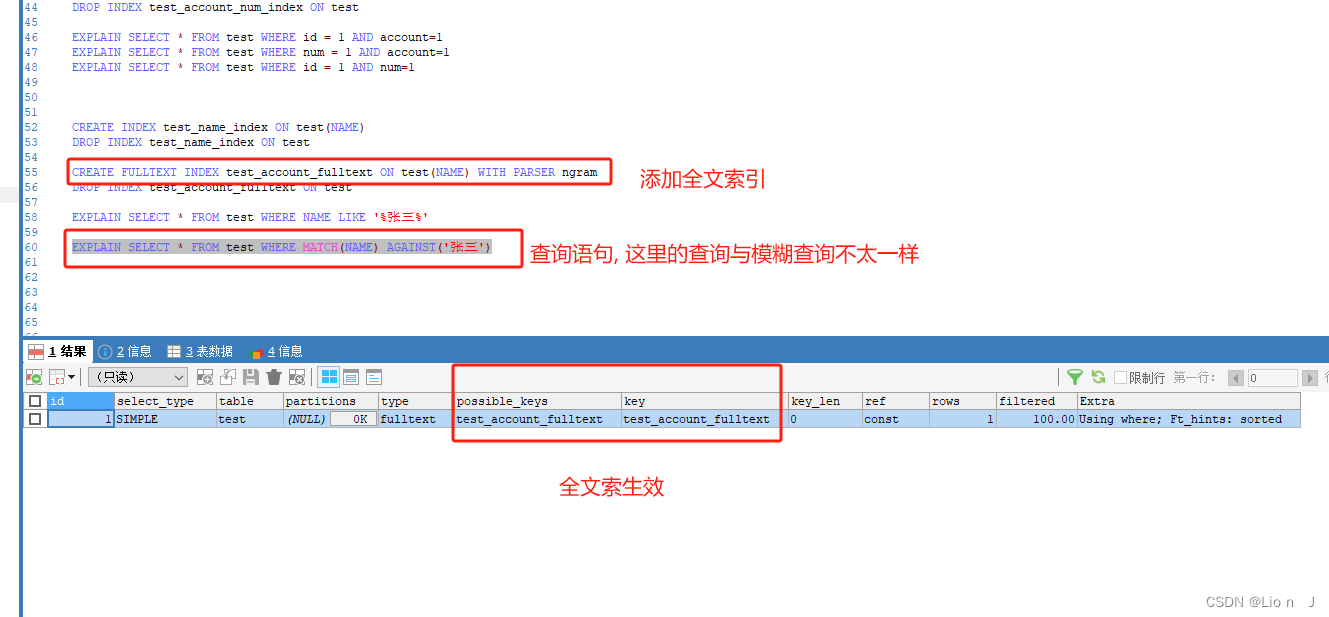
再使用全文索引
注意:在使用全文索引时,进行模糊查询语法稍微不一样
SELECT 结果 FROM 表名 WHERE MATCH(列名) AGAINST(‘搜索词’)
5. 索引的数据结构
索引数据结构是B+树的结构
为什么不能是二叉树?
因为数据库里的主键一般都是自增的, 而根据二叉树的性质知道, 此时的索引树将会向一边倾斜, 导致高度非常高(和链表一样), 反而查询效率更慢为什么不能是红黑树?
红黑树虽然可以通过子旋转,但是还是会向一边来加元素, 问题同上
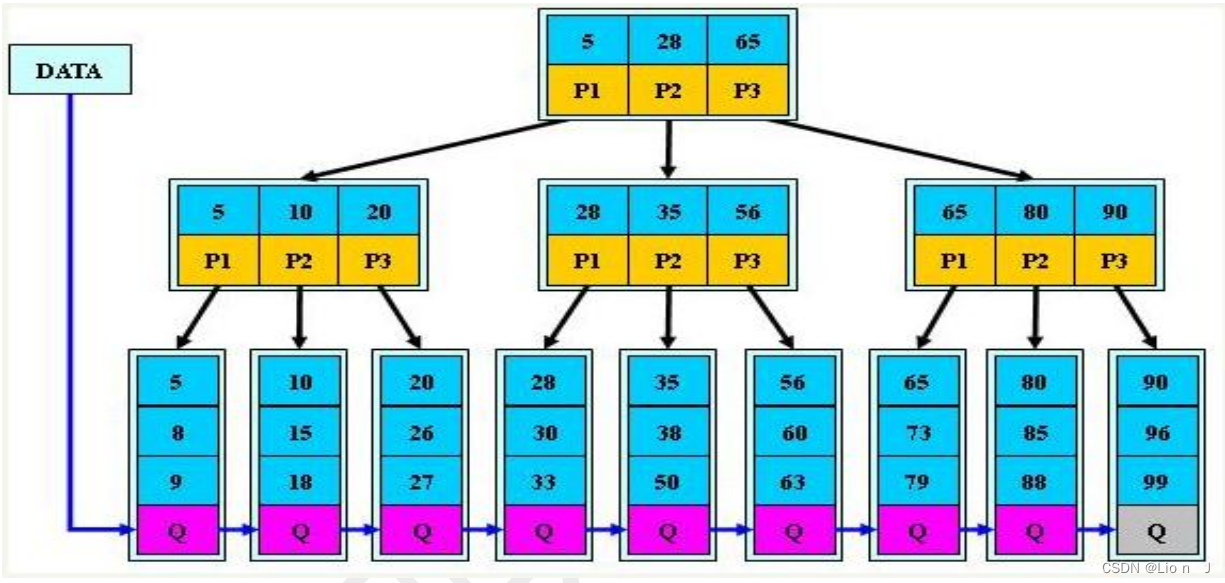
用B+树,非叶子结点上放数据的索引, B+树的性质刚好可以让一个非叶子结点放大量的索引;而将数据放到一个个的叶子结点里,所有叶子结点(数据之间有链指针)
这样可以在全表扫描时,查询某一索引时,快速锁定该索引, 再向下获取该索引对应数据
在sql范围查询时, 也可以通过链指针快速得到范围内的数据
图示:
6. 聚簇索引与非聚簇索引
●聚簇索引:
只在执行sql查询操作时, 可以通过索引直接获取数据, 比如InnoDB里的主键索引(一级索引)
聚簇是设计: InnoDB,索引与数据如下

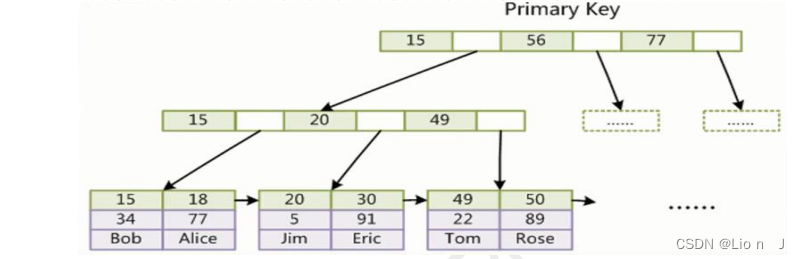
●非聚簇索引:
指的是,索引存储与数据存储是分离的, 比如在Myisam引擎,
>索引与数据关系如下
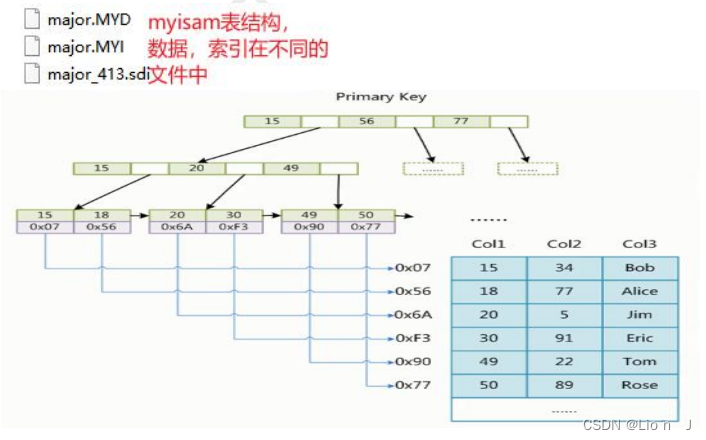
innodb与myisam虽然聚簇式设计与非聚簇式索引, 但是并不代表查询时候的索引都是聚簇索引与非聚簇索引,仅仅是根据两种思想设计的
innodb反例:
如一个表 字段 a(主键),b,c,字段c(单值索引)
selelct b,c from test where c = 33
该sql通过c的索引树查询到的索引结点数据是主键id, 再需要通过主键id重新查询一下,该sql查询中, c索引就是非聚簇索引
myisam反例:
例子同上
select id from test where id = 1
该种查询就直接查询到对应的索引结点,再通过索引结点直接获取内存里的数据物理地址
总结
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 深度学习实战67-基于Stable-diffusion的图像生成应用模型的搭建,在Kaggle平台的搭建部署,解决本地没有算力资源问题
- Java里的Collections算法类
- 【嵌入式移植】3、编译U-Boot
- 搜索引擎推广的实践技巧提升你的品牌影响力-华媒舍
- Redis 给集合元素单独设置过期
- Numpy数值计算
- 小模型也能COT
- ReactNative进阶(五十三)ios组包报错getaddrinfo ENOTFOUND static.realm.io问题修复
- 实用学习网站和资料
- 麒麟V10上安装Oracle 19C碰到的一些坑