机器学习 | Pandas超详细教程

欢迎关注博主 Mindtechnist 或加入【Linux C/C++/Python社区】一起学习和分享Linux、C、C++、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和技术。
Pandas
专栏:《机器学习》
🎉🎉🎉🎉🎉 重磅福利 🎉🎉🎉🎉🎉
🎉本次送2套书 ,评论区抽2位小伙伴送书
🎉活动时间:截止到 2023-12-31 10:00:00
🎉抽奖方式:评论区随机抽奖。
🎉参与方式:关注博主、点赞、收藏,评论。
?注意:一定要关注博主,不然中奖后将无效!
🎉通知方式:通过私信联系中奖粉丝。
💡提示:有任何疑问请私信公粽号 《机器和智能》

什么是Pandas
Pandas 库是一个免费、开源的第三方 Python 库,是 Python 数据分析必不可少的工具之一,它为 Python 数据分析提供了高性能,且易于使用的数据结构,即 Series 和 DataFrame。Pandas 自诞生后被应用于众多的领域,比如金融、统计学、社会科学、建筑工程等。
Pandas 库基于 Python NumPy 库开发而来,因此,它可以与 Python 的科学计算库配合使用。Pandas 提供了两种数据结构,分别是 Series(一维数组结构)与 DataFrame(二维数组结构),这两种数据结构极大地增强的了 Pandas 的数据分析能力。

Pandas 最初由 Wes McKinney(韦斯·麦金尼)于 2008 年开发,并于 2009 年实现开源。目前,Pandas 由 PyData 团队进行日常的开发和维护工作。在 2020 年 12 月,PyData 团队公布了最新的 Pandas 1.20 版本 。

pandas主要有以下优势:
- 增强图表可读性
- 便捷的数据处理能力
- 读取文件方便
- 封装了Matplotlib、Numpy的画图和计算
安装Pandas
Windows安装Pandas
直接在cmd命令行使用pip命令安装即可
pip install pandas
Linux安装Pandas
CentOS运行如下代码
sudo yum install numpy scipy matplotlib pandas
Ubuntu运行下面代码
sudo apt-get install numpy scipy matplotlib pandas
Pandas数据结构
Series结构
Series 结构,也称 Series 序列,它是一种类似于一维数组的结构,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系。
Series 可以保存任何数据类型,比如整数、字符串、浮点数、Python 对象等,它的标签默认为整数,从 0 开始依次递增。

创建series
# 导入pandas
import pandas as pd
pd.Series(data=None, index=None, dtype=None, copy)
参数:
- data:输入的数据,可以是列表、常量、ndarray 数组等。
- index:索引值必须是惟一的,且与数据的长度相等,如果没有传递索引,则默认为 np.arrange(n)。
- dtype:dtype表示数据类型,如果没有提供,则会自动判断得出。
- copy:表示对 data 进行拷贝,默认为 False。
示例:
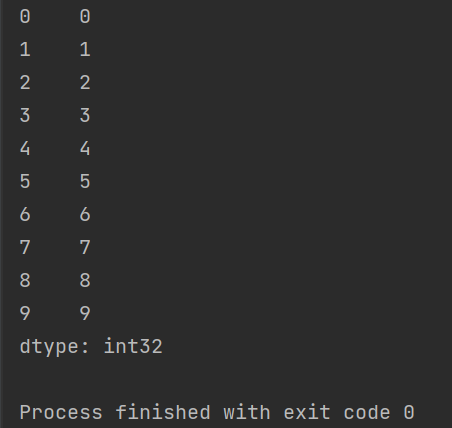
import pandas as pd
import numpy as np
print(pd.Series(np.arange(10)))
运行结果如下
我们也可以指定索引来创建
import pandas as pd
import numpy as np
p = pd.Series([1, 2, 3, 4, 5], index=[5, 4, 3, 2, 1])
print(p)
运行结果如图

也可以通过字典来创建
import pandas as pd
import numpy as np
p = pd.Series({'a':1, 'b':2, 'c':3, 'd':4})
print(p)
运行结果如图

访问Series数据
我们知道,Series结构有值和标签组成,那么自然可以想到,访问Series的方式也有两种,即通过位置索引和通过标签两种方式。
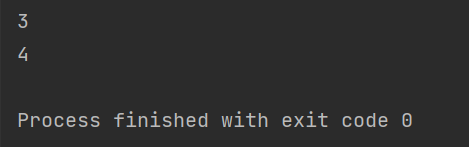
import pandas as pd
import numpy as np
p = pd.Series({'a':1, 'b':2, 'c':3, 'd':4})
#通过位置索引访问
print(p[2])
#通过标签访问
print(p['d'])
运行结果如下
Series的属性
Series主要有以下属性
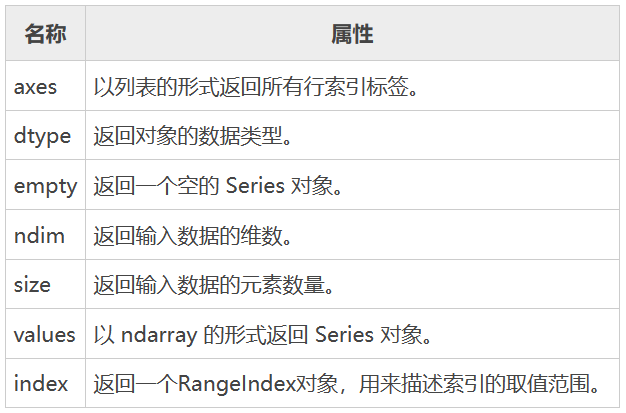
其中,index和values是两个常用的属性
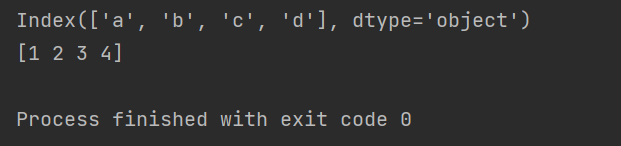
import pandas as pd
p = pd.Series({'a':1, 'b':2, 'c':3, 'd':4})
print(p.index)
print(p.values)
运行结果如下
Series常用方法
head()&tail()查看数据。head() 返回前 n 行数据,默认显示前 5 行数据;tail() 返回的是后 n 行数据,默认为后 5 行。
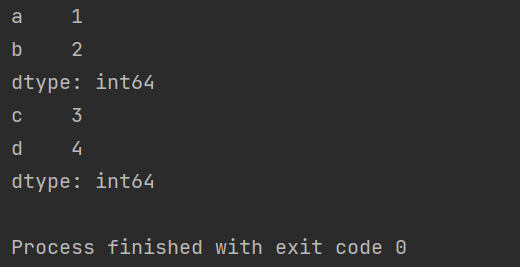
import pandas as pd
p = pd.Series({'a':1, 'b':2, 'c':3, 'd':4})
print(p.head(2))
print(p.tail(2))
运行结果如下
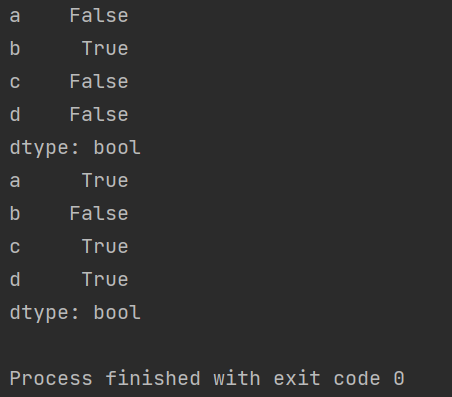
isnull()&nonull()检测缺失值。isnull()如果为值不存在或者缺失,则返回 True。notnull()如果值不存在或者缺失,则返回 False。
p2 = pd.Series({'a':1, 'b':None, 'c':3, 'd':4})
print(p2.isnull())
print(p2.notnull())
运行结果如下
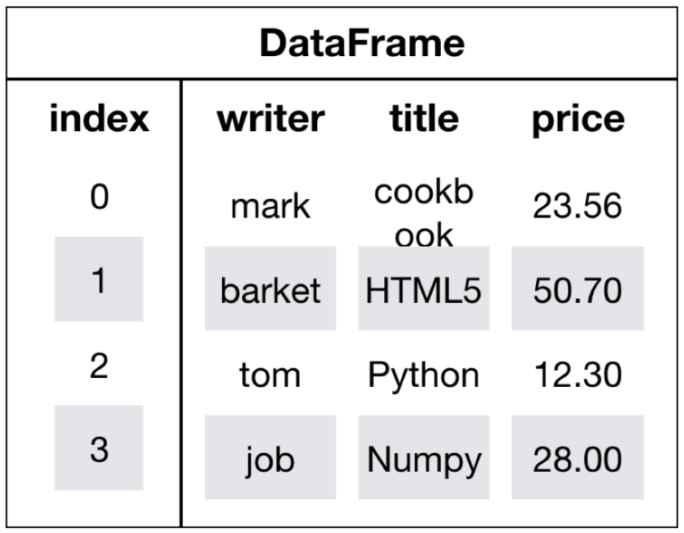
DataFrame结构
DataFrame 一个表格型的数据结构,既有行标签(index),又有列标签(columns),它也被称异构数据表,所谓异构,指的是表格中每列的数据类型可以不同,比如可以是字符串、整型或者浮点型等。
DataFrame 的每一行数据都可以看成一个 Series 结构,只不过,DataFrame 为这些行中每个数据值增加了一个列标签。因此 DataFrame 其实是从 Series 的基础上演变而来。在数据分析任务中 DataFrame 的应用非常广泛,因为它描述数据的更为清晰、直观。
简言之,DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引:
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
创建DataFrame
import pandas as pd
pd.DataFrame( data, index, columns, dtype, copy)
参数:
- data:输入的数据,可以是 ndarray,series,list,dict,标量以及一个 DataFrame。
- index:行标签,如果没有传递 index 值,则默认行标签是 np.arange(n),n 代表 data 的元素个数。
- columns:列标签,如果没有传递 columns 值,则默认列标签是 np.arange(n)。
- dtype:dtype表示每一列的数据类型。
- copy:默认为 False,表示复制数据 data。
创建一个DataFrame结构的示例如下
import numpy as np
import pandas as pd
# 生成10名同学,5门功课的数据
score = np.random.randint(40, 100, (10, 5))
#print(score)
# 使用Pandas中的数据结构
score_df = pd.DataFrame(score)
#print(score_df)
# 构造行索引序列
subjects = ["语", "数", "英", "美", "体"]
# 构造列索引序列
stu = ['同学' + str(i) for i in range(score_df.shape[0])]
# 添加行索引
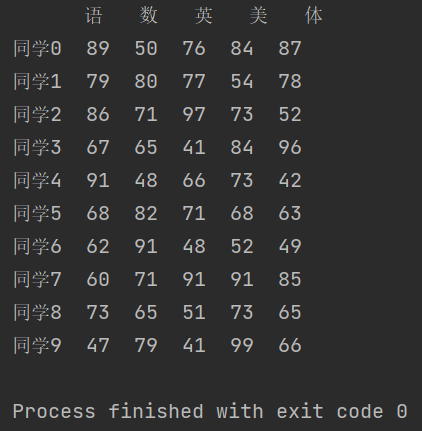
data = pd.DataFrame(score, columns=subjects, index=stu)
print(data)
运行结果
DataFrame 的属性和方法

以上属性和方法的示例代码如下,首先创建一个DataFrame结构
import numpy as np
import pandas as pd
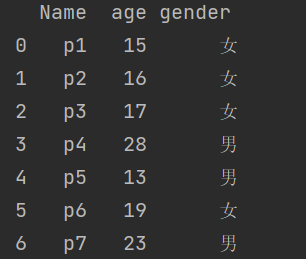
d = {'Name':pd.Series(['p1','p2',"p3",'p4','p5','p6','p7']),
'age':pd.Series([15,16,17,28,13,19,23]),
'gender':pd.Series(['女','女','女','男','男','女','男'])}
#创建DataFrame
df = pd.DataFrame(d)
print(df)
#输出DataFrame的转置
print(df.T)
#输出行、列标签
print(df.axes)
#返回每一列的数据类型
print(df.dtypes)
#判断输入数据是否为空
print(df.empty)
#返回数据对象的维数
print(df.ndim)
#返回数据对象的形状
print(df.shape)
#元素个数
print(df.size)
#以 ndarray 数组的形式返回 DataFrame 中的数据
print(df.values)
打印结果可以自行运行程序查看。
shift()移动行或列
用于移动 DataFrame 中的某一行/列,它提供了一个periods参数,该参数表示在特定的轴上移动指定的步幅。
DataFrame.shift(periods=1, freq=None, axis=0)
参数:
- peroids:类型为int,表示移动的幅度,可以是正数,也可以是负数,默认值为1。
- freq:日期偏移量,默认值为None,适用于时间序。取值为符合时间规则的字符串。
- axis:如果是 0 或者 “index” 表示上下移动,如果是 1 或者 “columns” 则会左右移动。
- fill_value:该参数用来填充缺失值。
head()&tail() 查看数据,类似于Series中的方法。
Panel结构
Panel 结构也称“面板结构”,它源自于 Panel Data 一词,翻译为“面板数据”。Panel 是一个用来承载数据的三维数据结构,它有三个轴,分别是 items(0 轴),major_axis(1 轴),而 minor_axis(2 轴)。这三个轴为描述、操作 Panel 提供了支持,其作用介绍如下:
- items:axis =0,Panel 中的每个 items 都对应一个 DataFrame。
- major_axis:axis=1,用来描述每个 DataFrame 的行索引。
- minor_axis:axis=2,用来描述每个 DataFrame 的列索引。
创建Panel
pandas.Panel(data, items, major_axis, minor_axis, dtype, copy)
参数:
- data:输入数据,可以是 ndarray,Series,列表,字典,或者 DataFrame。
- items:axis=0
- major_axis:axis=1
- minor_axis:axis=2
- dtype:每一列的数据类型。
- copy:默认为 False,表示是否复制数据。
MultiIndex
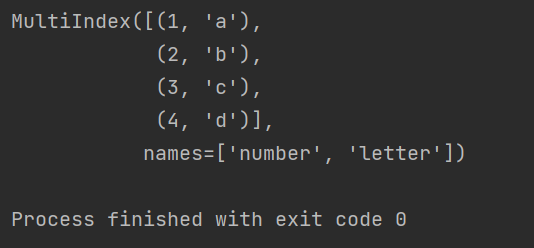
MultiIndex也是三维的数据结构,多级索引(也称层次化索引)是pandas的重要功能,可以在Series、DataFrame对象上拥有2个以及2个以上的索引。
import pandas as pd
arrays = [[1, 2, 3, 4], ['a', 'b', 'c', 'd']]
data = pd.MultiIndex.from_arrays(arrays, names=('number', 'letter'))
print(data)
运行结果如下
DataFrame操作
算术运算
add(other)
逻辑运算
query(expr)
其中,expr表示查询字符串。
统计运算
| count | Number of non-NA observations |
|---|---|
| sum | Sum of values |
| mean | Mean of values |
| median | Arithmetic median of values |
| min | Minimum |
| max | Maximum |
| mode | Mode |
| abs | Absolute Value |
| prod | Product of values |
| std | Bessel-corrected sample standard deviation |
| var | Unbiased variance |
| idxmax | compute the index labels with the maximum |
| idxmin | compute the index labels with the minimum |
| cumsum | 计算前1/2/3/…/n个数的和 |
| cummax | 计算前1/2/3/…/n个数的最大值 |
| cummin | 计算前1/2/3/…/n个数的最小值 |
| cumprod | 计算前1/2/3/…/n个数的积 |
自定义运算
apply(func, axis=0)
参数:
- func:自定义函数。
- axis=0:默认是列,axis=1为行进行运算。
排序
df.sort_values(by=, ascending=)
对单个键或者多个键进行排序,
参数:
- by:指定排序参考的键。
- ascending:默认升序,ascending=False表示降序,ascending=True表示升序。
Pandas绘图
Pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图操作。
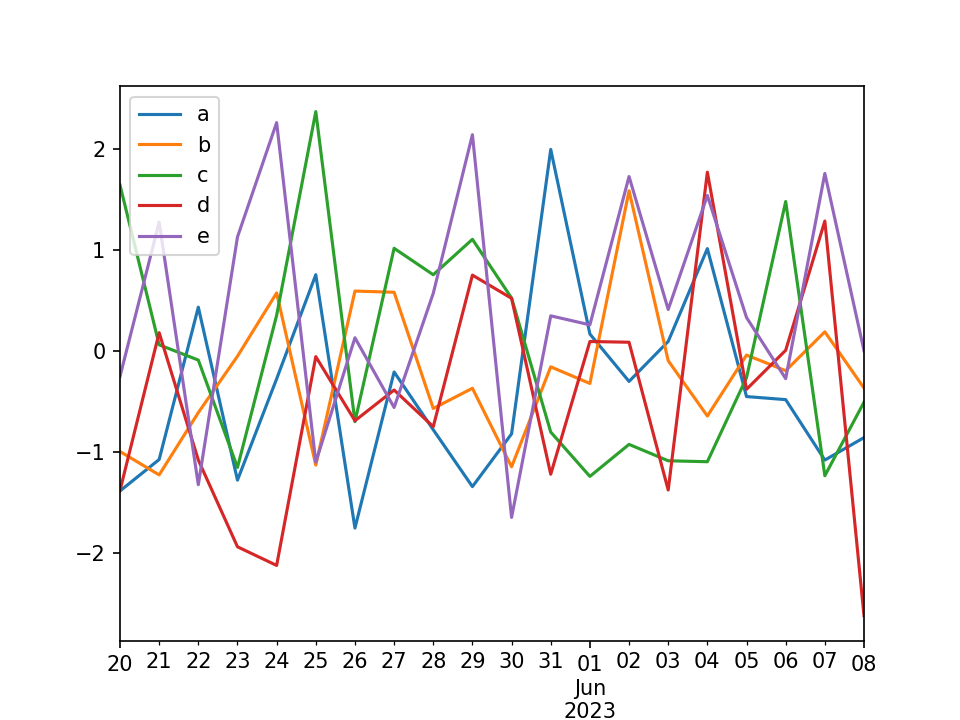
折线图
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(20,5),index=pd.date_range('5/20/2023', periods=20), columns=list('abcde'))
df.plot()
#不加这句话,无法显示图片
plt.show()
柱状图
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(20,5),columns=['a','b','c','d','e'])
df.plot.bar()
#不加这句话,无法显示图片
plt.show()
散点图
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(30, 5), columns=['a', 'b', 'c', 'd', 'e'])
df.plot.scatter(x='a',y='e')
#不加这句话,无法显示图片
plt.show()
饼状图
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
df = pd.DataFrame(3 * np.random.rand(2), index=['boy', 'girl'], columns=['L'])
df.plot.pie(subplots=True)
#不加这句话,无法显示图片
plt.show()
图书推荐-《Pandas数据分析》
Pandas是强大且流行的库,是Python中数据科学的代名词。本书将向你介绍如何使用Pandas对真实世界的数据集进行数据分析,如股市数据、模拟黑客攻击的数据、天气趋势、地震数据、葡萄酒数据和天文数据等。Pandas使我们能够有效地处理表格数据,从而使数据整理和可视化变得更容易。

内容简介
《Pandas数据分析》详细阐述了与Pandas数据分析相关的基本解决方案,主要包括数据分析导论、使用Pandas DataFrame、使用Pandas进行数据整理、聚合Pandas DataFrame、使用Pandas和Matplotlib可视化数据、使用Seaborn和自定义技术绘图、金融分析、基于规则的异常检测、Python机器学习入门、做出更好的预测、机器学习异常检测等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。 本书适合作为高等院校计算机及相关专业的教材和教学参考书,也可作为相关开发人员的自学用书和参考手册。

数据科学通常被认为是一个跨学科领域,涉及编程技能、统计知识和领域知识等。它已经迅速成为当今社会最热门的领域之一,而了解如何处理数据将使你在职业生涯中拥有很大的优势。无论是哪个行业、职位或项目,对数据技能的需求都很高,因此学习和掌握数据分析技能对于现代人来说至关重要。
数据科学领域涵盖许多不同方面:数据分析师更专注于提取业务见解,数据科学家重在将机器学习技术应用于业务问题,数据工程师专注于设计、构建和维护数据分析师和科学家使用的数据管道,机器学习工程师则拥有数据科学家的大部分技能,并且与数据工程师一样,都是熟练的软件工程师。

由此可见,数据科学涵盖许多领域,但对于它所涉及的领域而言,数据分析都是一个基本组成部分。你无论是要成为数据分析师、数据科学家、数据工程师,还是机器学习工程师,本书都可以为你提供基础技能。
数据科学中的传统技能包括了解如何从各种来源(如数据库和API)收集数据并对其进行处理。Python是一种流行的数据科学语言,它提供了收集和处理数据以及构建生产质量数据产品的方法。由于它是开源的,因此我们很容易通过利用其他人编写的库解决常见的数据任务和问题。




本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《地理信息系统原理》笔记/期末复习资料(11. GIS的输出与地图可视化)
- 手工计算层次分析法的最大特征根和特征向量
- 车载电子电器架构 —— 电子电气系统开发角色定义
- 旗鼓相当的对手 - 加强版#洛谷
- 【多线程及高并发 番外篇】虚拟线程怎么被 synchronized 阻塞了?
- 华硕主板开机只进入Bios模式不进入Windows系统
- xdoj 大一上期末c语言复习小结
- 热门平台引流玩法,一起看看吧
- 《代码随想录》笔记
- 【已解决】在使用frp内网穿透访问VUE项目提示:Invalid Host/Origin header 解决方案