正则表达式-分组括号以及捕获分组
发布时间:2024年01月20日
分组:
定义:
在java正则表达式中,( )是分组的意思,每组都有一个组号
如何识别分组?
只看左括号,不看右括号,按照左括号的顺序,从左往右,依次为第一组,第二组,第三组等等,如图:
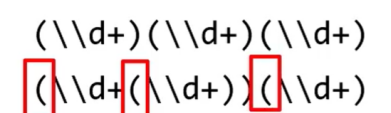
根据左括号分成了三组

正则表达式中分组有两种:
捕获分组,非捕获分组
捕获分组:
可以获取某一组中的内容反复使用
规则:
正则表达式内部使用:\\ 组号
外:$ 组号
捕获分组 练习 1
需求1:判断一个字符串的开始字符和结束字符是否一致?只考虑一个字符
String regex1="(.).+\\1";
System.out.println("_123_".matches(regex1));//true
System.out.println("_123_1".matches(regex1));//false(.)表示第一个分组
需求2:判断一个字符串的开始部分和结束部分是否一致?可以有多个字符
String regex2="(.+).+\\1";
System.out.println("ab_123ab_".matches(regex2));//true
System.out.println("asb_123ab_".matches(regex2));//false
需求3:判断一个字符串的开始部分和结束部分是否一致?开始部分内部每个字符也需要一致
String regex3="(.)\\1*.+\\1";
System.out.println("aaa123aaa".matches(regex3));//true
System.out.println("aaa123aab".matches(regex3));//false(.):匹配任意一个字符,并将其捕获为第一组(\1就是引用这个被捕获的字符)。
\\1*:表示匹配前面捕获的第一组(即与第一个字符相同的字符)零个或多个。
.+:匹配一个或多个任意字符(除换行符外)。
\\1:再次引用第一组捕获的字符,要求以与开头相同的字符结尾。
捕获分组 练习 2:
任务:把重复的内容 替换为 单个的
String str = "今天有亿亿亿亿亿点点点懒懒懒";
String regex="(.)\\1+";
String s = str.replaceAll(regex, "$1");
System.out.println(s);//今天有亿点懒(.)表示把重复内容的第一个字符看做一组
\\1+表示第一组字符至少再出现一次
$1 表示把正则表达式中第一组的内容,再拿出来用
非捕获分组:
分组之后不需要再用本组数据,仅仅是把数据括起来。不占组号
如:(在“带条件爬取”中已经见过)
文章来源:https://blog.csdn.net/2301_79947226/article/details/135721457
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LeetCode977有序数组的平方两种方法实现(java实现)
- 洛谷刷题的第....n+1天
- SurfaceFlinger的commit/handleTransaction分析
- HCIP BGP(一)
- 基于SpringBoot实现一个可扩展的事件总线
- Redis 有序集合(sorted set)常见问题
- 方法-总和
- 一键修复所有dll缺失的工具,dll修复工具下载使用教程
- webpack.config.js配置文件报错:The ‘mode‘ option has not been set
- echarts实现七天天气预报