【Transformer框架代码实现】
发布时间:2023年12月20日
Transformer
Transformer框架
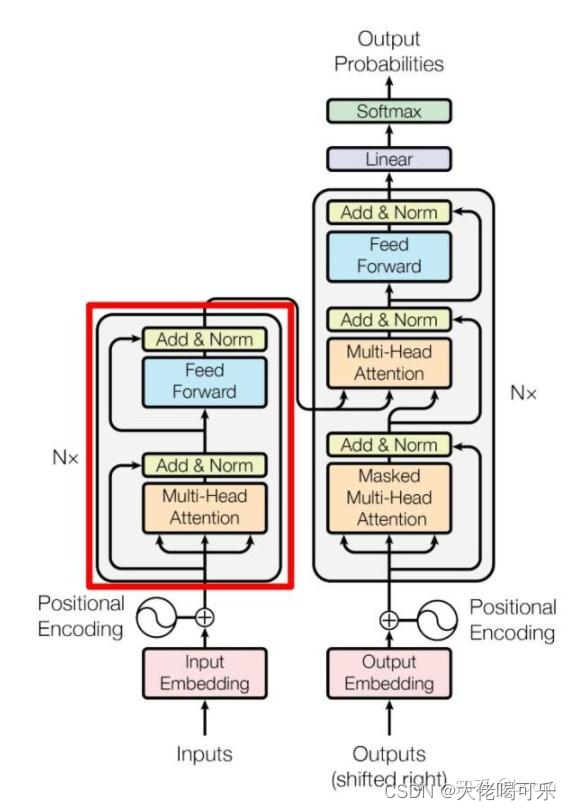
注意力机制框架
导入必要的库
from torch import nn
import torch
import math
import torch.nn.functional as F
Input Embedding / Out Embedding
词嵌入层的实现
nn.Embedding(vocab_size, embed_dim)中
vocab_size: 词典长度,必须大于输入的单词总量
embed_dim:词向量维度
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size, embed_dim):
"""
:param vocab_size: 词典长度/维度/图片size(0) 必须大于输入的单词总量. batch_size=句子数量
:param embed_dim: 词向量维度
"""
super(TokenEmbedding, self).__init__()
self.embed_dim = embed_dim
self.embedding = nn.Embedding(vocab_size, embed_dim)
def forward(self, x):
# 对原始向量进行缩放,出自论文
# [batch_size, vocab_size, embed_dim]
return self.embedding(x.long()) * math.sqrt(self.embed_dim)
Positional Embedding
位置编码层的实现
与RNN不同,对于给定输入input = “I am fine”,RNN中会顺序读入每个单词,而在Transformer中则是所有单词同时读入,因此失去了“有序性“,对机器来说,只收到三个单词I,am,fine,其并不知道这三个单词之间的位置关系,为此需要为每个单词附加上额外的位置信息。比如这里我们可以简单的传(I, 1),(am, 2),(fine, 3)。这样不仅传入了句子的单词,还附加上单词的位置信息。
一种好的位置编码方案需要满足以下几条要求:
- 能为每个时间步输出一个独一无二的编码
- 不同长度的句子之间,任何两个时间步之间的距离应该保持一致
- 模型应该能毫不费力地泛化到更长的句子,且值是有界的
- 必须是确定性的
class PositionEncoding(nn.Module):
def __init__(self, d_model, max_len, dropout=0.1, device='cpu'):
"""
:param max_len: 句子最大长度 default:5000
:param d_model: 模型维度/embed_dim default:512 必须为偶数
:param device:
"""
super(PositionEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
pos_encoding = torch.zeros(max_len, d_model, device=device)
# 2D: [max_len, d_model]
pos = torch.arange(0, max_len, dtype=torch.float, device=device).unsqueeze(dim=1)
# 2D: [max_len, 1]
div_term = torch.exp(torch.arange(0, d_model, step=2, device=device).float() * (-math.log(10000) / d_model))
# 1D: [d_model / 2]
pos_encoding[:, 0::2] = torch.sin(pos * div_term)
pos_encoding[:, 1::2] = torch.cos(pos * div_term)
# 2D: [max_len, d_model]
pos_encoding = pos_encoding.unsqueeze(dim=0)
# print(pos_encoding.shape)
# 3D: [1, max_len, d_model], 扩充batch_size维度 batch_size * max_len * d_model
self.register_buffer('pos_encoding', pos_encoding)
def forward(self, x):
# [batch_size, max_len, d_model]
x = x + self.pos_encoding[:, :x.size(1)].requires_grad_(False)
return self.dropout(x)
Transformer Embedding
词嵌入层+位置编码层
class TransformerEmbedding(nn.Module):
def __init__(self, vocab_size, max_len, d_model, drop, device):
"""
:param vocab_size: 字典大小,字典中不同字符个数
:param max_len:
:param d_model:
:param drop:
:param drop_prob:
:param device:
"""
super(TransformerEmbedding, self).__init__()
self.embed = TokenEmbedding(vocab_size, d_model)
self.pos = PositionEncoding(d_model, max_len, drop, device)
def forward(self, x):
"""
:param x: padding后的vectors
:return: embedding + pos_encoder 后的vectors; shape: [batch_size, max_len, d_model]
"""
embed = self.embed(x)
pos = self.pos(embed)
return pos
调试例子,可以详细查看每一步运行的shape变化
if __name__ == '__main__':
Input = [[1, 2, 3, 4], [5, 6, 2], [1, 7, 8, 9, 10, 11, 12, 13, 14, 15]]
# 有三个句子[['你 好 世 界'], ['我 很 好'], ['你 不 是 真 正 的 快 乐']]
# 句子长度不一致进行padding处理
max_len = len(Input[2])
print('The most length is {} sequences '.format(max_len))
src_sentence = torch.tensor([])
for i in range(len(Input)):
src_sen = torch.tensor([Input[i]])
src_sen = F.pad(src_sen, (0, max_len-len(Input[i])), 'constant', 0)
src_sentence = torch.cat([src_sentence, src_sen], dim=0)
# x = src_sentence.unsqueeze(dim=0)
x = src_sentence
print(x)
# token_embed = TokenEmbedding(vocab_size=18, embed_dim=32)
# x = token_embed(x)
# print('token的维度为:', x.shape)
# pos_embed = PositionEncoding(d_model=32, max_len=max_len)
# x = pos_embed(x)
# print(x.shape)
trans = TransformerEmbedding(vocab_size=18, max_len=10, d_model=32, drop=0.1, device='cpu')
x = trans(x)
print('transformer的维度为:', x.shape)
ScaleDotProductAttention(self-attention)
单头注意力机制/自注意力机制实现
- q: query 查询,
-代表输入序列每个位置的上下文信息,可以看做单个位置向其他位置发出询问 - k: key 键,
-代表输入序列中每个位置的局部信息,每个位置将自己的局部信息编码为键,可以与其他位置进行比较和交互 - v: value 值,
-代表序列中每个位置的具体信息,可以获得具体数据
查询会和键进行一个相似度计算,然后根据相似度的权重对值进行加权求和
class ScaleDotProductAttention(nn.Module):
def __init__(self, dim_model):
"""
self_attention: softmax(QKT / sqrt(d_model))V
:param dim_model: 嵌入维度,default: 512
"""
super(ScaleDotProductAttention, self).__init__()
self.q = nn.Linear(dim_model, dim_model)
self.k = nn.Linear(dim_model, dim_model)
self.v = nn.Linear(dim_model, dim_model)
self.softmax = nn.Softmax(dim=-1)
def forward(self, query, key, value, mask=None):
"""
:param query: [batch_size, max_len, d_model]
:param key:
:param value:
:param mask: [max_len, max_len]
:return:
"""
q = self.q(query)
k = self.k(key)
v = self.v(value)
d_k = query.size(-1)
qk = self.softmax(torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(d_k))
if mask is not None:
qk = qk.masked_fill(mask == 0, -1e9)
attn_weights = self.softmax(qk)
output = torch.matmul(attn_weights, v)
return attn_weights, output
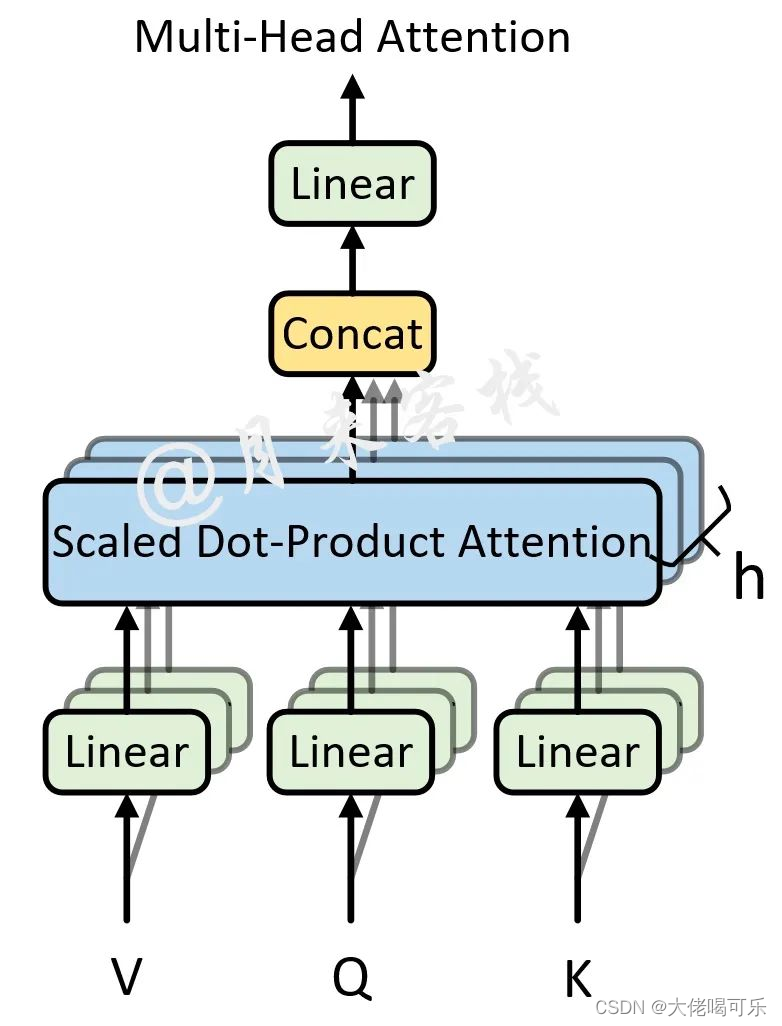
MultiHeadAttention 多头注意力机制
多头注意力机制实现
模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置, 因此作者提出了通过多头注意力机制来解决这一问题。同时,使用多头注意力机制还能够给予注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
import torch
from torch import nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
def __init__(self, dim_model, n_head, bias=True):
"""
:param dim_model: 词嵌入的维度,也就是前面的d_model参数,论文中的默认值为512
:param n_head: self-attention的个数 多头注意力机制中多头的数量,也就是前面的n_head参数, 论文默认值为 8
:param bias: 最后对多头的注意力(组合)输出进行线性变换时,是否使用偏置
"""
super(MultiHeadAttention, self).__init__()
self.d_model = dim_model
self.head_dim = dim_model // n_head
self.k_dim = self.head_dim
self.v_dim = self.head_dim
self.nums_head = n_head
# self.dropout = nn.Dropout(dropout)
assert self.nums_head * self.head_dim == self.d_model, 'embed_dim 除以 num_heads必须为整数'
self.q_weight = nn.Parameter(torch.Tensor(dim_model, dim_model))
# d_model = k_dim * nums_head
self.k_weight = nn.Parameter(torch.Tensor(dim_model, dim_model))
self.v_weight = nn.Parameter(torch.Tensor(dim_model, dim_model))
self.output_weights = nn.Parameter(torch.Tensor(dim_model, dim_model))
# self.output_bias = bias
self.output = nn.Linear(dim_model, dim_model, bias=bias)
def forward(self, query, key, value, drop_p, training=True, attn_mask=None, key_padding_mask=None):
"""
在论文中,编码时query, key, value 都是同一个输入,
解码时 输入的部分也都是同一个输入,
解码和编码交互时 key,value指的是 memory, query指的是tgt
:param drop_p: attention_weights layer
:param training: 是否开启训练模式
:param query: [batch_size, tgt_len, embed_dim], tgt_len 表示目标序列的长度
:param key: [batch_size, src_len, embed_dim], src_len 表示源序列的长度
:param value: [batch_size, src_len, embed_dim], src_len 表示源序列的长度
:param attn_mask: [tgt_len,src_len] or [num_heads*batch_size,tgt_len, src_len]
一般只在解码时使用,为了并行一次喂入所有解码部分的输入,所以要用mask来进行掩盖当前时刻之后的位置信息
:param key_padding_mask: [batch_size, src_len], src_len 表示源序列的长度. 填充部分掩码操作
:return:
attn_output: [tgt_len, batch_size, embed_dim]
attn_output_weights: # [batch_size, tgt_len, src_len]
"""
# 第一阶段: 计算得到Q、K、V
q = F.linear(query, self.q_weight)
# F.linear(inputs, weights, bias)
# query:[batch_size, src_len/tgt_len, d_model], q_weight:[d_model, d_model]
k = F.linear(key, self.k_weight)
v = F.linear(value, self.v_weight)
# 第二阶段:缩放,以及attn_mask维度判断
b_s, tgt_len, embed_dim = query.size()
source_len = key.size(1)
scaling = 1 / math.sqrt(self.head_dim)
# q*scaling: [batch_size, query_len, k_dim*nums_head]
q = q * scaling
# print(tgt_len, source_len)
if attn_mask is not None:
# [tgt_len, src_len] or [nums_head*batch_size, tgt_len, src_len]
if attn_mask.dim() == 2:
attn_mask = attn_mask.unsqueeze(0)
# print(attn_mask.shape)
if list(attn_mask.size()) != [1, tgt_len, source_len]:
raise RuntimeError('The size of the 2D attn_mask is not correct.')
elif attn_mask.dim() == 3:
if list(attn_mask.size()) != [b_s*self.nums_head, tgt_len, source_len]:
raise RuntimeError('The size of the 3D attn_mask is not correct.')
# 第三阶段: 计算得到注意力权重矩阵
# [batch_size, n_head, tgt_dim, k_dim] 计算时候是[tgt_dim, k_dim]* [k_dim, tgt_dim]->
# [batch_size, n_head, tgt_dim, tgt_dim] == [batch_size * n_head, tgt_dim, tgt_dim]
# q = q.view(b_s, tgt_len, n_head, head_dim).transpose(1, 2)
q = q.contiguous().view(b_s*self.nums_head, tgt_len, self.head_dim)
# [batch_size * n_head, tgt_len, k_dim]
k = k.contiguous().view(b_s*self.nums_head, -1, self.k_dim)
v = v.contiguous().view(b_s*self.nums_head, -1, self.v_dim)
# print(q.shape, k.shape, v.shape)
attn_output_wights = torch.bmm(q, k.transpose(-1, -2))
# [batch_size*nums_head, tgt_len, head_dim] * [batch_size*nums_head, k_dim, src_len]
# [batch_size*nums_head, tgt_len, src_len]
# 第四阶段: 进行相关掩码操作
if attn_mask is not None:
attn_output_wights = attn_output_wights + attn_mask
# [batch_size*nums_head, tgt_len, src_len] + [batch_size*nums_head, tgt_len, src_len]
if key_padding_mask is not None:
attn_output_wights = attn_output_wights.view(b_s, self.nums_head, tgt_len, source_len)
attn_output_wights = attn_output_wights.masked_fill(key_padding_mask.unsqueeze(1).unsqueeze(2) == 0, float('-inf'))
attn_output_wights = attn_output_wights.view(b_s * self.nums_head, tgt_len, source_len)
attn_output_wights = F.softmax(attn_output_wights, dim=-1)
attn_output_wights = F.dropout(attn_output_wights, p=drop_p, training=training)
attn_output = torch.bmm(attn_output_wights, v)
# [batch_size * nums_head, tgt_len, src_len], [batch_size*nums_head, src_len, v_dim]
# [batch_size * nums_head, tgt_len, v_dim]
attn_output = attn_output.contiguous().view(b_s, tgt_len, self.d_model)
# print(attn_output.shape)
attn_output_wights = attn_output_wights.view(b_s, self.nums_head, tgt_len, source_len)
Z = F.linear(attn_output, self.output.weight)
return Z, attn_output, attn_output_wights.sum(dim=1) / self.nums_head
if __name__ == '__main__':
inputs = 'transformer_embedding_out'
src_len = 5
batch_size = 2
d_model = 32
num_head = 1
src = torch.rand(([batch_size, src_len, d_model]))
mha = MultiHeadAttention(dim_model=d_model, n_head=num_head, bias=True)
out, attn_out, attn_weight = mha(src, src, src, drop_p=0.1, attn_mask=None, key_padding_mask=None)
print(out.shape, attn_out.shape, attn_weight.shape)
# print(src, out, attn_out, attn_weight)
# out = mha(inputs, inputs, inputs, drop_p=0.1, attn_mask=None, key_padding_mask=None)
EncoderLayer 编码层
单个编码层的实现
注意力机制经过残差连接后,进行层归一化后输出
class EncoderLayer(nn.Module):
def __init__(self, embed_dim, n_head, feedforward_dim, drop_fc=None, drop_attn=None, drop_feed=None):
"""
单个的编码层,论文中6个
:param embed_dim: 嵌入维度,词向量和位置编码的嵌入维度,论文中:512
:param n_head: 多头注意力机制个数,论文中:8个, 512//64=8,batch_size=64
:param drop_attn: 注意力机制层输出的随机丢弃
:param drop_feed: 前馈网络层输出的随机丢弃
"""
super(EncoderLayer, self).__init__()
# TransformerEmbedding(vocab_size=2048, d_model=512, drop=0.1, drop_prob=0.1, max_len=None, device='cpu')
# 注意力机制层 [batch_size, max_len, d_model]
self.attn_encoder = MultiHeadAttention(dim_model=embed_dim, n_head=n_head, bias=True)
# 注意力机制输出进行drop
self.drop_out1 = nn.Dropout(drop_attn)
self.norm1 = nn.LayerNorm(embed_dim)
# 前馈网络层
self.feedforward = PositionWiseFeedForward(dim_model=embed_dim, drop_fc=drop_fc, dim_feedforward=feedforward_dim)
# 前馈网络输出进行drop
self.drop_out2 = nn.Dropout(drop_feed)
self.norm2 = nn.LayerNorm(embed_dim)
self.activation = nn.ReLU()
def forward(self, src_sentence, drop=None, training=True, attn_mask=None, src_key_padding_mask=None):
"""
填充后的句子输入,经过词向量+位置编码/注意力机制层/残差连接/前馈传播层/残差连接/输出
:param src_key_padding_mask: 输入句子的填充部分做掩盖处理
:param attn_mask: 注意力的掩码,一般在解码部分为了掩盖后续position需要使用
:param training: 是否训练模式
:param drop: 注意力层weights输出的drop
:param src_sentence: 填充后的原始句子
:return: 编码层的输出, 解码层的部分输入
"""
# input_embedding = self.input_embedding(src_sentence)
input_embedding = src_sentence
attn_encoder = self.attn_encoder(input_embedding, input_embedding, input_embedding, drop_p=drop,
training=training, attn_mask=attn_mask, key_padding_mask=src_key_padding_mask)[0]
# add & norm 残差连接后归一化处理,归一化防止数值过大后续训练时候造成梯度丢失或爆炸
embedding_attn = input_embedding + self.drop_out1(attn_encoder)
attn_out = self.norm1(embedding_attn)
attn_out = self.activation(attn_out)
# 前馈连接,Feed_Forward层
feed_forward = self.feedforward(attn_out)
# Feed_Forward层后的残差连接+归一化
attn_feed = attn_encoder + self.drop_out2(feed_forward)
encoder_layer_out = self.norm2(attn_feed)
return encoder_layer_out
Encoder多层编码块/前馈网络层
多个编码层的实现
class Encoder(nn.Module):
def __init__(self, embed_dim, n_head, feedforward_dim, drop_fc, drop_attn, drop_feed, n_layers):
super(Encoder, self).__init__()
self.layers = nn.ModuleList([EncoderLayer(embed_dim=embed_dim, n_head=n_head, feedforward_dim=feedforward_dim,
drop_fc=drop_fc, drop_attn=drop_attn, drop_feed=drop_feed)
for _ in range(n_layers)])
def forward(self, src_sentence, drop, training=True, src_mask=None, src_key_padding_mask=None):
"""
:param drop:
:param training:
:param src_sentence: 嵌入向量的输入
:param src_mask: 一般只在解码时使用,为了并行一次喂入所有解码部分的输入,所以要用mask来进行掩盖当前时刻之后的位置信息
:param src_key_padding_mask: 编码部分输入的padding情况,形状为 [batch_size, src_len]
:return:
"""
encoder_out = src_sentence
for layer in self.layers:
encoder_out = layer(src_sentence, training=training, drop=drop, attn_mask=src_mask,
src_key_padding_mask=src_key_padding_mask)
return encoder_out
class PositionWiseFeedForward(nn.Module):
def __init__(self, drop_fc=None, dim_model=512, dim_feedforward=2048):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(dim_model, dim_feedforward)
self.fc2 = nn.Linear(dim_feedforward, dim_model)
self.relu = nn.ReLU()
self.drop = nn.Dropout(drop_fc)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.drop(x)
x = self.fc2(x)
return x
DecoderLayer解码层
单个解码层的实现
需要与Encoder层进行交互
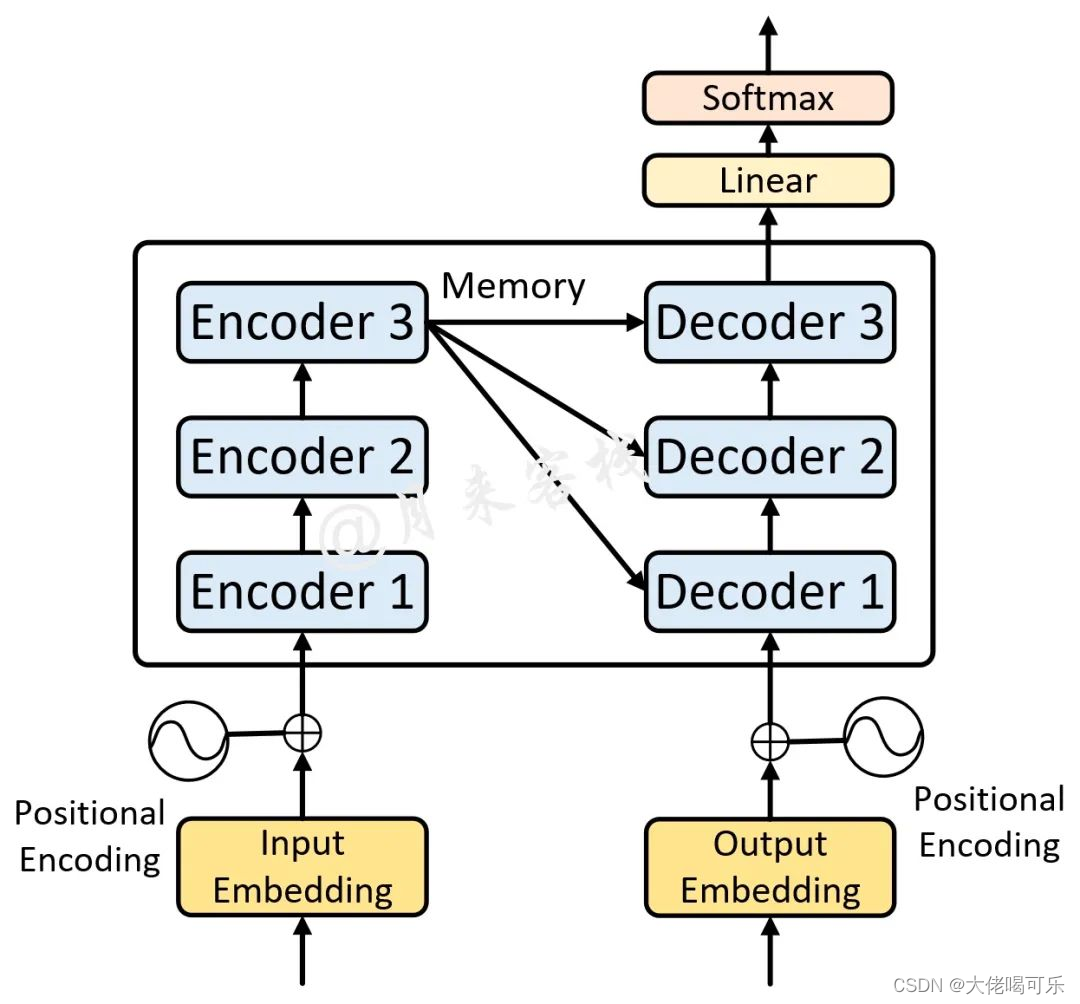
class DecoderLayer(nn.Module):
def __init__(self, embed_dim, feedforward_dim, n_head, drop_fc, drop_mask_attn, drop_attn, drop_feed, bias=True):
"""
解码层:输入嵌入+位置编码-->带掩码的多头注意力-->与编码交互的多头注意力-->前馈网络
:param embed_dim: 嵌入维度:512
:param feedforward_dim: 前馈网络的隐层维度:2048
:param n_head: 多头注意力头数:8 512//64=8 d_model//batch_size=n_head
:param drop_fc: 前馈网络中隐层输出的随机丢弃比例
:param drop_mask_attn: 带掩码的多头注意力层输出
:param drop_attn: 与编码交互的多头注意力层输出
:param drop_feed: 前馈网络层输出
:param bias: 多头注意力层线性输出时候是否加偏置
"""
super(DecoderLayer, self).__init__()
# self.out_embedding =
# TransformerEmbedding(vocab_size=2048, d_model=512, drop=0.1, drop_prob=0.1, max_len=None, device='cpu')
self.attn = MultiHeadAttention(dim_model=embed_dim, n_head=n_head, bias=bias)
self.mask_attn = MultiHeadAttention(dim_model=embed_dim, n_head=n_head, bias=bias)
self.fc = PositionWiseFeedForward(dim_model=embed_dim, drop_fc=drop_fc, dim_feedforward=feedforward_dim)
# mask_attention层
self.drop1 = nn.Dropout(drop_mask_attn)
# encoder_decoder_attention层
self.drop2 = nn.Dropout(drop_attn)
# 前馈网络层
self.drop3 = nn.Dropout(drop_feed)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
self.norm3 = nn.LayerNorm(embed_dim)
self.activation = nn.ReLU()
def forward(self, tgt, memory, drop=None, tgt_mask=None, memory_mask=None,
tgt_key_padding_mask=None, memory_key_padding_mask=None):
"""
:param drop:
:param memory_mask: 编码器-解码器交互时的注意力掩码,一般为None
:param tgt_mask: 注意力机制中的掩码矩阵,用于掩盖当前position之后的信息, [tgt_len, tgt_len]
:param memory: 编码部分的输出(memory), [src_len,batch_size,embed_dim]
:param tgt: 解码部分的输入,形状为 [tgt_len,batch_size, embed_dim]
:param tgt_key_padding_mask:解码部分输入的padding情况,形状为 [batch_size, tgt_len],填充词的掩码
:param memory_key_padding_mask: 编码部分输入的padding情况,形状为 [batch_size, src_len]
:return:
"""
# out_embedding = self.out_embedding(tgt_sentence)
# out_embedding = tgt_sentence
# MultiHeadAttention返回: attn_out_linear, attn_concat, attn_weights
mask_attn = self.mask_attn(tgt, tgt, tgt, drop_p=drop, training=True,
attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0]
mask_out = self.norm1(tgt + self.drop1(mask_attn))
self_attn = self.attn(tgt, key=memory, value=memory, drop_p=drop, training=True,
attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0]
attn_out = self.norm2(mask_out + self.drop2(self_attn))
attn_out = self.activation(attn_out)
feed_forward = self.fc(attn_out)
decoder_out = self.norm3(attn_out+self.drop3(feed_forward))
return decoder_out
Decoder多层解码块
多个解码层的实现
class Decoder(nn.Module):
def __init__(self, n_layers, embed_dim, feedforward_dim, n_head, drop_fc,
drop_mask_attn, drop_attn, drop_feed, bias=True):
super(Decoder, self).__init__()
self.layers = nn.ModuleList([DecoderLayer(embed_dim=embed_dim, feedforward_dim=feedforward_dim, n_head=n_head,
drop_fc=drop_fc, drop_mask_attn=drop_mask_attn, drop_attn=drop_attn,
drop_feed=drop_feed, bias=bias) for _ in range(n_layers)])
def forward(self, tgt_sentence, memory, drop, tgt_mask=None, memory_mask=None, tgt_key_padding_mask=None,
memory_key_padding_mask=None):
decoder_out = tgt_sentence
for layer in self.layers:
decoder_out = layer(tgt_sentence, memory, drop=drop, tgt_mask=tgt_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask, memory_mask=None)
return decoder_out
if __name__ == '__main__':
src_len = 5
batch_size = 2
d_model = 32
num_head = 1
n_layer = 6
src = torch.rand(([batch_size, src_len, d_model]))
encoder = Decoder(n_layers=n_layer, embed_dim=d_model, feedforward_dim=2048, n_head=num_head, drop_fc=0.1,
drop_mask_attn=0.1, drop_attn=0.1, drop_feed=0.1, bias=True)
print(encoder)
MyTransformer实现完整的Transformer框架
import torch
import torch.nn as nn
import torch.nn.functional as F
from TransformerEmbedding import TransformerEmbedding
from EncoderLayer import Encoder
from DecoderLayer import Decoder
class MyTransformer(nn.Module):
def __init__(self, src_vocab_size, src_max_len, tgt_vocab_size, tgt_max_len, embed_dim, feedforward_dim, n_head,
drop_prob, n_layers):
super(MyTransformer, self).__init__()
self.src_embedding = TransformerEmbedding(vocab_size=src_vocab_size, max_len=src_max_len, d_model=embed_dim,
drop=drop_prob, device='cpu')
self.tgt_embedding = TransformerEmbedding(vocab_size=tgt_vocab_size, max_len=tgt_max_len, d_model=embed_dim,
drop=drop_prob, device='cpu')
self.encoder = Encoder(embed_dim=embed_dim, n_head=n_head, feedforward_dim=feedforward_dim, n_layers=n_layers,
drop_fc=drop_prob, drop_attn=drop_prob, drop_feed=drop_prob)
self.decoder = Decoder(embed_dim=embed_dim, feedforward_dim=feedforward_dim, n_head=n_head, n_layers=n_layers,
drop_fc=drop_prob, drop_mask_attn=drop_prob, drop_attn=drop_prob, drop_feed=drop_prob)
# self.fc = nn.Linear(drop_prob)
def forward(self, src, tgt, drop_prob, training=True, src_mask=None, tgt_mask=None,
src_key_padding_mask=None, tgt_key_padding_mask=None):
src_embedding = self.src_embedding(src)
tgt_embedding = self.tgt_embedding(tgt)
memory = self.encoder(src_embedding, drop=drop_prob, training=training,
src_key_padding_mask=src_key_padding_mask)
# print(src_embedding.shape, tgt_embedding.shape, memory.shape)
print('编码完成------------------------------')
decoder = self.decoder(tgt_embedding, memory, drop=drop_prob, tgt_mask=tgt_mask,
tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=src_key_padding_mask)
print('解码完成')
return decoder
def init_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def generate_square_subsequent_mask(self, s_z):
mask = torch.tril(torch.ones(s_z, s_z)).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0.0, float('-inf')).masked_fill(mask == 1.0, float('-inf'))
return mask
if __name__ == '__main__':
Input = [[1, 2, 3, 4], [5, 6, 2], [1, 7, 8, 9, 10, 11, 12, 13, 14, 15]]
output = [[1, 1, 2, 3, 4], [5, 5, 6, 2], [1, 7, 7, 8, 9, 10, 11, 12, 13, 14, 15]]
# 有三个句子[['你 好 世 界'], ['我 很 好'], ['你 不 是 真 正 的 快 乐']]
# 句子长度不一致进行padding处理
src_sentence = torch.tensor([])
for i in range(len(Input)):
src_sen = torch.tensor([Input[i]])
src_sen = F.pad(src_sen, (0, len(Input[2]) - len(Input[i])), 'constant', 0)
src_sentence = torch.cat([src_sentence, src_sen], dim=0)
# x = src_sentence.unsqueeze(dim=0)
tgt_sentence = torch.tensor([])
for i in range(len(output)):
src_sen = torch.tensor([output[i]])
src_sen = F.pad(src_sen, (0, len(output[2]) - len(output[i])), 'constant', 0)
tgt_sentence = torch.cat([tgt_sentence, src_sen], dim=0)
src_len = 10
batch_size = 3
dmodel = 32
tgt_len = 11
num_head = 8
# src = torch.rand((src_len, batch_size, dmodel)) # shape: [src_len, batch_size, embed_dim]
# src_key_padding_mask = torch.tensor([[True, True, True, False, False],
# [True, True, True, True, False]]) # shape: [batch_size, src_len]
#
# tgt = torch.rand((tgt_len, batch_size, dmodel)) # shape: [tgt_len, batch_size, embed_dim]
# tgt_key_padding_mask = torch.tensor([[True, True, True, False, False, False],
# [True, True, True, True, False, False]]) # shape: [batch_size, tgt_len]
my_transformer = MyTransformer(src_vocab_size=5000, src_max_len=10, tgt_vocab_size=5000, tgt_max_len=11, embed_dim=32,
feedforward_dim=2048, n_head=8, drop_prob=0.1, n_layers=6)
tgt_mask = my_transformer.generate_square_subsequent_mask(tgt_len)
out = my_transformer(src=src_sentence, tgt=tgt_sentence, drop_prob=0.1, tgt_mask=tgt_mask,
src_key_padding_mask=src_sentence,
tgt_key_padding_mask=tgt_sentence)
print(out.shape)
# torch.Size([3, 11, 32])
文章来源:https://blog.csdn.net/weixin_44322171/article/details/135112041
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!