comfyui使用
按住鼠标拖动,滚动中建缩放。
如果你搞砸了,只需点击 Load Default 菜单将其重置为初始状态即可。
双击界面弹出节点搜索框
通过单击右下角 Queue Prompt 菜单,或按 Ctrl + Enter来启动工作流。
将comfyui生成的图像或者json文件,拖到界面中,或者点击右下角的load,即可加载工作流。
借助基于节点的界面,您可以构建由数十个节点组成的工作流,从而实现一些非常整洁的图像生成管道。
请找到名为 extra_model_paths.yaml.example 的文件,将其重命名为 extra_model_paths.yaml,在里面指定模型文件的位置。
节点:
节点的基本结构,就是若干个输入输出。
若干个节点就组成了一张网,实际上就是数据结构里面的图,完成我们的图像生成任务。
核心节点:
模型加载器,包括主模型即stable diffusion,以及其它各种模型,clip什么扩展模型加载节点
条件控制节点:包括文本提示,controlNet, mask等
Image节点
潜变量
采样器
安装好模型之后,点击refresh 刷新,不用重启
了解您需要下载哪些模型的最佳方法是打开 ComfyUI Manager 并继续“安装模型”部分。在这里,您将找到每个节点需要或建议下载的所有模型的列表。
一些其它相关的算法
Ground DINO
Grounding DINO可以根据文字描述检测指定目标。
当Grounding DINO和stable diffusion结合时,就会出现更加神奇的功能–自动P图。如下图右侧,你告诉它:“将左侧的狮子变成狗”,它就会帮你把左边的狮子P成狗。

Grounding DINO的整体结构如下图所示。Grounding DINO是一个双encoder单decoder结构,它包含了一个image backbone用于提取image feature、一个text backbone用于提取text feature、一个feature enhancer用于融合image和text feature、一个language-guide query selection模块用于query初始化、一个cross-modality decoder用于bbox预测。
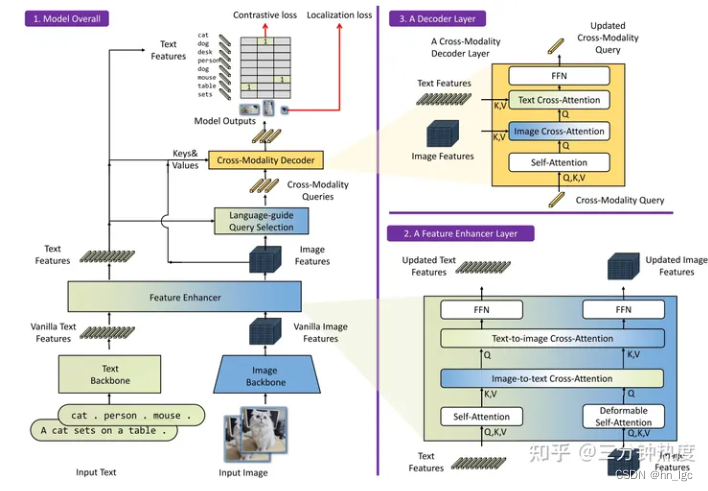
GroundDino Sam
来源 https://github.com/IDEA-Research/Grounded-Segment-Anything?tab=readme-ov-file
官方介绍 将 Grounding-DINO 与 Segment Anything & Stable Diffusion 相结合,并识别任何内容 - 自动检测、分割和生成任何内容。
首先结合GroundDino和sam,就是通过语言分割任何物品。但是sam本来就有根据文本检测的功能,但是sam的文本提示应该是clip,估计提示能力不够强,使用GroundDino效果的更强吧。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 企业数字化转型如何影响企业 ESG 表现 —来自中国上市公司的证据(数据复现+代码)
- 单因素重复测量方差分析原理和SAS代码实现
- MMWave API
- 网络安全(黑客)——自学2024
- websocket介绍并模拟股票数据推流
- 【AI】人类视觉感知特性与深度学习模型(2/2)
- 系分笔记数据库反规范化、SQL语句和大数据
- Postman —— HTTP请求基础组成部分
- Angular系列教程之模板语法
- 怎么制作一款简单的小游戏?