Scrapy爬虫在新闻数据提取中的应用
发布时间:2024年01月24日
Scrapy是一个强大的爬虫框架,广泛用于从网站上提取结构化数据。下面这段代码是Scrapy爬虫的一个例子,用于从新闻网站上提取和分组新闻数据。
使用场景
在新闻分析和内容聚合的场景中,收集和组织新闻数据是常见需求。例如,如果我们需要为用户提供按日期分类的新闻更新,或者我们想分析特定时间段内的新闻趋势,这段代码就非常适合。
页面截图

结构截图
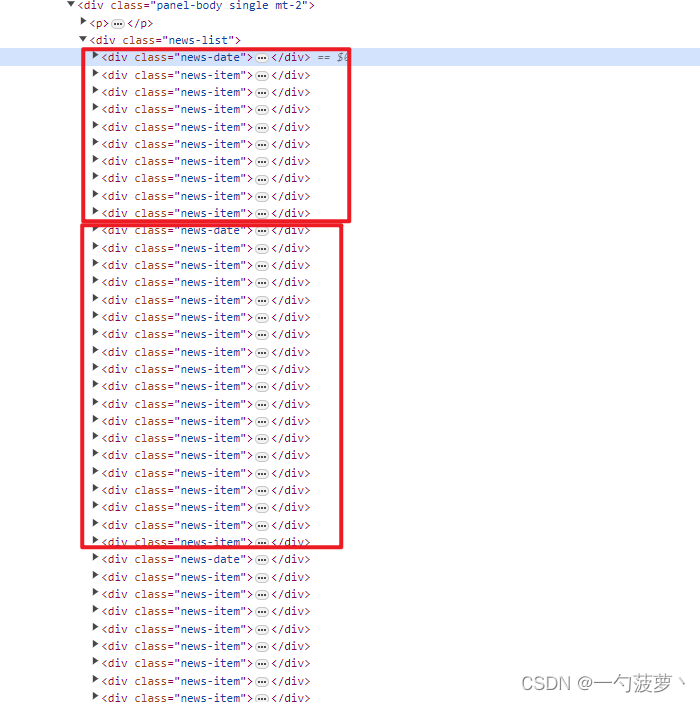
代码注释解释
# Scrapy爬虫的parse方法,用于处理响应并提取信息
def parse(self, resp, **kwargs):
grouped_news_items = [] # 存储所有分组的新闻条目
children = resp.xpath('//div[@class="news-list"]/*') # 获取新闻列表中的所有子元素
current_group = [] # 当前日期下的新闻条目集合
current_date = None # 当前新闻条目的日期
# 遍历新闻列表中的每个子元素
for child in children:
# 如果子元素是日期标签,更新current_date并将之前的新闻组添加到grouped_news_items
if 'news-date' in child.xpath('@class').get(''):
if current_group:
grouped_news_items.append((current_date, current_group))
current_group = []
current_date = child.xpath('normalize-space(text())').get()
# 如果子元素是新闻条目,提取相关信息并添加到current_group
elif 'news-item' in child.xpath('@class').get(''):
news_info = {
'title': child.xpath('./div/h2/a/text()').extract_first(), # 新闻标题
'link': child.xpath('./div/h2/a/@href').extract_first(), # 新闻链接
'source_name': child.xpath('./div/p/span/text()').extract()[1].strip(), # 来源名称
'source_img': child.xpath('./div/p/span/img/@data-src').extract_first() # 来源图标
}
current_group.append(news_info)
# 将最后一个日期的新闻条目集合添加到grouped_news_items
if current_group:
grouped_news_items.append((current_date, current_group))
# 生成Scrapy Item,并通过yield返回
for date, items in grouped_news_items:
for item in items:
an = AiNewsItem() # Scrapy Item对象,用于存储新闻信息
an['time_str'] = date
an['title'] = item['title']
an['source_name'] = item['source_name']
an['source_img'] = item['source_img']
an['link'] = item['link']
yield an
文章来源:https://blog.csdn.net/weixin_39973810/article/details/135828061
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AntDesignBlazor示例——分页查询
- PyQt5统计图生成
- 落实这关键的四点,企业才能真正做到数据安全交换
- HarmonyOS自定义弹出对话框CustomDialog并传递变量
- git设置代理
- 加法器原理详解
- hadoop集群环境搭建
- uniapp-使用返回的base64转换成图片
- ChatGPT在地学、GIS、气象、农业、生态、环境等领域中的高级应用
- 《剑指 Offer》专项突破版 - 面试题 16 : 不含重复字符的最长子字符串(C++ 实现)