loTDB数据库学习笔记之初识 —— 筑梦之路
loTDB简介
IoTDB 是针对时间序列数据收集、存储与分析一体化的数据管理引擎。具有体量轻、性能高、易使用的特点,适用于工业物联网应用中海量时间序列数据高速写入和复杂分析查询的需求,同时包含数据订阅、数据同步、负载均衡和运维监控功能。
由清华大学软件学院设计开发。
不同数据库比较?
 ?
?
?loTDB主要功能特点
IoTDB 具有以下特点:
- 灵活的部署方式
- 云端一键部署
- 终端解压即用
- 终端-云端无缝连接(数据云端同步工具)
- 低硬件成本的存储解决方案
- 高压缩比的磁盘存储
- 无损压缩比可达 20:1以上
- 10 亿数据点硬盘成本低于 1.4 元
- 目录结构的时间序列组织管理方式
- 支持复杂结构的智能网联设备的时间序列组织(多层树形结构,层级数量无限制)
- 支持大量同类物联网设备的时间序列组织
- 可用模糊方式对海量复杂的时间序列目录结构进行检索
- 高通量的时间序列数据读写
- 支持百万级低功耗强连接设备数据接入(海量)
- 支持智能网联设备数据高速读写(高速)
- 以及同时具备上述特点的混合负载
- 面向时间序列的丰富查询语义
- 跨设备、跨传感器的时间序列时间对齐
- 面向时序数据特征的计算
- 提供面向时间维度的丰富聚合函数支持
- 极低的学习门槛
- 支持类 SQL 的数据操作
- 提供 JDBC 的编程接口
- 完善的导入导出工具
- 完美对接开源生态环境
- 支持开源数据分析生态系统:Hadoop、Spark
- 支持开源可视化工具对接:Grafana
- 统一的数据访问模式
- 无需进行分库分表处理
- 无需区分实时库和历史库
- 高可用性支持
- 支持HA分布式架构,系统提供7*24小时不间断的实时数据库服务
- 应用访问系统,可以连接集群中的任何一个节点进行
- 一个物理节点宕机或网络故障,不会影响系统的正常运行
- 物理节点的增加、删除或过热,系统会自动进行计算/存储资源的负载均衡处理
- 支持异构环境,不同类型、不同性能的服务器可以组建集群,系统根据物理机的配置,自动负载均衡
- 知识产权及国产化支持
- 具有自主知识产权
- 支持龙芯、飞腾、鲲鹏等国产CPU
- 支持中标麒麟、银河麒麟、统信、凝思等国产服务器操作系统
loTDB系统架构
?
在上图中,用户可以通过 JDBC 将来自设备上传感器采集的时序数据、服务器负载和 CPU 内存等系统状态数据、消息队列中的时序数据、应用程序的时序数据或者其他数据库中的时序数据导入到本地或者远程的 IoTDB 中。用户还可以将上述数据直接写成本地(或位于 HDFS 上)的 TsFile 文件。
可以将 TsFile 文件写入到 HDFS 上,进而实现在 Hadoop 或 Spark 的数据处理平台上的诸如异常检测、机器学习等数据处理任务。
对于写入到 HDFS 或者本地的 TsFile 文件,可以利用 TsFile-Hadoop 或 TsFile-Spark 连接器允许 Hadoop 或 Spark 进行数据处理。
对于分析的结果,可以写回成 TsFile 文件。
IoTDB 和 TsFile 还提供了相应的客户端工具,满足用户查看和写入数据的 SQL 形式、脚本形式和图形化形式等多种需求。
IoTDB 提供了单机部署和集群部署两种模式。在集群部署模式下,IoTDB支持自动故障转移,确保系统在节点故障时能够快速切换到备用节点。切换时间可以达到秒级,从而最大限度地减少系统中断时间,且可保证切换后数据不丢失。当故障节点恢复正常,系统会自动将其重新纳入集群,确保集群的高可用性和可伸缩性。
IoTDB还支持读写分离模式部署,可以将读操作和写操作分别分配给不同的节点,从而实现负载均衡和提高系统的并发处理能力。
通过这些特性,IoTDB能够避免单点性能瓶颈和单点故障(SPOF),提供高可用性和可靠性的数据存储和管理解决方案。
loTDB性能特点
数据库连接
- 支持高并发连接,单台服务器可支持数万次并发连接/秒。
数据库读写性能
- 具备高写入吞吐的特点,单核处理写入请求大于数万次/秒,单台服务器写入性能达到数千万点/秒;集群可线性扩展,集群的写入性能可达数亿点/秒。
- 具备高查询吞吐、低查询延迟的特点,单台服务器支持数千万点/秒查询吞吐,可在毫秒级聚合百亿数据点。
存储性能
- 支持存储海量数据,具备PB级数据的存储和处理能力。
- 支持高压缩比,无损压缩能够达到20倍压缩比,有损压缩能够达到100倍压缩比。
测试工具:IoT-benchmark
loTDB应用场景
车联网

车辆数据基于TCP和工业协议编码后发送至边缘网关,网关将数据发往消息队列Kafka集群,解耦生产和消费两端。Kafka将数据发送至Flink进行实时处理,处理后的数据写入IoTDB中,历史数据和最新数据均在IoTDB中进行查询,最后数据通过API流入可视化平台等进行应用。?
智能运维
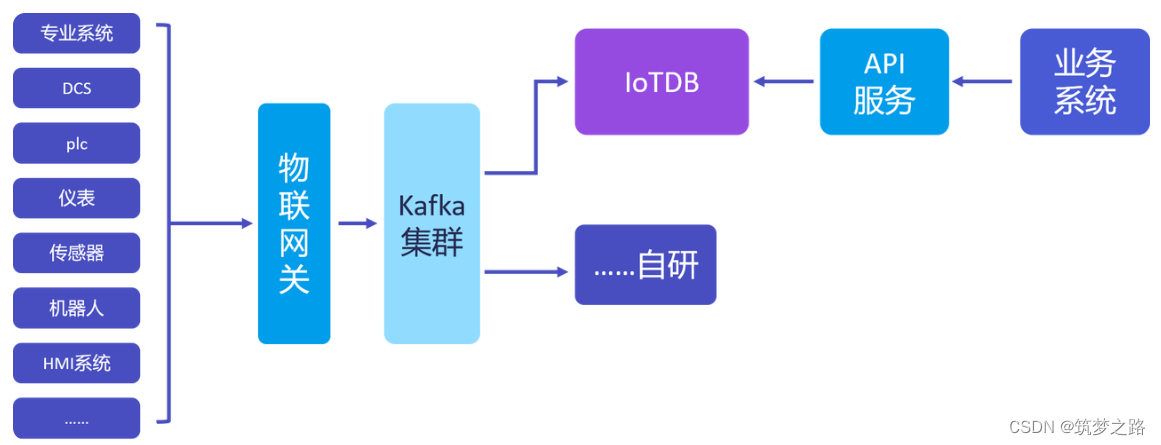 ?智能工厂
?智能工厂

工况监控

更多详细内容请阅读官方网站:IoTDB 简介 | IoTDB Website?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Django 安装
- 【C++类与对象】继承
- getWriter() has already been called for this response
- 解析消费增值----化妆品行业如何簇拥新电商,成就破亿销量
- 安装完虚拟机系统进行初始化设置
- 【UE Niagara】网格体渲染器初识
- 5 个让日常编码更简单的 Python 库
- 乐乐的图形
- Java的HashMap源码解析和实现原理如下:(具体解释了put方法)
- ruoyi-cloud—若依微服务打包部署