14.1 Linux 并发与竞争
一、并发与竞争
??并发:多个执行单元同时、并行执行。
??竞争:并发的执行单元同时访问共享资源(硬件资源和软件上的全局变量等)易导致竞态。
二、原子操作
1. 原子操作简介
??原子操作:不能再进一步分割的操作,一般用于变量或位操作。
??例如在 C 语言中对 无符号整型变量 a 赋值:
a = 3;??但 C 语言要先编译成汇编语言,ARM 架构不支持直接对寄存器(内存)进行读写操作,要借助寄存器 R0、 R1 等来完成赋值操作。假设变量 a 的地址为 0X3000000 ,汇编代码如下:
ldr r0, =0X30000000 // 将变量a的地址加载到寄存器r0中
ldr r1, = 3 // 写入变量a的值加载到寄存器r1中
str r1, [r0] // 将寄存器r1中的值3写入到变量a的地址所指向的内存中??现在假设线程 A要向 a 变量写入 10 这个值,而线程 B 也要向 a 变量写入 20 这个值,理想情况是这样:

??实际执行流程可能情况是这样:
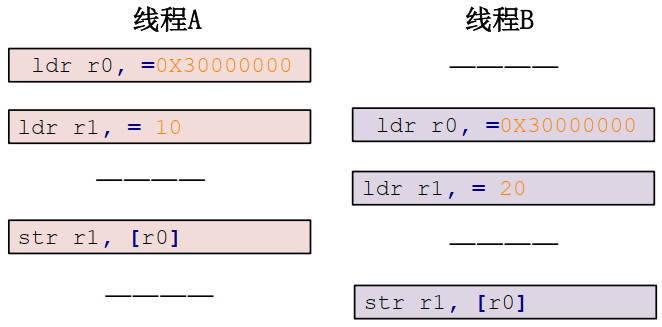
??这算一个简单的并发与竞争的例子。要解决这个问题就需要把这三行汇编指令作为一个整体运行,也就是一个原子。
2. 原子整形操作 API 函数?
??Linux 内核定义了叫做 atomic_t 的结构体来完成整形数据的原子操作,在使用中用原子变量来代替整形变量,如果要使用原子操作 API 函数,首先要先定义一个 atomic_t 的变量:
atomic_t a;
// 也可以在定义原子变量的时候给原子变量赋初值
atomic_t b = ATOMIC_INIT(0); // 定义原子变量,b赋初值为0。ATOMIC_INIT就是给原子赋初值用的??以下是操作 API 函数:
| 函数 | 描述 |
| ATOMIC_INIT(int i) | 定义原子变量的时候对其初始化。 |
| int atomic_read(atomic_t *v) | 读取 v 的值,并且返回。 |
| void atomic_set(atomic_t *v, int i) | 向 v 写入 i 值。 |
| void atomic_add(int i, atomic_t *v) | 给 v 加上 i 值。 |
| void atomic_sub(int i, atomic_t *v) | 从 v 减去 i 值。 |
| void atomic_inc(atomic_t *v) | 给 v 加 1,也就是自增。 |
| void atomic_dec(atomic_t *v) | 从 v 减 1,也就是自减 |
| int atomic_dec_return(atomic_t *v) | 从 v 减 1,并且返回 v 的值。 |
| int atomic_inc_return(atomic_t *v) | 给 v 加 1,并且返回 v 的值。 |
| int atomic_sub_and_test(int i, atomic_t *v) | 从 v 减 i,如果结果为 0 就返回真,否则返回假 |
| int atomic_dec_and_test(atomic_t *v) | 从 v 减 1,如果结果为 0 就返回真,否则返回假 |
| int atomic_inc_and_test(atomic_t *v) | 给 v 加 1,如果结果为 0 就返回真,否则返回假 |
| int atomic_add_negative(int i, atomic_t *v) | 给 v 加 i,如果结果为负就返回真,否则返回假 |
??如果使用 64 位的 SOC 的话,就要使用 64 位的原子变量,atomic64_t ,并且以上 API 函数都要换成 64 位的。
??原子变量和相应的 API 函数举例:
atomic_t v = ATOMIC_INIT(0); /* 定义并初始化原子变零 v=0 */
atomic_set(&v, 10); /* 设置 v=10 */
atomic_read(&v); /* 读取 v 的值,肯定是 10 */
atomic_inc(&v); /* v 的值加 1, v=11 */3. 原子位操作 API 函数?
??原子位操作是直接对内存进行操作,API 函数如下表:
| 函数 | 描述 |
| void set_bit(int nr, void *p) | 将 p 地址的第 nr 位置 1。 |
| void clear_bit(int nr,void *p) | 将 p 地址的第 nr 位清零。 |
| void change_bit(int nr, void *p) | 将 p 地址的第 nr 位进行翻转。 |
| int test_bit(int nr, void *p) | 获取 p 地址的第 nr 位的值。 |
| int test_and_set_bit(int nr, void *p) | 将 p 地址的第 nr 位置 1,并且返回 nr 位原来的值。 |
| int test_and_clear_bit(int nr, void *p) | 将 p 地址的第 nr 位清零,并且返回 nr 位原来的值。 |
| int test_and_change_bit(int nr, void *p) | 将 p 地址的第 nr 位翻转,并且返回 nr 位原来的值。 |
三、自旋锁
1. 自旋锁简介
??原子操作只能对整形变量或者位进行保护,太过简单。设备结构体变量不是整形变量,我们也要对结构体成员保证原子性,在线程 A 对结构体使用期间,应禁止其他线程来访问此结构体变量,这就是自旋锁。
??当一个线程要访问某个共享资源的时候首先要先获取相应的锁,锁只能被一个线程持有,只要此线程不释放持有的锁,那么其他的线程就不能获取此锁。如果自旋锁正在被线程 A 持有,线程 B 想要获取自旋锁,那么线程 B 就会处于忙循环-旋转-等待状态, 线程 B 回一直等待锁可用。
??自旋锁的“自旋”也就是“原地打转”的意思,“原地打转”的目的是为了等待自旋锁可以用,可以访问共享资源。 这也看出自旋锁有一个缺点:等待自旋锁的线程会一直处于自旋状态,这样会浪费处理器时间,降低系统性能,所以自旋锁的持有时间不能太长。自旋锁适用于短时期的轻量级加锁,如果遇到需要长时间持有锁的场景那就需要换其他的方法了。
??Linux 内核使用结构体 spinlock_t 表示自旋锁,使用自旋锁得先定义一个自旋锁变量。
spinlock_t lock;2. 自旋锁 API 函数
| 函数 | 描述 |
| DEFINE_SPINLOCK(spinlock_t lock) | 定义并初始化一个自选变量。 |
| int spin_lock_init(spinlock_t *lock) | 初始化自旋锁。 |
| void spin_lock(spinlock_t *lock) | 获取指定的自旋锁,也叫做加锁。 |
| void spin_unlock(spinlock_t *lock) | 释放指定的自旋锁。 |
| int spin_trylock(spinlock_t *lock) | 尝试获取指定的自旋锁,如果没有获取到就返回 0 |
| int spin_is_locked(spinlock_t *lock) | 检查指定的自旋锁是否被获取,如果没有被获取就 返回非 0,否则返回 0。 |
??自旋锁 API 适用于线程与线程之间, 自旋锁保护的临界区(临界区就是共享数据段 )一定不能调用任何能够引起睡眠和阻塞的API 函数,否则回导致死锁现象出现。自旋锁会自动禁止抢占,也就说当线程 A 得到锁以后会暂时禁止内核抢占。如果线程 A 在持有锁期间进入了休眠状态,那么线程 A 会自动放弃 CPU 使用权。线程 B 开始运行,线程 B 也想要获取锁,但是此时锁被 A 线程持有,而且内核抢占还被禁止了!线程 B 无法被调度出去,那么线程 A 就无法运行,锁也就无法释放, 这就是死锁。
??在线程之间并发访问的时候,中断也想访问共享资源。中断里也能使用自旋锁,但在中断里面使用自旋锁的时候,获取锁之前需要禁止本地中断(本CPU中断),否则可能发生死锁。
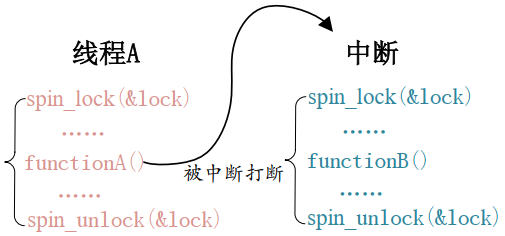
??上图中,线程 A 抢先一步抢走 lock 锁,当线程 A 运行到 functionA 的时候,中断发生,中断抢走了 CPU 使用权,右边的中断也要这个 lock 这个锁,但这个线程会一直被线程 A 所占有,中断一直自旋,等待锁有效,死锁发生。
??最好的解决办法就是获取锁之前关闭本地中断,Linux 提供了相应的 API 函数:
| 函数 | 描述 |
| void spin_lock_irq(spinlock_t *lock) | 禁止本地中断,并获取自旋锁。 |
| void spin_unlock_irq(spinlock_t *lock) | 激活本地中断,并释放自旋锁。 |
| void spin_lock_irqsave(spinlock_t *lock, unsigned long flags) | 保存中断状态,禁止本地中断,并获取自旋锁。 |
| void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags) | 将中断状态恢复到以前的状态,并且激活本地中断, 释放自旋锁。 |
???建议使用 spin_lock_irqsave/ spin_unlock_irqrestore 函数,因为这两个函数会保存中断状态,在释放锁的时候恢复中断状态。一般在线程中使用 spin_lock_irqsave/spin_unlock_irqrestore,在中断中使用 spin_lock/spin_unlock?,示例代码如下:
spinlock_t lock; // 定义一个自旋锁
DEFINE_SPINLOCK(lock) /* 定义并初始化一个锁 */
/* 线程 A */
void functionA (){
unsigned long flags; /* 中断状态 */
spin_lock_irqsave(&lock, flags) /* 获取锁 */
/* 临界区 */
spin_unlock_irqrestore(&lock, flags) /* 释放锁 */
}
/* 中断服务函数 */
void irq() {
spin_lock(&lock) /* 获取锁 */
/* 临界区 */
spin_unlock(&lock) /* 释放锁 */
}3. 自旋锁使用注意事项
??1、因为在等待自旋锁的时候处于“自旋”状态,因此锁的持有时间不能太长,一定要短,否则的话会降低系统性能。如果临界区比较大,运行时间比较长的话要选择其他的并发处理方式,比如信号量和互斥体。
??2、自旋锁保护的临界区内不能调用任何可能导致线程休眠的 API 函数,否则的话可能导致死锁。
??3、不能递归申请自旋锁,因为一旦通过递归的方式申请一个你正在持有的锁,那么你就必须“自旋”,等待锁被释放,然而你正处于“自旋”状态,根本没法释放锁。?
??4、在编写驱动程序的时候我们必须考虑到驱动的可移植性,因此不管你用的是单核的还是多核的 SOC,都将其当做多核 SOC 来编写驱动程序。?
四、信号量
1. 信号量简介
??信号量是同步的一种方式,信号量也常常用于控制对共享资源的访问。 比如有一个能停 100 辆车的停车场,停车数量就是信号量,如果信号满了,需要有车开出来,信号量-1,你再开进去,信号量+1,这就是计数型信号量。
??相比于自旋锁,信号量可以使线程进入休眠状态。比如 A 和 B合租房子,A先去了厕所,过一会B也想上,B一直等着就是自旋锁,B说你完了喊我,B之后回去睡觉,这是信号量。信号量特点:
??① 因为信号量可以使等待资源线程进入休眠状态,因此适用于那些占用资源比较久的场合。?
??② 因此信号量不能用于中断中,因为信号量会引起休眠,中断不能休眠。?
??③ 如果共享资源的持有时间比较短,那就不适合使用信号量了,因为频繁的休眠、切换线程引起的开销要远大于信号量带来的那点优势。?
??通过信号量控制访问资源的线程数,在初始化的时候将信号量值设置的大于 1,那么这个信号量就是计数型信号量,计数型信号量不能用于互斥访问,因为它允许多个线程同时访问共享资源。如果要互斥的访问共享资那么信号量的值就不能大于 1,此时的信号量就是一个二值信号量(只能取0和1)。?
2. 信号量 API 函数
??Linux 内核使用 semaphore 结构体表示信号量,结构体内容如下所示:?
struct semaphore {
raw_spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};??使用信号量之前先定义,然后再初始化信号量。信号量相关 API 函数如下:
| 函数 | 描述 |
| DEFINE_SEAMPHORE(name) | 定义一个信号量,并且设置信号量的值为 1。 |
| void sema_init(struct semaphore *sem, int val) | 初始化信号量 sem,设置信号量值为 val。 |
| void down(struct semaphore *sem) | 获取信号量,因为会导致休眠,因此不能在中断中使用。 |
| int down_trylock(struct semaphore *sem); | 尝试获取信号量,如果能获取到信号量就获 取,并且返回 0。如果不能就返回非 0,并且 不会进入休眠。 |
| int down_interruptible(struct semaphore *sem) | 获取信号量,和 down 类似,只是使用 down 进入休眠状态的线程不能被信号打断。而使用此函数进入休眠以后是可以被信号打断的。 |
| void up(struct semaphore *sem) | 释放信号量 |
??使用方式如下:
struct semaphore sem; /* 定义信号量 */
sema_init(&sem, 1); /* 初始化信号量,并把sem设为1 */
down(&sem); /* 申请信号量 */
/* 临界区 */
up(&sem); /* 释放信号量 */五、互斥体
1. 互斥体简介
??将信号量的值设置为 1 就可以使用信号量进行互斥访问了,虽然可以通过信号量实现互斥,但是 Linux 提供了一个比信号量更专业的机制来进行互斥,它就是互斥体—mutex。互斥访问表示一次只有一个线程可以访问共享资源,不能递归申请互斥体。编写 Linux 驱动的时候遇到需要互斥访问的地方建议使用 mutex。 Linux 内核使用 mutex 结构体表示互斥体。
??使用 mutex 之前需要定义 mutex 变量,使用 mutex 注意以下几点:
??① mutex 可以导致休眠,因此不能在中断中使用 mutex,中断中只能使用自旋锁。?
??② 和信号量一样, mutex 保护的临界区可以调用引起阻塞(一个线程由于某种原因无法继续执行,并进入等待状态的情况)的 API 函数。
??③ 因为一次只有一个线程可以持有 mutex,因此,必须由 mutex 的持有者释放 mutex。并且 mutex 不能递归上锁和解锁。?
2. 互斥体 API 函数
| 函数 | 描述 |
| DEFINE_MUTEX(name) | 定义并初始化一个 mutex 变量。 |
| void mutex_init(mutex *lock) | 初始化 mutex。 |
| void mutex_lock(struct mutex *lock) | 获取 mutex,也就是给 mutex 上锁。如果获 取不到就进休眠。 |
| void mutex_unlock(struct mutex *lock) | 释放 mutex,也就给 mutex 解锁。 |
| int mutex_trylock(struct mutex *lock) | 尝试获取 mutex,如果成功就返回 1,如果失 败就返回 0。 |
| int mutex_is_locked(struct mutex *lock) | 判断 mutex 是否被获取,如果是的话就返回 1,否则返回 0。 |
| int mutex_lock_interruptible(struct mutex *lock) | 使用此函数获取信号量失败进入休眠以后可 以被信号打断。 |
??互斥体的使用:
struct mutex lock; /* 定义一个互斥体 */
mutex_init(&lock); /* 初始化互斥体 */
mutex_lock(&lock); /* 上锁 */
/* 临界区 */
mutex_unlock(&lock); /* 解锁 */六、总结
??这一章讲了并发和竞争,还有常用的原子操作(整形原子操作和位原子操作)、自旋锁、信号量和互斥体。知道这些名词的概念和常用的用法就即可。
并发:有多个线程同时执行。
竞争:多个线程同时访问共享资源。
原子操作:不能进一步分割,适用于变量或位操作。使用方式:
atomic_t v = ATOMIC_INIT(0); /* 定义并初始化原子变零 v=0 */
atomic_set(&v, 10); /* 设置 v=10 */
atomic_read(&v); /* 读取 v 的值,肯定是 10 */
atomic_inc(&v); /* v 的值加 1, v=11 */自旋锁:线程 A 对结构体使用期间,禁止其他进程对结构体使用(针对于短时期的加锁)。使用方式:
DEFINE_SPINLOCK(lock) /* 定义并初始化一个锁 */
/*
另一种方式定义和初始化:
spinlock_t lock; // 定义一个锁
spin_lock_init(&lock); // 初始化 lock 锁
*/
/* 线程 A */
void functionA (){
unsigned long flags; /* 中断状态 */
spin_lock_irqsave(&lock, flags) /* 获取锁 */
/* 临界区 */
spin_unlock_irqrestore(&lock, flags) /* 释放锁 */
}
/* 中断服务函数 */
void irq() {
spin_lock(&lock) /* 获取锁 */
/* 临界区 */
spin_unlock(&lock) /* 释放锁 */
}信号量:类似与自旋锁,但是信号量可以让线程进入休眠,并且信号量针对于长时间的加锁。但是信号量值小于1的时候变为互斥体。使用方式:
struct semaphore sem; /* 定义信号量 */
sema_init(&sem, 1); /* 初始化信号量,并把sem设为1 */
down(&sem); /* 申请信号量 */
/* 临界区 */
up(&sem); /* 释放信号量 */互斥体:互斥访问表示一次只有一个线程可以访问共享资源,不能递归(有了一个互斥体后再申请互斥体)申请互斥体。使用方式:
struct mutex lock; /* 定义一个互斥体 */
mutex_init(&lock); /* 初始化互斥体 */
mutex_lock(&lock); /* 上锁 */
/* 临界区 */
mutex_unlock(&lock); /* 解锁 */本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux 系统磁盘空间扩容
- 递归内存分析
- SQL SERVER 不拼接SQL如何条件查询
- jrebel debug 启动不起来
- 入门教程:使用 Postman 发送 post 请求
- 代码随想录算法训练营第十三天 | 二叉树基础和深度优先遍历
- 【第2讲】原理介绍和权限开通
- HarmonyOS 应用开发学习笔记 ets自定义组件及其引用 @Component自定义组件
- 【知识积累】深度度量学习综述
- Ngnix之反向代理、负载均衡、动静分离