CV必备的15个多尺度模型分享,涵盖特征融合、多尺度预测等4种网络结构
在卷积神经网络中,感受野的大小会影响到模型能够捕捉到的特征的尺度,从而影响模型的性能。因此我们在设计网络时,需要合理地控制感受野的大小。
那么问题来了:怎样才能合理控制?
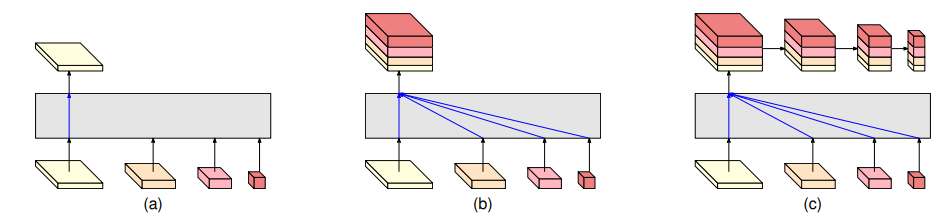
到目前为止,已有很多学者设计出了各种各样的多尺度模型架构供我们学习参考。这其中,图像金字塔和特征金字塔是实现多尺度的两种常用方法。更具体点,可以分为多尺度输入网络、多尺度特征融合网络、多尺度特征预测融合网络、多尺度特征和预测融合网络4种网络结构。
为了让同学们更轻松地设计网络、找创新点,今天我就从以上4种网络结构中梳理了15个CV领域必学的多尺度模型架构。希望对想发顶会的各位有所帮助。
模型原文和开源代码看文末
多尺度输入网络
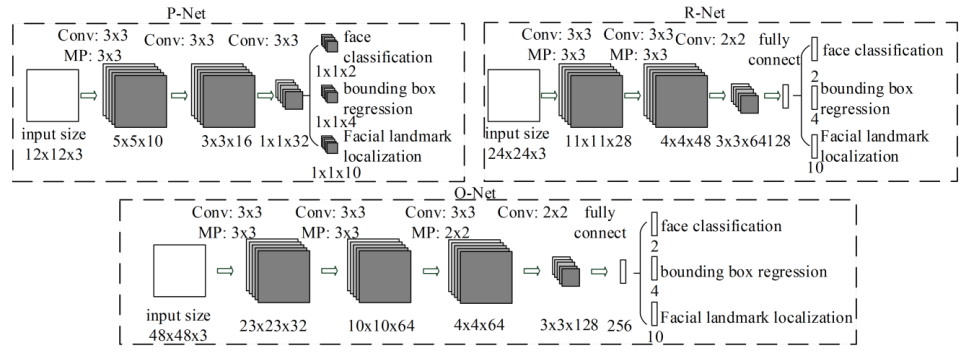
1.人脸检测MTCNN
论文:Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
使用多任务级联卷积网络进行联合人脸检测和校准
「简述:」论文提出了一种深度级联多任务框架,用于在不受约束的环境中进行人脸检测和对齐。该框架采用了一个级联结构,包含三个精心设计的深度卷积网络阶段,以粗到精的方式预测人脸和地标位置。该方法在具有挑战性的基准测试中实现了优于最新技术的人脸检测精度和人脸对齐精度,同时保持了实时性能。
多尺度特征融合网络
并行多分支结构
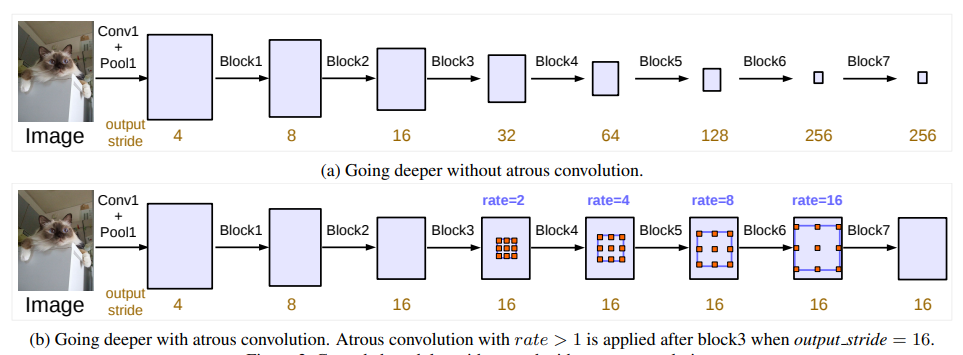
1.图像分割网络Deeplab V3
论文:Rethinking atrous convolution for semantic image segmentation
重新思考用于语义图像分割的空洞卷积
「简述:」本文重新审视了空洞卷积在语义图像分割中的应用。为了解决多尺度对象分割的问题,作者设计了模块,采用级联或并行的方式使用不同扩张率的空洞卷积来捕捉多尺度上下文信息。此外,作者还提出了增强之前提出的Atrous Spatial Pyramid Pooling模块的方法,该模块可以在多个尺度上探索卷积特征,并结合全局上下文的图像级别特征进一步提升性能。
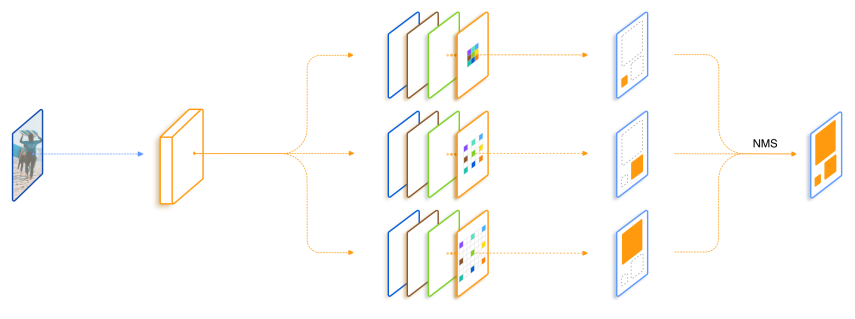
2.目标检测网络trident networks
论文:Scale-aware trident networks for object detection
用于目标检测的尺度感知Trident网络
「简述:」论文研究了目标检测中尺度变化的问题,并提出了Trident网络来解决。该网络采用并行多分支架构,每个分支具有不同的感受野,但共享相同的变换参数。通过尺度感知的训练方案,每个分支可以专门针对适当尺度的目标实例进行训练。此外,Trident网络还提供了一个快速近似版本,可以在不增加额外参数和计算成本的情况下实现显著的性能提升。在COCO数据集上,使用ResNet-101主干网络的Trident网络实现了最佳单模型结果。
3.SPP——SPPNet
论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
用于视觉识别的深度卷积网络中的空间金字塔池化
「简述:」论文提出了SPP-net网络结构,使用空间金字塔池化策略消除了深度卷积神经网络对固定尺寸输入图像的要求。该网络可以生成与图像大小/尺度无关的固定长度表示,并且对物体变形具有鲁棒性。在多个数据集上,SPP-net表现出良好的性能,并且在目标检测方面也具有优势。该方法被广泛应用于各种CNN架构中,并在ILSVRC竞赛中获得优异成绩。

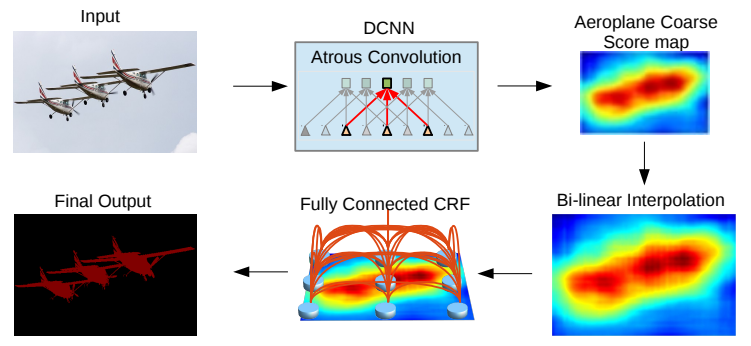
4.ASPP——DeepLab V2
论文:DeepLab v2: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
使用深度卷积网络、空洞卷积和全连接CRFs进行语义图像分割
「简述:」论文提出了一种语义图像分割方法DeepLab,主要贡献包括三个方面。首先,使用扩张率卷积来控制深度卷积神经网络中特征响应的计算分辨率和扩大滤波器的视野。其次,提出空洞空间金字塔池化来稳健地在多个尺度上分割对象。第三,结合DCNNs和概率图形模型的方法改善对象边界的定位精度。该方法在PASCAL VOC-2012数据集上达到了新的最先进水平,并在其他三个数据集上也取得了进展。
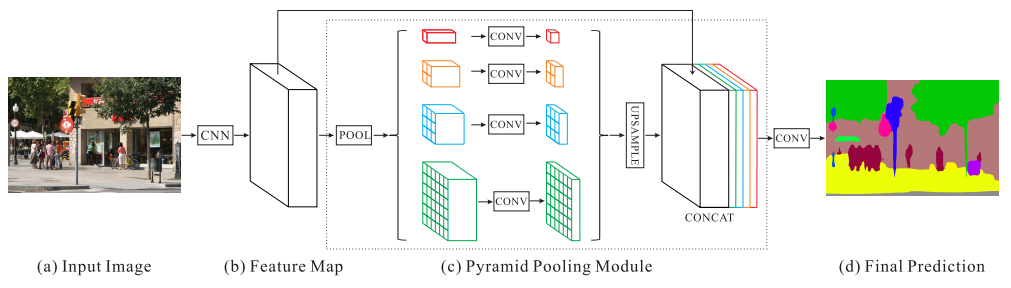
5.PSPNet
论文:Pyramid scene parsing network
金字塔场景解析网络
「简述:」论文提出了一种金字塔场景解析网络(PSPNet),通过在不同区域之间进行上下文聚合的金字塔池化模块来利用全局上下文信息。该方法能够有效地产生高质量的场景分割结果,并在像素级预测任务中提供优越的框架。在各种数据集上,该方法实现了最先进的性能,在ImageNet场景解析挑战2016、PASCAL VOC 2012基准测试和Cityscapes基准测试中获得第一名。单个PSPNet在PASCAL VOC 2012上获得了85.4%的mIoU准确性和Cityscapes上的80.2%准确性的新记录。
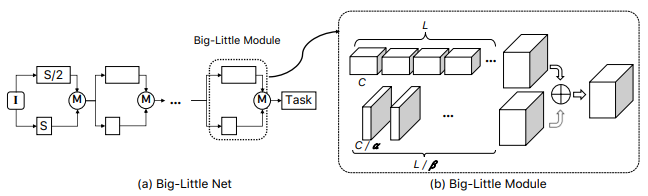
6.Big-little Net
论文:Big-little net: An efficient multi-scale feature representation for visual and speech recognition
一种用于视觉和语音识别的高效多尺度特征表示方法
「简述:」本文提出了一种多分支卷积神经网络架构,用于学习具有良好速度和准确性权衡的多尺度特征表示。通过频繁地合并来自不同尺度分支的特征,该模型获得了多尺度特征,同时减少了计算量。在对象识别和语音识别任务上,该方法提高了模型效率和性能,并超过了最先进的CNN加速方法。
串行多分支结构
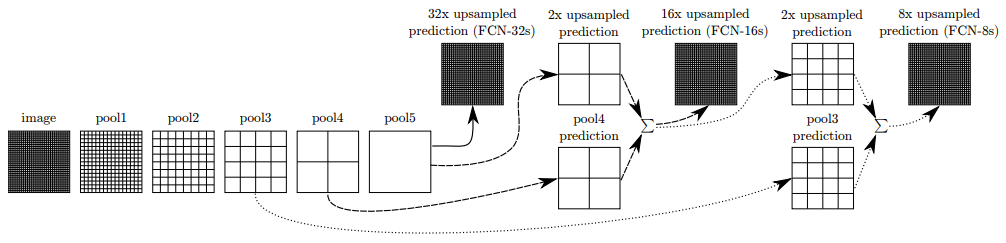
7.FCN
论文:Fully Convolutional Networks for Semantic Segmentation
用于语义分割的全卷积网络
「简述:」本文提出了一种全卷积网络架构,用于语义分割。通过将当代分类网络(AlexNet、VGG和GoogLeNet)转换为全卷积网络,并将它们学习到的表示形式进行微调以适应分割任务,实现了高效推理和学习的相应大小的输入和输出。作者还定义了一种新颖的架构,将深层粗糙层中的语义信息与浅层精细层中的表现信息相结合,以产生准确而详细的分割结果。该全卷积网络在PASCAL VOC、NYUDv2和SIFT Flow上实现了最先进的分割,同时对于普通图像的推理只需要三分之一秒。
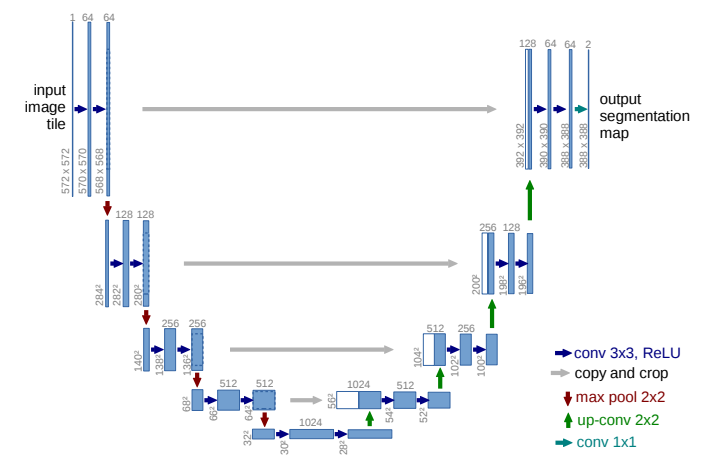
8.U-Net
论文:U-Net: Convolutional Networks for Biomedical Image Segmentation
用于生物医学图像分割的卷积神经网络
「简述:」论文提出了U-Net卷积神经网络,该网络通过强化数据增强技术,能够更有效地利用有限的带注释训练样本。U-Net包含收缩路径以捕获上下文信息和对称扩展路径以实现精确定位。该网络可以在很少的图像上进行端到端的训练,并且在电子显微镜和透射光显微镜图像上的分割和追踪任务中表现出色。此外,该网络的运行速度很快,对512x512图像的分割只需不到一秒的时间。
9.HRNet
论文:Deep High-Resolution Representation Learning for Visual Recognition
用于视觉识别的深度高分辨率表示学习
「简述:」本文介绍了HRNet网络架构,用于解决需要高分辨率表示的位置敏感视觉问题。该网络在整个过程中保持高分辨率表示,通过将高到低分辨率卷积并行连接并重复交换信息来产生更丰富和精确的表示。作者在人体姿态估计、语义分割和目标检测等应用程序中展示了HRNet的优越性,表明它是一种更强大的计算机视觉骨干。
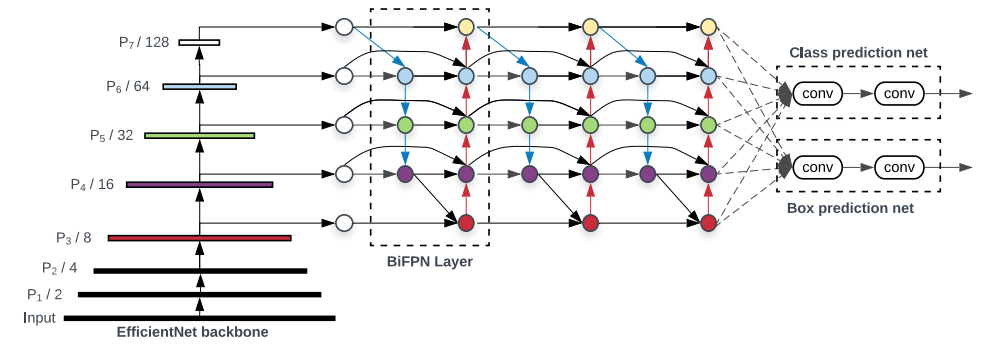
10.BiFPN
论文:EfficientDet: Scalable and Efficient Object Detection
可扩展的高效的目标检测
「简述:」EfficientDet在设计上更加高效,能够在各种资源限制下实现更好的性能。它采用了加权的双向特征金字塔网络,可以进行快速的多尺度特征融合。同时,它还采用了复合缩放方法,统一了骨干网络、特征网络和预测网络的分辨率、深度和宽度。与之前的检测器相比,EfficientDet的参数更少,使用的浮点运算也更少。在COCO测试开发集上,EfficientDet-D7模型达到了55.1的AP,比之前的检测器小4-9倍,使用的浮点运算少13-42倍。
多尺度特征预测融合网络
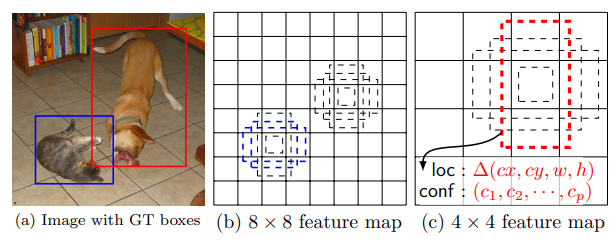
1.目标检测SSD
论文:SSD: Single Shot MultiBox Detector
单步多框目标检测
「简述:」SSD是一个使用单个深度神经网络进行目标检测的方法。它通过在每个特征图位置上设置不同纵横比和尺度的默认框,实现了高效的物体检测。SSD消除了传统的提议生成步骤,简化了训练和推理过程。实验结果显示,SSD在各种数据集上均具有高准确性和高速度,可以轻松集成到其他需要目标检测的系统。与需要额外提议步骤的方法相比,SSD更加简单高效。
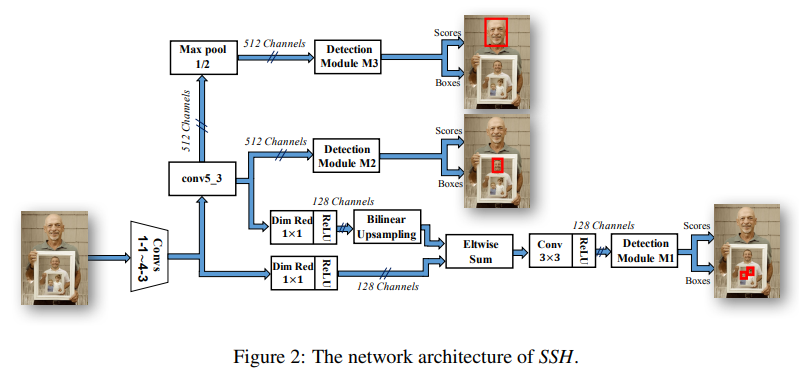
2.SSH
论文:Ssh: Single stage headless face detector
单阶段无头人脸检测
「简述:」SSH是一个单阶段无头人脸检测器,它直接从分类网络的早期卷积层中检测人脸,不需要额外的提议生成步骤。它比传统的两阶段方法更快,更轻量级。通过设计上的改进,SSH能够同时检测不同尺度的人脸,并且不依赖于图像金字塔。在实验中,使用无头的VGG-16,SSH在某些数据集上达到了最先进的性能,并且运行速度更快。此外,如果使用图像金字塔,SSH的性能还可以进一步提高。
多尺度特征和预测融合
1.FPN
论文:Feature Pyramid Networks for Object Detection
用于目标检测的特征金字塔网络
「简述:」特征金字塔网络(FPN)是一种深度学习目标检测技术,利用了深度卷积网络的多尺度层次结构,以构建高效的特征金字塔。FPN通过自上而下的架构和横向连接,在各种尺度上构建高层次的语义特征图。在Faster R-CNN等基础目标检测系统中使用FPN,可以实现高性能的目标检测,且运算速度较快。在COCO检测基准上,FPN达到了领先的单模型结果,超过了其他现有技术。此外,FPN在GPU上的运行速度可达到5 FPS,是一种实用的多尺度目标检测解决方案。
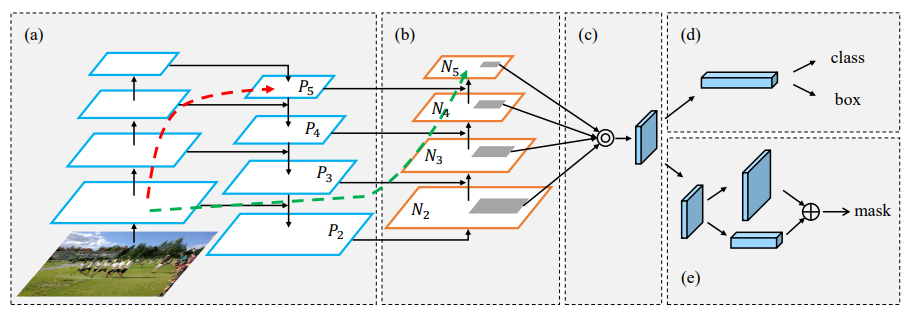
2.PANet路径聚合网络
论文:Path Aggregation Network for Instance Segmentation
用于实例分割的路径聚合网络
「简述:」PANet是一种用于实例分割的神经网络,旨在改进信息在神经网络中的传播。它通过自下而上的路径增强和自适应特征池化来提高信息流,从而提高了实例分割的准确性。此外,PANet还创建了一个互补分支,捕捉每个提议的不同视图,进一步改善了掩码预测。这些改进简单易实现,计算开销小,使PANet在COCO 2017挑战中排名第一,并在其他数据集上达到了最先进的性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“多尺度”获取论文+开源代码
码字不易,欢迎大家点赞评论收藏
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Spring Boot配置文件:properties 与 yml 的竞争
- YOLOv5改进 | 主干篇 | 华为移动端模型GhostnetV2一种移动端的专用特征提取网络
- 石家庄数字孪生赋能工业智能制造,助力制造业企业数字化转型
- linux驱动(五):framebuffer
- Linux内存管理:(七)页面回收机制
- 斯坦福开发WikiChat:几乎不会产生幻觉的模型
- 《设计模式》之策略模式
- 负载开关IC——PC9511/21可编程高精度限流集成28mΩ功率FET外围只需极少元器件
- JMeter逻辑控制器之IF控制器
- 解决Maven找不到依赖的问题