扩散模型U-Net可视化理解
发布时间:2023年12月26日
简介
U-Net是生成式扩散模型的核心。它的输入有三个:(1)带噪声的图片 (2)时间标签 (3)其他条件变量。经过层层运算,得到一个噪声输出。该噪声输出可用于给图片去噪。
这里推荐一个diffusion实现手写数字的源代码https://github.com/TeaPearce/Conditional_Diffusion_MNIST,适合新手入门。本文主要讲解其中U-Net的工作过程。
U-net结构
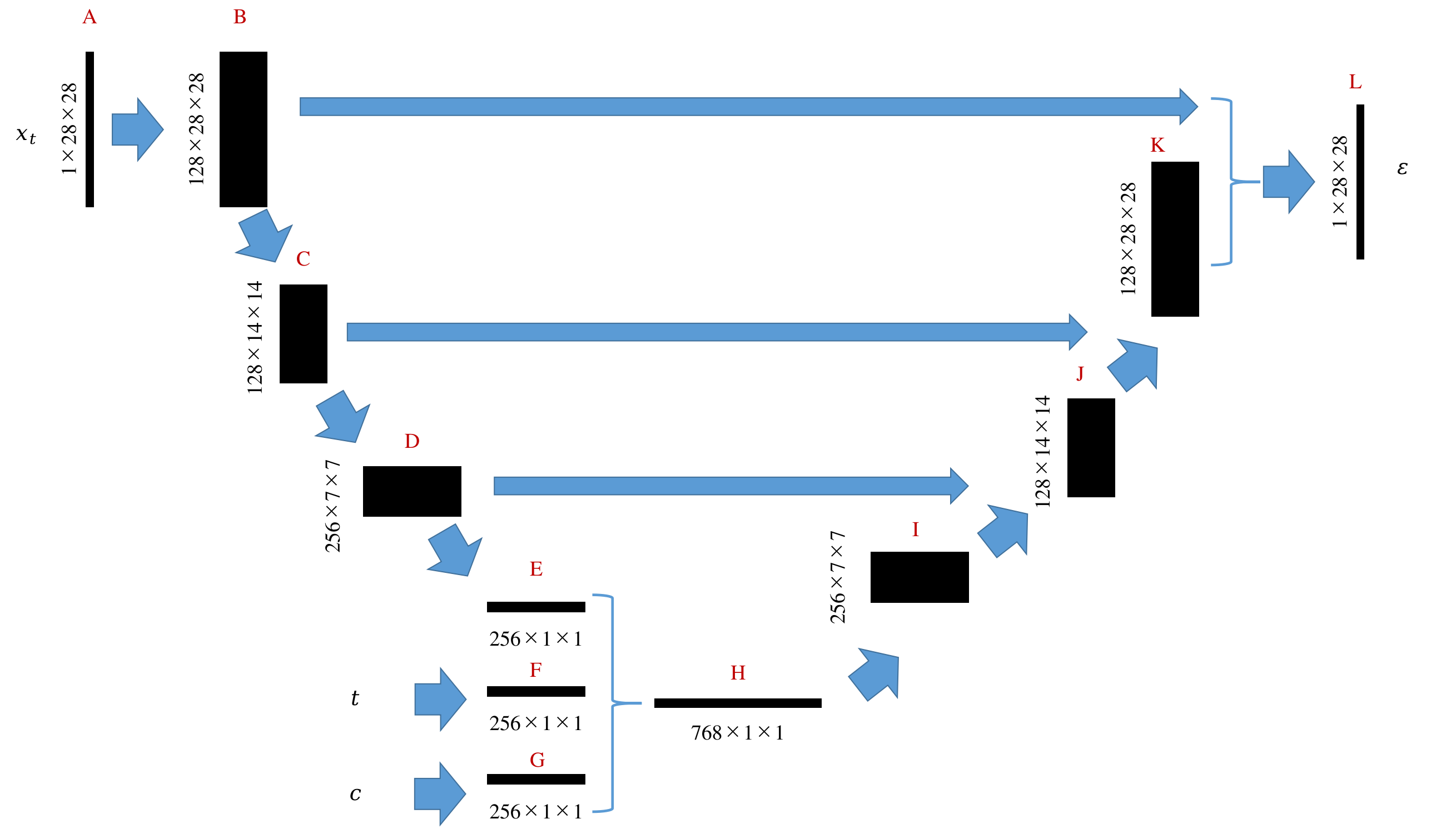
扩散模型中的U-net结构如下图所示,1X28X28表示通道数为1,长宽为28的图片。在实际训练中不是一个三阶张量而是一个四阶张量128X1X28X28,其中128表示批处理数,即128张图片同时在GPU上完成一次训练迭代。
整个计算流程如下:输入图片(A)被提取出128张特征图(B),经过第一次下采样图像缩小一半(C),经过第二次下采样图像进一步缩小为一半(D),经过平均池化得到一个向量(E),这个向量包含了图片中的所有必要特征信息。至此,输入图片已被编码。除了图片以外,时间标签、其他条件变量也可使用全链接网络进行编码,得到两个向量(F和G),为了确保后续上采样顺利,E、F、G的长度应当相同。接下来,将E、F、G合并为一个更长的向量H。H经过上采用不断恢复出I、J、K直到L。L即为最终期望输出的噪声图。用这个噪声图即可实现对图片的去噪。
可视化
接下来以一个batch size=128来说明上述过程。
A

B(第一个通道)

C(第一个通道)

D(第一个通道)

E(batch中的第一个图片的所有通道)

F

G

H

I(第一个通道)

J(第一个通道)

K(第一个通道)

L

文章来源:https://blog.csdn.net/weixin_43325228/article/details/135223972
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 个人网站制作 Part 2 | Web开发项目
- 3.2 内容管理模块 - 课程分类、新增课程、修改课程
- JavaOOP篇----第二十四篇
- 年销5万的岚图没有爆款
- 【2023开发组二等奖】湖南省国土空间规划双评价系统
- 工具系列:PyCaret介绍_Fugue 集成_Spark、Dask分布式训练
- 分别使用OVP-UVP和OFP-UFP算法以及AFD检测算法实现反孤岛检测simulink建模与仿真
- HTML+CSS基础——CSS控制器(文本控制(字体、大小,间距、颜色))
- Apex如何只保留date中的日期
- 基于SSM+BootStrap的企业人力资源管理系统、考勤管理系统、员工管理系统(Java毕业设计)