hung-yi Lee hw2 语音辨识
发布时间:2024年01月19日
作业link
https://www.kaggle.com/c/ml2021spring-hw2![]() https://www.kaggle.com/c/ml2021spring-hw2助教code
https://www.kaggle.com/c/ml2021spring-hw2助教code
https://colab.research.google.com/github/ga642381/ML2021-Spring/blob/main/HW![]() https://colab.research.google.com/github/ga642381/ML2021-Spring/blob/main/HW这次作业来自于语音辨识的一部分,他需要我们根据已有音频材料预测音位,而数据预处理部分是:从原始波形中提取mfcc特征(已经由助教完成了),然后我们则需要以此分类:即使用预先提取的mfcc特征进行帧级音素分类 。
https://colab.research.google.com/github/ga642381/ML2021-Spring/blob/main/HW这次作业来自于语音辨识的一部分,他需要我们根据已有音频材料预测音位,而数据预处理部分是:从原始波形中提取mfcc特征(已经由助教完成了),然后我们则需要以此分类:即使用预先提取的mfcc特征进行帧级音素分类 。
音位分类预测(Phoneme classification)是通过语音数据,预测音位。音位(phoneme),是人类某一种语言中能够区别意义的最小语音单位,是音位学分析的基础概念。每种语言都有一套自己的音位系统。
助教代码的逻辑
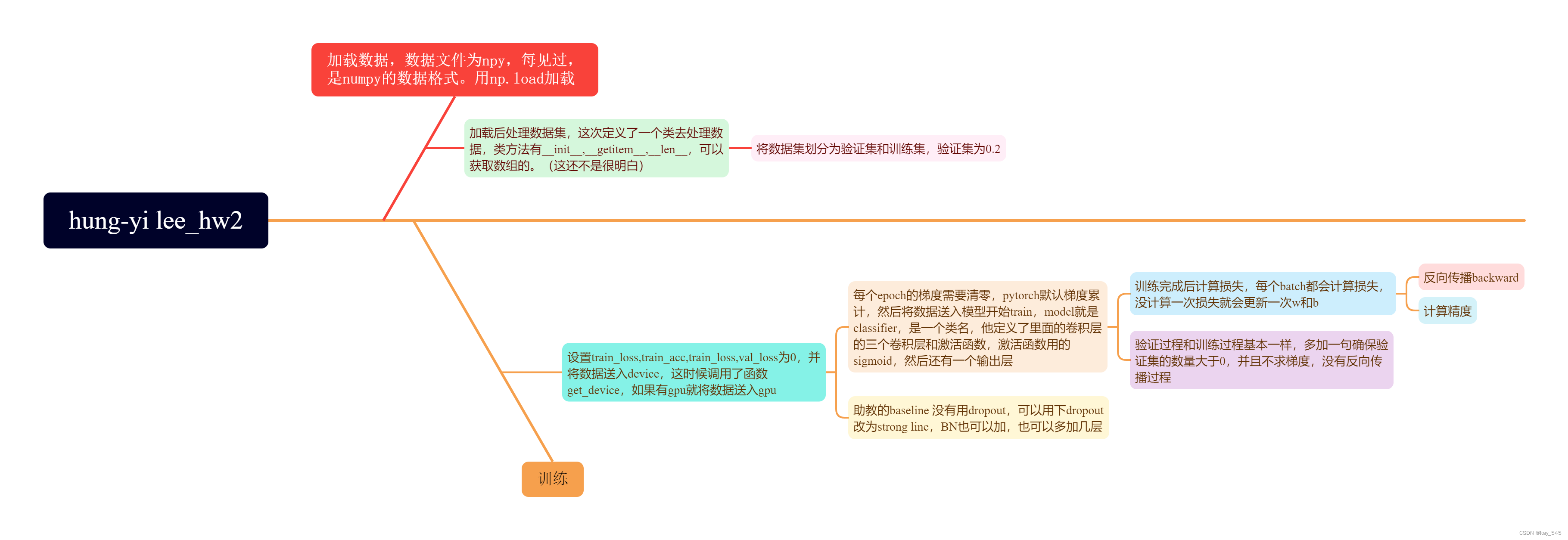
?整体的代码加上注释
import numpy as np
import torch
from torch.utils.data import Dataset
import torch.nn as nn
from torch.utils.data import DataLoader
import gc
import time
# 试试输出耗费时长
start_time = time.time()
print('Loading data ...')
data_root=r'D:/mine/datasets/ml2021spring-hw2/timit_11/timit_11/'
train = np.load(data_root + 'train_11.npy')
# print(type(train))
train_label = np.load(data_root + 'train_label_11.npy')
test = np.load(data_root + 'test_11.npy')
print('Size of training data: {}'.format(train.shape))
print('Size of testing data: {}'.format(test.shape))
print("train_label:",train_label)
end_time = time.time()
print("执行本次程序耗时:",end_time-start_time,"s") # 输出的单位是s
class TIMITDataset(Dataset):
def __init__(self, X, y=None):
self.data = torch.from_numpy(X).float()
if y is not None:
y = y.astype(np.int)
self.label = torch.LongTensor(y)
else:
self.label = None
def __getitem__(self, idx):
if self.label is not None:
return self.data[idx], self.label[idx]
else:
return self.data[idx]
def __len__(self):
return len(self.data)
VAL_RATIO = 0.2
percent = int(train.shape[0] * (1 - VAL_RATIO))
train_x, train_y, val_x, val_y = train[:percent], train_label[:percent], train[percent:], train_label[percent:] # numpy数组,直接切片
print('Size of training set: {}'.format(train_x.shape))
print('Size of validation set: {}'.format(val_x.shape))
BATCH_SIZE = 64
train_set = TIMITDataset(train_x, train_y)
# print(train_set)
val_set = TIMITDataset(val_x, val_y)
# print("val set",val_set[0])
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True) #only shuffle the training data
val_loader = DataLoader(val_set, batch_size=BATCH_SIZE, shuffle=False)
del train, train_label, train_x, train_y, val_x, val_y
gc.collect()
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.layer1 = nn.Linear(429, 1024)
self.layer2 = nn.Linear(1024, 512)
self.layer3 = nn.Linear(512, 128)
self.out = nn.Linear(128, 39)
self.act_fn = nn.Sigmoid()
def forward(self, x):
x = self.layer1(x)
x = self.act_fn(x)
x = self.layer2(x)
x = self.act_fn(x)
x = self.layer3(x)
x = self.act_fn(x)
x = self.out(x)
return x
#check device
def get_device():
return 'cuda' if torch.cuda.is_available() else 'cpu'
# fix random seed
def same_seeds(seed):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# fix random seed for reproducibility
same_seeds(0)
# get device
device = get_device()
print(f'device: {device}')
# training parameters
num_epoch = 20 # number of training epoch
learning_rate = 0.0001 # learning rate
# the path where checkpoint saved
model_path = './model.ckpt'
# create model, define a loss function, and optimizer
model = Classifier().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# start training
best_acc = 0.0
for epoch in range(num_epoch):
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
# training
model.train() # set the model to training mode
for i, data in enumerate(train_loader): # train_laoder 里面既有数据,又有标签 ,i是拿到数据的标号,i好像没啥用 ?
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) # 将数据和标签都送入 device
optimizer.zero_grad() # 每个epoch梯度清零 pytorch默认梯度累计
outputs = model(inputs) # 送入模型进行训练
batch_loss = criterion(outputs, labels) # 计算损失
_, train_pred = torch.max(outputs, 1) # get the index of the class with the highest probability outputs是一个输出模型,torch.max(outputs, 1)表示在outputs的第一个维度上进行操作,返回每行最大值及其索引的元组,元组的第一个元素是每行最大值的值,第二个元素是每行最大值的所在的索引
batch_loss.backward()
optimizer.step()
train_acc += (train_pred.cpu() == labels.cpu()).sum().item() # 那准确率怎么控制在0-1之间, 别急,下面才会输出,在验证部分
train_loss += batch_loss.item() # 每个batch 都会计算loss
# validation
if len(val_set) > 0:
model.eval() # set the model to evaluation mode,不用dropout
with torch.no_grad():
for i, data in enumerate(val_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
batch_loss = criterion(outputs, labels)
_, val_pred = torch.max(outputs, 1)
val_acc += (val_pred.cpu() == labels.cpu()).sum().item() # get the index of the class with the highest probability
val_loss += batch_loss.item()
print('[{:03d}/{:03d}] Train Acc: {:3.6f} Loss: {:3.6f} | Val Acc: {:3.6f} loss: {:3.6f}'.format(
epoch + 1, num_epoch, train_acc/len(train_set), train_loss/len(train_loader), val_acc/len(val_set), val_loss/len(val_loader)
))
# if the model improves, save a checkpoint at this epoch
if val_acc > best_acc: # best_acc = 0.0
best_acc = val_acc
torch.save(model.state_dict(), model_path)
print('saving model with acc {:.3f}'.format(best_acc/len(val_set)))
else: # 如果没有验证集
print('[{:03d}/{:03d}] Train Acc: {:3.6f} Loss: {:3.6f}'.format(
epoch + 1, num_epoch, train_acc/len(train_set), train_loss/len(train_loader) # len(train_loader)就是这个epoch有多少个batches,每个epoch都需要更新loss,所以不是总的batch
))
# if not validating, save the last epoch
if len(val_set) == 0:
torch.save(model.state_dict(), model_path)
print('saving model at last epoch')这是助教的baseline版本--------2024.01.19
strong line 待更新
文章来源:https://blog.csdn.net/m0_67647321/article/details/135704026
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 兔单抗制备|兔单抗制备方法-卡梅德生物
- 【设计模式】一文理解记住设计模式的原则
- 假设法做线段树
- 修复Apache httpd中的SSL/TLS 协议信息泄露漏洞(CVE-2016-2183)
- 用友NC Cloud IUpdateService接口存在XXE漏洞
- 如何量化Diffusion Models?
- 回溯法解决染色问题(递归版和迭代版)
- Vant2组件的使用
- 【正点原子STM32连载】第三十五章 多通道ADC采集(DMA读取)实验 摘自【正点原子】APM32E103最小系统板使用指南
- 使用Open3D实现3D激光雷达可视化:以自动驾驶的2DKITTI深度框架为例(下篇)