elasticsearch简单相关操作
查看索引
GET _cat/indices //获取所有的index
GET account
发送post不带id新建数据
POST user/_doc/
{
"name":"bobby",
"compamy":"imooc"
}
如果post带id就和put一样的操作了, put是不允许不带id的
post + _create
没有就创建,有就报错
POST user/_create/1
{
"name":"bobby",
"compamy":"imooc"
}
通过put+id新建数据
在customer下保存id为1的数据, 这里id是必须的
PUT account/_doc/1
{
"name":"bobby",
"age":18,
"company":[
{
"name":"imooc",
"address":"beijing"
},
{
"name":"imooc2",
"address":"shanghai"
}
]
}
关于 _version和_seq_no的区别和作用请参考https://discuss.elastic.co/t/relation-between-version-seq-no-and-primary-term/179647
获取数据
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html
GET user/_doc/1
获取部分数据–>只返回source的值
GET user/_source/1
搜索数据
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html
Elasticsearch有两种查询方式
1. URI带有查询条件(轻量查询)
查询能?有限,不是所有的查询都可以使?此?式
2. 请求体中带有查询条件(复杂查询)
查询条件以JSON格式表现,作为查询请求的请求体,适合复杂的查询
1通过url查询数据
请求参数位于_search端点之后,参数之间使用&分割,例如:
GET _search?q=bobby
GET user/_search?q=bobby
搜索API的最基础的形式是没有指定任何查询的空搜索,它简单地返回集群中所有索引下的所有文档。
通过request body查询数据
GET user/_search
{
"query":{
"match_all": {},
}
}
想要给已有的数据新增字段
POST users/_doc/1
{
"age":18
}
此时会发现,已有的数据的name字段没有了,只有age字段
此时我们需要使用
POST user/_update/1
{
"doc": {
"age":18
}
}
如果值是一样,就会什么都不做,使用doc需要做检查
删除数据和索引
DELETE users/_doc/1
DELETE users
批量操作(bulk)–>互不影响
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
POST _bulk
{ "index" : { "_index" : "user", "_id" : "1" } }
{ "name" : "bobby" }
{ "index" : { "_index" : "user", "_id" : "2" } }
{ "name" : "bobby2" }
批量获取(mget)
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-multi-get.html
GET /_mget
{
"docs": [
{
"_index": "my-index-000001",
"_id": "1"
},
{
"_index": "my-index-000001",
"_id": "2"
}
]
}
用法
GET /_mget
{
"docs": [
{
"_index": "user",
"_id": "1"
},
{
"_index": "account",
"_id": "1"
}
]
}
#对于es来说from和size分页在数据量比较的情况下可行,一旦很大性能下降很厉害,这样需要使用scroll
GET user/_search
{
"query": {
"match_all": {}
},
"from": 4, //偏移量
"size": 4 //取多少个
}
全文查询 - 分词
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
1. match查询(匹配查询)
match :模糊匹配,需要指定字段名,但是输入会进行分词,比如"hello world"会进行拆分为hello和world,然后匹配,如果字段中包含hello或者world,或者都包含的结果都会被查询出来,也就是说match是一个部分匹配的模糊查询。查询条件相对来说比较宽松。
//大小写不敏感
GET user/_search
{
"query": {
"match": {
"address": "street"
}
}
}
倒排索引
写入数据和查询数据都会分词,然后进行倒排索引
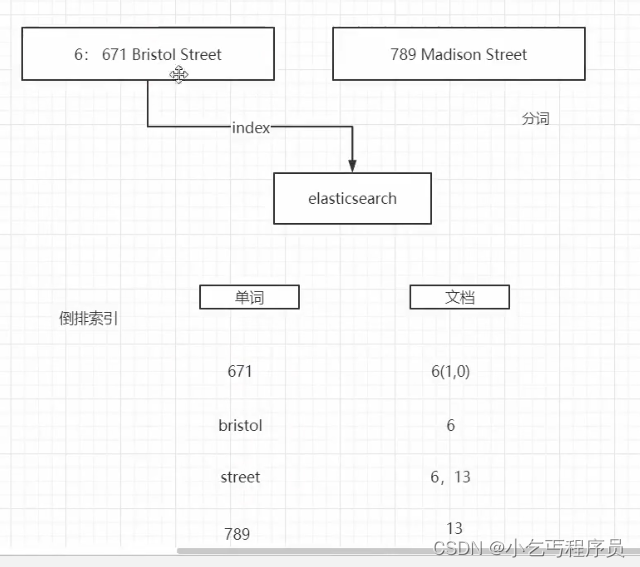
比如id为6的时候,先进行分词,把这些分词进行插入–>文档内会得到id为6,再来一个id为7的,进行分词,如果有相同的分词,就会在相同位置的文档添加一个id为7,这样相同的有6,7分词。
match_phrase(p rui si)查询 短语查询
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase.html
match_phase :会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样。以"hello world"为例,要求结果中必须包含hello和world,而且还要求他们是连着的,顺序也是固定的,hello that word不满足,world hello也不满足条件。
GET /_search
{
"query": {
"match_phrase": {
"message": "this is a test"
}
}
}
GET user/_search
{
"query": {
"match_phrase": {
"address": "Madison street"
}
}
}
multi_match(ma le te)查询
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-multi-match-query.html
multi_match 查询提供了一个简便的方法用来对多个字段执行相同的查询,即对指定的多个字段进行match查询==>还可以执行权重(^2这样用)
POST resume/_doc/12
{
"title": "后端?程师",
"desc": "多年go语?开发经验, 熟悉go的基本语法, 熟悉常?的go语?库",
"want_learn":"python语?"
}
POST resume/_doc/13
{
"title": "go?程师",
"desc": "多年开发经验",
"want_learn":"java语?"
}
POST resume/_doc/14
{
"title": "后端?程师",
"desc": "多年开发经验",
"want_learn":"rust语?"
}
GET resume/_search
{
"query": {
"multi_match": {
"query": "go",
"fields": ["title", "desc"]
}
}
}
GET resume/_search
{
"query": {
"multi_match": {
"query": "go",
"fields": ["title^2", "desc"]
}
}
}
query_string查询
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html
query_string:和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。
GET user/_search {
"query":{
"query_string":
{
"default_field": "address", #指明搜索字段
"query":"Madison AND street" #AND作为连接符
}
}
}
term查询–>不会做分词(原子查询)==>对输入的内容不做处理
https://www.elastic.co/guide/en/elasticsearch/reference/current/term-level-queries.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-term-query.html
term : 这种查询和match在有些时候是等价的,比如我们查询单个的词hello,那么会和match查询结果一样,但是如果查询"hello world",结果就相差很大,因为这个输入不会进行分词,就是说查询的时候,是查询字段分词结果中是否有"hello world"的字样,而不是查询字段中包含"hello world"的字样,elasticsearch会对字段内容进行分词,“hello world"会被分成hello和world,不存在"hello world”,因此这里的查询结果会为空。这也是term查询和match的区别。
GET user/_search
{
"query": {
"term": {
"address": "madison street"
}
}
}
GET /_search
{
"query": {
"term": {
"address": {
"value": "street",
}
}
}
}
range查询 - 范围查询
以下搜索将返回字段包含术语的文档 介于 和 之间。age10–20
GET user/_search
{
"query":{
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
}
exists查询(存在查询)–>是否存在
GET user/_search
{
"query": {
"exists": {
"field": "school"
}
}
}
POST user/_doc
{
"school":"middle school"
}
fuzzy模糊查询
GET user/_search
{
"query": {
"fuzzy": {
"address": "streat" #本来是street 但是写成了streat
}
}
}
GET user/_search
{
"query": {
"match": {
"address": {
"query":"Midison streat"
"fuzziness": 1 #开启模糊查询
}
}
}
}
复合查询
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-bool-query.html
Elasticsearch bool查询对应Lucene BooleanQuery, 格式如下
{
"query":{
"bool":{
"must":[
],
"should":[
],
"must_not":[
],
"filter":[
],
}
}
}
must: 必须匹配,查询上下?,加分-->必须全部满足,影响得分
should: 应该匹配,查询上下?,加分-->满足也可不满足也可 满足得分高一些
must_not: 必须不匹配,过滤上下?,过滤-->全部不满足
filter: 必须匹配,过滤上下?,过滤-->进行过滤 必须满足
bool查询采用了一种匹配越多越好的方法,因此每个匹配的must或should子句的分数将被加在一起,以提供每个文档的最终得分
GET user/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"state": "tn"
}
},
{
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
],
"must_not": [
{
"term": {
"gender": "m"
}
}
],
"should": [
{
"match": {
"firstname": "Decker"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 25,
"lte": 30
}
}
}
]
}
}
}
mapping
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html
keyword和text类型
keyword是不进行分词的,全部数据放到倒排索引中去。
text类型是进行分词的
analyzer–>分析器(分词、小写)
https://www.elastic.co/guide/en/elasticsearch/reference/current/specify-analyzer.html#specify-index-time-analyzer
Standard Analyzer - 默认分词器,按词切分,小写处理
Simple Analyzer - 按照非字母切分(符号被过滤),小写处理
Stop Analyzer - 小写处理,停用词过滤(the ,a,is)
Whitespace Analyzer - 按照空格切分,不转小写
Keyword Analyzer - 不分词,直接将输入当做输出
Patter Analyzer - 正则表达式,默认 \W+
Language - 提供了 30 多种常见语言的分词器
Analyzer 的组成
Analyzer 由三部分组成:Character Filters、Tokenizer、Token Filters
Character Filters–>字符过滤器
Character Filters字符过滤器接收原始文本text的字符流,可以对原始文本增加、删除字段或者对字符做转换。一个Analyzer 分析器可以有 0-n 个按顺序执行的字符过滤器。
Tokenizer–>分词器
Tokenizer 分词器接收Character Filters输出的字符流,将字符流分解成的那个的单词,并且输出单词流。例如空格分词器会将文本按照空格分解,将 “Quick brown fox!” 转换成 [Quick, brown, fox!]。分词器也负责记录每个单词的顺序和该单词在原始文本中的起始和结束偏移offsets 。一个Analyzer 分析器有且只有 1个分词器。
Token Filters–>单词过滤器
Token Filters单词过滤器接收分词器Tokenizer输出的单词流,可以对单词流中的单词做添加、移除或者转换操作,例如lowercase token filter会将单词全部转换成小写,stop token filter会移除the、and这种通用单词,synonym token filter会往单词流中添加单词的同义词。
Token filters不允许改变单词在原文档的位置以及起始、结束偏移量。
一个Analyzer 分析器可以有 0-n 个按顺序执行的单词过滤器。
https://blog.csdn.net/u013200380/article/details/106887305?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170285088316800225525006%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=170285088316800225525006&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-106887305-null-null.142^v96^control&utm_term=analyzer&spm=1018.2226.3001.4187
设置分词器
GET _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
文本分词
单词是语言中重要的基本元素。一个单词可以代表一个信息单元,有着指代名称、功能、动作、性质等作用。在语言的进化史中,不断有新的单词涌现,也有许多单词随着时代的变迁而边缘化直至消失。根据统计,《汉语词典》中包含的汉语单词数目在37万左右,《牛津英语词典》中的词汇约有17万。理解单词对于分析语言结构和语义具有重要的作用。因此,在机器阅读理解算法中,模型通常需要首先对语句和文本进行单词分拆和解析。分词(tokenization)的任务是将文本以单词为基本单元进行划分。由于许多词语存在词型的重叠,以及组合词的运用,解决歧义性是分词任务中的一个挑战。不同的分拆方式可能表示完全不同的语义。如在以下例子中,两种分拆方式代表的语义都有可能:
南京市|?江|?桥
南京|市?|江?桥
分词的意义 - nlp
1.将复杂问题转化为数学问题
在 机器学习的文章 中讲过,机器学习之所以看上去可以解决很多复杂的问题,是因为它把这些问题都转化为了数学问题。
而 NLP 也是相同的思路,文本都是一些「非结构化数据」,我们需要先将这些数据转化为「结构化数据」,结构化数据就可以转化为数学问题了,而分词就是转化的第一步。
2.词是一个比较合适的粒度
词是表达完整含义的最小单位。
字的粒度太小,无法表达完整含义,比如”鼠“可以是”老鼠“,也可以是”鼠标“。
而句子的粒度太大,承载的信息量多,很难复用。比如”传统方法要分词,一个重要原因是传统方法对远距离依赖的建模能力较弱。”
中英文分词的3个典型区别
区别1:分词方式不同,中文更难
英文有天然的空格作为分隔符,但是中文没有。所以如何切分是一个难点,再加上中文里一词多意的情况非常多,导致很容易出现歧义。下文中难点部分会详细说明。
区别2:英文单词有多种形态
英文单词存在丰富的变形变换。为了应对这些复杂的变换,英文NLP相比中文存在一些独特的处理步骤,我们称为词形还原(Lemmatization)和词干提取(Stemming)。中文则不需要
词性还原:does,done,doing,did 需要通过词性还原恢复成 do。
词干提取:cities,children,teeth 这些词,需要转换为 city,child,tooth”这些基本形态
区别3:中文分词需要考虑粒度问题
例如「中国科学技术大学」就有很多种分法:
中国科学技术大学
中国 \ 科学技术 \ 大学
中国 \ 科学 \ 技术 \ 大学
粒度越大,表达的意思就越准确,但是也会导致召回比较少。所以中文需要不同的场景和要求选择不同的粒度。这个在英文中是没有的。
中文分词的3大难点
难点 1:没有统一的标准
目前中文分词没有统一的标准,也没有公认的规范。不同的公司和组织各有各的方法和规则。
难点 2:歧义词如何切分
例如「兵乓球拍卖完了」就有2种分词方式表达了2种不同的含义:
乒乓球 \ 拍卖 \ 完了
乒乓 \ 球拍 \ 卖 \ 完了
难点 3:新词的识别
信息爆炸的时代,三天两头就会冒出来一堆新词,如何快速的识别出这些新词是一大难点。比如当年「蓝瘦香菇」大火,就需要快速识别。
3种典型的分词方法
分词的方法大致分为 3 类:
- 基于词典匹配
- 基于统计
- 基于深度学习
给予词典匹配的分词方式
优点:速度快、成本低
缺点:适应性不强,不同领域效果差异大
基本思想:基于词典匹配,将待分词的中文文本根据一定规则切分和调整,然后跟词典中的词语进行匹配,匹配成功则按照词典的词分词,匹配失败通过调整或者重新选择,如此反复循环即可。代表方法有基于正向最大匹配和基于逆向最大匹配及双向匹配法。
基于统计的分词方法
优点:适应性较强
缺点:成本较高,速度较慢
这类目前常用的是算法是 HMM、CRF、SVM、深度学习 等算法,比如stanford、Hanlp分词工具是基于CRF算法。以CRF为例,基本思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑上下文,具备较好的学习能力,因此其对歧义词和未登录词的识别都具有良好的效果。
基于深度学习
优点:准确率高、适应性强
缺点:成本高,速度慢
例如有人员尝试使用双向LSTM+CRF实现分词器,其本质上是序列标注,所以有通用性,命名实体识别等都可以使用该模型,据报道其分词器字符准确率可高达97.5%。常见的分词器都是使用机器学习算法和词典相结合,一方面能够提高分词准确率,另一方面能够改善领域适应性。
中文分词工具
下面排名根据 GitHub 上的 star 数排名:
- jieba
- Hanlp
- IK
- Stanford 分词
- ansj 分词器
- 哈工大 LTP
- KCWS分词器
- 清华大学THULAC
- ICTCLAS
英文分词工具
- Keras
- Spacy
- Gensim
- NLTK
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SABO-LSTM MATLAB实现基于减法平均优化器优化长短期记忆神经网络的多输入单输出数据回归预测模型 (多指标,多图)
- window10下载与安装Dubbo Admin,图文说明
- Rust-模式解构
- 手把手教你从入门到精通C# Socket通信
- 计算机基础知识——数据的表示概述
- [每周一更]-(第45期):Docker私有镜像仓库配置并打通阿里云OSS
- Centos 8 安装 Elasticsearch
- 【python】爬取百度热搜排行榜Top50+可视化【附源码】【送数据分析书籍】
- 国产Apple Find My「查找」认证芯片-伦茨科技ST17H6x芯片
- 手写GPT实现小说生成(一)