在机器学习训练测试集中,如何切分出一份验证集
发布时间:2023年12月31日
文章目录
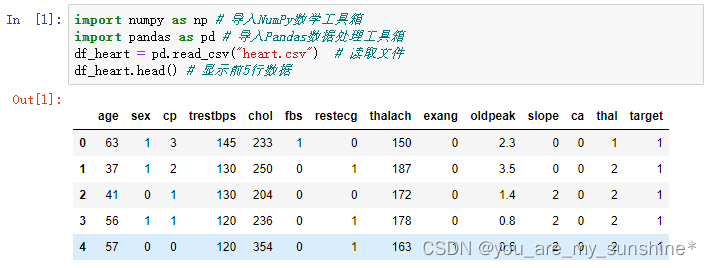
1.读取数据:
import numpy as np # 导入NumPy数学工具箱
import pandas as pd # 导入Pandas数据处理工具箱
df_heart = pd.read_csv("heart.csv") # 读取文件
df_heart.head() # 显示前5行数据
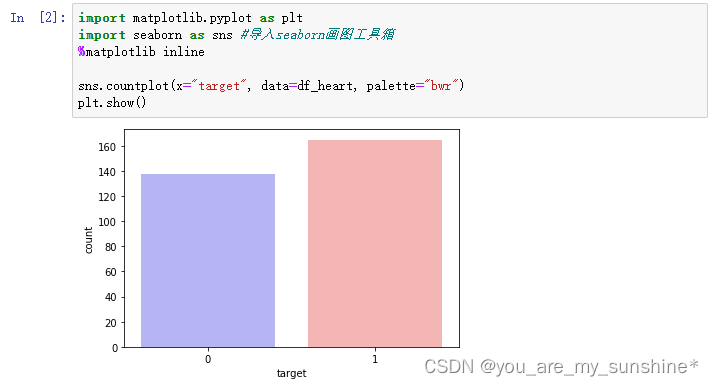
2.绘图查看target数量情况:
import matplotlib.pyplot as plt
import seaborn as sns #导入seaborn画图工具箱
%matplotlib inline
sns.countplot(x="target", data=df_heart, palette="bwr")
plt.show()
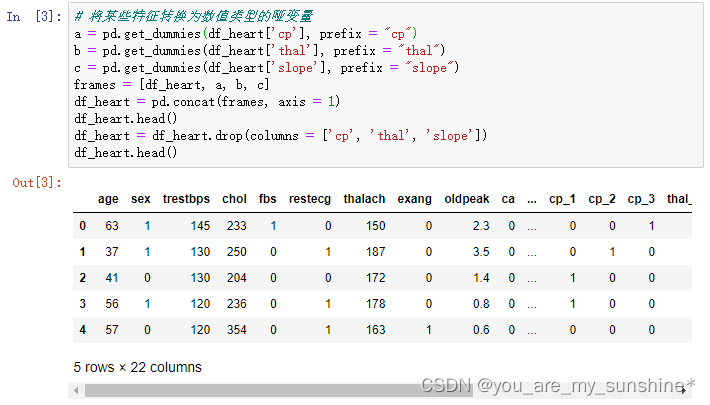
3.特征拓展:
# 将某些特征转换为数值类型的哑变量
a = pd.get_dummies(df_heart['cp'], prefix = "cp")
b = pd.get_dummies(df_heart['thal'], prefix = "thal")
c = pd.get_dummies(df_heart['slope'], prefix = "slope")
frames = [df_heart, a, b, c]
df_heart = pd.concat(frames, axis = 1)
df_heart.head()
df_heart = df_heart.drop(columns = ['cp', 'thal', 'slope'])
df_heart.head()
4.构建X,y:
# 构建特征和标签集
y = df_heart.target.values
X = df_heart.drop(['target'], axis = 1)

5.拆分训练集和测试集,特征做缩放处理:
from sklearn.model_selection import train_test_split # 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.2,random_state=0)
from sklearn import preprocessing
scaler = preprocessing.MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)

6.从训练集里再切一次出验证集,特征做缩放处理:
# 从训练集里再切一次出验证集
X_train, X_check, y_train, y_check = train_test_split(X_train,y_train,test_size = 0.2,random_state=0)
X_check = scaler.transform(X_check)

7.测试集训练效果:
from sklearn.ensemble import RandomForestClassifier # 导入随机森林分类器
from sklearn.metrics import f1_score, confusion_matrix
import warnings
warnings.filterwarnings('ignore')
rf = RandomForestClassifier(n_estimators = 1000, random_state = 1)
rf.fit(X_train, y_train)
rf_acc = rf.score(X_test,y_test)*100
y_pred = rf.predict(X_test) # 预测心脏病结果
print("随机森林算法下的测试集准确率:: {:.2f}%".format(rf.score(X_test, y_test)*100))
print("随机森林算法下的测试集F1分数: {:.2f}%".format(f1_score(y_test, y_pred)*100))
print('随机森林算法下的测试集混淆矩阵:\n', confusion_matrix(y_pred, y_test))

8.从训练集里再切一次出验证集,验证集训练效果:
rf_acc = rf.score(X_check,y_check)*100
y_check_pred = rf.predict(X_check) # 预测心脏病结果
print("随机森林算法下的验证集准确率:: {:.2f}%".format(rf.score(X_check, y_check)*100))
print("随机森林算法下的验证集F1分数: {:.2f}%".format(f1_score(y_check, y_check_pred)*100))
print('随机森林算法下的验证集混淆矩阵:\n', confusion_matrix(y_check_pred, y_check))

参考资料《零基础学机器学习》一书,但“切分出一份验证集“,第6跟第8点是自己从中延伸而来
文章来源:https://blog.csdn.net/weixin_42504788/article/details/135310002
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于Java的中式甜品销售平台(源码+开题)
- 【算法提升—力扣每日一刷】五日总结【12/06--12/10】
- 【深度强化学习】目前落地的挑战与前沿对策
- 微服务概述之集群架构
- 什么是reids缓存雪崩、穿透、击穿
- 福音!Selenium使用WebDriverManager以后,再也不用被浏览器driver与浏览器版本不匹配的问题折磨了!
- 西南科技大学数据库实验六(选课系统综合查询)
- 云端赋能 算力加速 | 活动回顾
- Java 第13章 常用类 课堂练习
- Java构建线程的方式