【算法提升—力扣每日一刷】五日总结【12/06--12/10】

2023/12/06
力扣每日一刷:206. 反转链表
给你单链表的头节点
head,请你反转链表,并返回反转后的链表。示例 1:
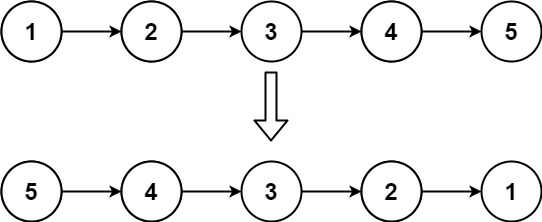
输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]示例 2:
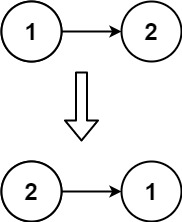
输入:head = [1,2] 输出:[2,1]示例 3:
输入:head = [] 输出:[]提示:
- 链表中节点的数目范围是
[0, 5000]-5000 <= Node.val <= 5000
// 方法1
//反转链表
public ListNode reverseList1(ListNode o1) {
ListNode n1 = null;//新链表的头节点
ListNode p = o1;//原来链表的头结点
while (p != null) {
n1 = new ListNode(p.val, n1);
p = p.next;
}
return n1;
}
//方法2 面向对象,List类在最下方
public ListNode reverseList2(ListNode o1) {
//创建一个链表,将o1的值赋值给链表
List list_old = new List(o1);
//创建一个新的链表,初始头节点为null
List list_new = new List(null);
//当链表头节点不为空时,循环
while (list_old.head != null) {
//将链表头节点删除,并赋值给headList
ListNode headList = list_old.removeHeadList();
//将headList添加到新链表的头部
list_new.addHeadList(headList);
}
//返回新链表的头节点
return list_new.head;
}
//方法3 - 递归
// 递归调用reverseList函数,传入参数o1.next,返回反转后的链表
public ListNode reverseList3(ListNode o1) {
if (o1==null||o1.next == null) {
return o1;
}
ListNode last = reverseList(o1.next);
o1.next.next = o1;
o1.next = null;
return last;
}
//方法4
public ListNode reverseList4(ListNode o1){
//判断边界 1.空链表 2.只有一个节点的链表 ->都将o1输出即可
if(o1==null||o1.next==null){
return o1;
}
ListNode o2 = o1.next;
ListNode n1 = o1;
while (o2!=null){
o1.next = o2.next;
o2.next = n1;
n1 = o2;
o2 = o1.next;
}
return n1;
}
//方法5
public ListNode reverseList(ListNode o1){
//判断边界条件 1.链表为空 2.链表只有一个节点
if(o1==null||o1.next==null){
return o1;
}
ListNode n1 = null;
while (o1!= null){
ListNode o2 = o1.next;
o1.next = n1;
n1 = o1;
o1 = o2;
}
return n1;
}
//链表
static class List {
//链表头节点
ListNode head;
public List(ListNode head) {
this.head = head;
}
/**
* 链表头部添加节点
* @param node 待添加节点
*/
public void addHeadList(ListNode node) {
//将添加的节点指向链表头节点
node.next = head;
//将添加的节点赋值给链表头节点
head = node;
}
/**
* 链表头部删除节点
* @return 删除的节点
*/
public ListNode removeHeadList() {
//将链表头节点赋值给head_old
ListNode head_old = head;
//当链表头节点不为空时,循环
if (head_old != null) {
//将链表头节点指向下一个节点
head = head_old.next;
}
//返回删除的节点
return head_old;
}
}
/** 非题解
* Leetcode 很多链表题目用到的节点类
*/
public class ListNode {
public int val;
public ListNode next;
public ListNode(int val, ListNode next) {
this.val = val;
this.next = next;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder(64);
sb.append("[");
ListNode p = this;
while (p != null) {
sb.append(p.val);
if (p.next != null) {
sb.append(",");
}
p = p.next;
}
sb.append("]");
return sb.toString();
// return String.valueOf(this.val);
}
public static ListNode of(int... elements) {
if (elements.length == 0) {
return null;
}
ListNode p = null;
for (int i = elements.length - 1; i >= 0; i--) {
p = new ListNode(elements[i], p);
}
return p;
}
}
方法一:直接创建新的链表,遍历旧的链表给新链表的节点赋值,并把新节点不断插入到新链表的头部,实现链表反转 ~~优点:~~易于思考和理解,思路较为简单 ~~缺点:~~无法重用节点,需要建立新的链表节点,比较浪费空间
方法二:利用面向对象的思想,给链表建立一个外部容器,可以在容器中定义操作链表的一些方法,比如上面代码中写道的:删除头结点,从头部插入节点等…建立两个链表容器,一个用题目所给的节点作为头结点,另一个头结点为空,每次将旧链表的头结点删除并定义一个指针记录被删除节点,然后将被删除节点插入到新链表的头部,实现链表反转 ~~优点:~~不需要建立新的节点,可以重用旧的节点,节省空间 ~~缺点:~~代码量比较多
方法三:利用递归的方式,先递归找到最后一个节点,利用递归的特点,在弹栈时就相当于逆向遍历链表,可以对链表实现逆向操作,在弹栈时,实现将当前节点的下一个节点的的下一个节点指向当前节点,实现相邻两个节点的反转,最终实现链表反转。~~优点:~~代码量少,代码看着简洁而优雅
~~缺点:~~对递归不熟悉的小伙伴理解上有难度
方法四:相当于用两个指针模拟出两个链表,实际上在操作一个链表,其中一个指针始终指向新链表的头部,另一个指针始终指向旧链表的头部,不断将旧链表的第二个节点指向新链表的头部,指针回位,循环操作,实现链表反转 ~~优点:~~代码量少 ~~缺点:~~指针太多,并不好理解
方法五:和方法二在思想上有异曲同工之妙,但是更面向过程
~~优点:~~代码量少 ~~缺点:~~指针太多,并不好理解
2023/12/07
力扣每日一刷:203. 移除链表元素
给你一个链表的头节点
head和一个整数val,请你删除链表中所有满足Node.val == val的节点,并返回 新的头节点 。示例 1:
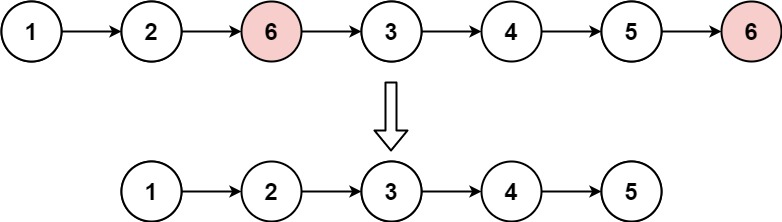
输入:head = [1,2,6,3,4,5,6], val = 6 输出:[1,2,3,4,5]示例 2:
输入:head = [], val = 1 输出:[]示例 3:
输入:head = [7,7,7,7], val = 7 输出:[]提示:
- 列表中的节点数目在范围
[0, 104]内1 <= Node.val <= 500 <= val <= 50
//方法一,定义两个指针循环遍历链表
public ListNode removeElements1(ListNode head, int val) {
ListNode s = new ListNode(666, head);//哨兵节点
ListNode p1 = s;
ListNode p2 = p1.next;
while (p2 != null) {
if (p2.val == val) {
p1.next = p2.next;
p2 = p2.next;
} else {
p1 = p1.next;
p2 = p2.next;
}
}
return s.next;
}
//代码优化版
public ListNode removeElements2(ListNode head, int val) {
ListNode s = new ListNode(666, head);//哨兵节点
ListNode p1 = s;
ListNode p2;
while ((p2 = p1.next) != null) {
if (p2.val == val) {
p1.next = p2.next;
} else {
p1 = p1.next;
}
}
return s.next;
}
//递归法
public ListNode removeElements(ListNode head, int val) {
//如果头节点为空,则返回空
if (head == null) {
return null;
}
//如果头节点的值等于val,则返回移除头节点之后的链表
if (head.val == val) {
return removeElements(head.next, val);
//否则,将头节点的下一个节点作为头节点,并递归调用removeElements函数,返回头节点
} else {
head.next = removeElements(head.next, val);
return head;
}
}
/** 非题解
* Leetcode 很多链表题目用到的节点类
*/
public class ListNode {
public int val;
public ListNode next;
public ListNode(int val, ListNode next) {
this.val = val;
this.next = next;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder(64);
sb.append("[");
ListNode p = this;
while (p != null) {
sb.append(p.val);
if (p.next != null) {
sb.append(",");
}
p = p.next;
}
sb.append("]");
return sb.toString();
// return String.valueOf(this.val);
}
public static ListNode of(int... elements) {
if (elements.length == 0) {
return null;
}
ListNode p = null;
for (int i = elements.length - 1; i >= 0; i--) {
p = new ListNode(elements[i], p);
}
return p;
}
}

力扣今日两刷:19. 删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第
n个结点,并且返回链表的头结点。示例 1:
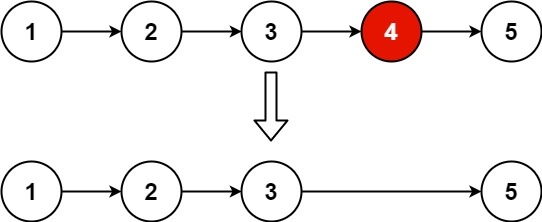
输入:head = [1,2,3,4,5], n = 2 输出:[1,2,3,5]示例 2:
输入:head = [1], n = 1 输出:[]示例 3:
输入:head = [1,2], n = 1 输出:[1]提示:
- 链表中结点的数目为
sz1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
//递归实现
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode s = new ListNode(-1, head);//哨兵
recursion(s, n);
return s.next;
}
private int recursion(ListNode p, int n) {
if (p == null) {
return 0;
}
//nth:当前节点的下一个节点是倒数第几个节点
int nth = recursion(p.next, n);
if (nth == n) {
p.next = p.next.next;
}
return nth + 1;
}
//双指针
//删除倒数第n个节点
public ListNode removeNthFromEnd2(ListNode head, int n) {
ListNode s = new ListNode(-1, head);//哨兵
ListNode p1 = s;
ListNode p2 = s;
//p2先移动n+1步
for (int i = 0; i <= n; i++) {
p2 = p2.next;
}
//一起移动,直到p2为空 保持两个指针之间距离不变,当p2指向null时,p1所指的节点即为倒数第n个节点的上一个节点
while (p2 != null) {
p1 = p1.next;
p2 = p2.next;
}
//删除倒数第n个节点
p1.next = p1.next.next;
return s.next;
}

外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
2023/12/08
力扣每日一刷:83. 删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
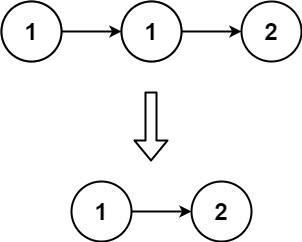
输入:head = [1,1,2]
输出:[1,2]
示例 2:
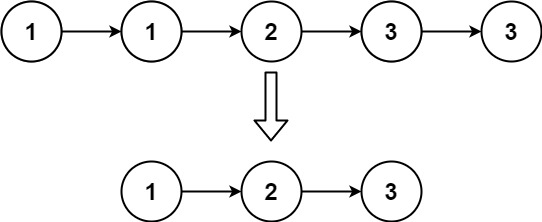
输入:head = [1,1,2,3,3]
输出:[1,2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
//方法一:双指针
public ListNode deleteDuplicates1(ListNode head) {
//节点数<2
if (head == null || head.next == null) {
return head;
}
ListNode s = new ListNode(-1, head);//哨兵节点
ListNode p1 = s;
ListNode p2 = p1.next;
while (p2 != null) {
if (p1.val == p2.val) {
p1.next = p2.next;
p2 = p2.next;
} else {
p1 = p1.next;
p2 = p2.next;
}
}
return s.next;
}
//代码优化版
public ListNode deleteDuplicates2(ListNode head) {
//节点数<2
if (head == null || head.next == null) {
return head;
}
ListNode s = new ListNode(-1, head);//哨兵节点
ListNode p1 = s;
ListNode p2;
while ((p2 = p1.next) != null) {
if (p1.val == p2.val) {
p1.next = p2.next;
} else {
p1 = p1.next;
}
}
return s.next;
}
这段代码是用于删除链表中的重复元素。有两个方法:
deleteDuplicates1和deleteDuplicates2。方法一:双指针
- 首先创建一个哨兵节点
s,并将其指向链表的头节点head。- 定义两个指针
p1和p2,分别指向哨兵节点s和s.next(即链表的头节点)。- 当
p2不为空时,进行以下操作:
a. 如果p1.val和p2.val相等,说明当前节点是重复的,将p1.next指向p2.next,即将当前节点的下一个节点从链表中删除。然后将p2指向下一个节点,继续遍历。
b. 如果p1.val和p2.val不相等,说明当前节点不是重复的,将p1指向下一个节点,即p1 = p1.next。然后将p2指向下一个节点,继续遍历。- 遍历结束后,返回哨兵节点
s的下一个节点,即链表的头节点。方法二:代码优化版
- 与方法一相同,创建一个哨兵节点
s,并将其指向链表的头节点head。- 定义一个指针
p1,指向哨兵节点s。- 当
p2不为空时,进行以下操作:
a. 如果p1.val和p2.val相等,说明当前节点是重复的,将p1.next指向p2.next,即将当前节点的下一个节点从链表中删除。
b. 如果p1.val和p2.val不相等,说明当前节点不是重复的,将p1指向下一个节点,即p1 = p1.next。然后将p2指向下一个节点,继续遍历。- 遍历结束后,返回哨兵节点
s的下一个节点,即链表的头节点。优化版与原始版的主要区别在于:原始版在找到重复节点时,会更新
p2的值,而优化版在找到重复节点时,不会更新p2的值。这样可以减少不必要的计算,提高效率。
//方法二:递归
public ListNode deleteDuplicates(ListNode p) {
if (p == null || p.next == null) {
return p;
}
if(p.val == p.next.val){
return deleteDuplicates(p.next);
}else {
p.next=deleteDuplicates(p.next);
return p;
}
}
这段代码是用于删除链表中的重复元素。方法名
deleteDuplicates,输入参数为一个链表的头节点p,返回值为删除重复元素后的链表的头节点。方法二:递归
- 如果链表为空或者链表只有一个节点,直接返回链表的头节点。
- 如果当前节点的值等于下一个节点的值,说明当前节点是重复的,直接返回下一个节点去除重复元素后的链表的头节点。
- 如果当前节点的值不等于下一个节点的值,说明当前节点不是重复的,将下一个节点去除重复元素后的链表的头节点接到当前节点的下一个节点,然后返回当前节点。
递归的核心思想是:将去除重复元素后的链表的头节点接到当前节点的下一个节点,然后返回当前节点。这样就可以实现从底层逐步向上去除重复元素。
力扣今日两刷:82. 删除排序链表中的重复元素 II
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。(重复元素一个不留)
示例 1:
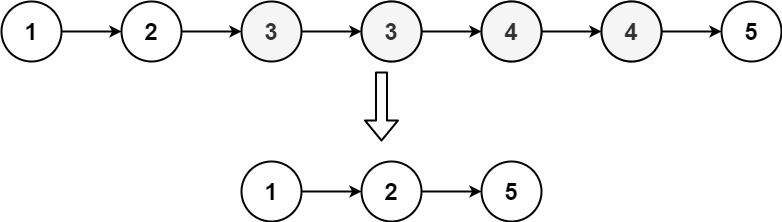
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
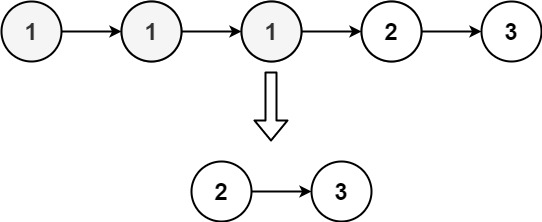
输入:head = [1,1,1,2,3]
输出:[2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
//方法一:递归
public ListNode deleteDuplicates1(ListNode p) {
if (p == null || p.next == null) {
return p;
}
if (p.val == p.next.val) {
ListNode p1 = p.next.next;
while (p1 != null && p1.val == p.val) {
p1 = p1.next;
}
return deleteDuplicates(p1);
}else {
p.next=deleteDuplicates(p.next);
return p;
}
}
方法一:递归
- 首先,判断输入的链表(p)是否为空或者只有一个节点,如果是,则直接返回该链表。
- 如果当前节点的值(p.val)与下一个节点的值(p.next.val)相等,则需要删除重复的节点。具体操作如下: a. 创建一个指针p1,初始时指向当前节点的下一个节点。 b. 使用while循环,当p1不为空且p1的值与当前节点的值相等时,将p1指向下一个节点。 c. 最后,返回删除重复节点后的链表,即deleteDuplicates(p1)。
- 如果当前节点的值与下一个节点的值不相等,则说明当前节点不需要删除,直接将当前节点的指针(p.next)指向下一个节点的递归结果,即deleteDuplicates(p.next),然后返回当前节点。
总之,这个方法通过递归地处理链表中的每个节点,实现了删除重复元素的目的。
//方法二:非递归,三指针
public ListNode deleteDuplicates(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode s = new ListNode(-1,head);//哨兵节点
ListNode p1 = s;
ListNode p2,p3;
while ((p2 = p1.next)!=null&&(p3=p2.next)!=null){
if(p2.val==p3.val){
while ((p3 = p3.next)!=null&&p3.val==p2.val){}
p1.next=p3;
}else {
p1 = p1.next;
}
}
return s.next;
}
这段代码是用于删除链表中的重复元素。它使用了非递归、三指针的方法。
- 首先,创建一个哨兵节点(sentry node),将其指向链表的头节点(head)。
- 然后,定义三个指针:p1、p2 和 p3。p1 指向哨兵节点,p2 指向 p1 的下一个节点,p3 指向 p2 的下一个节点。
- 进入循环,当 p2 不为空且 p3 不为空时,执行以下操作: a. 比较 p2 和 p3 的值。如果它们相等,说明 p2 和 p3 指向的节点是重复的,需要删除。 i. 首先,通过循环找到下一个不等于 p2.val 的节点 p3。 ii. 然后,将 p1 的下一个节点指向 p3,即 p1.next = p3。 b. 如果 p2 和 p3 的值不相等,说明它们指向的节点不是重复的,将 p1 指向 p2 的下一个节点,即 p1 = p1.next。
- 循环结束后,返回哨兵节点的下一个节点,即 s.next。
总之,这段代码通过非递归、三指针的方法实现了删除链表中的重复元素。
//方法三:一次遍历
public ListNode deleteDuplicates(ListNode head) {
if (head == null || head.next == null) {
return head;
}
ListNode s = new ListNode(-1,head);//哨兵节点
ListNode cur = s;
while (cur.next != null && cur.next.next != null){
if(cur.next.val==cur.next.next.val){
int x = cur.next.val;
while (cur.next != null && cur.next.val == x){
cur.next = cur.next.next;
}
}else {
cur=cur.next;
}
}
return s.next;
}
这段代码是用于删除链表中重复的节点的。它使用了三种方法来解决这个问题,这里我们只解释一次遍历的方法。
- 首先,创建一个哨兵节点(sentinel node)
s,其值为-1,并将其next指针指向链表的头节点head。这样做的目的是为了方便处理链表的第一个节点可能也是重复的节点的情况。- 然后,定义一个指针
cur,初始时指向哨兵节点s。- 进入循环,当
cur.next不为空且cur.next.next不为空时,继续循环。- 在循环中,判断
cur.next和cur.next.next的值是否相等。如果相等,说明这两个节点是重复的,需要删除。此时,我们定义一个变量x来存储重复的值,然后使用一个while循环来删除重复的节点。循环的条件是cur.next不为空,并且cur.next.val等于x。在循环中,将cur.next指向cur.next.next,从而删除重复的节点。- 如果
cur.next和cur.next.next的值不相等,说明它们不是重复的节点,将cur指向cur.next,继续遍历下一个节点。- 最后,返回哨兵节点的下一个节点,即原始链表的头节点。
2023/12/09
力扣每日一刷:21. 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
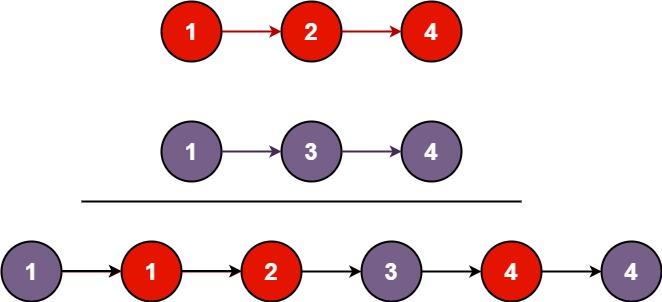
输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]示例 2:
输入:l1 = [], l2 = [] 输出:[]示例 3:
输入:l1 = [], l2 = [0] 输出:[0]提示:
- 两个链表的节点数目范围是
[0, 50]-100 <= Node.val <= 100l1和l2均按 非递减顺序 排列
//方法一:迭代
public ListNode mergeTwoLists1(ListNode p1, ListNode p2) {
ListNode s = new ListNode(-1, null);//新链表的哨兵节点
ListNode p = s;
while (p1 != null && p2 != null) {
if (p1.val < p2.val) {
p.next = p1;
p1 = p1.next;
} else {
p.next = p2;
p2 = p2.next;
}
p = p.next;
}
if (p1 != null) {
p.next = p1;
}
if (p2 != null) {
p.next = p2;
}
return s.next;
}
这段代码是Java中用于合并两个有序链表的方法。给定的链表p1和p2都是有序的,因此我们可以通过比较它们的节点值来合并它们。
方法一:迭代
- 首先,我们创建一个新的链表s,它的头节点是一个值为-1的节点,后面跟着一个空节点。这个新链表将用于存储合并后的节点值。
- 然后,我们创建一个指针p,指向新链表的哨兵节点s。
- 接下来,我们使用一个while循环来遍历p1和p2链表。在每次循环中,我们比较p1和p2节点的值。
- 如果p1节点的值小于p2节点的值,我们将p节点的下一个指针指向p1节点,然后将p1节点向前移动一位。
- 如果p2节点的值小于或等于p1节点的值,我们将p节点的下一个指针指向p2节点,然后将p2节点向前移动一位。
- 最后,我们更新p指针,以便在下一轮循环中指向下一个节点。
- 当p1或p2链表遍历完毕后,我们将另一个链表的剩余节点直接添加到新链表的末尾。
- 最后,我们返回新链表的第一个节点,即s.next。
总之,这段代码实现了一个简单的迭代方法来合并两个有序链表。
//方法二:递归
public ListNode mergeTwoLists(ListNode p1, ListNode p2) {
if(p1==null){
return p2;
}
if(p2==null){
return p1;
}
if(p1.val<p2.val){
p1.next=mergeTwoLists(p1.next,p2);
return p1;
}else {
p2.next=mergeTwoLists(p1,p2.next);
return p2;
}
}
这段代码是Java中用于合并两个有序链表的方法。给定的链表p1和p2都是有序的,因此我们可以通过比较它们的节点值来合并它们。
方法二:递归
- 如果p1为空,则返回p2;如果p2为空,则返回p1。
这是递归的终止条件。- 如果p1的值小于p2的值,我们将p1的下一个指针指向递归调用,该调用将p1的下一个节点与p2合并。然后返回p1。
- 如果p2的值小于或等于p1的值,我们将p2的下一个指针指向递归调用,该调用将p1和p2的下一个节点合并。然后返回p2。
总之,这段代码实现了一个递归方法来合并两个有序链表。递归方法的主要优点是代码更简洁,但可能会导致额外的栈空间使用。
力扣今日两刷:23. 合并 K 个升序链表[困难]
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [ 1->4->5, 1->3->4, 2->6 ] 将它们合并到一个有序链表中得到。 1->1->2->3->4->4->5->6示例 2:
输入:lists = [] 输出:[]示例 3:
输入:lists = [[]] 输出:[]提示:
k == lists.length0 <= k <= 10^40 <= lists[i].length <= 500-10^4 <= lists[i][j] <= 10^4lists[i]按 升序 排列lists[i].length的总和不超过10^4
/*
如果两个链表合并可以解决,那么多链表合并就可以解决,分治思想,将多链表先分为两个链表
*/
//分治思想:多路递归
public ListNode mergeKLists(ListNode[] lists) {
if (lists.length == 0) {
return null;
}
ListNode node = split(lists, 0, lists.length - 1);
return node;
}
//返回合并后的链表
private ListNode split(ListNode[] lists, int i, int j) {
if (i == j) {
return lists[i];
}
int m = (i + j) >>> 1;
ListNode left = split(lists, i, m);
ListNode right = split(lists, m + 1, j);
return mergeTowLists(left, right);
}
//合并两个链表 方法一:递归
private ListNode mergeTowLists(ListNode p1, ListNode p2) {
if (p1 == null) {
return p2;
}
if (p2 == null) {
return p1;
}
if (p1.val < p2.val) {
p1.next = mergeTowLists(p1.next, p2);
return p1;
} else {
p2.next = mergeTowLists(p1, p2.next);
return p2;
}
}
//合并两个链表 方法二:迭代
private ListNode mergeTowLists2(ListNode p1, ListNode p2) {
ListNode s = new ListNode(-1, null);
ListNode p = s;
while (p1 != null && p2 != null) {
if (p1.val < p2.val) {
p.next = p1;
p1 = p1.next;
} else {
p.next = p2;
p2 = p2.next;
}
p = p.next;
}
if (p1 != null) {
p.next = p1;
}
if (p2 != null) {
p.next = p2;
}
return s.next;
}
这段代码是Java中用于合并K个有序链表的方法。给定的链表数组lists包含了K个链表,每个链表都是有序的。
分治思想:多路递归
- 如果lists的长度为0,则返回null。
- 调用split方法,该方法将链表数组lists分成两半,并返回合并后的链表。
- split方法通过递归地将链表数组lists分成两半,然后将它们合并。
split方法:
- 如果i等于j,则返回lists[i]。
- 计算中间位置m,即将链表数组lists分成两半。
- 递归地将链表数组lists分成两半,并将它们合并。
合并两个链表的方法一:递归
- 如果p1为null,则返回p2;如果p2为null,则返回p1。这是递归的终止条件。
- 如果p1的值小于p2的值,我们将p1的下一个指针指向递归调用,该调用将p1的下一个节点与p2合并。然后返回p1。
- 如果p2的值小于或等于p1的值,我们将p2的下一个指针指向递归调用,该调用将p1和p2的下一个节点合并。然后返回p2。
合并两个链表的方法二:迭代
- 创建一个新的链表s,其值为-1,并且next为null。
- 创建一个指针p,初始值为s。
- 当p1和p2都不为null时,比较它们的值。
- 如果p1的值小于p2的值,则将p的下一个指针指向p1,并将p1的指针指向p1的下一个节点。
- 如果p2的值小于或等于p1的值,则将p的下一个指针指向p2,并将p2的指针指向p2的下一个节点。
- 将p指针移动到下一个节点。
- 最后,如果p1不为null,则将p的下一个指针指向p1;如果p2不为null,则将p的下一个指针指向p2。
- 返回s的下一个节点。
总之,这段代码实现了一个分治方法来合并K个有序链表。分治方法的主要优点是代码更简洁,但可能会导致额外的栈空间使用。
力扣今日三刷:876. 链表的中间结点
给你单链表的头结点
head,请你找出并返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。
示例 1:

输入:head = [1,2,3,4,5] 输出:[3,4,5] 解释:链表只有一个中间结点,值为 3 。示例 2:

输入:head = [1,2,3,4,5,6] 输出:[4,5,6] 解释:该链表有两个中间结点,值分别为 3 和 4 ,返回第二个结点。提示:
- 链表的结点数范围是
[1, 100]1 <= Node.val <= 100
//双指针:快慢指针
public ListNode middleNode(ListNode head) {
if(head.next==null){
return head;
}
ListNode p1 = head;
ListNode p2 = head;
while (p2!=null||p2.next!=null){
p1=p1.next;
p2=p2.next.next;
}
return p1;
}
这段代码是Java中用于找到链表的中间节点的的方法。给定的链表的头节点head。
双指针:快慢指针
- 如果链表只有一个节点,则返回该节点。
- 创建两个指针p1和p2,初始值都为头节点head。
- 进入while循环,当p2不为null且p2的下一个节点不为null时,将p1移动到下一个节点,将p2移动到下一个节点的下一个节点。(p1走一步,p2走两步,当p2走到头,p1所在的节点就是中间节点)
- 当p2为null或p2的下一个节点为null时,跳出循环。
- 返回p1节点,即链表的中间节点。
总之,这段代码实现了一个简单的方法来找到链表的中间节点。这种方法通过使用快慢指针来遍历链表,当快指针到达链表尾部时,慢指针恰好到达链表的中间位置。
2023/12/10
力扣每日一刷:234. 回文链表[困难]
给你一个单链表的头节点
head,请你判断该链表是否为回文链表。如果是,返回true;否则,返回false。示例 1:

输入:head = [1,2,2,1] 输出:true示例 2:
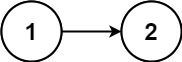
输入:head = [1,2] 输出:false提示:
- 链表中节点数目在范围
[1, 105]内0 <= Node.val <= 9进阶: 你能否用
O(n)时间复杂度和O(1)空间复杂度解决此题?
/*
1.找到链表中间节点
2.反转中间节点以后的链表
3.将反转后的链表与原来的链表比较
*/
public boolean isPalindrome(ListNode head) {
ListNode middle = this.middle(head);//1.找到链表中间节点
ListNode newHead = this.reverse(middle);//2.反转中间节点以后的链表
return this.compare(newHead, head);
}
//返回中间节点:双指针
private ListNode middle(ListNode p){
ListNode p1 = p;
ListNode p2 = p;
while (p2!=null&&p2.next!=null){
p1 = p1.next;
p2 = p2.next.next;
}
return p1;
}
//反转链表
private ListNode reverse(ListNode o1) {
ListNode n1 = null;//反转后的新链表
while (o1!=null){
ListNode o2 = o1.next;
o1.next = n1;
n1 = o1;
o1 = o2;
}
return n1;
}
//反转后的链表与原来链表做比较
private boolean compare(ListNode newHead, ListNode head) {
while (newHead!=null){
if(newHead.val!=head.val){
return false;
}
newHead = newHead.next;
head = head.next;
}
return true;
}
这段Java代码定义了一个名为
isPalindrome的方法,该方法接受一个链表的头节点作为参数,并返回一个布尔值,表示该链表是否为回文链表。以下是
isPalindrome方法的详细步骤:
- 找到链表中间节点:使用快慢指针法找到链表的中间节点。
- 反转中间节点以后的链表:使用迭代法反转中间节点以后的链表。
- 将反转后的链表与原来的链表比较:比较反转后的链表与原来的链表是否相等,相等则返回true,否则返回false。
以下是每个方法的详细说明:
- 找到链表中间节点:
- 定义一个名为
middle的方法,该方法接受一个链表节点p作为参数。- 初始化两个指针
p1和p2,都指向链表的头节点p。- 当
p2不为空且p2的下一个节点不为空时,将p1和p2分别向后移动一位。- 最后返回
p1,即链表的中间节点。
- 反转中间节点以后的链表:
- 定义一个名为
reverse的方法,该方法接受一个链表节点o1作为参数。- 初始化一个空链表
n1。- 使用迭代法反转链表,具体实现如下:
- 定义一个指向
o1的指针o2,初始时o2为o1的下一个节点。- 将
o1的下一个节点指向n1,即o1.next = n1。- 将
n1指向o1,即n1 = o1。- 将
o1指向o2,即o1 = o2。- 将
o2向后移动一位,即o2 = o2.next。- 当
o2不为空时,重复上述步骤,直到链表反转完成。- 最后返回
n1,即反转后的新链表。
- 将反转后的链表与原来的链表比较:
- 定义一个名为
compare的方法,该方法接受两个链表节点newHead和head作为参数。- 使用迭代法比较两个链表是否相等,具体实现如下:
- 当
newHead不为空时,比较newHead和head的值是否相等,如果不相等,返回false。- 将
newHead和head分别向后移动一位,即newHead = newHead.next和head = head.next。- 当
newHead为空时,说明两个链表相等,返回true。
代码优化版:将查找中间节点和反转链表放在同一个循环中,在查找中链表的过程同时反转前半部分的链表
/*
1.找到链表中间节点
2.反转中间节点以后的链表
3.将反转后的链表与原来的链表比较
*/
public boolean isPalindrome(ListNode head) {
ListNode p1 = head;//慢指针
ListNode p2 = head;//快指针
ListNode n1 = null;//反转后新链表头结点
ListNode o1 = head;//旧链表的头结点
while (p2!=null&&p2.next!=null){
//查找中间节点
p1 = p1.next;
p2 = p2.next.next;
//反转前部分链表
ListNode o2 = o1.next;//记录旧链表的头结点的下一个节点
o1.next = n1;
n1 = o1;
o1 = o2;
}
//如果链表节点数为奇数,则从中间链表的下一个节点开始与反转链表进行比较
if(p2!=null){
p1 = p1.next;
}
while (n1 !=null){
if(n1.val!= p1.val){
return false;
}
n1 = n1.next;
p1 = p1.next;
}
return true;
}
这段代码定义了一个名为
isPalindrome的方法,该方法接受一个链表的头节点作为参数。该方法的主要目的是检查给定的链表是否为回文链表。以下是代码的详细解释:
首先,定义了三个指针:
p1、p2和n1。p1和p2用于找到链表的中间节点,而n1用于存储反转后新链表的头结点。然后,定义了两个指针:
o1和o2。o1指向旧链表的头结点,而o2指向旧链表的头结点的下一个节点。在循环中,
p1和p2指针分别向前移动两个节点。当p2的下一个节点不为空时,继续循环。在循环内部,首先记录旧链表的头结点的下一个节点
o2。然后,将o1的下一个节点设置为n1,并将n1设置为o1。接着,将o1设置为o2,继续循环。当循环结束时,如果
p2的下一个节点为空,说明链表长度为奇数,中间节点需要跳过。否则,说明链表长度为偶数,不需要跳过。接下来,使用
n1指针遍历反转后的新链表,并与原始链表进行比较。如果两个链表的节点值不相等,则返回false,表示链表不是回文链表。如果遍历结束后没有找到不相等的节点,则返回true,表示链表是回文链表。
力扣每五日一总结【12/06–12/10】
2023/12/06
- 方法一:直接反转:创建一个新链表,然后对旧链表进行迭代,将每次迭代出节点的值添加到新链表的头部
~~优点:~~理解容易,代码简单 ~~缺点:~~空间成本大,需要额外创建节点,节点无法重复利用
- 方法2 :面向对象思想:由于题目中给的链表只有一个链表的头结点,我们可以运用面向对象思想,为链表创建一个容器,即创建一个链表对象,然后通过操作链表对象,实现递归旧链表,每次将旧链表的头节点移除并记录,添加到新链表的头部,实现链表反转。
优点:理解容易,实现了节点重复利用,空间成本低缺点:代码量大,还需要另外创建链表类
- 方法三:利用递归的方式,先递归找到最后一个节点,利用递归的特点,在弹栈时就相当于逆向遍历链表,可以对链表实现逆向操作,在弹栈时,实现将当前节点的下一个节点的的下一个节点指向当前节点,实现相邻两个节点的反转,最终实现链表反转。~~优点:~~代码量少,代码看着简洁而优雅
~~缺点:~~对递归不熟悉的小伙伴理解上有难度
方法四:相当于用两个指针模拟出两个链表,实际上在操作一个链表,其中一个指针始终指向新链表的头部,另一个指针始终指向旧链表的头部,不断将旧链表的第二个节点指向新链表的头部,指针回位,循环操作,实现链表反转
~~优点:~~代码量少 ~~缺点:~~指针太多,并不好理解
方法五:和方法二在思想上有异曲同工之妙,但是更面向过程
~~优点:~~代码量少 ~~缺点:~~指针太多,并不好理解
2023/12/07
- 方法一:双指针
? 定义两个指针,其中一个快指针用于扫描链表,另一个慢指针用于生成链表,当快指针扫描到的节点数据与题目中的数据一致时,即该节点需要删除,则使用慢指针的next直接指向快指针的next,即跳过待删除的指针,即可删除节点。
- 方法二:递归
? 递归方法本意为:返回从当前节点开始的所有节点,递归方法中判断,如果当前节点的数据等于题目所给的数据,则证明当前节点需要被删除,则递归调用当前方法,传入当前节点的下一节点,即删除当前节点,如果当前节点的数据不等于题目所给的数据,则递归调用当前方法更新当前节点的下一节点,返回当前节点。
双指针:定义两个指针,一开始两个节点均指向哨兵节点,然后将其中一个快指针在方法开始时就移动n+1步(n为题目所给的倒数第n个节点),然后将两个指针同时移动,当快指针指向null时,慢指针刚好指向的为倒数第n+1个节点,即待删除节点的上一节点,此时只需将慢指针指向的节点的下一个节点指向下下个节点,即可完成对待删除节点的删除。
方法二:递归:
? 递归方法的本意为:返回当前节点是倒数第几个节点,递归方法中判断如果当前节点的下一个节点等于题目所给的值,则证明当前节点的下一个节点是需要被删除的,则向当前节点的下一节点直接指向当前节点的下一个节点的下一个节点,即删除当前节点的下个节点,至于当前节点的下一个个节点是倒数第几个节点如何得知,只需要递归调用当前方法,传入当前节点的下一个节点的即可。
2023/12/08
方法一:双指针
首先创建一个哨兵节点
s,并将其指向链表的头节点head。定义两个指针
p1和p2,分别指向哨兵节点s和s.next(即链表的头节点)。当
p2不为空时,进行以下操作:
a. 如果p1.val和p2.val相等,说明当前节点是重复的,将p1.next指向p2.next,即将当前节点的下一个节点从链表中删除。然后将p2指向下一个节点,继续遍历。
b. 如果p1.val和p2.val不相等,说明当前节点不是重复的,将p1指向下一个节点,即p1 = p1.next。然后将p2指向下一个节点,继续遍历。遍历结束后,返回哨兵节点
s的下一个节点,即链表的头节点。方法二:递归
如果链表为空或者链表只有一个节点,直接返回链表的头节点。
如果当前节点的值等于下一个节点的值,说明当前节点是重复的,直接返回下一个节点去除重复元素后的链表的头节点。
如果当前节点的值不等于下一个节点的值,说明当前节点不是重复的,将下一个节点去除重复元素后的链表的头节点接到当前节点的下一个节点,然后返回当前节点。
~~递归的核心思想是:~~将去除重复元素后的链表的头节点接到当前节点的下一个节点,然后返回当前节点。这样就可以实现从底层逐步向上去除重复元素。
递归
首先,判断输入的链表(p)是否为空或者只有一个节点,如果是,则直接返回该链表。
如果当前节点的值(p.val)与下一个节点的值(p.next.val)相等,则需要删除重复的节点。具体操作如下: a. 创建一个指针p1,初始时指向当前节点的下一个节点。 b. 使用while循环,当p1不为空且p1的值与当前节点的值相等时,将p1指向下一个节点。 c. 最后,返回删除重复节点后的链表,即deleteDuplicates(p1)。
如果当前节点的值与下一个节点的值不相等,则说明当前节点不需要删除,直接将当前节点的指针(p.next)指向下一个节点的递归结果,即deleteDuplicates(p.next),然后返回当前节点。
总之,这个方法通过递归地处理链表中的每个节点,实现了删除重复元素的目的。
非递归:三指针
首先,创建一个哨兵节点(sentry node),将其指向链表的头节点(head)。
然后,定义三个指针:p1、p2 和 p3。p1 指向哨兵节点,p2 指向 p1 的下一个节点,p3 指向 p2 的下一个节点。
进入循环,当 p2 不为空且 p3 不为空时,执行以下操作: a. 比较 p2 和 p3 的值。如果它们相等,说明 p2 和 p3 指向的节点是重复的,需要删除。 i. 首先,通过循环找到下一个不等于 p2.val 的节点 p3。 ii. 然后,将 p1 的下一个节点指向 p3,即 p1.next = p3。 b. 如果 p2 和 p3 的值不相等,说明它们指向的节点不是重复的,将 p1 指向 p2 的下一个节点,即 p1 = p1.next。
循环结束后,返回哨兵节点的下一个节点,即 s.next。
总之,这段代码通过非递归、三指针的方法实现了删除链表中的重复元素。
一次遍历
首先,创建一个哨兵节点(sentinel node)
s,其值为-1,并将其next指针指向链表的头节点head。这样做的目的是为了方便处理链表的第一个节点可能也是重复的节点的情况。然后,定义一个指针
cur,初始时指向哨兵节点s。进入循环,当
cur.next不为空且cur.next.next不为空时,继续循环。在循环中,判断
cur.next和cur.next.next的值是否相等。如果相等,说明这两个节点是重复的,需要删除。此时,我们定义一个变量x来存储重复的值,然后使用一个while循环来删除重复的节点。循环的条件是cur.next不为空,并且cur.next.val等于x。在循环中,将cur.next指向cur.next.next,从而删除重复的节点。如果
cur.next和cur.next.next的值不相等,说明它们不是重复的节点,将cur指向cur.next,继续遍历下一个节点。最后,返回哨兵节点的下一个节点,即原始链表的头节点。
2023/12/09
方法一:迭代
首先,我们创建一个新的链表s,它的头节点是一个值为-1的节点,后面跟着一个空节点。这个新链表将用于存储合并后的节点值。
然后,我们创建一个指针p,指向新链表的哨兵节点s。
接下来,我们使用一个while循环来遍历p1和p2链表。在每次循环中,我们比较p1和p2节点的值。
如果p1节点的值小于p2节点的值,我们将p节点的下一个指针指向p1节点,然后将p1节点向前移动一位。
如果p2节点的值小于或等于p1节点的值,我们将p节点的下一个指针指向p2节点,然后将p2节点向前移动一位。
最后,我们更新p指针,以便在下一轮循环中指向下一个节点。
当p1或p2链表遍历完毕后,我们将另一个链表的剩余节点直接添加到新链表的末尾。
最后,我们返回新链表的第一个节点,即s.next。
总之,这段代码实现了一个简单的迭代方法来合并两个有序链表。
方法二:递归
如果p1为空,则返回p2;如果p2为空,则返回p1。
这是递归的终止条件。如果p1的值小于p2的值,我们将p1的下一个指针指向递归调用,该调用将p1的下一个节点与p2合并。然后返回p1。
如果p2的值小于或等于p1的值,我们将p2的下一个指针指向递归调用,该调用将p1和p2的下一个节点合并。然后返回p2。
总之,这段代码实现了一个递归方法来合并两个有序链表。递归方法的主要优点是代码更简洁,但可能会导致额外的栈空间使用。
- 分而治之思想:
? 分治思想:多路递归
- 如果lists的长度为0,则返回null。
- 调用split方法,该方法将链表数组lists分成两半,并返回合并后的链表。
- split方法通过递归地将链表数组lists分成两半,然后将它们合并。
split方法:
- 如果i等于j,则返回lists[i]。
- 计算中间位置m,即将链表数组lists分成两半。
- 递归地将链表数组lists分成两半,并将它们合并。
合并两个链表的方法一:递归
- 同上一题!
合并两个链表的方法二:迭代
- 同上一题!
总之,这段代码实现了一个分治方法来合并K个有序链表。分治方法的主要优点是代码更简洁,但可能会导致额外的栈空间使用。
双指针:
如果链表只有一个节点,则返回该节点。
创建两个指针p1和p2,初始值都为头节点head。
进入while循环,当p2不为null且p2的下一个节点不为null时,将p1移动到下一个节点,将p2移动到下一个节点的下一个节点。(p1走一步,p2走两步,当p2走到头,p1所在的节点就是中间节点)
当p2为null或p2的下一个节点为null时,跳出循环。
返回p1节点,即链表的中间节点。
总之,这段代码实现了一个简单的方法来找到链表的中间节点。这种方法通过使用快慢指针来遍历链表,当快指针到达链表尾部时,慢指针恰好到达链表的中间位置。
2023/12/10
处理链表各类方法组合运用:
找到链表中间节点:使用快慢指针法找到链表的中间节点。
反转中间节点以后的链表:使用迭代法反转中间节点以后的链表。
将反转后的链表与原来的链表比较:比较反转后的链表与原来的链表是否相等,相等则返回true,否则返回false。
以下是每个方法的详细说明:
找到链表中间节点:
- 定义一个名为
middle的方法,该方法接受一个链表节点p作为参数。- 初始化两个指针
p1和p2,都指向链表的头节点p。- 当
p2不为空且p2的下一个节点不为空时,将p1和p2分别向后移动一位。- 最后返回
p1,即链表的中间节点。反转中间节点以后的链表:
- 定义一个名为
reverse的方法,该方法接受一个链表节点o1作为参数。- 初始化一个空链表
n1。- 使用迭代法反转链表,具体实现如下:
- 定义一个指向
o1的指针o2,初始时o2为o1的下一个节点。- 将
o1的下一个节点指向n1,即o1.next = n1。- 将
n1指向o1,即n1 = o1。- 将
o1指向o2,即o1 = o2。- 将
o2向后移动一位,即o2 = o2.next。- 当
o2不为空时,重复上述步骤,直到链表反转完成。- 最后返回
n1,即反转后的新链表。将反转后的链表与原来的链表比较:
- 定义一个名为
compare的方法,该方法接受两个链表节点newHead和head作为参数。- 使用迭代法比较两个链表是否相等,具体实现如下:
- 当
newHead不为空时,比较newHead和head的值是否相等,如果不相等,返回false。- 将
newHead和head分别向后移动一位,即newHead = newHead.next和head = head.next。- 当
newHead为空时,说明两个链表相等,返回true。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!