滴水逆向三期笔记和作业-c语言总结4
第十八课 c语言11 字符串与数组
这一节课b站缺失了,参考一下大佬的笔记学习,链接:滴水三期:day21.1-字符数组与字符串_如果一个值溢出某个变量的数据类型存储范围,但仍然存入该变量,那么存入该变量中的-CSDN博客
1.字符数组
char arr[10] = {'A','B','C','D','E','F'};? ? //编译器默认在结尾添加0x00
char arr[3] = {'A','B','C'};? ? ? ? ? ? ? ? ? ? //但是如果没有留出'\0'的空间,编译器就不会自动添加
char arr2[6] = {'A','B','C','D','E',0};? ? ?//注意区分这里的0不是'0'
char buffer[100] = "";? ? ? ? ? ? ? ? ? ? ? ? //定义了一个空字符串,字符串中每个字节默认初始为0x00
char buffer[] = ""; ?????????????????????????????//这个数组长度只有1,且默认初始为0x00
总结:
定义字符数组来表示字符串时,一定要在结尾给'\0',我们可以手动添加,也可以不添加让编译器自己自动帮我们在结尾处添加'\0',但是一定要注意如果让编译器添加的话,要把字符数组的宽度的长度设置好,一定要预留空间给'\0'
2.字符串
也是字符数组的一种,字符串就会经常在常量区
char names[] = "ABCDE";
//可以省略数组大小,但是此时的数组大小应该6,因为编译器会自动在末尾加0x00
char* p = "ABCDE";
//这个是将常量区中存储ABCDE字符串的首地址赋给p,此时p的长度是4字节,常量区的字符
char arr1[6] = {'A','B','C','D','E','\0'};
char arr2[6] = {'A','B','C','D','E',0}; //注意区分这里的0不是'0'
char arr3[6] = {'A','B','C','D','E'}; //只要比5大,数组的长度随便
char names[] = "ABCDE";
printf("%s\n",arr1);
printf("%s\n",arr2);
printf("%s",names);
char word[8];
scanf("%7s", word);//最多读7个字符- %s的用法:打印一个字符串,直到内存为 0 为止。这个0相当于16进制的0,平时我们用则使用0或者'\0'来表示
3.常量区
前面有一张内存图,现在来说说之前没讲到的全局变量和常量区

这是海哥上课的例子代码
char* x = "china";
//x中存的就是存储在常量区的china字符串的首地址,x指针型变量直接指向常量区中的存储china字符串的首地址
char y[] = "china";
//这里也是常量区中的china字符串,但是与指针不同的是,这里会将字符串值复制一份到给y字符数组变量分配的内存中(栈)
void Func(){
y[1] = 'A'; //可以修改
*(x + 1) = 'A'; //无法修改
x = "ABC"; //可以修改,相当于重新指向ABC这个新的地址
}先从反汇编层面看看

可以看到x变量存储的直接就是china常量区的地址,而y存储的是china拷贝过来的值而且放到堆栈里,所以x无法修改但是y数组可以
总结:
- *(x+1) = 'A'是尝试去修改常量区china字符串的值,因为常量区可读不可写,所以修改失败
- y数组由于修改的是拷贝过来的堆栈区,所以可以修改成功
- x = "ABC";也可以修改成功,相当于重新指向ABC这个新的地址
作业一

错误示范
我们要用int类型搜索内容,一次搜四个字节,但是int类型+1后下一次搜索就是每隔四个字节搜一次,而我们现在需要用int类型每隔一个字节搜一次,所以出现下面的错误代码

#include "stdafx.h"
char data[100] = { //全局变量
0x00,0x01,0x02,0x03,0x04,0x05,0x06,0x07,0x07,0x09,
0x00,0x20,0x10,0x03,0x03,0x0C,0x00,0x00,0x44,0x00,
0x00,0x33,0x00,0x47,0x0C,0x0E,0x00,0x0D,0x00,0x11,
0x00,0x00,0x00,0x02,0x64,0x00,0x00,0x00,0xAA,0x00,
0x00,0x00,0x64,0x10,0x00,0x00,0x00,0x00,0x00,0x00,
0x00,0x00,0x02,0x00,0x74,0x0F,0x41,0x00,0x00,0x00,
0x01,0x00,0x00,0x00,0x05,0x00,0x00,0x00,0x0A,0x00,
0x00,0x02,0x74,0x0F,0x41,0x00,0x06,0x08,0x00,0x00,
0x00,0x00,0x00,0x64,0x00,0x0F,0x00,0x00,0x0D,0x00,
0x00,0x00,0x23,0x00,0x00,0x64,0x00,0x00,0x64,0x00
};
int length = sizeof(data) / sizeof(data[0]);
void find_blood(int num,int width){ //输入要查找的数值,查找宽度
if(width == 1){
for(int i = 0;i < length - width + 1;i++){
if(*(data + i) == num)
printf("add:%x num:%d\n",data + i,*(data + i));
}
}else if(width == 2){
for(int i = 0;i < length - width + 1;i++){
short* p = (short*)(data + i); //直接使用char* data++,但是每次判断前把当前地址转型赋给一个新short* p即可,不需要上面那么麻烦
if(*p == num){
printf("add:%x num:%d\n",p,*p);
}
}
}else if(width == 4){
for(int i = 0;i < length - width + 1;i++){
int* p = (int*)(data + i);
if(*p == num){
printf("add:%x num:%d\n",p,*p);
}
}
}else{
printf("宽度不符合规定");
}
}
int main(int argc, char* argv[])
{
printf("%x\n",data);
find_blood(256,2);
getchar();
return 0;
}这把借鉴作业了
还有个改进前的思路也可以看看
void findblood(int size){
if(size == 2){ //数值类型为short时,即2字节
short* temp = (short*)blood; //因为每次定位到一个地址,要查的数是从这往后2字节,所以先强转
for(int i = 0;i < 100 - size + 1;i++){
if(*(temp) == 100){ //因为temp是short*类型,所以取的地址宽度为2字节
printf("%x\t%d\n",temp,*temp);
}
char* temp2 = (char*)temp; //因为要一个一个地址挨着找,所以先转换成char*类型,如果拿 short*的temp直接++,那么结果就是源temp中地址+2*1,就不是依次逐个地址找了,就是跳了一个
temp2++; //那么char*变量在++时,结果为:地址 + char宽度,即下一个地址
temp = (short*)temp2;//然后再将下一个地址的值赋给temp,下次比较就是从temp往后数2字节是否 是0x0064
}
}else if(size == 4){ //数值类型为int时,即4字节
int* temp = (int*)blood;
for(int i = 0;i < 100 - size + 1;i++){ //因为如果4字节为单位,则查到倒数第4个地址就是最后 一个地址了,就不用继续我往后查了
if(*(temp) == 100){
printf("%x\t%d\n",temp,*temp);
}
char* temp2 = (char*)temp;
temp2++;
temp = (int*)temp2;
}作业二

1、
2、

3、

注意:x数组需要给大一点的空间,否则在y赋值过去后,没有足够的空间来容纳两个字符串的拼接结果,可能会导致超出数组界限的访问,进而引发未定义的行为。

打印调试出错误

虽然我感觉我理解错题意了下面代码,不过就这样吧
char datas[] = { 0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x07, 0x09,
0x00, 0x20, 0x10, 0x03, 0x03, 0x0C, 0x00, 0x00, 0x44, 0x00,
0x00, 0x33, 0x00, 0x47, 0x0C, 0x0E, 0x00, 0x0D, 0x00, 0x11,
0x00, 0x00, 0x00, 0x02, 0x64, 0x00, 0x00, 0x00, 0xAA, 0x00,
0x00, 0x00, 0x64, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x02, 0x00, 0x74, 0x0F, 0x41, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x0A, 0x00,
0x00, 0x02, 0x57, 0x4F, 0x57, 0x00, 0x06, 0x08, 0x00, 0x00,
0x00, 0x00, 0x00, 0x64, 0x00, 0x0F, 0x00, 0x00, 0x0D, 0x00,
0x00, 0x00, 0x23, 0x00, 0x00, 0x64, 0x00, 0x00, 0x64, 0x00 };
int length = sizeof(datas) / sizeof(datas[0]);
void FindNameAddr(char* pData, char* pName,int width)
{
if (width == 1)
{
for (int i = 0; i < length - width + 1; i++)
{
if (*(pData+i) == *pName)
{
if(*(pData + i +1) == *(pName+1))
if (*(pData + i + 2) == *(pName + 2))
printf("addr:%x\n",pData+i);
}
}
}
else if (width == 2)
{
for (int i = 0; i < length - width + 1; i++)
{
short* ret = (short*)(pData+i);
if (*ret == *((short*)pName))
{
if(*(ret+1) == *((short*)pName+1))
printf("addr:%x\n", pData + i);
}
}
}
else if (width == 4)
{
for (int i = 0; i < length - width + 1; i++)
{
int* ret = (int*)(pData + i);
if (*ret == *((int*)pName))
{
printf("addr:%x\n", pData + i);
}
}
}
else
{
printf("宽度输入错误");
}
}
int main()
{
FindNameAddr(datas, (char*)"WOW", 4);
}第十九课 c语言12 指针数组 结构体指针
1.指针数组
赋值

常见的指针数组
把"if""for"这些常量的地址放入数组


2.结构体指针
赋值取值

思维不被限制,结构体指针指向的地址不是结构体也可以,只是他的内存宽度对应不上,但是强转后编译器能编译通过,不管指向的地址后面是什么都打印出来就完事了

作业
问题

1、答


问题

答?

总结:
结构体指针和结构体的取值也不一样,ret->id和p.id
第二十课 c语言13 多级指针 数组指针 函数指针
1.多级指针反汇编
一二级指针
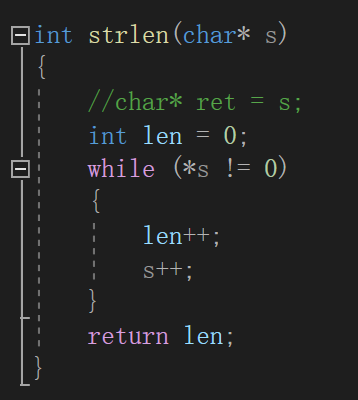
可以看到*p1== *(p1+0) == p1[0]


本来一直没想懂为什么是movsx ecx,byte ptr [eax],是byte,才发现p1是char*类型,所以才得用movsx拓展

*(p1+2) == p1[2],指针可以用*和[]取值,他们是一样的
*(*(*(p3+1)+2)+3) == p3[1][2][3]

在*(*(p2+1)+1)中,(*(p2+1)+1)是char**类型,所以他的+1等于+4,*(p2+1)是char*类型,他的+1就是+1

三级指针
p3是char***类型,*p3是char**类型,*(*p3)是char*类型,*(*(*p3))是char类型

总结:

2.数组指针
基本特性

数组指针的*p和p

虽然*px和px的值一样,但是类型不一样,所以运算出来的值也不一样
疑问?
为什么px的值会和*px一样?
看一下反汇编

px这个值的地址存放的就是1,那我*px就是取0113FD38这个地址的值,为什么不是取出1呢
写个普通的例子,他*px是会取出px的值后再取一次

答
px的类型是int (*)[2],所以是指向arr数组首地址,*px的类型是int [2],还是一个数组类型,数组类型的含义还是数组的首地址,所以*px的值还是一个地址,参考直接arr的时候,arr取值还是一个数组首地址。
总结:
多去使用砍星看看目前的变量是什么类型
运算才需要砍星,px的本身类型是int (*)[2],这个类型的宽度是4,虽然是数组指针但也熟是个指针类型的宽度
数组指针运算
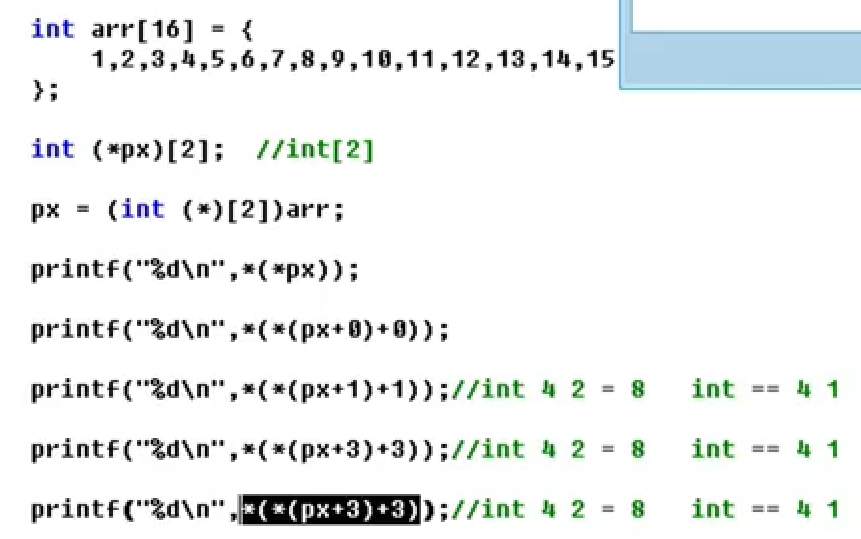
*(px+1)就先把px的类型(int (*)[2])砍个星,那么现在砍完是int [2],那么*(px+1)等于px+8
*(*(px+3)+3) px+3算完是int [2]类型,要继续+3运算就继续砍星,int [2]砍完是int类型,所以*(*(px+3)+3)第二个+3就是+12
总结:
- 运算记得砍星砍类型宽度
- *(*(px+3)+3)相当于px[3][3]
3.多维数组指针
一维数组
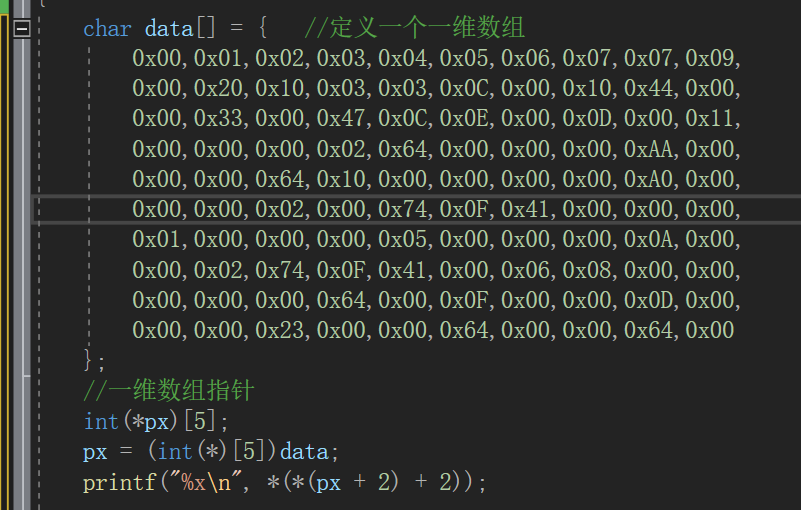
通过上面数组指针的运算已经练的很熟练了,+48,指向第49个数据也就是0xA0,但是我们的数据类型是int (*)[5],宽度为4,所以读出来的数据是000000A0
二维数组
二维数组运算

一样砍星运算,*(px+3)要运算砍星后的类型是char [2][3],所以+3等于+18,*(*(px+3)+2)运算砍星后的类型是char[3],所以+2等于+6
4.函数指针
代码也是数据
基础特征
函数指针宽度还是4,但是由于砍星后宽度不确定,无法进行加减运算,但是可以比较大小

赋值
定义的函数指针的返回值和参数,要和在赋值的函数的返回值和参数一样,否则一运行就挂了,可以强制转型编译成功但是一运行还是会挂

函数也是一段数据
论证函数其实也就是一段数据,这段数据的地址被指向函数指针时,可以被当做函数执行,强转欺骗编译器


作业

1、不完全正确,不要这么理解,指针就是指针,爱指哪就指哪,指针只是操作数据的工具
第二十一课 c语言14 位运算
1.什么是位运算
- 位运算效率高
- 计算机的加减乘除所有运算到最后都需要位运算
- 位运算还可以用于加密
2.汇编中的算数位移指令
- SAL(Shift Arithmetic Left):算术左移(和SHL效果一样)
- SAR(Shift Arithmetic Right):算术右移
- 格式:即算数移位指令后面的第一个操作数是寄存器或者内存;第二个操作数是寄存器或者立即数

反汇编例子
0x81二进制为10000001,左移一位后为00000010,左边最高位给cf,右边最低位补0
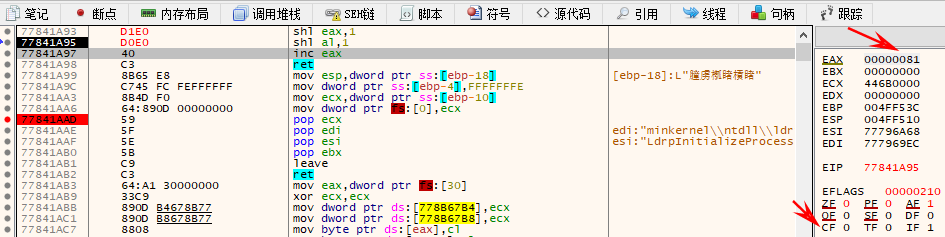

如果是用eax寄存器的话最高位的1就直接左移,不用移到cf标志位了
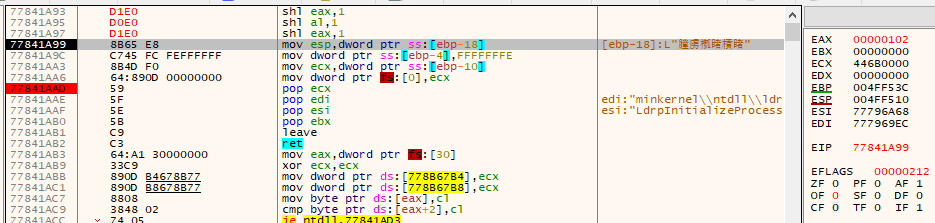
0x81二进制为10000001,右移一位后为11000000,左边补最高位,右边最低为的移到cf标志位

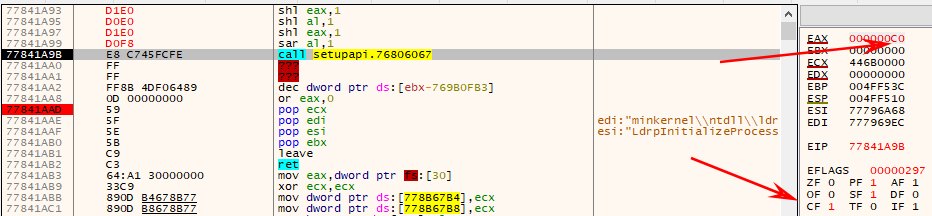
3.逻辑移位指令
- SHL(Shift Left):逻辑左移
- SHR(Shift Right):逻辑右移
左移和算数移位指令一样,右移就不一样,最左边补0

4.循环移位指令
- ROL(Rotate Left):循环左移
- ROR(Rotate Right):循环右移

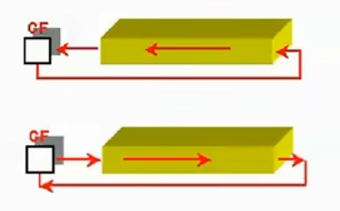
5.带进位的循环移位指令
- RCL(Rotate through Carry Left):带进位循环左移
- RCR(Rotate through Carry Right):带进位循环右移
作业

第二十二课 c语言15 内存分配
1.c程序的执行步骤
- 替换 -->编译 -->链接 -->装入内存 --> 执行
2.宏定义
无参数
#define 标识符 字符序列
#define DEBUG 1
void Function(){
//....
if(DEBUG)
printf("测试信息");
} 有参数
#define 标识符(参数表) 字符序列
类似定义函数,但是define是把标识符直接替换成后面字符序列(函数执行代码),不会在堆栈创建空间
#define MAX(A,B) ((A) > (B)?(A):(B))
void Func(){
int x = MAX(1,2);
}注意事项:
- 宏名标识符与左圆括号之间不允许有空白符,应紧接在一起
- 宏与函数的区别:函数分配额外的堆栈空间,而宏只是替换
- 为了避免出错,宏定义中给形参加上括号
- 末尾不需要分号
- define可以替代多行的代码,记得后面加
\?(一行写不下,就加\接着下一行写)
#define MALLOC(n,type)\
((type*)malloc((n)*sizeof(type)))3.动态分配内存
前面学习的int x; char arr[100];都是静态申请内存,今天学学动态的申请内存
malloc函数
作用:分配所指定大小的内存空间,并返回一个指向它的指针,如果内存空间不够,则返回NULL
声明:
#include "stdlib .h"
void* malloc(size_t size)void*
void*表示任何类型的指针,在需要的时候再去强转成我们需要的对应类型指针,比如malloc动态申请内存,要返回一个指向内存的指针,但是我们声明时不知道要用一个什么类型的指针,那么返回值可以使用void*,因此宽度就不确定,无法做加减运算
使用:
//在堆中申请内存,分配128个int
int* ptr = (int *)malloc(sizeof(int)*128); //假设这块内存要给一个int型数组使用,将void*强转int*
//无论申请的空间大小,一定要进行校验,判断是否申请成功
if(ptr == NULL){
return 0;
}
//初始化分配的内存空间,将分配的这片内存中全设为0(可以不用加,这里是害怕这块内存中有别人留下的数据)
memset(ptr,0,sizeof(int)*128);
//使用内存
*(ptr) = 1; //使用指针来操作指向的内存中的数据
//使用完毕,释放申请的堆空间
free(ptr);
//将指针设置为NULL。因为这次我使用了ptr指针,我用完之后ptr应该还是指向了最后的内存中的地址,如果有坏蛋尝试使用了ptr指针,即用完后又使用了ptr指针,那很可能把原先指向的内存中的其他数据给读出来了,不安全。如果设置了NULL,后面不小心使用ptr,会报错
ptr = NULL;内存泄露问题:
我们平时如果在函数外定义一个变量,分配的内存在全局区;在函数内定义一个变量,分配的内存在堆栈;使用完这个变量,也不用我们手动的去释放分配的内存空间,因为堆栈平衡等原因,使用完后这些内存中的数据就变成了垃圾,下一次再使用赋初始值覆盖这块内存中的数据即可。
但是现在如果我们使用malloc函数动态申请内存,分配的内存空间在堆中,堆有一个特点,如果此时一个数据占用了堆中的某块内存,那么操作系统就会记住这块内存已经分配出去了,其他数据就不能占用了,要么等待释放、要么此exe程序退出后,其他的数据才能再使用这块内存。
但是像服务器上运行的程序,会长时间运行,使用malloc函数申请内存,如果使用完没有释放,就会造成这块内存一直被占用,当数据庞大时,会将堆全部占住,最后内存占用率会很高,程序就会奔溃,这就是内存泄露问题(堆)。所以一定要释放内存
作业


#pragma warning(disable:4996)//忽略函数不安全警告
int F_Size(FILE* fp)
{
fseek(fp, 0, 2);
int len = ftell(fp);
fseek(fp, 0, 0);
return len;
}
void F_exe()
{
FILE* fp;
fp = fopen("C:\\Windows\\notepad.exe","rb");
char* addr = (char*)malloc(F_Size(fp));
if (addr)
{
fread(addr, F_Size(fp),1,fp);
}
printf("%x",addr);
free(addr);
fclose(fp);
}
int main()
{
F_exe();
}
ftell函数和fseek函数
返回当前文件位置指示符,可以和fseek函数联合使用,先使用fseek把文件指针定位到文件尾部,ftell就可以返回当前文件位置距离文件头还有多少字节,从而计算出文件大小
流 stream 的文件位置为给定的偏移 offset,参数 offset 意味着从给定的 whence 位置查找的字节数。
int fseek( FILE *stream, long offset, int origin );
第一个参数stream为文件 指针
第二个参数offset为 偏移量 ,正数表示正向偏移,负数表示负向偏移
第三个参数origin设定从文件的哪里开始偏移,可能取值为:SEEK_CUR、 SEEK_END 或 SEEK_SET
SEEK_SET: 文件开头
SEEK_CUR: 当前位置
SEEK_END: 文件结尾
其中SEEK_SET,SEEK_CUR和SEEK_END依次为0,1和2.
简言之:
fseek(fp,100L,0);把文件内部 指针 移动到离文件开头100字节处;
fseek(fp,100L,1);把文件内部 指针 移动到离文件当前位置100字节处;
fseek(fp,-100L,2);把文件内部 指针 退回到离文件结尾100字节处。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《PySpark大数据分析实战》-09.Spark独立集群安装
- 数字电位器AD5262
- uniapp 微信小程序自带实时线上日志
- JavaScript变量
- 新版a_bogus算法分析
- LED闪烁
- (5)shell命令以及Linux的权限
- 在当前bash(sh)中执行脚本和注册函数
- UltraScale 和 UltraScale+ 生成已加密文件和已经过身份验证的文件
- 三网话费余额查询的API系统,基于thinkphp6.0框架,附带搭建教程