Kafka_01_Kafka初识
发布时间:2023年12月31日
Kafka
Kafka: ZooKeeper协调的分布式消息系统
- 基于Scala语言编写的高性能、多分区、多副本
- Kafka高性能的原因:页缓存、顺序IO、零拷贝
具有以下特性:
- 消息中间件: 系统解耦、冗余存储、流量消峰、异步通信等
- 存储系统: 通过消息持久化和多副本机制实现消息落盘
- 流处理: 为流式处理框架提供可靠的数据来源和库
Kafka组成: 若干个Producer、Consumer、Broker和ZooKeeper集群
- Producer(生产者): 生产并发送消息到Broker(推送)
- Consumer(消费者): 从Broker订阅并消费消息(拉取)
- Broker(服务代理节点): 将从Producer收到的消息进行落盘
- ZooKeeper集群:管理Kafka集群的元数据
// Broker可看成单个独立的Kafka服务实例, 多个Broker组成个Kafka集群
如: Kafka集群构成

基础概念
主题(Topic): Kafka中消息归类单位
- Topic并不实际存在(仅逻辑上的概念)
- Topic可细分为多个Partition, 但Partition仅属于单个Topic
- 功能: Producer将消息发送到特定Topic, Consumer订阅Topic消费消息
分区(Partition): 组成Topic的单位(实际存储消息)
- Partition在存储层面可视为: 可被追加的日志文件
- 同一Topic下的不同Partition包含的消息是不同的
- Partition可跨Broker(Topic可跨Broker)
偏移量(Offset): 消息追加到Partition时分配的标志位
- Offset是消息在Partition中的唯一标识(保证Partition内的有序性)
- Offset不支持跨Partition(Topic无序)
如: 消息追加写入Partition
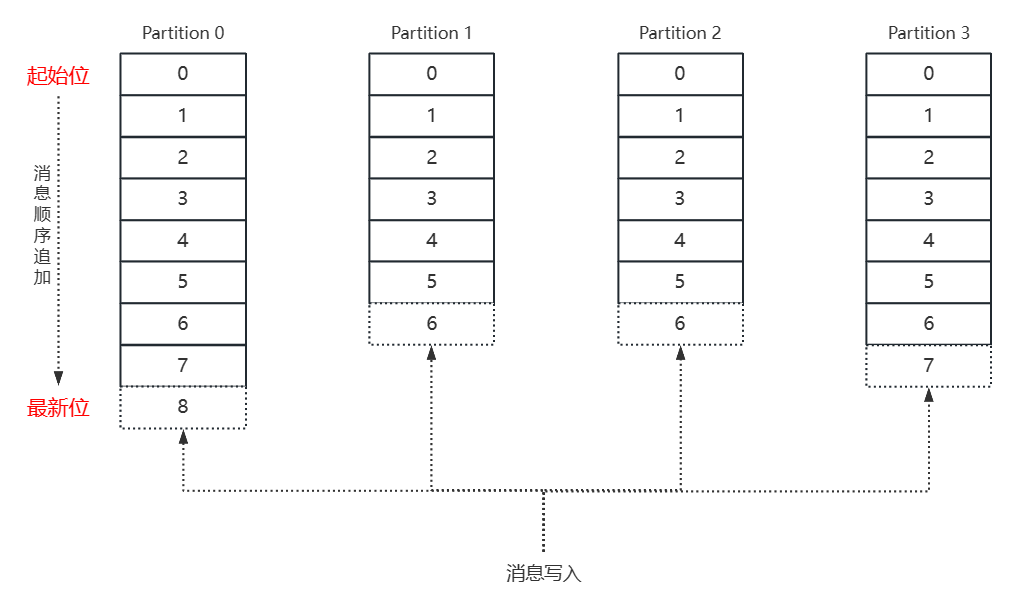
- 消息在发送到Broker之前, 都会先根据Partition规则分配到具体的Partition
- Topic的Partition应避免都属于单个文件(避免机器的I/O成为性能瓶颈)
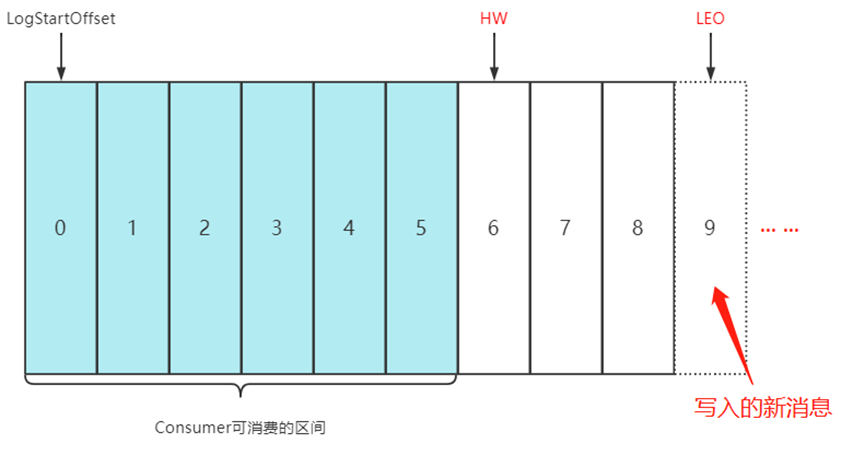
Partition中2个特殊的Offset:
- HW(High Watermark): Consumer能拉取到消息的最大Offset
- LEO(Log End Offset): Partition下条消息写入的Offset
// ISR中最小的LEO为该Partition的HW(最慢的follower)
如: Partition中的特殊Offset
副本(Replica): Partition的冗余
- 功能: Kafka通过多副本机制提高容灾能力
- 副本之间分为:leader(主副本)、follower(从副本)
- 副本间仅存在一主多从关系, 且可实现自动故障转移
- Producer和Consumer只能和leader进行交互(follower仅进行消息同步)
如: Kafka的多副本交互

副本相关名词:
- AR(Assigned Replicas): 所有副本(包括leader)
- ISR(In-Sync Replicas): 与leader保持同步的副本(包括leader)
- OSR(Out-of-Synce Replicas): 与leader同步滞后过多的副本(数据不同步)
// 默认仅ISR中的副本才有资格选举为leader, 且负责动态管理ISR和OSR中的follower
延迟任务
时间轮(TimeingWheel): 以固定时间粒度为单位管理和调度事件的数据结构
- 时间跨度(tickMs): 时间轮构成的基本单位, 个数固定
- 表盘指针(currentTime): 指向当前所处的时间粒度
- 时间轮对于插入/删除操作的时间复杂度为O(1)
定时器(SystemTimer): Kafka中各类延迟操作的触发
- 本质: 基于时间轮机制和数组构成的环形队列
- 定时任务项(TimerTaskEntry): 封装真正的定时/延迟任务(Task)
- 定时任务列表(TimerTaskList): 存放时间粒度下所有TimerTaskEntry的双向链表
如: 定时器构成结构
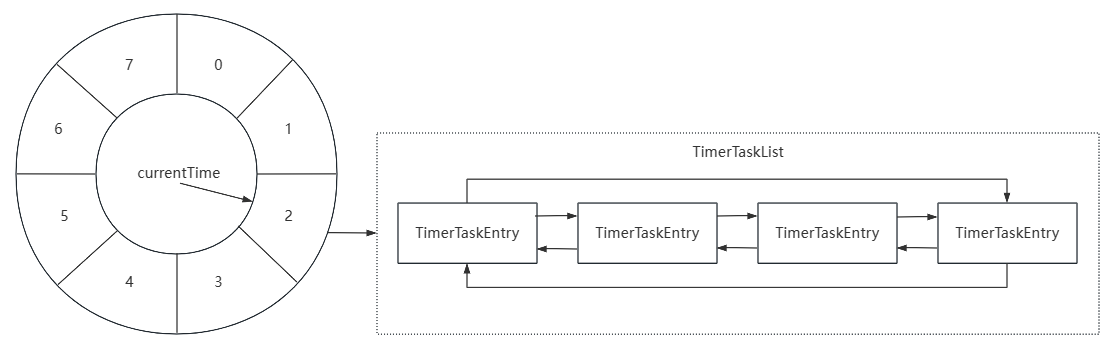
- 当添加TimerTaskEntry时, 会根据过期时间和currentTime算出应插入的TimerTaskList
- 当计算结果超出总tickMs时, 会复用之前的TimerTaskList
- TimerTaskList中都有个哑元节点方便操作(不存储数据)
层级时间轮(Hierarchical TimeingWheel): 分层处理不同tickMs的多级时间轮的组合结构
- 本质: 通过划分每个时间轮处理的时间范围, 以保证时间轮的高性能
- 升级: 当TimerTaskEntry的过期时间超出本层的时间范围时, 将交由上层时间轮
- 降级: 当TimerTaskEntry在高层时间轮中过期时, 会将其减少已过的时间并重新提交到层级时间轮
- TimerTask仅能由最底层的时间轮负责执行处理, 高层的时间轮仅根据时间粒度负责其的编排和重新提交
// Kafka中通过DelayQueue和ExpiredOperationReaper线程实现时间的推进(避免空转造成的性能浪费)
如: 层级时间轮
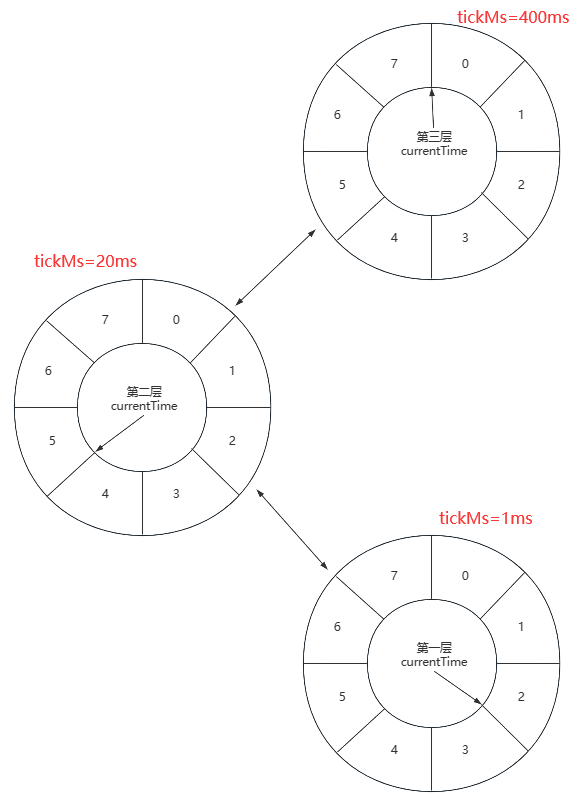
- 层级时间轮创建时会以当前系统时间作为最底层时间轮的起始时间(startMs)
- 高层时间轮的起始时间都为创建时上一层时间轮的currentTime
- 每层时间轮的currentTIme都必须是tickMs的整数倍
- Kafka仅持有最底层时间轮的引用
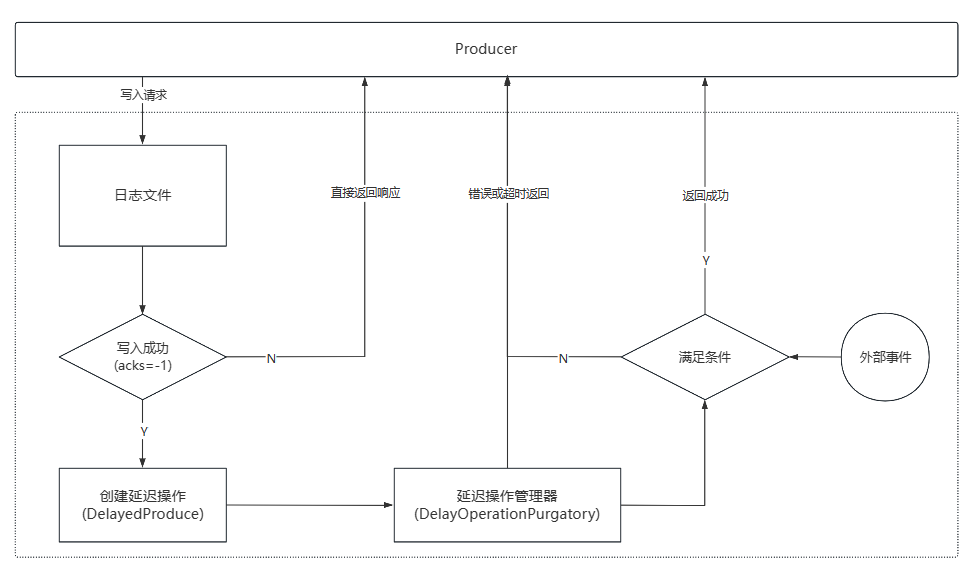
延迟操作管理器(DelayedOperationPurgatory, DOP): 管理/执行Kafka中各类延迟操作
- 每个DOP都对应个定时器(超时管理)和监听池(监听Partition事件)
- 当进行延迟拉取时, 会读取两次日志文件并等待足够数量的消息才会返回
如: Producer的延迟操作
文章来源:https://blog.csdn.net/qq_45686105/article/details/135318181
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Mybatis自动加解密
- SpringSecurity完整认证流程(包含自定义页面和自定义登录逻辑)
- 科普帖:什么是函数即服务 (FaaS)?
- 【HTML5、CSS3】新增特性总结!
- 一、基础数据结构——1.链表——1.动态链表
- CSS盒子的浮动与网页布局(重点,有电影页面案例)
- 从技术走向管理
- 随时随地安心工作:迅软DSE保护您手机办公中的关键数据
- 教你用Appium搭建Android自动化测试框架(详细教程)
- 品牌全球化:关于跨界合作的探索与解析