LLaMA Board: 通过一站式网页界面快速上手 LLaMA Factory
原文:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
![]()
?👋 加入我们的微信群。
{kind=link}
[?English?| 中文 ]
LLaMA Board: 通过一站式网页界面快速上手 LLaMA Factory
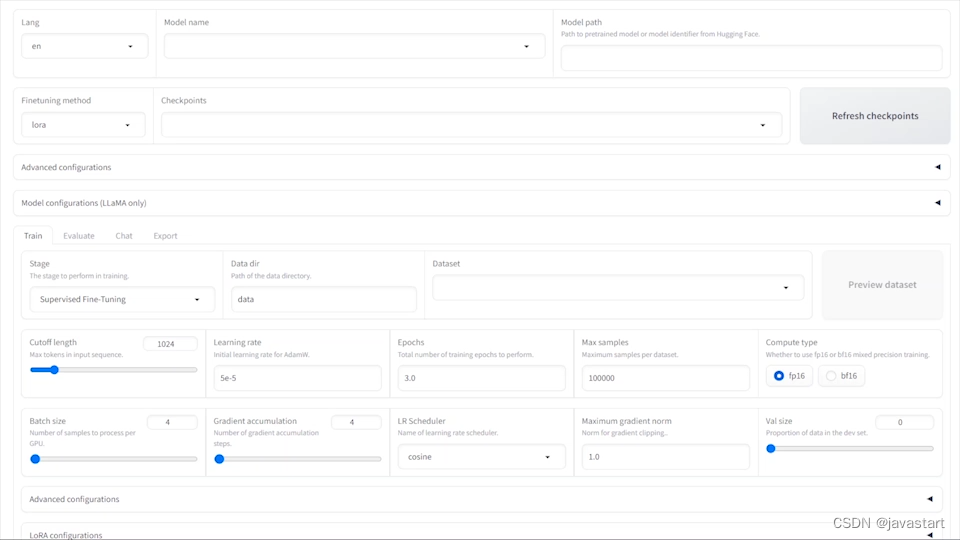
通过?🤗 Spaces?或?ModelScope?预览 LLaMA Board。
使用?CUDA_VISIBLE_DEVICES=0 python src/train_web.py?启动 LLaMA Board。(该模式目前仅支持单卡训练)
下面是使用单张 GPU 在 10 分钟内更改对话式大型语言模型自我认知的示例。
?tutorial.mp4?
目录
性能指标
与 ChatGLM 官方的?P-Tuning?微调相比,LLaMA-Factory 的 LoRA 微调提供了?3.7 倍的加速比,同时在广告文案生成任务上取得了更高的 Rouge 分数。结合 4 比特量化技术,LLaMA-Factory 的 QLoRA 微调进一步降低了 GPU 显存消耗。

变量定义
更新日志
[23/12/23] 我们针对 LLaMA, Mistral 和 Yi 模型支持了?unsloth?的 LoRA 训练加速。请使用?--use_unsloth?参数启用 unsloth 优化。该方法可提供 1.7 倍的训练速度,详情请查阅此页面。
[23/12/12] 我们支持了微调最新的混合专家模型?Mixtral 8x7B。硬件需求请查阅此处。
[23/12/01] 我们支持了从?魔搭社区?下载预训练模型和数据集。详细用法请参照?此教程。
展开日志
模型
| 模型名 | 模型大小 | 默认模块 | Template |
|---|---|---|---|
| Baichuan | 7B/13B | W_pack | baichuan |
| Baichuan2 | 7B/13B | W_pack | baichuan2 |
| BLOOM | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| ChatGLM3 | 6B | query_key_value | chatglm3 |
| Falcon | 7B/40B/180B | query_key_value | falcon |
| InternLM | 7B/20B | q_proj,v_proj | intern |
| LLaMA | 7B/13B/33B/65B | q_proj,v_proj | - |
| LLaMA-2 | 7B/13B/70B | q_proj,v_proj | llama2 |
| Mistral | 7B | q_proj,v_proj | mistral |
| Mixtral | 8x7B | q_proj,v_proj | mistral |
| Phi-1.5/2 | 1.3B/2.7B | Wqkv | - |
| Qwen | 1.8B/7B/14B/72B | c_attn | qwen |
| XVERSE | 7B/13B/65B | q_proj,v_proj | xverse |
| Yi | 6B/34B | q_proj,v_proj | yi |
| Yuan | 2B/51B/102B | q_proj,v_proj | yuan |
Note
默认模块应作为?--lora_target?参数的默认值,可使用?--lora_target all?参数指定全部模块。
对于所有“基座”(Base)模型,--template?参数可以是?default,?alpaca,?vicuna?等任意值。但“对话”(Chat)模型请务必使用对应的模板。
项目所支持模型的完整列表请参阅?constants.py。
训练方法
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练 | ? | ? | ? | ? |
| 指令监督微调 | ? | ? | ? | ? |
| 奖励模型训练 | ? | ? | ? | ? |
| PPO 训练 | ? | ? | ? | ? |
| DPO 训练 | ? | ? | ? | ? |
Note
请使用?--quantization_bit 4?参数来启用 QLoRA 训练。
数据集
预训练数据集
指令微调数据集
偏好数据集
使用方法请参考?data/README_zh.md?文件。
部分数据集的使用需要确认,我们推荐使用下述命令登录您的 Hugging Face 账户。
pip install --upgrade huggingface_hub huggingface-cli login
软硬件依赖
- Python 3.8+ 和 PyTorch 1.13.1+
- 🤗Transformers, Datasets, Accelerate, PEFT 和 TRL
- sentencepiece, protobuf 和 tiktoken
- jieba, rouge-chinese 和 nltk (用于评估及预测)
- gradio 和 matplotlib (用于网页端交互)
- uvicorn, fastapi 和 sse-starlette (用于 API)
硬件依赖
| 训练方法 | 精度 | 7B | 13B | 30B | 65B | 8x7B |
|---|---|---|---|---|---|---|
| 全参数 | 16 | 160GB | 320GB | 600GB | 1200GB | 900GB |
| 部分参数 | 16 | 20GB | 40GB | 120GB | 240GB | 200GB |
| LoRA | 16 | 16GB | 32GB | 80GB | 160GB | 120GB |
| QLoRA | 8 | 10GB | 16GB | 40GB | 80GB | 80GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 32GB |
如何使用
数据准备(可跳过)
关于数据集文件的格式,请参考?data/README_zh.md?的内容。构建自定义数据集时,既可以使用单个?.json?文件,也可以使用一个数据加载脚本和多个文件。
Note
使用自定义数据集时,请更新?data/dataset_info.json?文件,该文件的格式请参考?data/README_zh.md。
环境搭建(可跳过)
git clone https://github.com/hiyouga/LLaMA-Factory.git conda create -n llama_factory python=3.10 conda activate llama_factory cd LLaMA-Factory pip install -r requirements.txt
如果要在 Windows 平台上开启量化 LoRA(QLoRA),需要安装预编译的?bitsandbytes?库, 支持 CUDA 11.1 到 12.1.
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whl
使用魔搭社区(可跳过)
如果您在 Hugging Face 模型和数据集的下载中遇到了问题,可以通过下述方法使用魔搭社区。
export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`
接着即可通过指定模型名称来训练对应的模型。(在魔搭社区查看所有可用的模型)
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--model_name_or_path modelscope/Llama-2-7b-ms \
... # 参数同上
LLaMA Board 同样支持魔搭社区的模型和数据集下载。
CUDA_VISIBLE_DEVICES=0 USE_MODELSCOPE_HUB=1 python src/train_web.py
单 GPU 训练
Important
如果您使用多张 GPU 训练模型,请移步多 GPU 分布式训练部分。
预训练
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage pt \
--do_train \
--model_name_or_path path_to_llama_model \
--dataset wiki_demo \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_pt_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
指令监督微调
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--do_train \
--model_name_or_path path_to_llama_model \
--dataset alpaca_gpt4_zh \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
奖励模型训练
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage rm \
--do_train \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_sft_checkpoint \
--create_new_adapter \
--dataset comparison_gpt4_zh \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_rm_checkpoint \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-6 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
PPO 训练
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage ppo \
--do_train \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_sft_checkpoint \
--create_new_adapter \
--dataset alpaca_gpt4_zh \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--reward_model path_to_rm_checkpoint \
--output_dir path_to_ppo_checkpoint \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--top_k 0 \
--top_p 0.9 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-5 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
Warning
如果使用 fp16 精度进行 LLaMA-2 模型的 PPO 训练,请使用?--per_device_train_batch_size=1。
DPO 训练
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage dpo \
--do_train \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_sft_checkpoint \
--create_new_adapter \
--dataset comparison_gpt4_zh \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_dpo_checkpoint \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 1e-5 \
--num_train_epochs 1.0 \
--plot_loss \
--fp16
多 GPU 分布式训练
使用 Huggingface Accelerate
accelerate config # 首先配置分布式环境 accelerate launch src/train_bash.py # 参数同上
LoRA 训练的 Accelerate 配置示例
使用 DeepSpeed
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed ds_config.json \
... # 参数同上
使用 DeepSpeed ZeRO-2 进行全参数训练的 DeepSpeed 配置示例
合并 LoRA 权重并导出模型
python src/export_model.py \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_checkpoint \
--template default \
--finetuning_type lora \
--export_dir path_to_export \
--export_size 2 \
--export_legacy_format False
Warning
尚不支持量化模型的 LoRA 权重合并及导出。
Tip
合并 LoRA 权重之后可再次使用?--export_quantization_bit 4?和?--export_quantization_dataset data/c4_demo.json?量化模型。
API 服务
python src/api_demo.py \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_checkpoint \
--template default \
--finetuning_type lora
Tip
关于 API 文档请见?http://localhost:8000/docs。
命令行测试
python src/cli_demo.py \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_checkpoint \
--template default \
--finetuning_type lora
浏览器测试
python src/web_demo.py \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_checkpoint \
--template default \
--finetuning_type lora
模型评估
CUDA_VISIBLE_DEVICES=0 python src/evaluate.py \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_checkpoint \
--template vanilla \
--finetuning_type lora \
--task ceval \
--split validation \
--lang zh \
--n_shot 5 \
--batch_size 4
模型预测
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--do_predict \
--model_name_or_path path_to_llama_model \
--adapter_name_or_path path_to_checkpoint \
--dataset alpaca_gpt4_zh \
--template default \
--finetuning_type lora \
--output_dir path_to_predict_result \
--per_device_eval_batch_size 8 \
--max_samples 100 \
--predict_with_generate \
--fp16
Warning
如果使用 fp16 精度进行 LLaMA-2 模型的预测,请使用?--per_device_eval_batch_size=1。
Tip
我们建议在量化模型的预测中使用?--per_device_eval_batch_size=1?和?--max_target_length 128。
使用了 LLaMA Factory 的项目
- StarWhisper: 天文大模型 StarWhisper,基于 ChatGLM2-6B 和 Qwen-14B 在天文数据上微调而得。
- DISC-LawLLM: 中文法律领域大模型 DISC-LawLLM,基于 Baichuan-13B 微调而得,具有法律推理和知识检索能力。
- Sunsimiao: 孙思邈中文医疗大模型 Sumsimiao,基于 Baichuan-7B 和 ChatGLM-6B 在中文医疗数据上微调而得。
- CareGPT: 医疗大模型项目 CareGPT,基于 LLaMA2-7B 和 Baichuan-13B 在中文医疗数据上微调而得。
Tip
如果您有项目希望添加至上述列表,请通过邮件联系或者创建一个 PR。
协议
本仓库的代码依照?Apache-2.0?协议开源。
使用模型权重时,请遵循对应的模型协议:Baichuan?/?Baichuan2?/?BLOOM?/?ChatGLM3?/?Falcon?/?InternLM?/?LLaMA?/?LLaMA-2?/?Mistral?/?Phi-1.5?/?Qwen?/?XVERSE?/?Yi?/?Yuan
引用
如果您觉得此项目有帮助,请考虑以下列格式引用
@Misc{llama-factory,
title = {LLaMA Factory},
author = {hiyouga},
howpublished = {\url{https://github.com/hiyouga/LLaMA-Factory}},
year = {2023}
}
致谢
本项目受益于?PEFT、QLoRA?和?FastChat,感谢以上诸位作者的付出。
Star History

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- NLP深入学习(三):TF-IDF 详解以及文本分类/聚类用法
- 性能测试
- 数据结构与算法——队列
- 多域名证书和通配符证书的区别?
- 宏集方案 | 如何用工业树莓派和MQTT平台打通OT和IT?
- JUnit 5 单元测试框架
- SUSE Linux 12 SP5 安装图解
- Web前端 ---- 【Vue3】vue3中的组件传值(props、自定义事件、全局事件总线)
- 从奢侈品现状与发展困境,看花为缘·享奢二奢创业的前景和未来
- 安装nvidia driver出现 the cc vision check falied