什么?Figma 的 fig 文件格式居然被破解出来了
大家好,我是前端西瓜哥。
上周图形编辑器交流群里有人问,对于 Figma 导出的 fig 文件,该如何解析其格式,拿到可读数据。
经过群友的一番讨论,这个问题最后算是解决了。
fig 文件
导出 Figma 的设计文件,我们会得到一个 fig 文件。
fig 是一种二进制的格式。
它没有使用 XML 或是 JSON 的格式,而是选择使用了 Figma 自己实现的特殊编码工具进行了序列化编码,并做了封装,最后得到一个二进制文件。
二进制相比明文格式(JSON 和 XML),优点有:
-
体积更小,因为数据更紧凑;
-
解析速度快,像是 JSON 这种,要逐个字符解析然后构建 AST,考虑转义、空格等特殊情况,对于大文件,解析效率很差;
-
高保真,比如一些类型明文格式其实是不好表达的,需要多做一层转换(比如 Float32Array 类型,要保存为字符串就要转为普通数组);
-
安全性。因为编码规则是应用自己实现的,此外方便做加密(比如异或加密)。编码和解码的规则我们是无法知道的,除非它主动公布出来,否则只能尝试去做逆向。
先用 Figma 随便画几个基本图形。

然后导出 fig 文件,拿到了一个名为 fig-file.fig 的文件。

先用 vscode 打开看看。
不是文本文件,应该就是二进制文件了。

不管怎样,强行用文本格式打开。
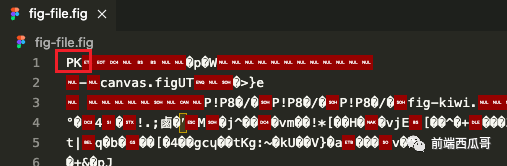
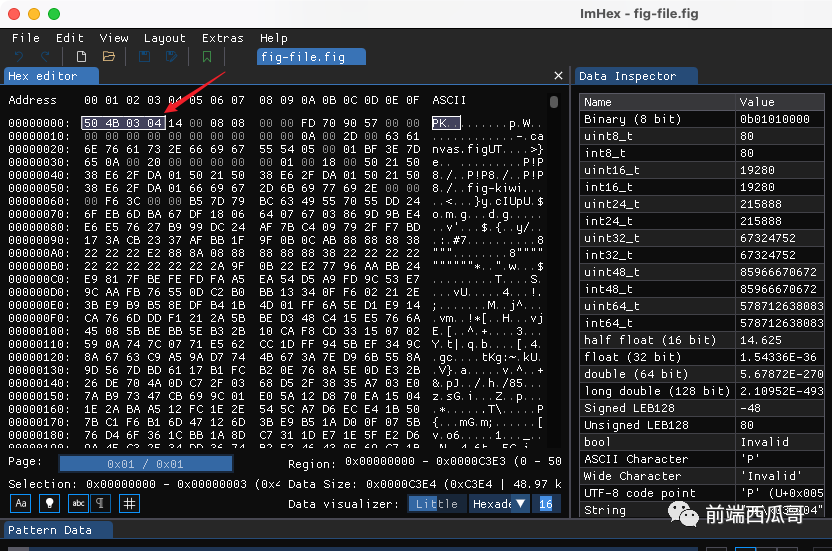
PK 打头,应该就是 ZIP 格式文件头的标识。
顺便再查看一下这个文件的二进制内容,看到开头这个 50 4B 03 04,说明确确实实是个 ZIP 文件。
基本上很多应用的导出文件都选择 ZIP 格式,然后再把后缀名改成自己定义的,比如 fig、xmind。
使用 ZIP 格式有以下好处:
-
进行了文件压缩,体积更小,并且是单文件;
-
保留了目录结构;
-
跨平台,基本所有主流操作系统都支持 ZIP。虽然用户一般来说并不会手动解压它,但用户安装的应用程序能直接使用操作系统的底层 API 去解压,有助于减少应用程序包体积;
解压一下。
unzip fig-file.fig
解压内容
解压后的内容为:
.
├── canvas.fig
├── fig-file.fig # 这个是压缩源文件
├── images
│ └── 0b15125516ae308a2d819f2970e851c0402949d2
├── meta.json
└── thumbnail.png
需要注意的是,解压出来的内容,并没有一个根文件夹存放这些内容。
但如果你用可视化界面去解压,通常会解压出一个文件夹,这个文件夹和压缩包同名。
这个其实是操作系统的额外操作,目的是防止解压出大量文件和当前文件夹的其他文件混在一起了,可能还会有文件同名的问题。
canvas.fig 是真正的 Figma 数据内容,记录图形树中图形的关系,以及图形的属性。
images 文件夹,存放的是图片,给里面的文件加上 .png 后缀可查看图片。
meta.json 是一些图纸的基本信息,比如导出的客户端使用的背景色,文件名等。
thumbnail.png 是预览图图片,如果你装了 figma 桌面端,则在会从 fig 提取出这个图片给文件预览器预览。
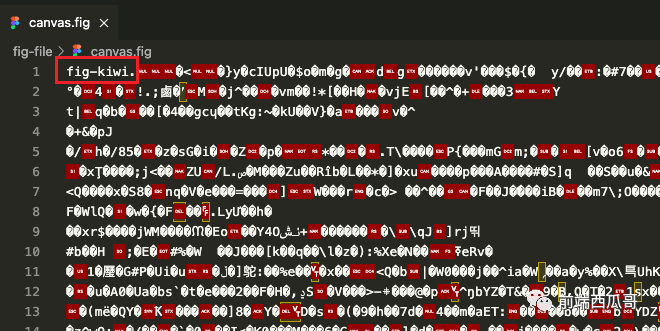
等下,不对,canvas.fig?怎么又是 fig 文件,这是在玩套娃?
经识别,也是个二进制文件,但它的文件格式却是。。。fig-kiwi?
Kiwi
这个叫做 Kiwi 的特殊格式被 Figma 的前 CTO,Evan Wallace 开源了。
Kiwi 是一种基于 Schecha 的二进制格式,用于高效地对树形数据结构进行编码。
它受到 Google 的 Protoclol Buffer 格式的启发,但更简单,编码更紧凑,且对自定义字段有更好的支持。
Kiwi 库提供了工具,能够解析二进制文件转换为编程语言中的对象,目前支持 JavaScript (TypeScript)、C++、Rust、Skew。
但要提供一个 Schecha,来进行类型的映射。
好在这个 Schecha 有保存在 fig 文件里的。
canvas.fig 文件
实际上这个 canvas.fig 文件并不是 Kiwi,它是一个复合产物。
首先开头的 fig-kiwi 字符串是一个注释,表示它是一个 fig 文件(毕竟前面也看到了,fig 文件可能也是 ZIP),并使用了 kiwi 进行编码。
文件里有 Kiwi 的二进制数据部分,也有 Schecha 部分,需要把它们提取出来。
这里要做 切片 了。
有个开源项目 Figma-To-JSON 成功解析了 fig,我们看看它怎么做的。
看了下,貌似是切在 50 89 这个地方,切好几刀,得到一些切片。我们需要前两个切片。
第一个切片是 Schecha,第二个是 Kiwi 数据。
每个切片都是 ZIP 压缩的,需要先给它们解压,然后再做 Kiwi 解码。
import { ByteBuffer, compileSchema, decodeBinarySchema } from "kiwi-schema"
export const figToJson = (fileBuffer: Buffer | ArrayBuffer): object => {
// 提取 fig 文件的 schema 和 kiwi 格式数据
const [schemaByte, dataByte] = figToBinaryParts(fileBuffer)
const schemaBB = new ByteBuffer(schemaByte)
const schema = decodeBinarySchema(schemaBB)
const dataBB = new ByteBuffer(dataByte)
const schemaHelper = compileSchema(schema)
// 这个 json 对象就是最终结果了
const json = schemaHelper[`decodeMessage`](dataBB)
return convertBlobsToBase64(json)
}
流程总结一下,大致如下:
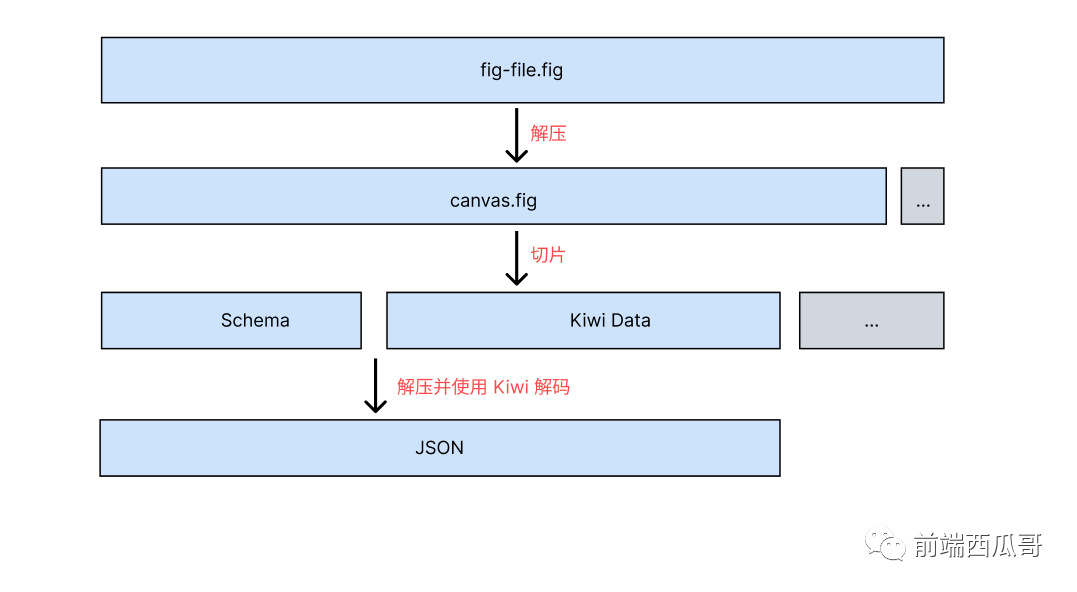
Figma-To-JSON
上面都是在说解码 fig 文件的过程。
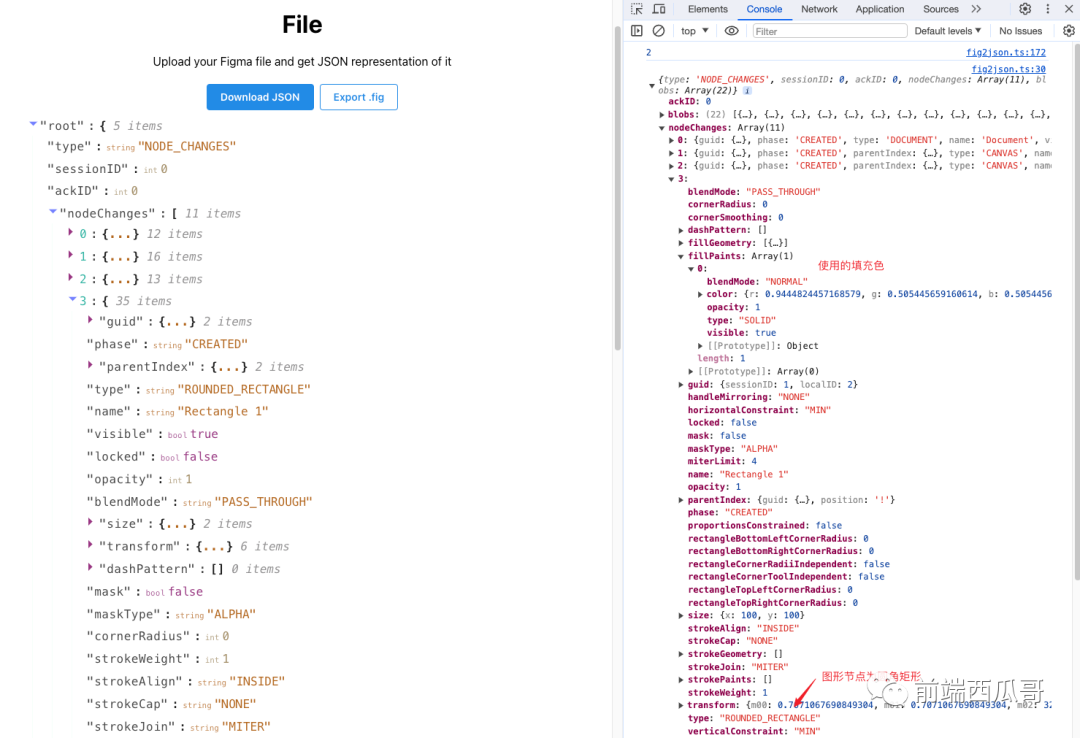
如果你只是想要得到 fig 的结构,对过程不感兴趣,可以直接用一个名为 Figma-To-JSON 的开源项目去解析。
下面是转换结果,是一个一维数组,风格类似 quill 的 delta。
每个节点保存有父节点的 id,可以关联构建出一棵图形树。
拿到 fig 数据格式有什么好处呢?
首先如果你开发自己的图形编辑器,或者直接就是 Figma 的竞品,你是要设计数据结构的,那 fig 数据格式就有很好的参考价值。
然后就是做二次开发,写一些工具做一些离线的批处理操作,比如提取 fig 的一些文本数据转换为 excal 之类的奇怪操作。
这样你就不用联网打开 Figma 网站,使用插件去进行这些操作。
Figma 官方的看法
Figma 的 fig 格式算是半公开的,在网上找找能找到不少蛛丝马迹。因为 Figma 还是比较开放的,使用的 Kiwi 编码格式也公开了。
但 Figma 不会主动提供在客户端转换 fig 的方式(但可以使用开发者 API 请求服务端数据),因为这 和它所希望的生态稳定相悖。
如果 Figma 主动提供 fig 的内部格式出来,那它就要对这个格式负责,且 Figma 在开发新的功能时,fig 文件在未来发展中结构大概率会有破坏性改变的。
当然如果你想和 Photopea 一样,尝试去解析它转换成的结构,那也是可以的,但你自己要对这个数据结构负责。
结尾
我是前端西瓜哥,欢迎关注我,学习更多图形编辑器知识。
如果你想加图形编辑器交流群,加我微信 frstars,我拉你进群。
相关阅读,
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!