用通俗易懂的方式讲解:一文讲透主流大语言模型的技术原理细节
发布时间:2024年01月13日
大家好,今天的文章分享三个方面的内容:
-
1、比较 LLaMA、ChatGLM、Falcon 等大语言模型的细节:tokenizer、位置编码、Layer Normalization、激活函数等。
-
2、大语言模型的分布式训练技术:数据并行、张量模型并行、流水线并行、3D 并行、零冗余优化器 ZeRO、CPU 卸载技术 ZeRo-offload、混合精度训练、激活重计算技术、Flash Attention、Paged Attention。
-
3、大语言模型的参数高效微调技术:prompt tuning、prefix tuning、adapter、LLaMA-adapter、 LoRA。
本文内容较长,喜欢可以收藏、点赞、关注。
用通俗易懂的方式讲解系列
- 用通俗易懂的方式讲解:不用再找了,这是大模型最全的面试题库
- 用通俗易懂的方式讲解:这是我见过的最适合大模型小白的 PyTorch 中文课程
- 用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
- 用通俗易懂的方式讲解:基于 LangChain + ChatGLM搭建知识本地库
- 用通俗易懂的方式讲解:基于大模型的知识问答系统全面总结
- 用通俗易懂的方式讲解:ChatGLM3 基础模型多轮对话微调)
- 用通俗易懂的方式讲解:最火的大模型训练框架 DeepSpeed 详解来了
- 用通俗易懂的方式讲解:这应该是最全的大模型训练与微调关键技术梳理
- 用通俗易懂的方式讲解:Stable Diffusion 微调及推理优化实践指南
- 用通俗易懂的方式讲解:大模型训练过程概述
- 用通俗易懂的方式讲解:专补大模型短板的RAG
- 用通俗易懂的方式讲解:大模型LLM Agent在 Text2SQL 应用上的实践
- 用通俗易懂的方式讲解:大模型 LLM RAG在 Text2SQL 上的应用实践
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
建立了大模型技术交流群,大模型学习资料、数据代码、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2060,备注:技术交流
0. 大纲

1. 大语言模型的细节
1.0 transformer 与 LLM

1.1 模型结构

1.2 训练目标

1.3 tokenizer

1.4 位置编码

1.5 层归一化

1.6 激活函数

1.7 Multi-query Attention 与 Grouped-query Attention

1.8 并行 transformer block

1.9 总结-训练稳定性

2. LLM 的分布式预训练

2.0 点对点通信与集体通信

2.1 数据并行

2.2 张量并行


2.3 流水线并行

2.4 3D 并行

2.5 混合精度训练

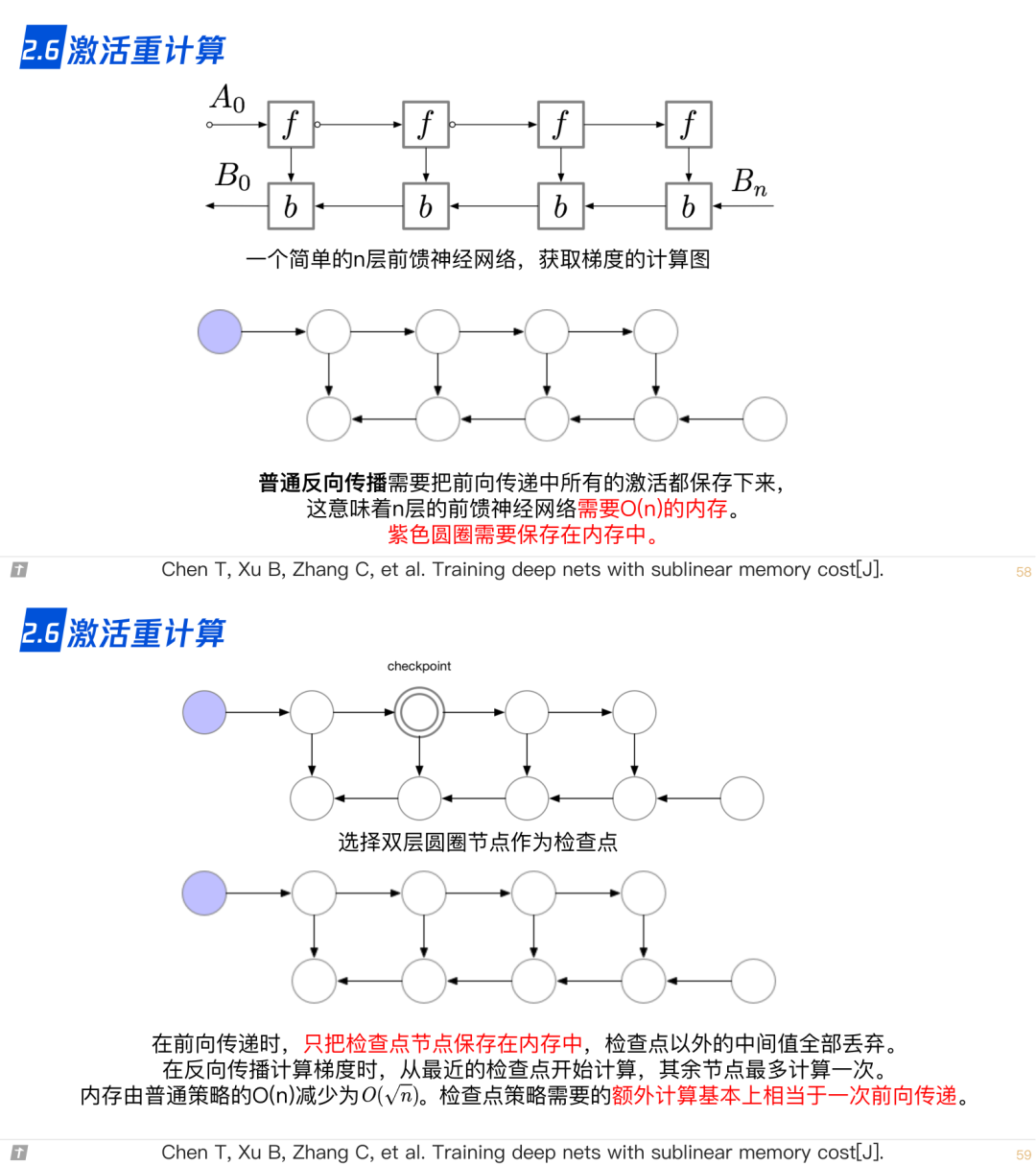
2.6 激活重计算
2.7 ZeRO,零冗余优化器

2.8 CPU-offload,ZeRO-offload

2.9 Flash Attention

2.10 vLLM: Paged Attention

3. LLM 的参数高效微调
3.0 为什么进行参数高效微调?

3.1 prompt tuning

3.2 prefix tuning

3.3 adapter

3.4 LLaMA adapter

3.5 LoRA

3.6 实验比较

4. 参考文献

文章来源:https://blog.csdn.net/m0_59596990/article/details/135563669
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!