Probabilistic Forecasting with Temporal Convolutional Neural Network

Abstract
??我们提出了一种基于卷积神经网络(CNN)的概率预测框架,用于多个相关时间序列预测。该框架可用于估计参数和非参数设置下的概率密度。更具体地说,构建基于扩张因果卷积网络的堆叠残差块来捕获序列的时间依赖性。与表示学习相结合,我们的方法能够学习复杂的模式,例如季节性、系列内和系列之间的假期影响,并利用这些模式进行更准确的预测,特别是在历史数据稀疏或不可用的情况下。对几个现实世界的数据集进行了广泛的实证研究,包括中国最大的在线零售商京东的数据集。结果表明,我们的框架在点预测和概率预测方面都优于最先进的框架。
关键词:概率预测,卷积神经网络,扩张因果卷积,需求预测,高维时间序列
1. Introduction
??时间序列预测在许多业务决策场景中发挥着关键作用,例如管理有限资源、优化运营流程等。大多数现有的预测方法侧重于点预测,即预测未来观测值的条件均值或中位数。然而,概率预测变得越来越重要,因为它能够从历史数据中提取更丰富的信息并更好地捕捉未来的不确定性。在零售业务中,产品供应和需求的概率预测是成功采购流程和优化库存计划的基础。此外,概率发货预测,即生成包裹交付量的概率分布,是后续物流操作的关键组成部分,例如劳动力资源规划和配送车辆部署。
? ?在这种情况下,我们需要预测数千或数百万个相关序列,而不是预测单个或少量时间序列。此外,实际应用中还存在更多挑战。例如,零售平台上每周都会出现新产品,而人们往往需要在没有历史购物节数据(例如北美的黑色星期五、中国的“11.11”购物节)的情况下预测产品的需求。此外,预测通常需要考虑对未来需求有重大影响的外生变量(例如,运营团队提供的促销计划、实体零售商的准确天气预报)。此类预测问题可以扩展到各个领域。例子包括预测互联网公司的网络流量(Kaggle,2017)、单个家庭的能源消耗、数据中心服务器的负载(Salinas 等人,2019)以及交通领域的流量(Lv 等人, 2015)。
? ? ?经典预测方法,例如 ARIMA(自回归综合移动平均,Box 等,2015)和指数平滑(Hyndman 等,2008),广泛应用于单变量基准水平预测。为了纳入外生协变量,人们提出了这些方法的几种扩展,例如 ARIMAX(带解释变量的自回归综合移动平均线)和动态回归模型(Hyndman 和 Athanasopoulos,2018)。这些模型非常适合数据结构易于理解且有足够历史数据的应用。然而,处理数千或数百万个系列需要大量的劳动力和计算资源来进行参数估计。此外,它们不适用于历史数据稀疏或不可用的情况。
? ?基于循环神经网络(RNN)(Graves,2013)和序列到序列(Seq2Seq)框架(Cho et al.,2014;Sutskever et al.,2014)的模型在许多不同的序列任务(例如机器学习)中取得了巨大的成功。翻译(Sutskever 等人,2014)、语言建模(Mikolov 等人,2010)和最近的时间序列预测(Laptev 等人,2017;Wen 等人,2017;Salinas 等人,2019;Rangapuram 等人) .,2018;Sagheer 和 Kotb,2019;Shen 等人,2019)。例如,在预测竞赛界,基于门控循环单元(GRU)的Seq2Seq模型(Cho et al., 2014)赢得了Kaggle网络流量预测竞赛(Suilin, 2017)。结合指数平滑方法和 RNN 的混合模型赢得了 M4 预测竞赛,该竞赛由 100,000 个具有不同季节模式的序列组成(Makridakis 等人,2018a)。然而,使用时间反向传播 (BPTT) 算法进行训练通常会妨碍高效计算。此外,训练 RNN 可能非常困难(Werbos,1990;Pascanu 等人,2013)。扩张因果卷积架构,例如 Wavenet(van den Oord 等,2016),提供了另一种建模方法顺序数据。通过堆叠扩张的因果卷积网络层,可以增加感受野,并且可以在不违反时间顺序的情况下捕获长期相关性。此外,在扩张因果卷积架构中,训练过程可以并行执行,从而保证了计算效率。
? ?大多数 Seq2Seq 框架或 Wavenet(van den Oord 等人,2016)都是自回归生成模型,将联合分布分解为条件的乘积。在这种情况下,采用一步一步预测方法,即首先使用过去的观察结果生成预测,然后将生成的结果作为基本事实反馈以进行进一步的预测。最近的研究表明,非自回归方法或直接预测策略,直接预测所有时间步的观测值,可以获得更好的性能(Gu et al., 2017; Bai et al., 2018; Wen et al., 2017)。特别是,非自回归模型通过避免误差累积,对错误指定更加稳健,从而产生更好的预测精度。此外,所有预测范围内的训练可以并行进行。
??回顾了所有这些挑战和发展,在本文中,我们提出了深度时序卷积网络(DeepTCN),这是一种用于大量相关时间序列的非自回归概率预测框架。论文的主要贡献如下:
?.?我们提出了一个基于 CNN 的预测框架,为概率密度估计提供参数和非参数方法。
? 该框架能够学习序列之间的潜在相关性并处理复杂的现实世界预测情况,例如数据稀疏和冷启动,表现出高度的可扩展性和可扩展性。
? 该模型非常灵活,可以包含外生协变量,例如额外的促销计划或天气预报。
? 广泛的实证研究表明,我们的框架在点预测和概率预测任务方面均优于最先进的方法。
本文的其余部分安排如下。第 2 节简要回顾了时间序列预测和深度学习预测方法的相关工作。在第 3 节中,我们描述了所提出的预测方法,包括神经网络架构、概率预测框架和输入特征。我们通过第 4 节中的大量实验证明了所提出方法的优越性,并在第 5 节中总结了本文。
2. Related Work
??早期关于时间序列预测的研究大多基于统计模型,主要是基于状态空间框架的生成模型,如指数平滑、ARIMA模型和其他几种扩展。对于这些方法,Hyndman 等人。 (2008) 和 Box 等人。 (2015)提供了单变量预测背景下的全面概述。
? ??近年来,大量相关系列出现在许多公司的日常运作中。传统的单变量预测方法不共享其他时间序列的信息,为每个单独的时间序列拟合一个模型,因此无法跨相似的时间序列进行学习。此外,许多研究人员表明,纯机器学习方法在预测单个时间序列方面无法优于统计方法,其原因可归因于过度拟合和非平稳性(Bandara 等人,2020;Makridakis 等人,2018b) 。因此,能够联合提供多个序列预测的方法在过去几年中受到越来越多的关注(例如,Yu et al., 2016)。
? ??RNN 和 CNN 均已被证明能够对复杂的非线性特征交互进行建模,并产生显着的预测性能,特别是当许多相关时间序列可用时(Smyl,2016;Laptev 等,2017;Wen 等,2017;Salinas)等人,2019;Rangapuram 等人,2018)。例如,长短期记忆(LSTM)(一种 RNN 架构)赢得了 CIF2016 月度时间序列预测竞赛(Stepnicka 和 Burda,2016)。比安奇等人。 (2017) 比较了各种 RNN 在短期负荷预测问题中的性能。博罗维克等人。 (2017) 研究了 CNN 在金融时间序列预测中的应用。
? ??为了更好地理解未来的不确定性,深度学习模型的概率预测引起了越来越多的关注。 DeepAR(Salinas 等人,2019)在丰富的相似时间序列集合上训练自回归 RNN 模型,可以对多个现实世界数据集产生更准确的概率预测。 Rangapuram 等人提出的深层状态空间模型(DeepState)。 (2018),将状态空间模型与深度学习相结合,可以在从原始数据中学习复杂模式的同时保持数据效率和可解释性。根据类似的计划,Maddix 等人。 (2018)提出深度神经网络和高斯过程的结合。最近,Gasthaus 等人。 (2019) 提出了 SQF-RNN,这是一种使用等张样条对条件分位数函数进行建模的概率框架,它允许更灵活的输出分布。
? ??大多数这些概率预测框架都是自回归模型,它们使用递归策略来生成多步骤预测。在神经机器翻译中,非自回归翻译(NAT)模型取得了显着的加速,但代价是性能稍差。与自回归翻译模型相比的有效性(Gu et al., 2017)。例如,白等人。 (2018) 提出了一种基于扩张因果卷积的非自回归框架,对多个数据集的实证研究表明,该框架优于 LSTM 和 GRU 等通用循环架构。在预测应用中,非自回归方法也被证明偏差较小且更加稳健。最近,文等人。 (2017) 提出了一种多水平分位数循环预测器,将顺序神经网络和分位数回归结合起来 (Koenker 和 Bassett Jr, 1978)。通过同时在所有时间点进行训练,他们的框架可以显着提高循环网络的训练稳定性和预测性能。
??我们的方法与上述方法的不同之处如下。首先,构建堆叠扩张因果卷积网络来表示编码器并对系列历史观察的随机过程进行建模。残差块不是应用门控机制(例如,在 Wavenet(van den Oord 等人,2016)中),而是用于扩张因果卷积网络,以提取历史观测信息并帮助实现卓越的预测精度。其次,受 ARIMAX 等动态回归模型(Pankratz,2012)的启发,在解码器部分,提出了残差神经网络的一种新变体,以合并来自过去观察和外生协变量的信息。最后,我们的模型可以灵活地采用各种概率密度估计方法。
3. Method
? ??多个相关时间序列的一般概率预测问题可以描述如下:给定一组时间序列 y1:t = {y(i) 1:t}iN=1,我们将未来时间序列表示为 y(t+ 1):(t+Ω) = {y(i) (t+1):(t+Ω)}iN=1,其中 N 是系列数,t 是历史观测值的长度,Ω 是预测范围的长度。我们的目标是对未来时间序列 P (y(t+1):(t+Ω)|y1:t ) 的条件分布进行建模。
??经典生成模型通常用于对时间序列数据进行建模,它将给定过去信息的未来观察的联合概率分解为条件概率的乘积:

其中每个未来的观察都以所有先前时间戳的观察为条件。在实践中,生成模型在应用于现实世界的预测场景(例如在线零售商的需求预测)时可能会面临一些挑战。除了训练和预测阶段的效率问题外,还存在误差累积问题,因为每个预测都作为地面实况反馈以预测更长的时间范围,其中过程误差可能会累积。我们的框架没有应用经典的生成方法,而是直接预测未来观测值的联合分布:

虽然时间序列数据通常具有趋势和季节性等系统模式,但预测框架允许协变量 X(i) t+ω(其中 ω = 1, ..., Ω 且 i = 1, ... , N ),其中包括方程式 2 中直接预测策略的附加信息。包含协变量的未来联合分布变为:
在上述设置下,挑战在于设计一个包含历史观测值 y1:t 和协变量 X(i) t+ω 的神经网络框架。在下面的部分中,我们将描述如何通过应用扩张因果卷积和残差神经网络来扩展动态回归模型(例如 ARIMAX 模型)的思想来构建多个时间序列的直接预测框架。然后,我们将详细描述概率预测框架以及输入特征的一些实际考虑因素。
3.1. Neural network architecture
??动态回归模型(例如 ARIMAX)扩展了经典时间序列模型,以包含来自过去观察的信息和外生变量(Pankratz 2012)。动态回归模型的表示方法如下:

其中 νB(·) 是一个传递函数,描述外生变量 X(i) t 的变化如何传递到 y(i) t ,n(i) t 是一个随机时间序列过程,例如 ARIMA 过程,它使用历史信息捕获 y(i) t 的预测。
??为了将动态回归模型扩展到多个时间序列预测场景,我们提出了残差神经网络的变体(resnet,He et al.,2016a,b)。它与原始 resnet 的主要区别在于,新块允许两个输入 - 一个输入用于历史观测,另一个输入用于外生变量。为了方便起见,我们在本文的其余部分将其称为 resnet-v。第 3.1.2 节提供了 resnet-v 模块的更多详细信息。
??在本文中,我们提出了深度时序卷积网络(DeepTCN)。 DeepTCN的整个架构如图1a所示。高层架构类似于经典的Seq2Seq框架。在编码器部分,堆叠扩张因果卷积是用来对历史观察的随机过程进行建模并输出 h(i) t 。然后,解码器部分的模块 resnet-v 合并潜在输出 h(i) t 和未来的外生变量 X(i) t+ω,并输出另一个潜在输出。最后,应用密集层来映射 resnet-v 的输出并生成未来观测的概率预测。在以下部分中,我们提供每个模块的更多详细信息。
3.1.1. Encoder: Dilated causal convolutions
? ? ?因果卷积是指时间 t 的输出只能从不晚于 t 的输入获得的卷积。膨胀因果卷积允许通过以特定步长跳过输入值,将滤波器应用于大于其长度的区域(van den Oord 等人,2016)。在单变量序列的情况下,给定一维输入序列 x,具有核 w 的扩张卷积的位置 t 处的输出(特征图) s 可以表示为:

其中 d 是膨胀因子,K 是内核的大小。堆叠多个扩张卷积使网络能够具有非常大的感受野,并用更少的层数捕获长程时间依赖性。图 1a 的左侧是扩张因果卷积的示例,扩张因子为 d = {1, 2, 4, 8},其中滤波器大小 K = 2,通过放置四层达到大小为 16 的感受野。
? ?图 1b 显示了编码器每一层的基本模块,其中模块内的两个扩张卷积都具有相同的内核大小 K 和扩张因子 d。 Wavenet 中没有实现经典的门控机制(van den Oord 等人,2016),其中扩张卷积之后是门控激活,而是将残差块作为成分。如图 1b 所示,每个残差块由两层扩张因果卷积组成,第一层后面是批量归一化和修正非线性单元 (ReLU)(Nair 和 Hinton,2010),而第二层后面是另一种批量归一化(Ioffe 和 Szegedy,2015)。第二批归一化层之后的输出作为残差块的输入,后面是第二个ReLU。残差块已被证明有助于有效地训练和稳定网络,特别是当输入序列很长时。更重要的是,在大多数实证研究中,修正线性单元(ReLU)获得的非线性实现了更好的预测精度。各种自然语言处理(NLP)任务也支持上述结论(Bai et al., 2018)。

图 1:(a) DeepTCN 的架构。编码器部分:构建堆叠扩张因果卷积网络来捕获长期时间依赖性。解码器部分:解码器包括残差块的变体(称为resnet-v,显示为⊕)和输出密集层。 resnet-v 模块旨在集成历史观察和未来协变量的随机过程的输出。然后采用输出密集层将 resnet-v 的输出映射到我们的最终预测中。
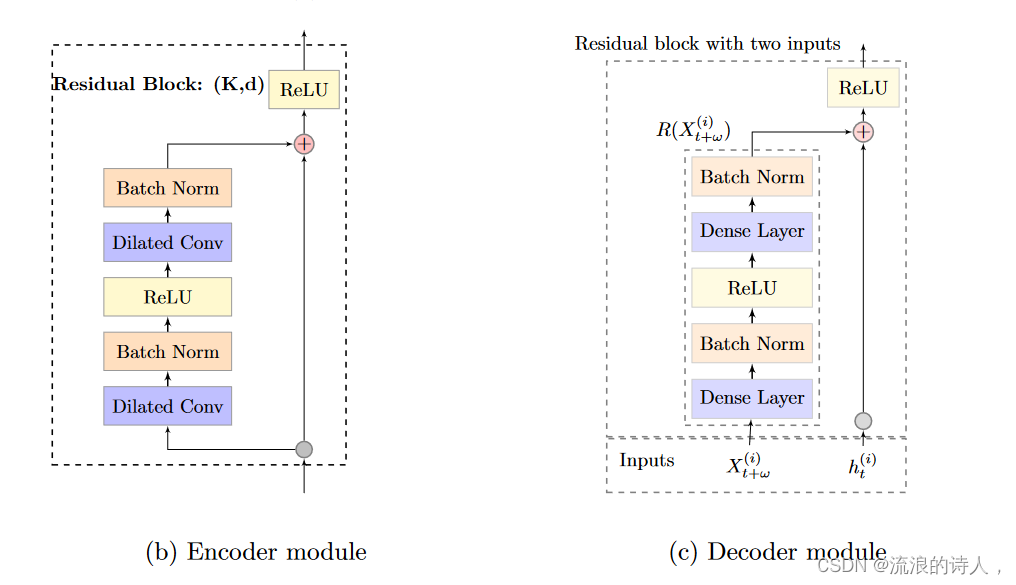
??(b) 编码器模块。剩余块被视为成分。每个残差块由两层扩张因果卷积组成,第一层后面跟着批量归一化和 ReLU,第二层后面跟着另一个批量归一化。输出作为残差块的输入,后面跟着另一个 ReLU。
(c) 解码器模块。 h(i) t 是编码器的输出,X(i) t+ω 是未来协变量,R(·) 是应用于 X(i) t+ω 的非线性函数。对于残差函数 R(·),我们首先应用密集层和批量标准化来预测未来的协变量。然后应用 ReLU 激活,然后是另一个密集层和批量归一化。
3.1.2. Decoder: Residual neural network
??解码器包括两部分。第一部分是残差神经网络的变体,模块 resnet-v。第二部分是一个密集层,它将 resnet-v 的输出映射到概率预测。如前所述,resnet-v 模块允许两个输入(一个用于历史信息,另一个用于外生变量),并且旨在捕获这两个输入的信息。可以写成:

其中 h(i) t 是编码器的潜在输出,X(i) t+ω 是未来协变量,δ(i) t+ω 是 resnet-v 的潜在输出。 R(·) 是应用于 X(i) t+ω 的残差函数。因此,非线性函数 R(·) 在动态回归模型中扮演传递函数的角色,并解释地面实况与仅由编码器部分确定的预测之间的残差(例如,在线零售商平台的促销效果或实体店的天气预报)零售商)。
??图 1c 显示了 resnet-v 的结构。对于残差函数 R(·),我们首先应用密集层和批量标准化来预测未来的协变量。然后应用 ReLU 激活,然后是另一个密集层和批量归一化。最后,输出密集层映射潜在变量 δ(i) t+ω 以产生与感兴趣的概率估计相对应的最终输出 Z。
??在下一节中,我们将描述如何通过输出密集层中的神经网络构建概率预测框架。
3.2. Probabilistic forecasting framework
??神经网络具有产生多个输出的灵活性。在 DeepTCN 框架中,对于每个未来的观察,解码器中的输出密集层可以产生 m 个输出:Z = (z1, ..., zm),它们表示感兴趣的假设分布的参数集。以高斯分布为例,对于第 i 个序列的第 ω 个未来观测值 y(i) t+ω,输出层产生两个输出(均值和标准差),从而给出 Z (i) t+ω = (μ(i) t+ω, σ(i) t+ω),其中 μ(i) t+ω 是 y(i) t+ω 的期望,σ(i) t+ω 是标准差。因此,概率预测可以描述为:
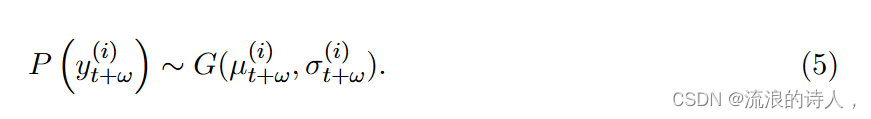
?更具体地说,我们在本文中考虑了两个概率预测框架。第一个是参数框架,其中可以通过基于最大似然直接预测假设分布的参数(例如高斯分布的平均值和标准差)来实现对未来观测值的概率预测估计。第二个是非参数的,它产生一组与感兴趣的分位数点相对应的预测(Koenker 和 Bassett Jr,1978),其中 Z 代表分位数预测。
? ?在实践中,选择参数化方法还是非参数化方法取决于应用环境。参数方法需要假设特定的概率分布,而非参数方法是无分布的,因此通常更稳健。然而,决策场景可能依赖于某个时期的概率预测的总和。例如,库存补货决策可能取决于接下来几天的需求总和的分布。在这种情况下,非参数方法将不起作用,因为输出(例如,分位数)不会随时间相加,并且参数方法的优点是通过从估计分布中采样来灵活地获取此类信息。
3.2.1. Non-parametric approach
? ?在非参数框架中,可以通过分位数回归获得预测。在分位数回归中(Koenker 和 Bassett Jr,1978),将特定分位数水平 q 的观察和预测分别表示为 y 和 ? yq,训练模型以最小化分位数损失,其定义为

其中 (y)+ = max(0, y) 且 q ∈ (0, 1)。给定一组分位数水平 Q = (q1, ..., qm),可以通过最小化总分位数损失来获得 m 个相应的预测,定义为

3.2.2. Parametric approach
??对于参数方法,给定预定分布(例如高斯分布),应用最大似然估计来估计相应的参数。以高斯分布为例,对于每个目标值y,网络输出分布的参数,即均值和标准差,分别用μ和σ表示。然后将负对数似然函数构造为损失函数:

我们可以将此方法扩展到各种概率分布族。例如,我们可以为长尾产品选择负二项分布,该分布传统上用于对过度分散的计数数据进行建模,并且在实证研究中已被证明表现良好(Villani et al., 2012;Snyder et al., 2012 年;Syntetos 等人,2015 年;Salinas 等人,2019 年)。
??值得一提的是,某个分布的某些参数(例如高斯分布中的标准差)必须满足正性条件。为了实现这一目标,我们应用“Soft ReLU”激活,即变换 ? z = log(1 + exp(z)),以确保积极性(Salinas 等人,2019)。
3.3. Input features
??通常有两种输入特征:与时间相关的特征(例如,产品价格和星期几)和与时间无关的特征(例如,产品 ID、产品品牌和类别)。与时间无关的协变量(例如产品 ID)包含系列特定信息。包含这些协变量有助于捕获每个特定系列的规模水平和季节性。
? 为了捕捉季节性,我们使用一天中的小时、一周中的某一天、一个月中的某一天来获取每小时数据,使用一年中的某一天来获取每日数据,使用一年中的月份来获取每小时数据。每月数据。此外,我们使用手工制作的购物节假期指标,例如“11.11”,这使得模型能够学习由于预定事件而导致的峰值。
? ??产品 ID 和星期几等虚拟变量通过嵌入映射到密集数值向量(Mikolov、Sutskever、Chen、Corrado 和 Dean,2013 年;Mikolov、Chen、Corrado 和 Dean,2013 年)。我们发现该模型能够通过表示学习在序列之间学习更多相似的模式,从而提高相关时间序列的预测准确性,这对于历史数据很少或没有的序列特别有用。对于新产品或新仓库没有足够历史数据的情况,我们进行补零以保证输入序列的所需长度。
4. Experiments
4.1. Datasets

4.2. Accuracy comparison

4.3. Sensitivity analysis
? ?鉴于历史观测的随机过程是由 DeepTCN 框架的编码器部分中的堆叠扩张因果卷积建模的,我们现在以流量数据集为例进行敏感性分析,以探讨编码器层数对模型性能。在本实验中,我们将扩张因果卷积的滤波器大小设置为 k = 2 并实现三种模型架构:(1) 扩张因子 d = {1, 2, 4, 8, 16} 的 5 层架构,( 2) 具有扩张因子 d = {1, 2, 4, 8, 16, 32} 的 6 层架构和 (3) 具有扩张因子 d = {1, 2, 4, 8, 16, 20、32}。请注意,在我们的流量数据集实验中,输入序列的长度为 7 × 24 = 168,这是前一周的每小时数据。对于扩张因果卷积的每一层,内核大小乘以扩张因子不能超过输入序列的长度,因此我们将第三个模型的扩张因子设置为 d = {1, 2, 4, 8, 16, 20, 32} 以保证每层的输入长度足够。
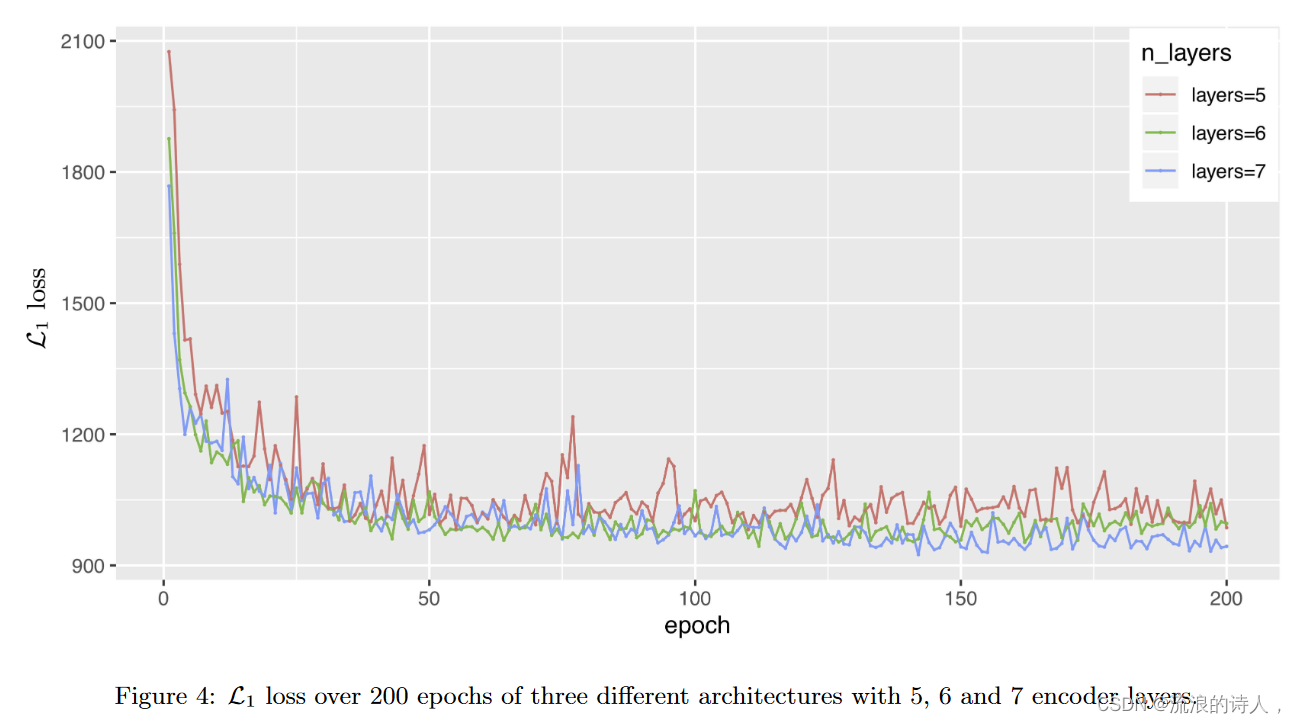
? ? ?图 4 显示了这三个模型在 200 个 epoch 中的 L1 损失。可以看出,6层和7层架构的性能均优于5层架构。原因之一是 5 层架构相对较浅,无法对历史观察中的信息进行充分建模。然而,正如我们所看到的,使用 6 层和 7 层之间的差异很小,这意味着只要使用足够多的层数,结果的差异就很小。这种现象在其他测试用例中非常一致。因此,我们的方法对于模型参数来说非常稳健。
5. Conclusion
? ?我们提出了一个针对多个相关时间序列的基于卷积的概率预测框架,并展示了基于神经网络对概率分布进行建模的非参数和参数方法。我们的解决方案可以帮助设计实际的大规模预测应用程序,其中涉及冷启动和数据稀疏等情况。工业数据集和公共数据集的结果表明,与其他最先进的方法相比,该框架在点预测和概率预测方面都具有卓越的性能。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Javac编译原理
- 用LED数码显示器循环显示数字0~9
- 【linux】cut的基本使用
- Redis主从复制哨兵及集群
- Ubuntu20.04.2-mate上Lazarus安装与测试
- c++多态与虚函数
- 网关Gateway
- 【算法】使用BFS算法(队列、哈希等)解决最短路径问题(C++)
- 【vite】找不到模块“vite”或其相应的类型声明
- 瑞芯微RK3288、RK3399、RK3568、RK3368芯片性能介绍与对比分析