Python 哈希表的实现——字典
文章目录
前言
接触过 Python 的小伙伴应该对【字典】这一数据类型都了解吧
虽然 Python 没有显式名称为“哈希表”的内置数据结构,但是字典是哈希表实现的数据结构
在 Python 中,字典的键(key)被哈希,哈希值决定了键对应的值(value)在字典底层数据存储中的位置
那么今天我们就来看看哈希表的原理以及如何实现一个简易版的 Python 哈希表
ps:文中提到的 Python 指的是 CPyhton 实现
何为哈希表?
哈希表(hash table)通常是基于“键-值对”存储数据的数据结构
哈希表的键(key)通过哈希函数转换为哈希值(hash value),这个哈希值决定了数据在数组中的位置。这种设计使得数据检索变得非常快
举个例子,下面有一组键值对数据,其中歌手姓名是 key,歌名是 value
+------------------------------+
| Key | Value |
+------------------------------+
| Kanye | Come to life |
| XXXtentacion | Moonlight |
| J.cole | All My Life |
| Lil wanye | Mona Lisa |
| Juice WRLD | Come & Go |
+------------------------------+
如果我们想要将这些键值对存储在哈希表中,首先需要将键的值转换成哈希表的数组的索引,这时候就需要用到哈希函数了
哈希函数是哈希表实现的主要关键,它能够处理键然后返回存放数据的哈希表中对应的索引
一个好的哈希函数能够在数组中均匀地分布键,尽量避免哈希冲突(两个键返回了相同的索引)
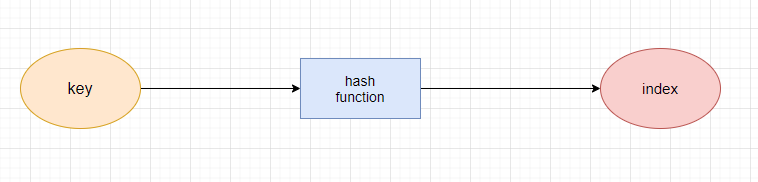
哈希函数是如何处理键的,这里我们创建一个简易的哈希函数来模拟一下(实际上哈希函数要比这复杂得多)
def simple_hash(key, size):
return ord(key[0]) % size
这个简易版哈希函数将歌手名(即 key)首字母的 ASCII 值与哈希表大小取余,得出来的值就是歌名(value)在哈希表中的索引
那这个简易版哈希函数有什么问题呢?聪明的你一眼就看出来了:容易出现碰撞。因为不同的键的首字母有可能是一样的,就意味着返回的索引也是一样的
例如我们假设哈希表的大小为 10 ,我们以上面的歌手名作为键然后执行 simple_hash(key, 10) 得到索引
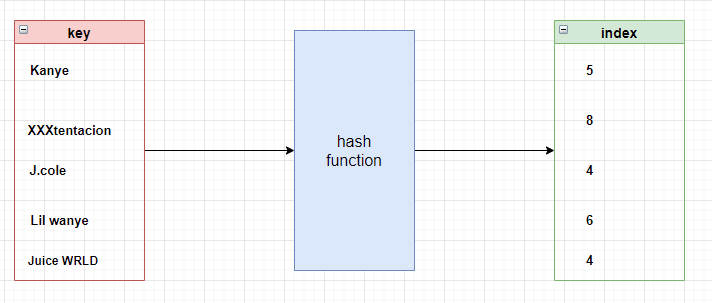
可以看到,由于Juice WRLD 和 J.cole 的首字母都一样,哈希函数返回了相同的索引,这里就发生了哈希碰撞
虽然几乎不可能完全避免任何大量数据的碰撞,但一个好的哈希函数加上一个适当大小的哈希表将减少碰撞的机会
当出现哈希碰撞时,可以使用不同的方法(例如开放寻址法)来解决碰撞
应该设计健壮的哈希函数来尽量避免哈希碰撞
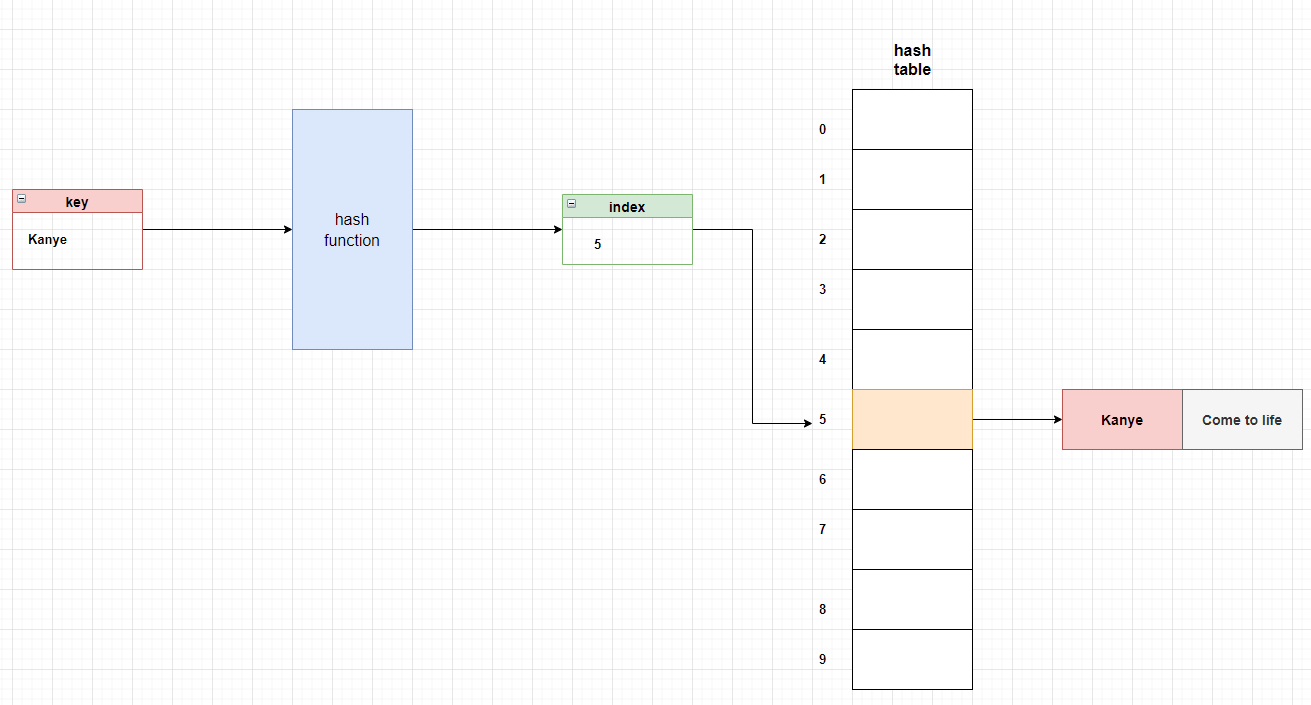
我们再来看其他的键,Kanye 通过 simple_hash() 函数返回 index 5,这意味着我们可以在索引 5 (哈希表的第六个元素)上找到 其键 Kanye 和值Come to life
哈希表优点
在哈希表中,是根据哈希值(即索引)来寻找数据,所以可以快速定位到数据在哈希表中的位置,使得检索、插入和删除操作具有常数时间复杂度 O(1) 的性能
与其他数据结构相比,哈希表因其效率而脱颖而出
不但如此,哈希表可以存储不同类型的键值对,还可以动态调整自身大小
Python 中的哈希表实现
在 Python 中有一个内置的数据结构,它实现了哈希表的功能,称为字典
Python 字典(dictionary,dict)是一种无序的、可变的集合(collections),它的元素以 “键值对(key-value)”的形式存储
字典中的 key 是唯一且不可变的,这意味着它们一旦设置就无法更改
my_dict = {"Kanye": "Come to life", "XXXtentacion": "Moonlight", "J.cole": "All My Life"}
在底层,Python 的字典以哈希表的形式运行,当我们创建字典并添加键值对时,Python 会将哈希函数作用于键,从而生成哈希值,接着哈希值决定对应的值将存储在内存的哪个位置中
所以当你想要检索值时,Python 就会对键进行哈希,从而快速引导 Python 找到值的存储位置,而无需考虑字典的大小
my_dict = {}
my_dict["Kanye"] = "Come to life" # 哈希函数决定了 Come to life" 在内存中的位置
print(my_dict["Alice"]) # "Come to life"
可以看到,我们通过方括号[key]来访问键对应的值,如果键不存在,则会报错
print(my_dict["Kanye"]) # "Come to life"
# Raises KeyError: "Drake"
print(my_dict["Drake"])
为了避免该报错,我们可以使用字典内置的 get() 方法,如果键不存在则返回默认值
print(my_dict.get('Drake', "Unknown")) # Unknown
在 python 中实现哈希表
首先我们定义一个 HashTable 类,表示一个哈希表数据结构
class HashTable:
def __init__(self, size):
self.size = size
self.table = [None]*size
def _hash(self, key):
return ord(key[0]) % self.size
在构造函数 __init__() 中:
size表示哈希表的大小table是一个长度为size的数组,被用作哈希表的存储结构。初始化时,数组的所有元素都被设为None,表示哈希表初始时不含任何数据
在内部函数 _hash() 中,用于计算给定 key 的哈希值。它采用给定键 key 的第一个字符的 ASCII 值,并使用取余运算 % 将其映射到哈希表的索引范围内,以便确定键在哈希表中的存储位置。
然后我们接着在 HashTable 类中添加对键值对的增删查方法
class HashTable:
def __init__(self, size):
self.size = size
self.table = [None]*size
def _hash(self, key):
return ord(key[0]) % self.size
def set(self, key, value):
hash_index = self._hash(key)
self.table[hash_index] = (key, value)
def get(self, key):
hash_index = self._hash(key)
if self.table[hash_index] is not None:
return self.table[hash_index][1]
raise KeyError(f'Key {key} not found')
def remove(self, key):
hash_index = self._hash(key)
if self.table[hash_index] is not None:
self.table[hash_index] = None
else:
raise KeyError(f'Key {key} not found')
其中,set() 方法将键值对添加到表中,而 get() 该方法则通过其键检索值。该 remove() 方法从哈希表中删除键值对
现在,我们可以创建一个哈希表并使用它来存储和检索数据:
# 创建哈希表
hash_table = HashTable(10)
# 添加键值对
hash_table.set('Kanye', 'Come to life')
hash_table.set('XXXtentacion', 'Moonlight')
# 获取值
print(hash_table.get('XXXtentacion')) # Outputs: 'Moonlight'
# 删除键值对
hash_table.remove('XXXtentacion')
# 报错: KeyError: 'Key XXXtentacion not found'
print(hash_table.get('XXXtentacion'))
前面我们提到过,哈希碰撞是使用哈希表时不可避免的一部分,既然 Python 字典是哈希表的实现,所以也需要相应的方法来处理哈希碰撞
在 Python 的哈希表实现中,为了避免哈希冲突,通常会使用开放寻址法的变体之一,称为“线性探测”(Linear Probing)
当在字典中发生哈希冲突时,Python 会使用线性探测,即从哈希冲突的位置开始,依次往后查找下一个可用的插槽(空槽),直到找到一个空的插槽来存储要插入的键值对。
这种方法简单直接,可以减少哈希冲突的次数。但是,它可能会导致“聚集”(Clustering)问题,即一旦哈希表中形成了一片连续的已被占用的位置,新元素可能会被迫放入这片区域,导致哈希表性能下降
为了缓解聚集问题,假若当哈希表中存放的键值对超过哈希表长度的三分之二时(即装载率超过66%时),哈希表会自动扩容
最后总结一下:
- 在哈希表中,是根据哈希值(即索引)来寻找数据,所以可以快速定位到数据在哈希表中的位置
- Python 的字典以哈希表的形式运行,当我们创建字典并添加键值对时,Python 会将哈希函数作用于键,从而生成哈希值,接着哈希值决定对应的值将存储在内存的哪个位置中
- Python 通常会使用线性探测法来解决哈希冲突问题
Python技术资源分享
小编是一名Python开发工程师,自己整理了一套 【最新的Python系统学习教程】,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。
保存图片微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

如果你是准备学习Python或者正在学习,下面这些你应该能用得上:
1、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

2、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

3、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

4、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

5、清华编程大佬出品《漫画看学Python》
用通俗易懂的漫画,来教你学习Python,让你更容易记住,并且不会枯燥乏味。

6、Python副业兼职与全职路线

这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
👉CSDN大礼包:《Python入门资料&实战源码&安装工具】免费领取(安全链接,放心点击)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux环境之Centos安装Docker流程
- a*x*x+b*x+c=0方程的解
- 有信息搜索、最佳优先搜索、贪心搜索、A_搜索详解
- 用 Java 流的方式实现树型结构
- Mysql字段的各种时间类型
- 防火墙双机热备配置步骤
- 小红书青年文化洞察:新“旷野文学”兴起,用户回归人间清醒?
- 平凡之路_2023年
- 要想做好私域运营,这几步最为关键
- 4.7 MEMORY AS A LIMITING FACTOR TO PARALLELISM