如何理解Transformer论文中的positional encoding,和三角函数有什么关系?
大家好,我分享交流下这个问题。
Positional Encoding
掏出一张被无数人讲述的架构图。
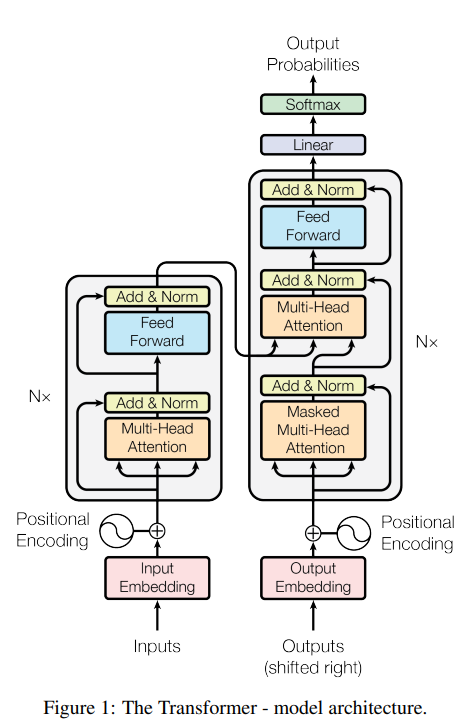
Transformer 模型中的位置编码(Positional Encoding)是为了让模型能够考虑单词在句子中的位置。
由于 Transformer 的自注意力(Self-Attention)机制本身并不考虑单词的顺序,位置编码就成为了引入这种顺序信息的关键。
位置如图
位置编码(Positional Encoding)分别加到了输入嵌入(Input Embedding)和输出嵌入(Output Embedding)之后。
输入嵌入(Input Embedding)
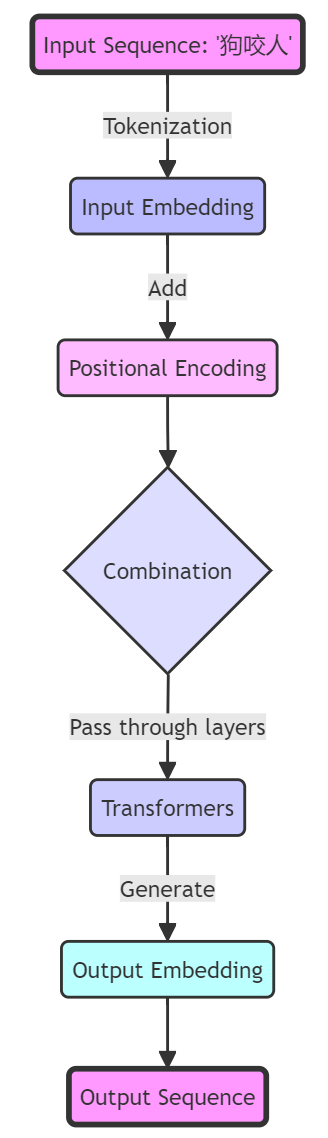
输入序列,例如序列狗咬人 这些单词也叫Token(词符)。
Token 是文本序列中的最小单位,可以是单词、字符等形式。
tokens:[“狗”, " 咬人"]。Token 的词汇表中包含了所有可能情况,每个 token 预先被分配了唯一的数字 ID,称为 token ID。
最后是词嵌入(Word Embedding)。词嵌入的目标是把每个 token 转换为固定长度的向量表示
这些向量可以根据 token ID 在预训练好的词嵌入库(例如 Word2Vec 等)中拿到。
结合示例(“狗咬人描述”)

对于输入序列“狗咬人”,模型首先会获得每个单词“狗”和“咬人”的嵌入向量。
然后,模型会为序列中的每个位置生成一个位置编码向量。
最后,每个单词的嵌入向量会与其对应位置的位置编码向量相加,生成最终的向量,该向量同时包含了单词的语义信息和位置信息。
这样,即使是单词“狗”出现在不同的位置,其最终的向量表示也会因为位置编码的加入而有所不同,从而使得模型能够区分“狗咬人”和“人咬狗”。
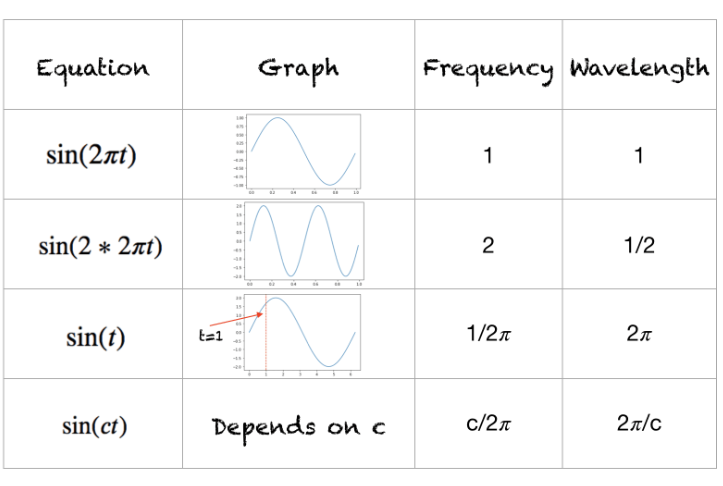
三角函数
位置编码(Positional Encoding)不一定非要使用三角函数。虽然在原始的Transformer模型中,位置编码使用了正弦和余弦函数的固定模式,但这不是唯一的方法。
Transformer 模型中的位置编码(Positional Encoding)是为了让模型能够考虑单词在句子中的位置。由于 Transformer 的自注意力(Self-Attention)机制本身并不考虑单词的顺序,位置编码就成为了引入这种顺序信息的关键。
假设你有一个长度为L的输入序列,要计算第K个元素的位置编码。位置编码由不同频率的正弦和余弦函数给出:
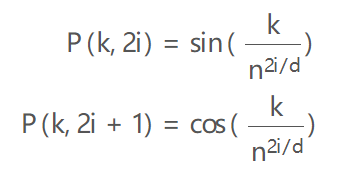
- k:对象在输入序列中的位置,0<=k<L/2
- d: 输出嵌入空间的维度
- P(k,j): 位置函数,用于映射输入序列中k处的元素到位置矩阵的(k,j)处
- n:用户定义的标量,由 Attention Is All You Need 的作者设置为 10,000。
- i: 用于映射到列索引,0<=i<d/2,单个值i映射到正弦和余弦函数
你可以看到偶数位置对应正弦函数,奇数位置对应余弦函数。
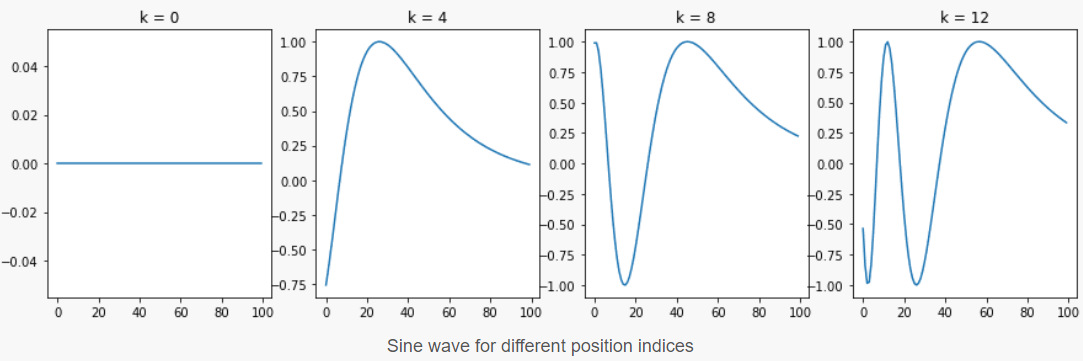
如果有不清楚可以看下A Gentle Introduction to Positional Encoding in Transformer Models, Part 1 ,有代码和图表展示。
中文版本:http://www.bimant.com/blog/transformer-positional-encoding-illustration/
总结
后面有疑问咱们继续交流!
独立开源软件开发者,SolidUI作者,对于新技术非常感兴趣,专注AI和数据领域,如果对我的文章内容感兴趣,请帮忙关注点赞收藏,谢谢!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java项目:114SSM图书管理系统
- L1-071 前世档案(Java)
- 二分查找算法模版
- ThreadLocal 是什么?它的实现原理是什么?
- 【前端】Vue3项目搭建
- 模型评估:超参数调优
- IDEA版SSM入门到实战(Maven+MyBatis+Spring+SpringMVC) -Spring的AOP前奏
- 【Tomcat】在一台计算机上运行两个Tomcat服务
- 嵌入式培训机构四个月实训课程笔记(完整版)-Linux网络编程第三天-UDP编程练习题(物联技术666)
- 2023蓝帽杯初赛取证