目标检测之序章-类别、必读论文和算法对比(实时更新)
文章目录
前言
目标检测是计算机视觉领域(CV)热门且较成熟的主流研究方向之一,其应用广泛(自动驾驶、安防监控、医学影像分析、零售业货品管理等等)且已经深入到我们生活的方方面面,现在从个人学习角度,开展目标检测系列文章,主要侧重为深度学习,希望起到抛砖引玉的效果,如果有误的地方敬请指正。
PS:应该注意到,近些年来,CV模型有融合的趋势,原来的目标检测模型不再是单一任务,往往能同时处理多种任务:目标检测、语义分割、实例分割、姿态检测等。
一、目标检测算法分类
1. 传统的目标检测算法
传统目标检测流程:
- 图像预处理(归一化、图像增强等)
- 寻找候选区(如穷举策略:采用滑动窗口,且设置不同的大小,不同的长宽比对图像进行遍历,时间复杂度高)
- 特征提取(SIFT、HOG等;形态多样性、光照变化多样性、背景多样性使得特征鲁棒性差)
- 分类器分类(主要有SVM、Adaboost等)
- 后处理(去除多余候选框等)
例:Cascade+HOG/DPM+Haar/SVM
2.候选区域/窗+深度学习分类(Two Stage)
通过提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案,如:
- R-CNN(Selective Search+CNN+SVM)
- SPP-Net(ROI Pooling)
- Fast R-CNN(Selective Search+CNN+ROI)
- Faster R-CNN(RPN+CNN+ROI)
- Mask R-CNN
…
3.基于深度学习的回归方法(One Stage)
YOLO/SSD/DenseBox等方法
结合RNN算法的RRC detection
结合DPM的Deformable CNN
…
4.基于Transformer的方法
ViT backbone
Swin Transformer backbone + MaskRCNN
…
二、必读文献
| 类别 | 流程/算法 | 论文、年份 | Google学术引用次数 |
| 传统算法 | 区域选择 => 特征提取 => 分类器分类 | ||
| One Stage | |||
| R-CNN(Selective Search+CNN+SVM) | 《Rich feature hierarchies for accurate object detection and semantic segmentation》,2014 | 32030 | |
| SPP-Net(ROI Pooling) | 《Spatial pyramid pooling in deep convolutional networks for visual recognition》,2015 | 12948 | |
| Fast R-CNN(Selective Search+CNN+ROI) | 《Fast r-cnn》,2015 | 28730 | |
| Faster R-CNN(RPN+CNN+ROI) | 《Faster r-cnn: Towards real-time object detection with region proposal networks》,2015 | 62285 | |
| Mask RCNN | 《Mask r-cnn》,2017 | 30742 | |
| Two Stage | |||
| YOLOv1 | 《You only look once: Unified, real-time object detection》,2016 | 37319 | |
| SSD | 《SSD: Single shot multibox detector》,2016 | 31541 | |
| YOLOv2 | 《YOLO9000: better, faster, stronger》,2017 | 17556 | |
| RetinaNet | 《Focal Loss for Dense Object Detection》,2017 | 22861 | |
| YOLOv3 | 《Yolov3: An incremental improvement》,2018 | 21678 | |
| EfficientDet | 《EfficientDet: Scalable and Efficient Object Detection》,2020 | 4200 | |
| YOLOv4 | 《Yolov4: Optimal speed and accuracy of object detection》,2020,Alexey Bochkovskiy团队 | 10758 | |
| YOLOv5 | https://github.com/ultralytics/yolov5,2020,Ultralytics团队(无paper) | - | |
| YOLOx | 《Yolox: Exceeding yolo series in 2021》,2021,旷视科技 | 1813 | |
| YOLOv6 | 《YOLOv6: A single-stage object detection framework for industrial applications》,2022,美团 | 314 | |
| YOLOv7 | 《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》,2023,Alexey Bochkovskiy团队 | 1251 | |
| YOLOv8 | https://github.com/ultralytics/ultralytics,2023,Ultralytics团队(无paper) | - | |
| Transormer | |||
| DETR | 《End-to-end object detection with transformers》,2020,Facebook | 6937 | |
| Swin Transformer | 《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 》,2021 | 11969 | |
| DINO | 《Dino: Detr with improved denoising anchor boxes for end-to-end object detection》,2022 | 430 | |
| stable DINO | 《Detection Transformer with Stable Matching》,2023 | 5 | |
| CO DETR | 《DETRs with Collaborative Hybrid Assignments Training》,2023,商汤 | 47 |
Paper list from 2014 to now(2019)
源自GitHub - hoya012/deep_learning_object_detection: A paper list of object detection using deep learning.

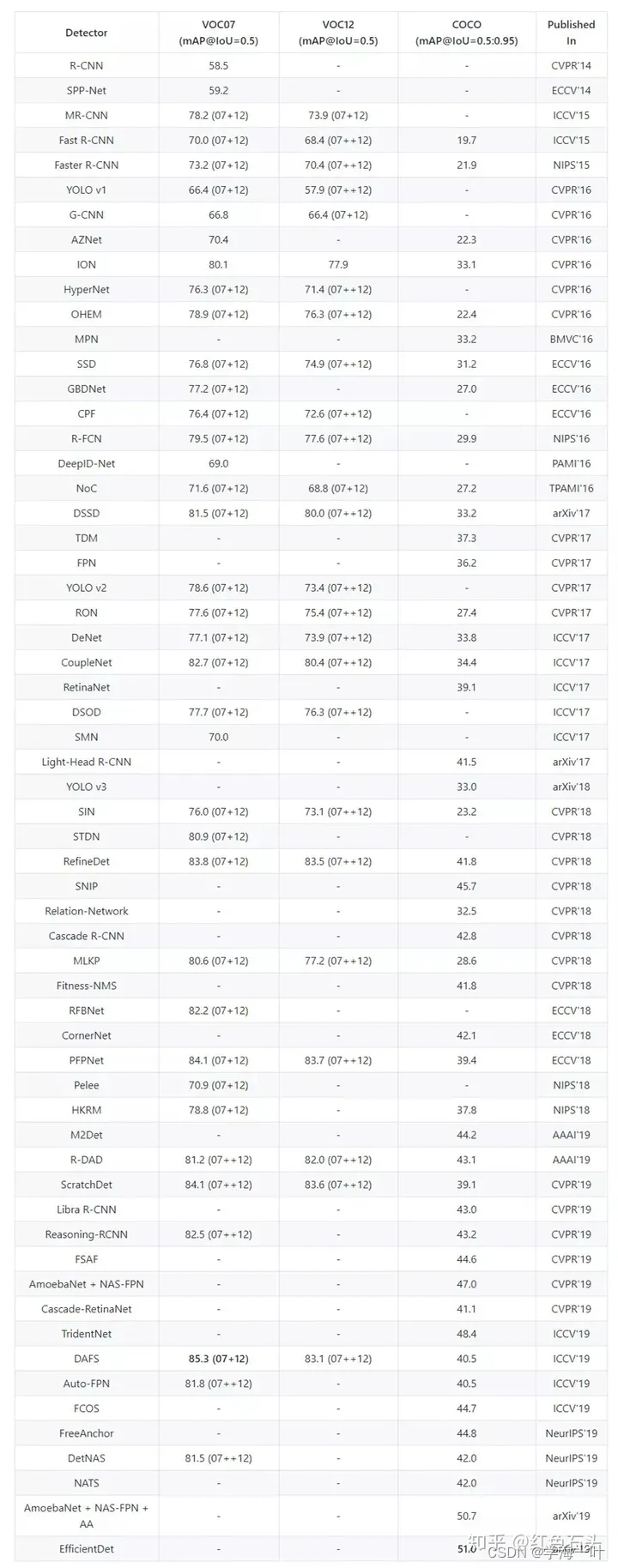
三、算法对比
1.总体描述-精度和速度
| 优缺点 | One-Stage | Two-Stage | Transformer-based |
| 优点 | 1.速度快 2.避免背景错误产生false positives 3.学到物体的泛化特征 | 1.精度高(定位、检出率) 2.小目标检测和复杂场景中表现较好 | 1.大数据量下精度更高(定位、检出率) 2.有利于多模态数据融合 3.感受野更大 |
| 缺点 | 1.精度低(定位、检出率) 2.小物体的检测效果不好 | 1.速度慢 2.训练时间长 3.误报相对高 | 1.更占用显存 2.训练时间长 3.无归纳偏置,小数据量下表现不如CNN架构 |
2.目标检测数据集
典型的数据集有:PASCAL VOC, ImageNet, MS-COCO, Open Images等
VOC (PASCAL Visual Object Classes) :是经典的计算机视觉竞赛PASCAL VOC Challenges的数据集,时间跨度为2005-2012,任务包括图像分类、目标检测、语义分割和动作检测。数据集包含20个种类,其中 VOC07和VOC12最为常用,近年来被更大的数据集像ILSVRC和MS-COCO逐渐取代。
ImageNet(ILSVRC):计算机视觉竞赛The ImageNet Large Scale Visual Recognition Challenge采用的数据集 ,时间跨度为2010-2017, 共包含200个种类
MS-COCO :是微软构建的一个数据集,从2015起沿用至今,最大的特点是除了bounding box 注释,还给了segmentation。MS-COCO也包含更多的小目标(面积小于图像大小的百分之一)和稠密的目标。这些特征使得MS-COCO更接近于现实生活。MS-COCO已经成了目标检测家族中的实际标准。
Open Image: 2018年 the Open Images Detection challenge出现。两个任务:1常规n目标检测。2视觉关系检测,即检测特殊关系中成对的目标。600个种类。
DOTA:武汉大学于 2017 年发布的大规模遥感图像数据集,为Object Detection In Aerial Images on DOTA竞赛数据集,目前有三个版本:
- DOTA-v1.0包含15个常见类别、2,806张图像和188、282个实例。DOTA-v1.0中训练集、验证集和测试集的比例分别为1/2、1/6和1/3。15个类别为:飞机、船只、储蓄罐、棒球内场、网球场、篮球场、田径场、海港、桥、大型车辆、小型车辆、直升飞机、英式足球场、环形路线、游泳池。
- DOTA-v1.5 使用与 DOTA-v1.0 相同的图像,但也注释了极小的实例(小于 10 像素)。此外,还增加了一个新类别“集装箱起重机”。它总共包含 403,318 个实例。图像数量和数据集分割与DOTA-v1.0相同。该版本是针对 2019 年 DOAI 挑战赛(关于航空图像中的对象检测)与 IEEE CVPR 2019 联合发布的。
- DOTA-v2.0 收集了更多 Google Earth、GF-2 卫星和航拍图像。DOTA-v2.0中有18个常见类别、11,268张图像和1,793,658个实例。相比DOTA-v1.5,进一步增加了“机场”和“直升机停机坪”的新类别。DOTA 的 11,268 张图像分为训练集、验证集、测试开发集和测试挑战集。为了避免过拟合问题,训练集和验证集的比例小于测试集。此外,包含两个测试集,即 test-dev 和 test-challenge。训练包含 1,830 张图像和 268,627 个实例,验证包含 593 个图像和 81,048 个实例,test-dev 包含 2,792 个图像和 353,346 个实例,test-challenge包含 6,053 张图像和 1,090,637 个实例。
DIOR:西北工业大学2019年发布的遥感图像目标检测的大规模基准数据集,含23463张图片和190288实例,覆盖20种目标:飞机、机场、棒球场、篮球场、桥梁、烟囱、水坝、高速公路服务区、高速公路收费站、港口、高尔夫球场、地面田径场、天桥、船舶、体育场、储罐、网球场、火车站、车辆和风机。


3.精度对比
Meta AI 收集的SOTA的模型榜单
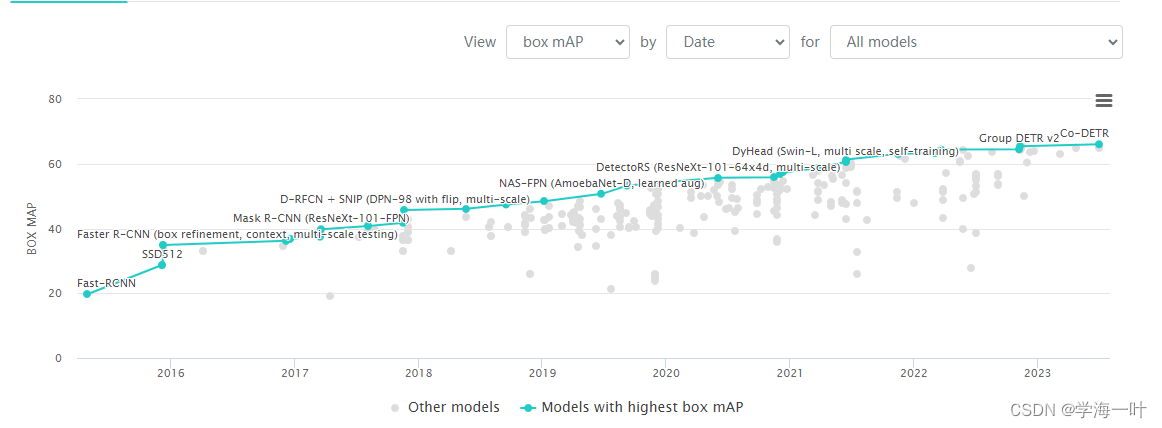
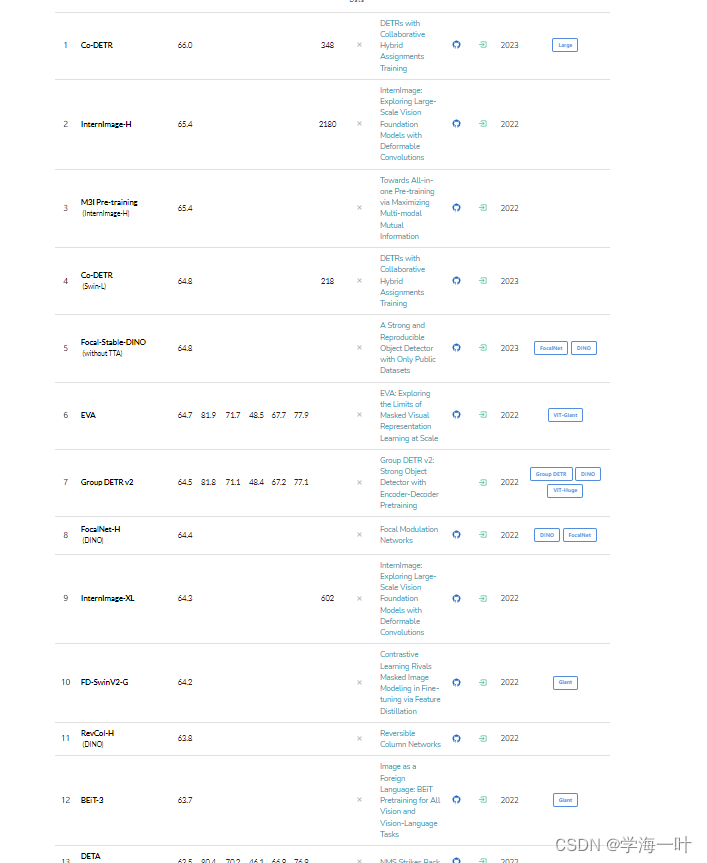
《Object Detection in 20 Years: A Survey,2023》
总结的算法精度对比,注意这里的算法全为原始算法不包括变体:
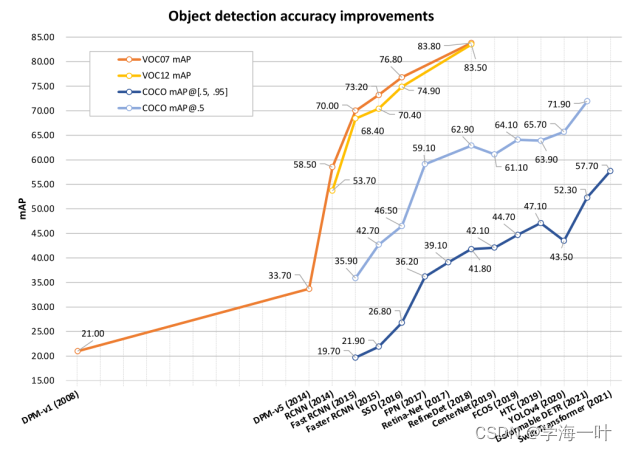
从图中看出 COCO数据集 mAP[.5, .95]精度方面:
Faster RCNN < SSD < FPN < Retine-Net < RefineDet < CenterNet < YOLOv4 < DETR < Swin Transformer
Yolov3,2018
YOLOv3论文(2018)所述:精度比SSD变体高得多,AP50和当时的SOTA-RetinaNet相当,但RetinaNet耗时为YOLOv3的3.8倍还多
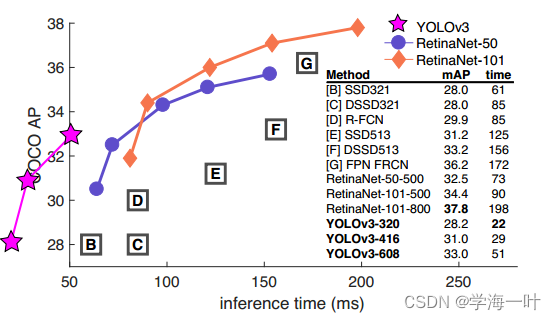
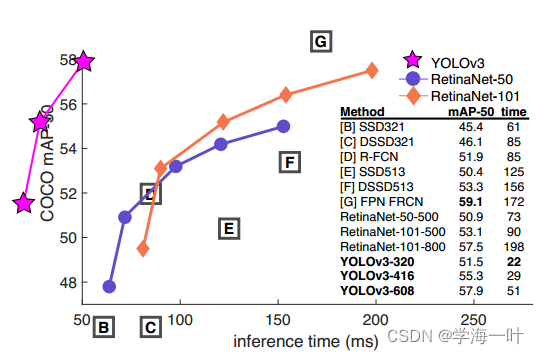
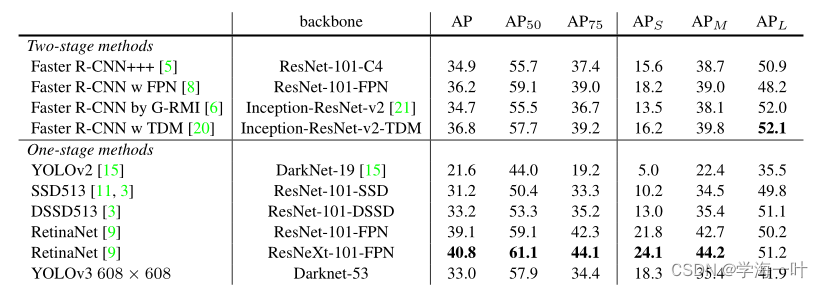
编者注:从图中看出mAP[.5, .95]精度方面,YOLOv2 < SSD < YOLOv3 < Faster RCNN及其变体 < RetinaNet
EfficientDet, 2020
EfficientDet论文所述(2020): EfficientDet实现了最先进的52.2%COCO AP,其参数和FLOPs比过往的目标检测算法少得多。
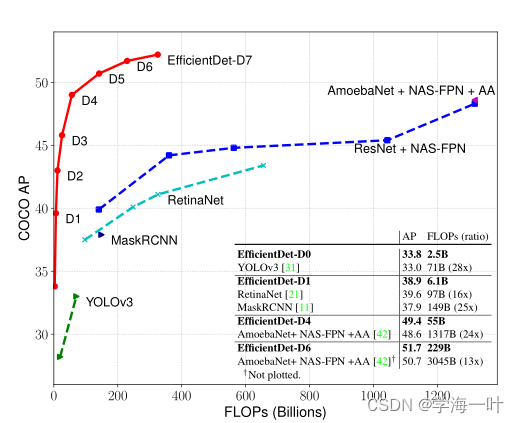
Yolov4,2020
YOLOv4论文(2020)所述: 在MS COCO数据集上得精度为43.5%AP(65.7%AP50),Tesla V100上实时速度约为65 FPS,和其他最先进的目标检测算法比较:YOLOv4的运行速度是EfficientDet的两倍,性能相当。相比于YOLOv3,AP和FPS分别提高了10%和12%
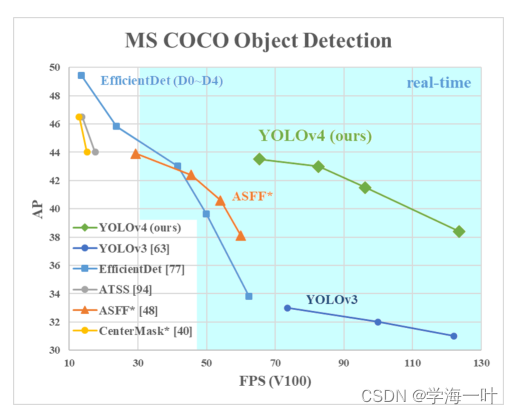
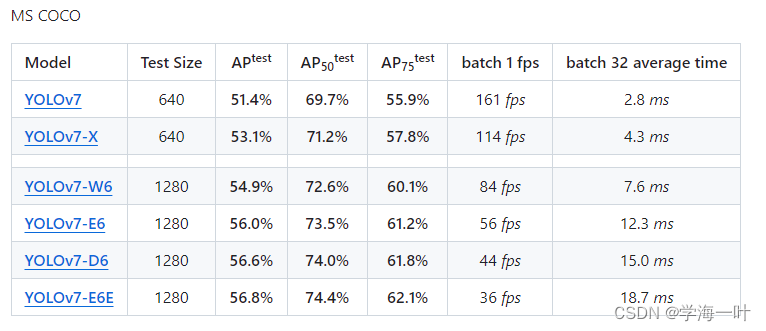
YOLOv7,2022
Yolo v7 for COCO 2017 数据集
train 训练
val 调参
test 测试
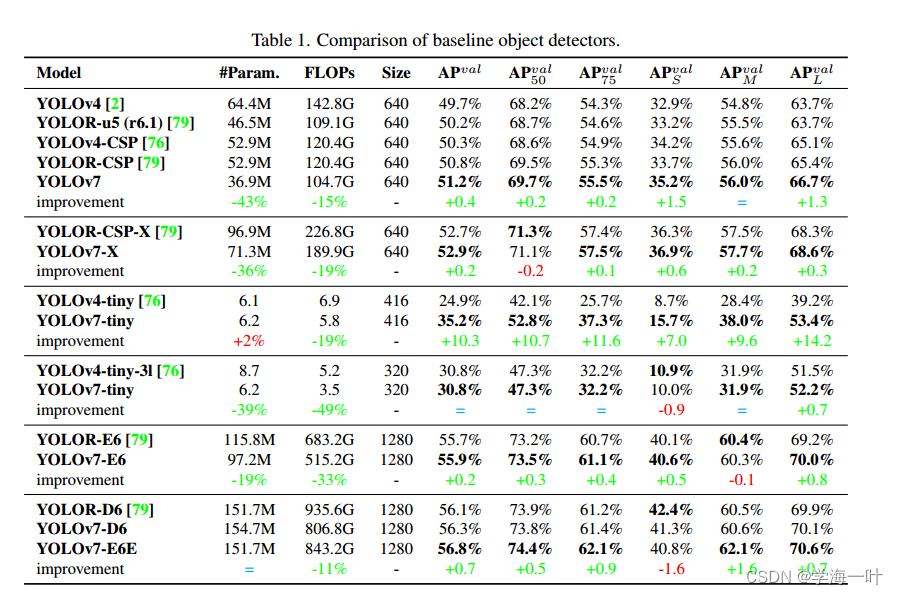
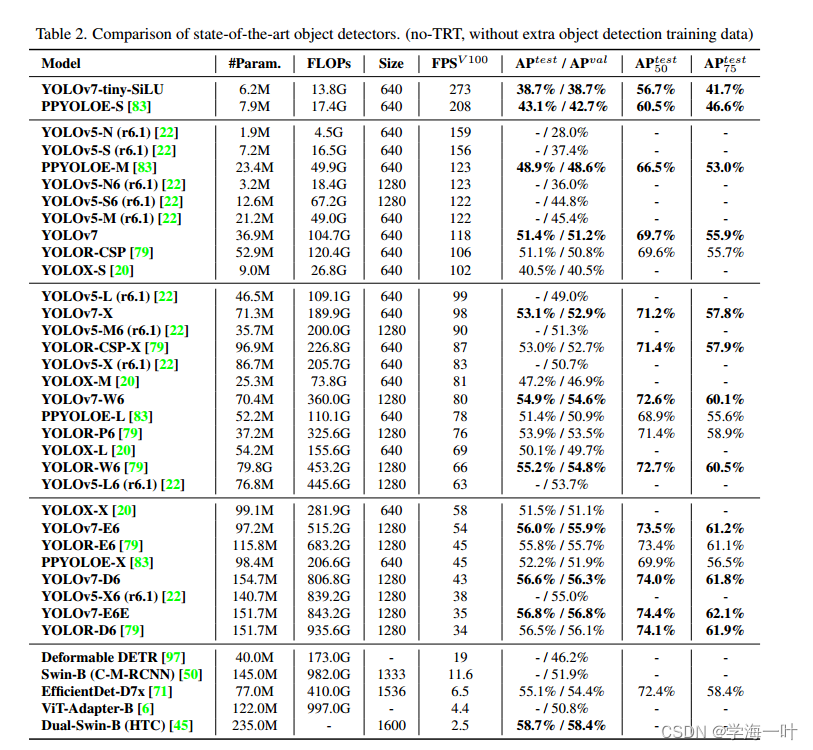
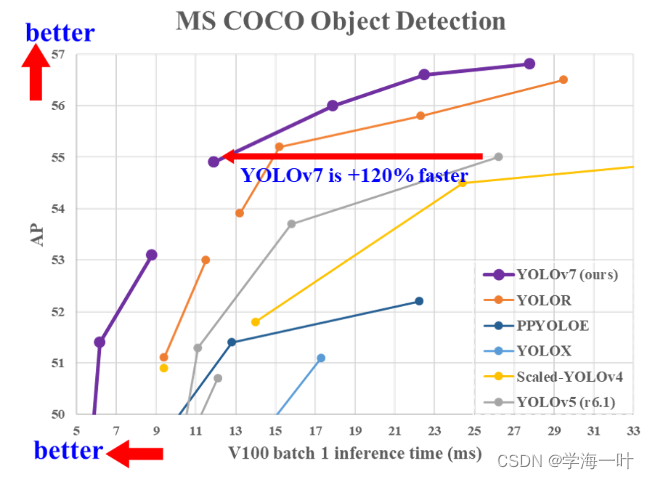
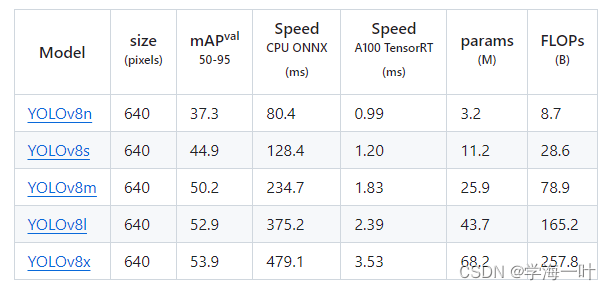
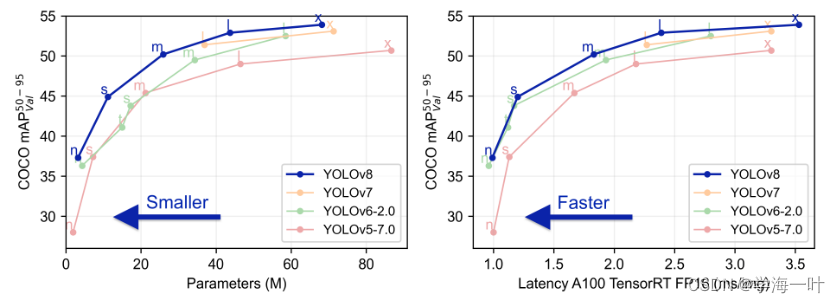
YOLOv8,2023
保证精度的情况下,速度极大提升
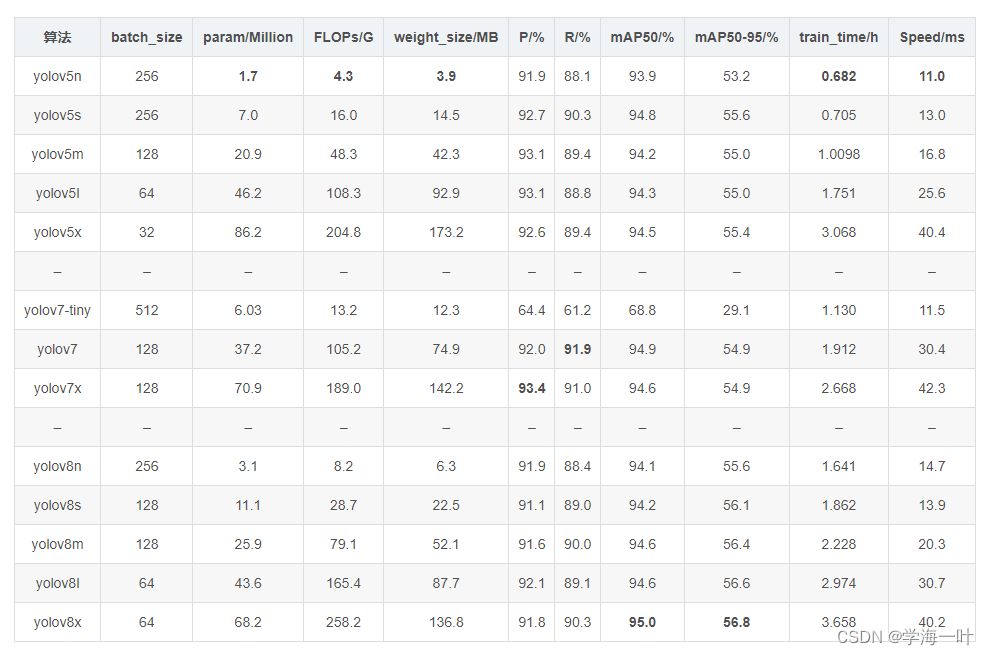
小麦检测数据集的YOLO系列模型精度对比
来源于YOLOv8(n/s/m/l/x)&YOLOv7(yolov7-tiny/yolov7/yolov7x)&YOLOv5(n/s/m/l/x)不同模型参数/性能对比(含训练及推理速度)-CSDN博客
Faster RCNN,2015

Mask RCNN,2017
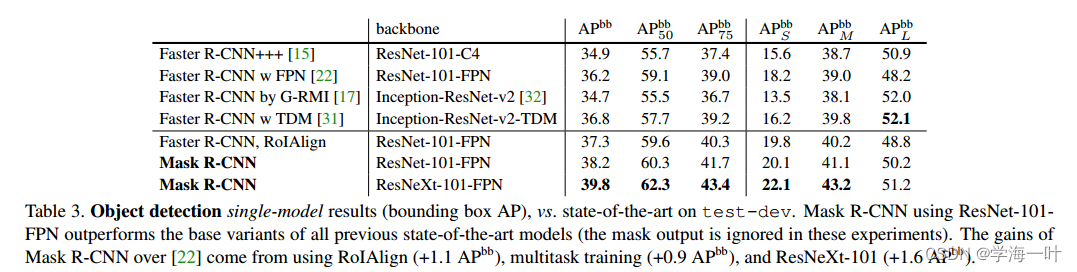
DETR,2020
第一个基于transformer的端到端算法,没有anchor前处理和NMS后处理,但是Detr收敛慢,训练慢,推理也慢
虽然 DETR(COCO/44.9%mAP)取得了较高的检测精度,但DETR采用固定长度的目标查询向量与图像特征进行全局交互。这种方式需要长时间的注意力权重训练才能关注到特征图上稀疏且关键的位置,导致模型收敛时间过长,在 COCO 上,需要 500 个 epochs 才能收敛,速度仅为 Faster RCNN 的 5%~10%。其次,对小目标检测效果较差,这主要是由于DETR仅使用单一尺度的特征进行预测以及在处理高分辨率输入时有很高的计算复杂度。最后,相较于 CNN 目标检测算法,DETR更加依赖数据的规模,当采用小规模数据训练时,模型性能明显下降。
Swin Transformer,2021
2021 ICCV最佳论文,可直接用于多种视觉任务,包括图像分类(ImageNet-1K中取得86.4 top-1 acc)、目标检测(COCO test-dev 58.7 box AP和51.1 mask AP)和语义分割(ADE20K 53.5 val mIoU,并在其公开benchmark中排名第一),其中在COCO目标检测与ADE20K语义分割中均为state-of-the-art。**
DINO,2022
DINO(DETR withImproved deNoising anchOr boxes),从2022年三月初霸榜至7月,该模型第一次让DETR (DEtection TRansformer)类型的检测器取得了目标检测的SOTA性能,在COCO上取得了63.3 AP的性能,相比之前的SOTA检测器将模型参数和训练数据减少了十倍以上
Stable DINO,2023
通过与 FocalNet-Huge 主干网相结合,Focal-Stable-DINO 在 COCO val2017 上达到 64.6 AP,在 COCO test-dev 上达到 64.8 AP,而无需增加任何测试时间
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- eBPF:arm平台上的uprobe
- 基于NASM搭建一个能编译汇编语言的汇编软件工具环境(利用NotePad++)
- 英飞凌TC3xx之一起认识GTM系列(四)如何实现GTM与GPIO关联的配置(ATOM/TIM实例)
- 单点定位算法流程和编程实践
- TCP/IP详解——IP协议,IP选路
- 【数据结构】队列的使用|模拟实现|循环队列|双端队列|面试题
- springboot流浪动物救助系统-计算机毕业设计源码78174
- 【Linux】进程周边006之进程地址空间
- 捕捉“五彩斑斓的黑”:锗基短波红外相机的多种成像应用
- 梯度消失与梯度爆炸的问题小结