GBASE南大通用-Teradata迁移到GBase 8a解决方案
GBASE南大通用自主研发的GBase 8a MPP (GBase UP LDW)分布式逻辑数据仓库,已经完成了100+用户TeraData等国外数据库替换迁移。通过众多项目的PoC及后续签约的实施,在替换Teradata产品方面,GBase 8a积累了丰富的实施经验,形成了一套完整的迁移实施方案,可快速复制推广,实现由teradata到GBase 8a的高精准迁移。
下面根据GBase 8a的迁移经验,从上到下对迁移方案进行阐述:
一、先看一个项目迁移后的实施效果
·搭建两套A(7节点)、B(14节点)集群承载主要业务
·SGA、ODS、F、DW、DM各层整体数据量200+TB
·完成1000+个程序迁移工作
·日增量基础数据每日?7:00?前完成
·月度报表在每月?3?日前完成数据发布
·整体性能提升?2~10?倍

二、项目迁移流程是迁移工作的指导框架,可有效组织迁移工作的有序开展,主要流程步骤如下图:
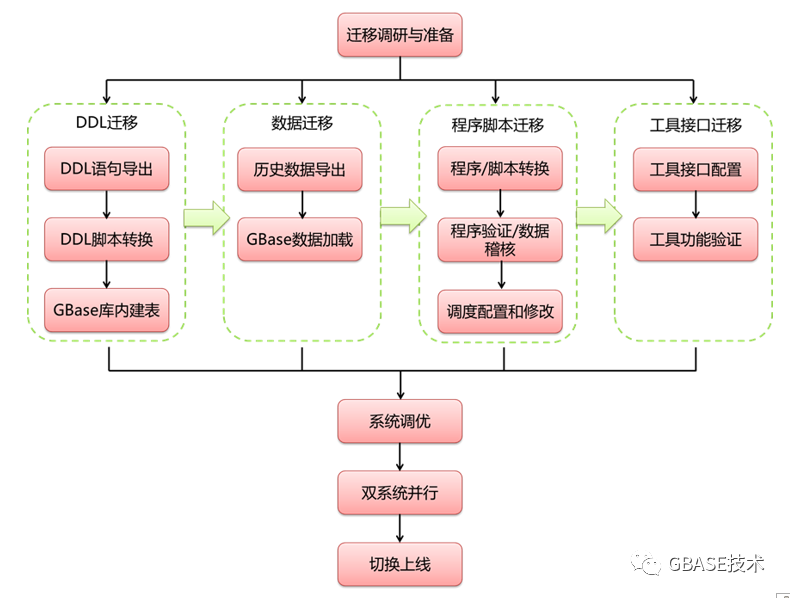
三、项目迁移前期调研及迁移方案设计,主要进行迁移前的调研评估,以及用来进行指导迁移落地执行的迁移方案形成。内容包括如下几点:
1、迁移前期调研内容及要点
调研的重点是了解客户需求和当前的痛点,迁移后要有针对性的给客户提供改善的方案!
迁移实施调研
·迁移实施调研是迁移项目的重要工作环节,此部分为项目实施不可省略环节
·迁移实施调研根据项目售前阶段的推进情况可能在签约前进行也可以在签约后进行
迁移实施调研的目标
·了解项目迁移实施范围
·评估迁移工作量、实施工期、人员数量及能力要求
·评估迁移技术难点、项目主要风险
迁移实施调研的内容
·迁移系统现状:架构、配置、上下游情况、仓库逻辑设计
·系统运行状况:应用场景、作业类型、负载情况、ETL加工整体流程、作业数、并发情况、加工时间
·系统指标要求:不同类型作业的指标要求,如跑批业务的时间窗口要求、即席查询的响应时间要求、并发能力要求等
·接口情况:上游入库方式、下游供数方式、第三方工具支持要求
2、迁移方案设计
迁移方案是根据迁移调研的结果,并针对客户当前的需求和痛点制定的项目实施方案,主要包括:
迁移系统的硬件配置和部署方案
针对客户需求和痛点提供的针对性解决方案
迁移实施的步骤和工作内容
工作计划
3、硬件资源评估
替换TD的GBase 8a集群的硬件配置评估方式采用倒推的方法,即首先需要获取TD的详细配置信息,之后再根据TD一体机的CPU整体核数、内存容量、磁盘容量倒推GBase 8a集群单台服务器的配置以及配置服务器的台数。原则上GBase 8a集群所有服务器的CPU整体核数、内存容量和磁盘容量及盘片数量上应不得小于TD一体机配置的2倍。

四、数据及业务的迁移,主要进行全量、增量数据的迁移、ETL追跑、迁移前后数据的比对方式等技术难点进行提前规划,数据流程的迁移流程如下所示。
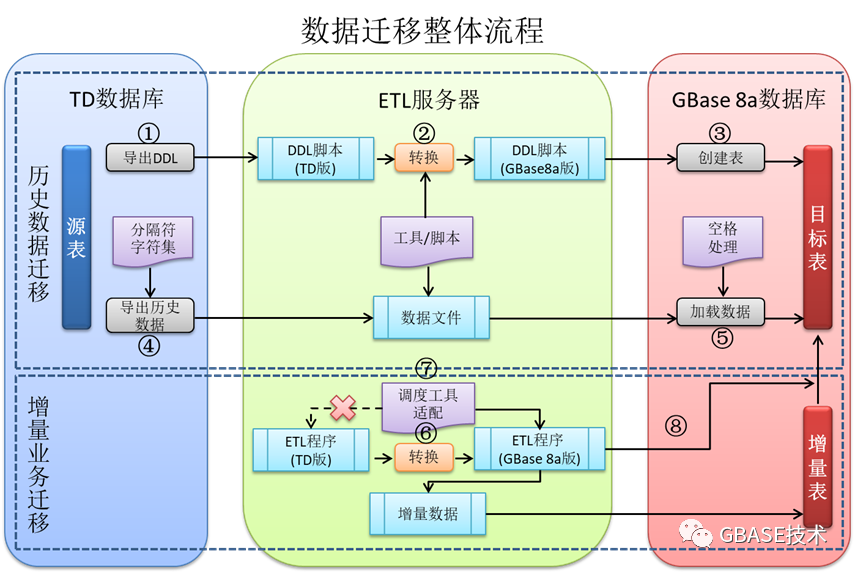
1、全量数据迁移方案评估方案及要点
迁移全量数据,其迁移的时间窗口很大程度的决定全量迁移是一次性还是分批迁移。主要有以下几个方面的因素影响,需要重点考虑:
·源数据库迁移数据量【需要实测以评估源库内数据的压缩比】
·业务允许的停机时间窗口【此过程中源库需要处于只读状态,且负载要轻,往往是硬约束条件】
·源数据库数据导出性能【需要实测已确定能力】
·加载文件服务器台数、IO性能、与8a集群网络带宽【迁移环境制约因素】
·8a集群节点的加载性能【IO性能和网络带宽综合考虑】
·增量业务的类型append only/IDU/拉链表/每次都全量 【决定增量追跑的方式,是否支持分批迁移】
·仓库设计上是否支持分层、是否支持数据加工幂等性 【决定迁移是否可以按业务或者层次进行纵向或横向的分批】
对于迁移时间窗口的预估,需按照如下的公式进行估算:
迁移整体时间 = TD导出时间 + GBase 8a加载时间
TD导出时间 = TD存储数据量(单位GB) /?? TD并行导出性能(GB/小时)
GBase 8a加载时间 = TD导出数据量(单位GB) / GBase 8a并行加载性能(GB/小时)
GBase 8a并行加载性能 = 加载机台数 * 1000MB/s * 1/2 *3600
数据迁移需要注意的点有:
TD存储数据量要转化为导出库外平面文件的数据量,因此要评估压缩比
TD并行导出的性能需要实测,并考虑导出时TD的负载情况
GBase 8a并行加载性能需要实测,推算时刻参考公式4
评估万兆带宽的使用率时要给出一定的冗余度,一般计算需要乘以1/2系数
整体时间窗口按照导出和加载串行方式评估,而不采用流水线方式评估,保证一定冗余度应对突发情况,而实际执行时可以按照pipeline方式设计迁移的实际执行方式。
以下是设计出的三种不同复杂度的全量数据迁移方案:
1)简单迁移方案
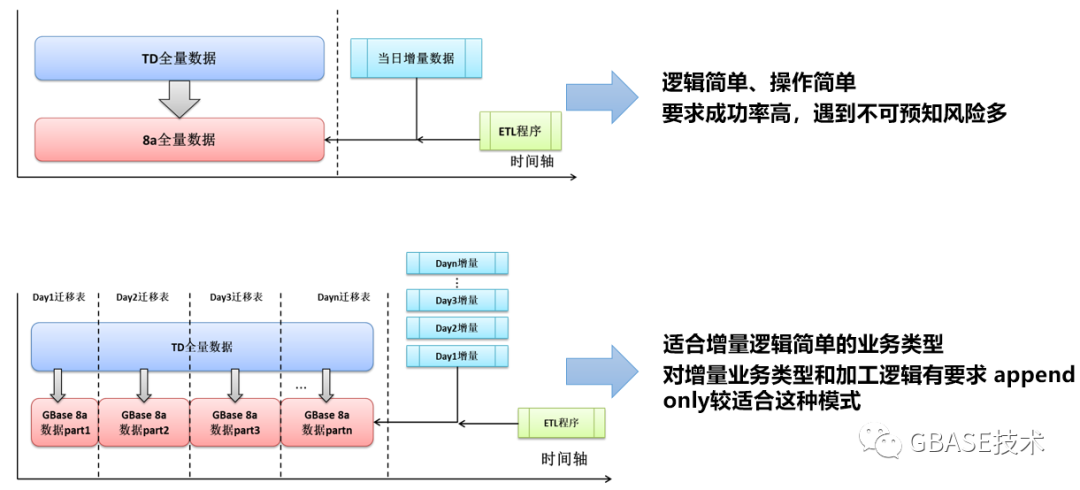
2)纵向按业务迁移方案
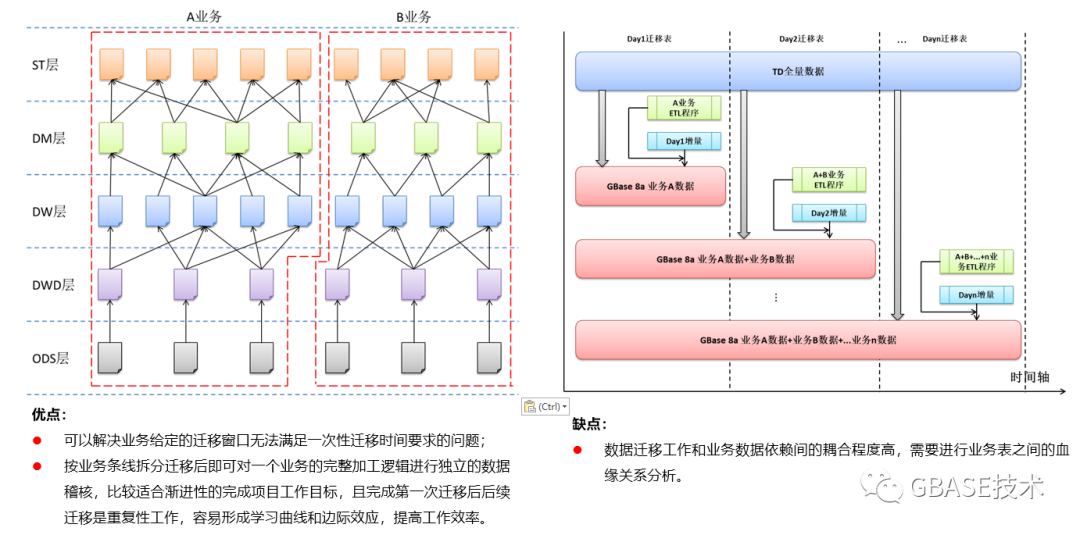
3)横向按仓库层次迁移方案

4)纵横混合方式迁移方案
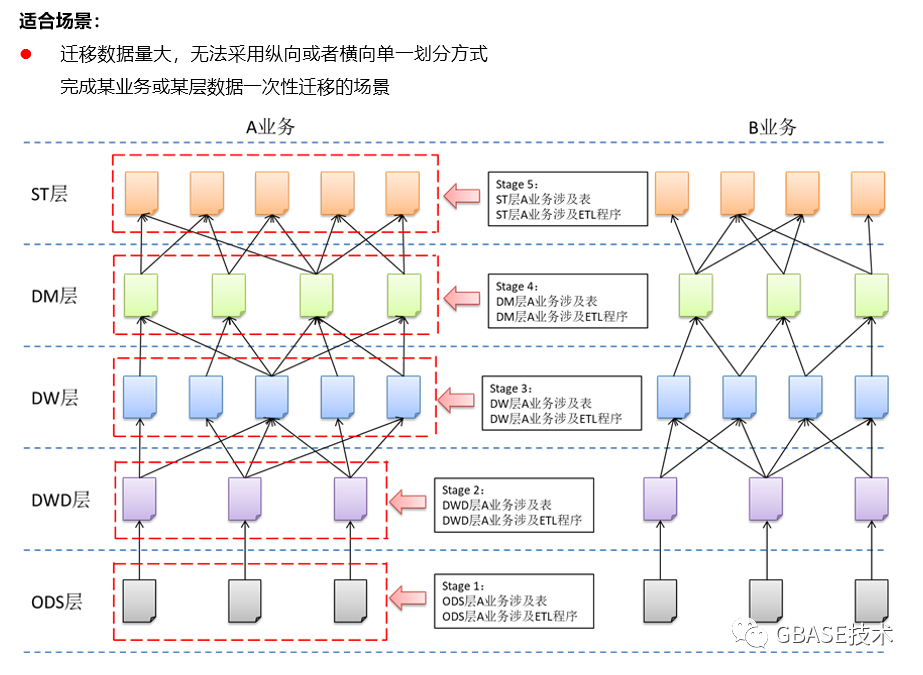
2、增量数据迁移
增量数据一般来源于上游,最常见的是时间戳的方式,通过时间戳来区分增量数据,每次同步时间戳迭代的数据,达到增量同步的目的。
时间戳方式(对各种数据库):它是一种基于快照比较的变化数据捕获方式,在源表上增加一个时间戳字段,系统中更新修改表数据的时候,同时修改时间戳字段的值。当进行增量数据抽取时,通过比较系统时间与时间戳字段的值来决定抽取哪些数据。
优点:同触发器方式一样,时间戳方式的性能也比较好,ETL 系统设计清晰,源数据抽取相对清楚简单,可以实现数据的递增加载。
缺点:时间戳维护需要由业务系统完成,对业务系统也有很大的侵入性(加入额外的时间戳字段),需要对业务系统的数据表的模型设计有一定的修改。
五、最后一步是数据准确性,数据稽核
数据稽核的最终目的是检验迁移的脚本和程序的正确性,采用的方法是通过比对原系统和迁移系统对相同数据的加工结果,通过结果是否一致来推断过程是否迁移的正确。
数据准确不等于完全相同,数据准确是指对比数据的结果在预期可接受的误差范围之内,在迁移项目中做到100%的运算结果完全相同有时是无法做到的,其可能原因包括:抽取前端数据的业务时间不同,不同数据库对计算结果的舍入和截取的规则不同,不同数据库对相同排序列值数据的排列顺序不一致,不同数据库对加载文件中的少量脏数据的处理机制不同等原因造成。
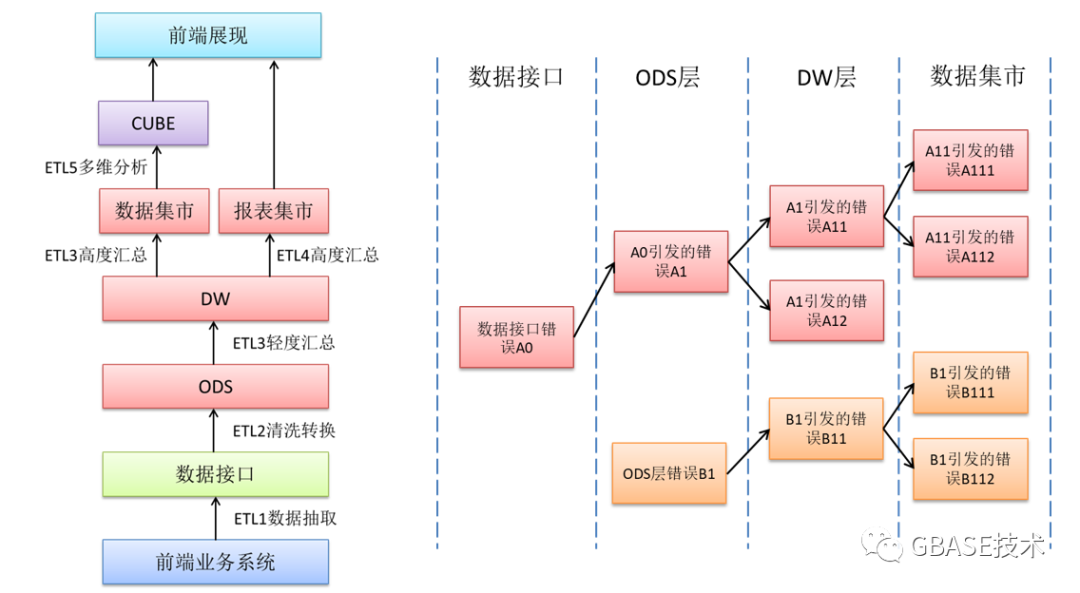
1、常用的稽核思路
自顶向下的稽核顺序:上层指标核对通过则可暂时不考虑底层的不一致问题
自底向上的错误排查顺序:出现不一致的上层指标需要利用血缘关系图从底层开始排查

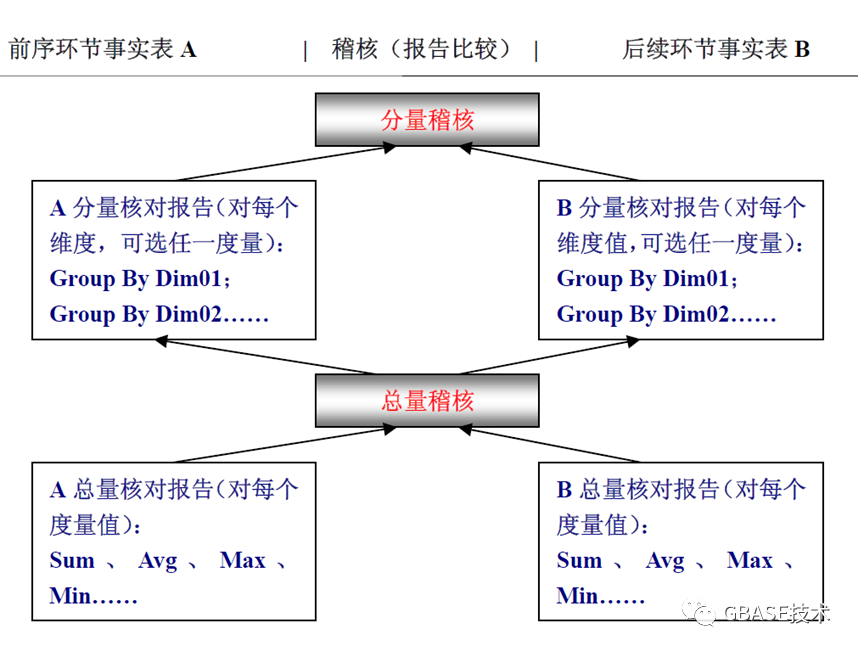
2、数据稽核常用方法
总量稽核:count值、sum值、avg值对比
分量稽核:对表内各维度进行group by后对这个维度的一个指标值进行count、sum、avg核对
错误对比:在发现不一致的表时,将对比的表拉到一个环境上进行详细分析,如进行minus运算,找出差数据再进一步分析
稽核报告:稽核报告是稽核工作输出物,对数据一致性问题进行记录和分析,对之前解决的问题进行追溯,形成数据稽核工作常见问题的知识体系
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- (2023|ICLR,文本反演,LDM,伪词)一个词描述一张图像:使用文本反演个性化文本到图像的生成
- 湖南大学-数据库系统-2017期末考试解析
- 如何修改element中el-popover + 时间选择器
- 小型洗衣机哪个牌子质量好?热门内衣洗衣机质量排名
- Ubuntu 20.04 prometheus prometheus-process-exporter
- 嵌入式开发之外部中断EXTI
- 动物免疫(羊驼免疫)-泰克生物
- OpenVAS简介
- Linux jinja2模板的使用
- RHCE——第五次作业