索引优化与设计
发布时间:2023年12月31日
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
索引使用
覆盖索引
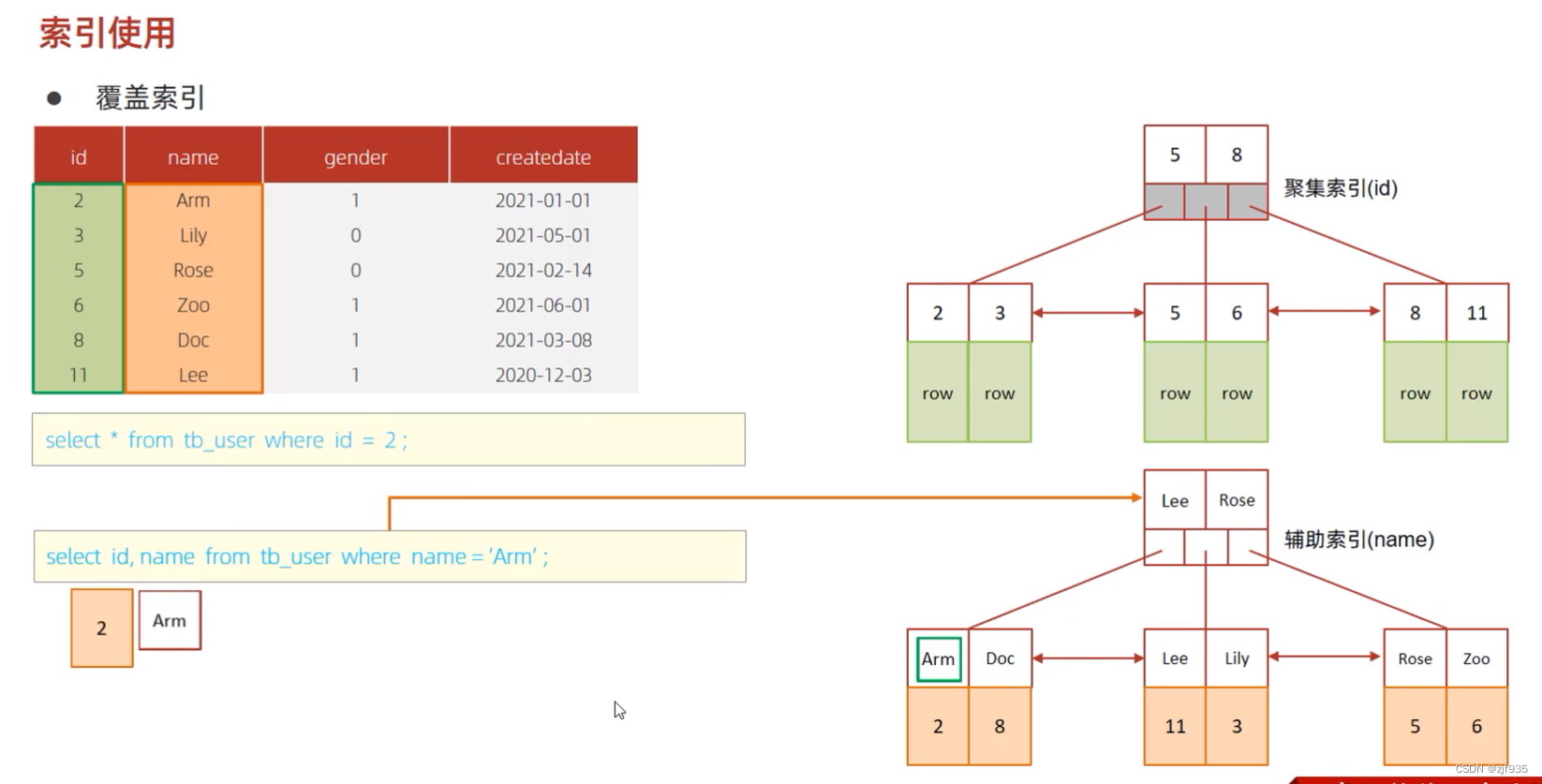
诸如此类查询,根据主键来查询以及 根据二级索引的字段查询,都是不需要回表的,能够直接给出结果
一次扫描即可完成
但是:
select id,name,gender from tb_user where name = 'Arm';
执行这条sql语句的时候,会怎么做呢?
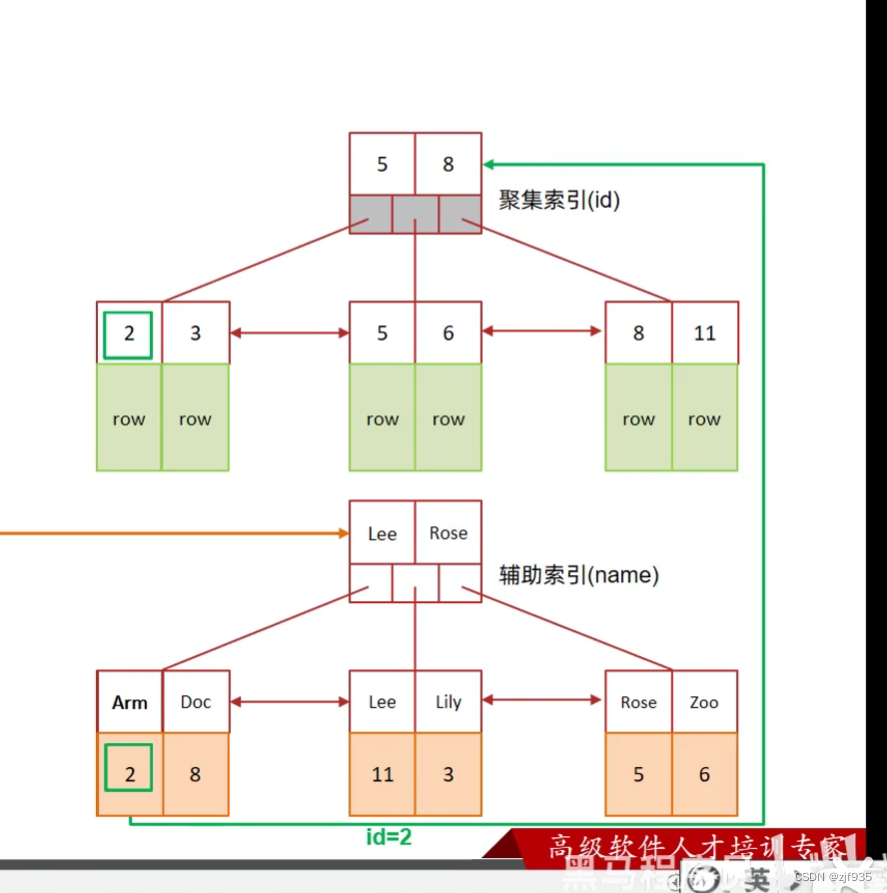
- 先根据name去二级索引去查询
- 查询之后发现还需要gender这个数据,二级索引里没有。
- 就会根据二级索引下的主键id值,去聚集索引当中根据id的值去查找数据
- 拿到了这一行的数据,再取出gender字段。
这种查询就叫做回表查询。
**因此,我们要避免在查询中使用:select ***
面试题
一张表,有四个字段(id, username, password, status),由于数据量大,需要对以下SQL语句进行优化,该如何进行才是最优方案:
select id, username, password from tb_user where username='itcast';
解:给username和password字段建立联合索引,则不需要回表查询,直接覆盖索引
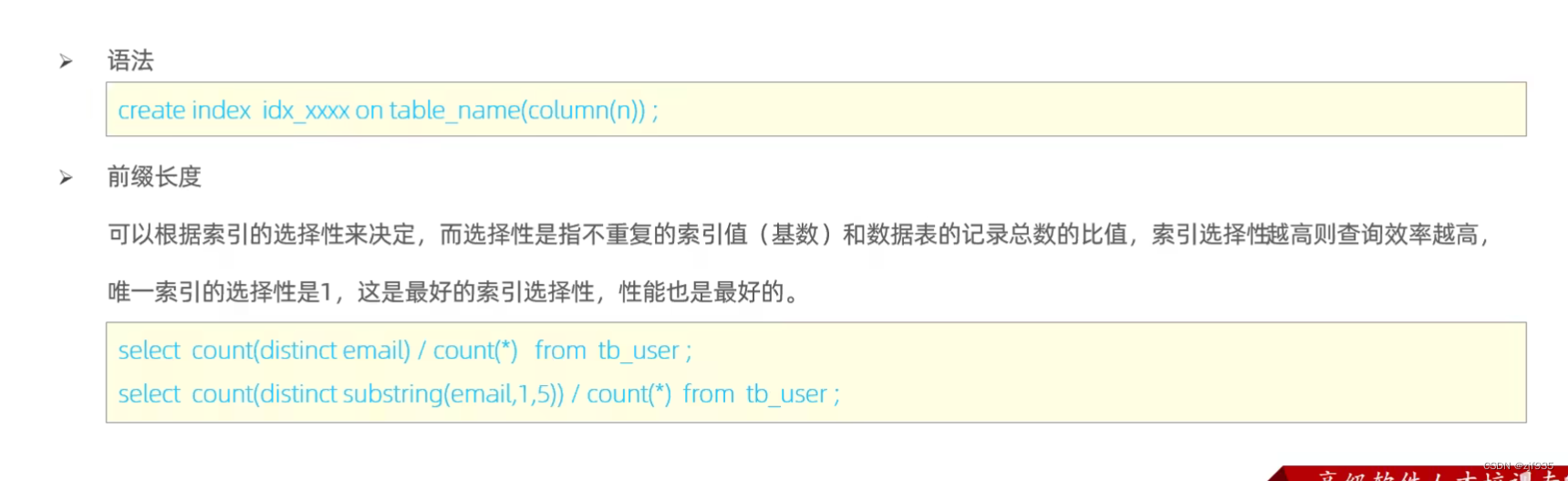
前缀索引
当字段类型为字符串(varchar, text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率,此时可以只降字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
比如我们email字段可以取前缀

语法:
create index idx_xxx on table (column(n))
其中n代表要拿索引的前n个字符作为前缀
索引创建过程:
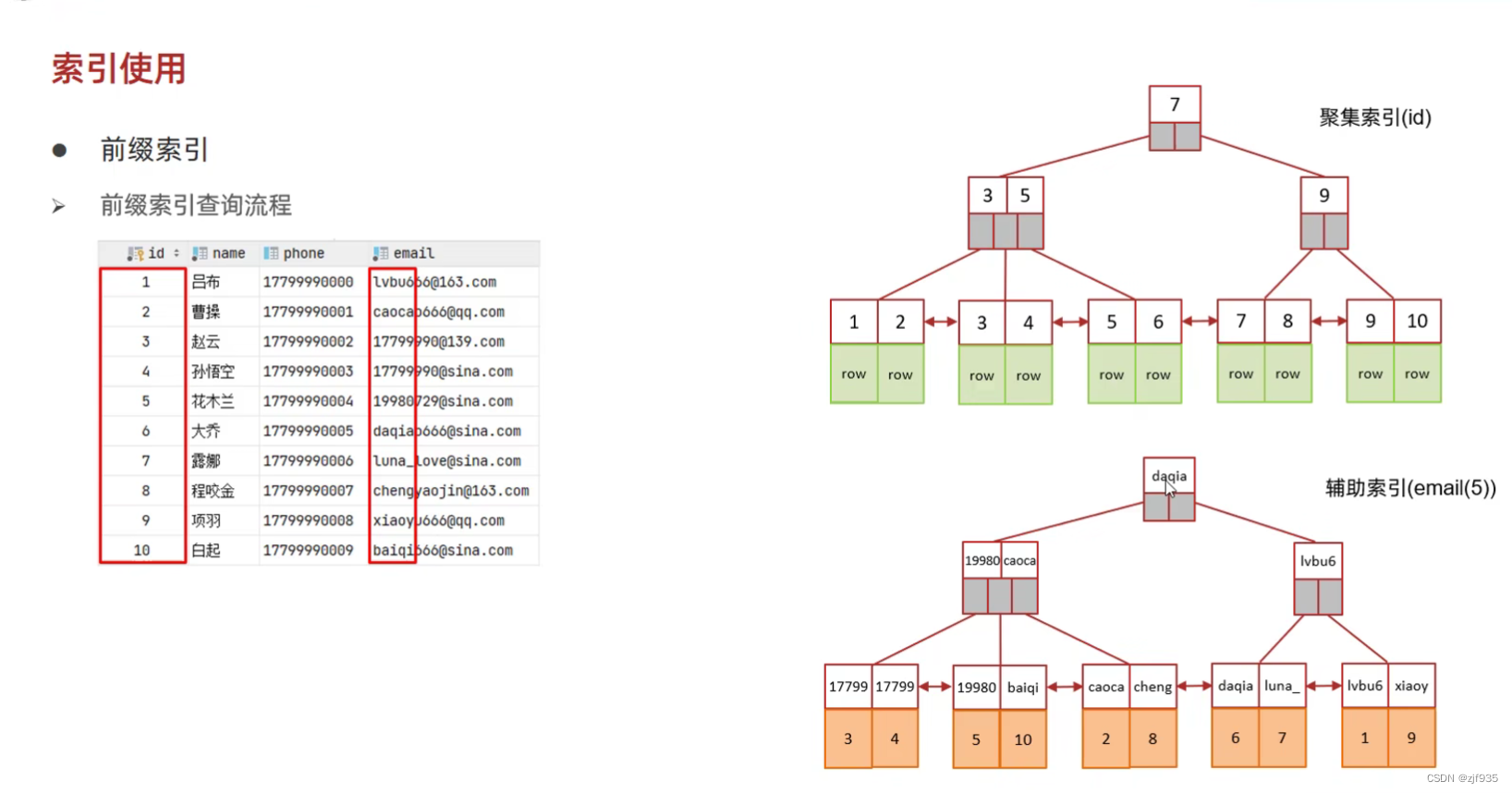
select * from tb_user where email='lvu666@163.com';
- 首先截取email中前五个字符去和辅助索引比对
- 找到叶子节点中的值
- 拿到id,去聚集索引去查询
- 获取到id值下的这行的数据之后,去比对email值是否相同
- 是,返回,不是再次查询。
联合索引与单列索引
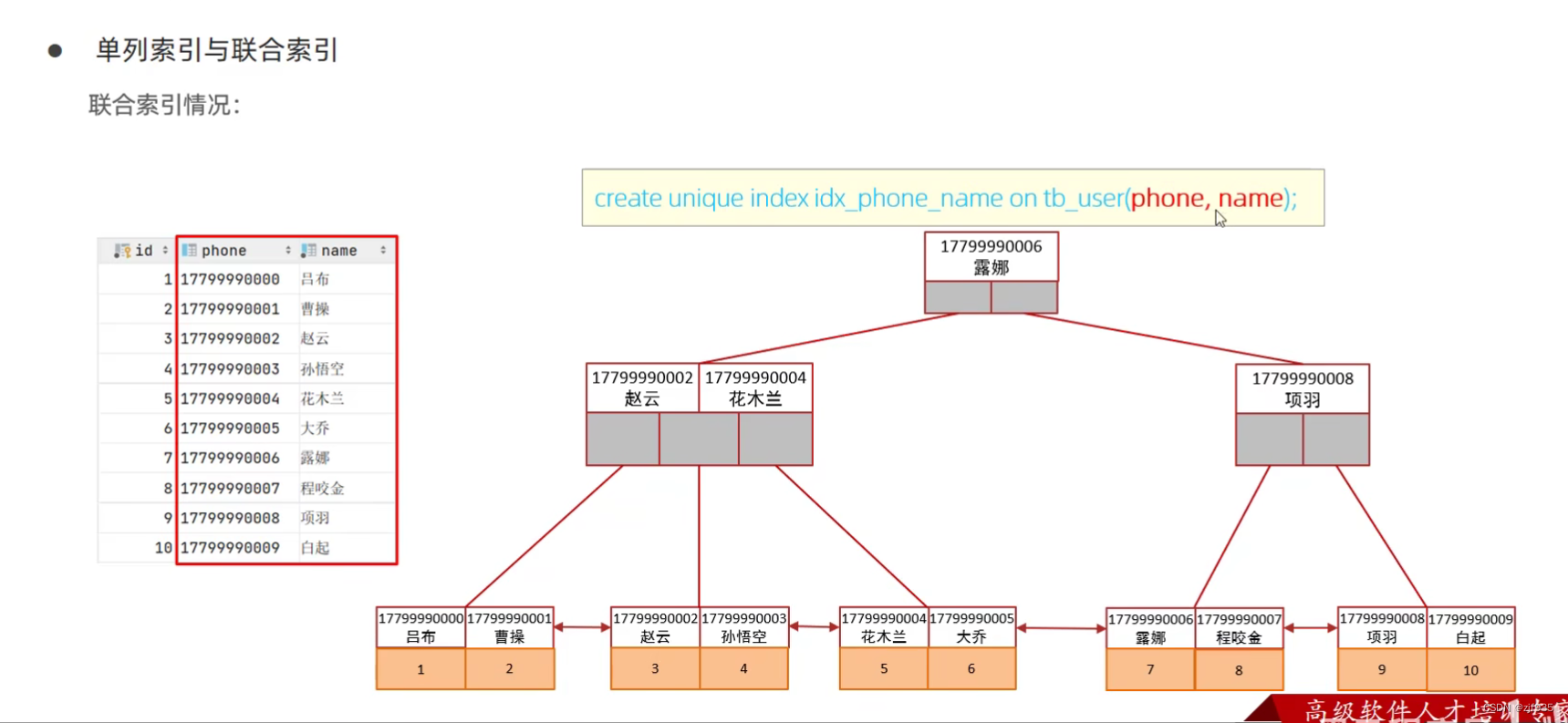
单列索引:即一个索引只包含单个列
联合索引:即一个索引包含了多个列
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
注意事项
- 多条件联合查询时,MySQL优化器会评估哪个字段的索引效率更高,会选择该索引完成本次查询
- 创建联合索引的时候注意顺序问题,如果是name在前面,那么name字段必须存在(最左前缀法则)。
设计原则
- 针对于数据量较大,且查询比较频繁的表建立索引
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
- 如果是字符串类型的字段,字段长度较长,可以针对于字段的特点,建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价就越大,会影响增删改的效率
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询
文章来源:https://blog.csdn.net/weixin_70496041/article/details/135310236
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!