什么是检索增强生成 (RAG)
什么是 RAG
RAG,即检索增强生成,是一种将预训练的大型语言模型的功能与外部数据源相结合的技术。这种方法将 GPT-3 或 GPT-4 等 LLM 的生成能力与专用数据搜索机制的精确性相结合,从而形成一个可以提供细微响应的系统。
本文更详细地探讨了检索增强生成,提供了一些实际示例和应用,以及一些资源来帮助您更多地了解 LLM。
为什么要使用 RAG 来改进 LLM
为了更好地展示 RAG 是什么以及该技术的工作原理,让我们考虑当今许多企业面临的场景。
想象一下,您是一家销售智能手机和笔记本电脑等设备的电子公司的高管。您想为您的公司创建一个客户支持聊天机器人,以回答与产品规格、故障排除、保修信息等相关的用户查询。
您想使用 GPT-3 或?GPT-4?等 LLM 的功能来为您的聊天机器人提供支持。
但是,大型语言模型具有以下局限性,导致客户体验效率低下:
缺乏具体信息
语言模型仅限于根据其训练数据提供通用答案。如果用户要询问特定于您销售的软件的问题,或者如果他们对如何执行深入的故障排除有疑问,传统的 LLM 可能无法提供准确的答案。
这是因为他们没有接受过特定于组织的数据培训。此外,这些模型的训练数据有一个截止日期,限制了它们提供最新响应的能力。
幻觉
LLM 可以“产生幻觉”,这意味着它们倾向于根据想象的事实自信地产生错误的反应。如果这些算法对用户的查询没有准确的答案,它们也可能提供偏离主题的响应,从而导致糟糕的客户体验。
一般性回应
语言模型通常提供不是针对特定上下文量身定制的通用响应。这可能是客户支持方案中的一个主要缺点,因为通常需要单个用户首选项来促进个性化的客户体验。
RAG 通过为您提供一种将 LLM 的一般知识库与访问特定信息(例如产品数据库和用户手册中的数据)集成的方法,有效地弥合了这些差距。这种方法允许根据组织的需求量身定制的高度准确和可靠的响应。
RAG是如何工作的
现在您已经了解了 RAG 是什么,让我们看一下设置此框架所涉及的步骤:
第 1 步:数据收集
您必须首先收集应用程序所需的所有数据。对于电子公司的客户支持聊天机器人,这可以包括用户手册、产品数据库和常见问题解答列表。
第 2 步:数据分块
数据分块是将数据分解为更小、更易于管理的部分的过程。例如,如果您有一本长达 100 页的用户手册,您可以将其分解为不同的部分,每个部分都可能回答不同的客户问题。
这样,每个数据块都集中在一个特定的主题上。当从源数据集中检索到一条信息时,它更有可能直接应用于用户的查询,因为我们避免包含整个文档中的不相关信息。
这也提高了效率,因为系统可以快速获取最相关的信息,而不是处理整个文档。
第 3 步:文档嵌入
现在,源数据已分解为更小的部分,需要将其转换为向量表示。这涉及将文本数据转换为嵌入,嵌入是捕获文本背后语义含义的数字表示形式。
简单来说,文档嵌入允许系统理解用户查询,并根据文本的含义将其与源数据集中的相关信息进行匹配,而不是简单的逐字比较。此方法可确保响应相关且与用户的查询保持一致。
第 4 步:处理用户查询
当用户查询进入系统时,还必须将其转换为嵌入或向量表示。文档和查询嵌入必须使用相同的模型,以确保两者之间的一致性。
将查询转换为嵌入后,系统会将查询嵌入与文档嵌入进行比较。它使用余弦相似度和欧几里得距离等度量来识别和检索嵌入与查询嵌入最相似的块。
这些区块被认为是与用户查询最相关的区块。
第 5 步:使用 LLM 生成响应
检索到的文本块以及初始用户查询将馈送到语言模型中。该算法将使用这些信息通过聊天界面生成对用户问题的连贯响应。
下面是一个简化的流程图,总结了 RAG 的工作原理:
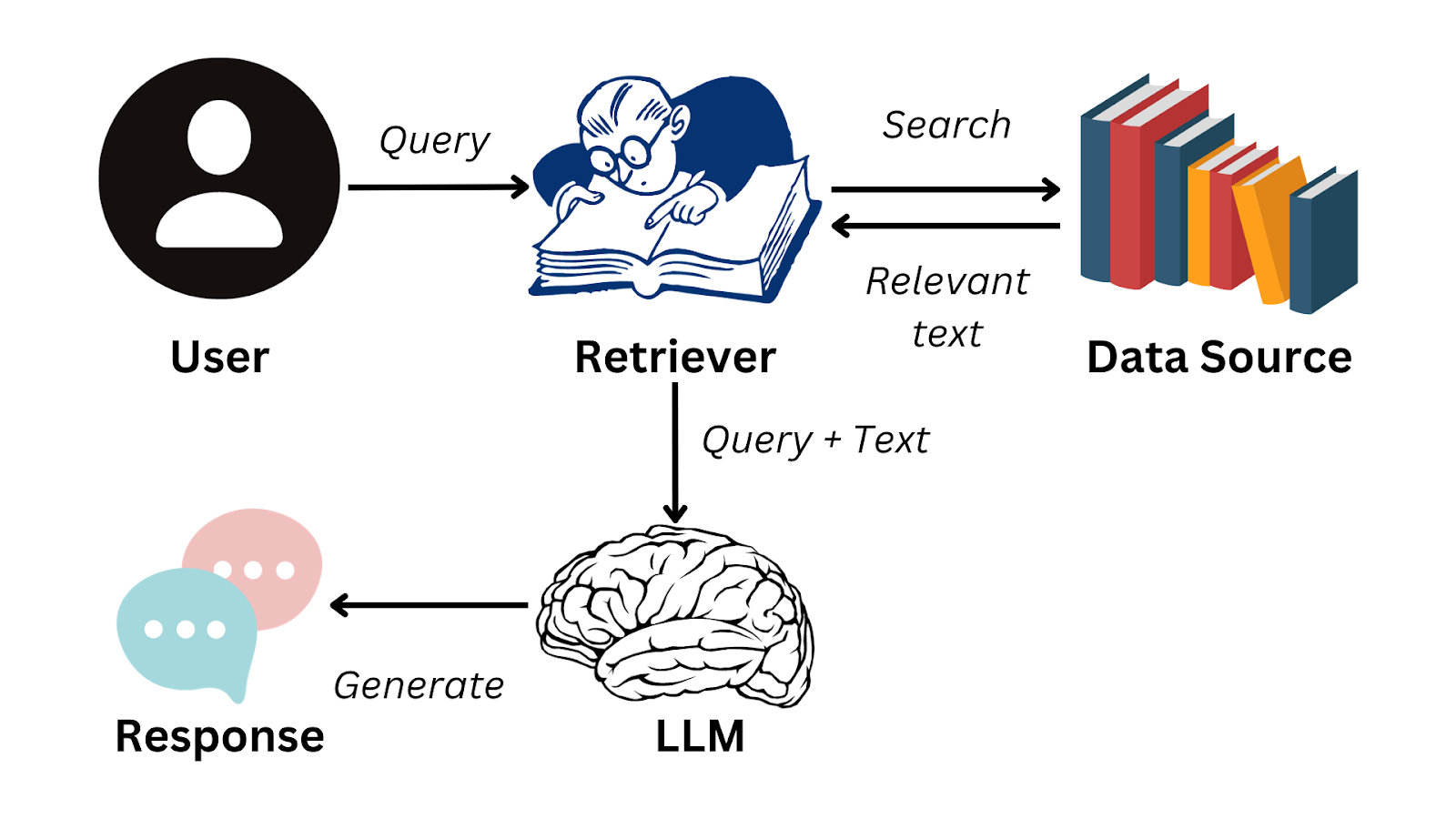 ?
?
要无缝完成使用 LLM 生成响应所需的步骤,您可以使用像 LlamaIndex 这样的数据框架。
该解决方案允许您通过有效管理从外部数据源到 GPT-3 等语言模型的信息流来开发自己的 LLM 应用程序。
RAG的实际应用
我们现在知道,RAG 允许 LLM 根据其训练数据之外的信息形成连贯的响应。像这样的系统具有各种业务用例,可以提高组织效率和用户体验。除了我们在本文前面看到的客户聊天机器人示例外,以下是 RAG 的一些实际应用:
文本摘要
 ?
?
RAG 可以使用来自外部来源的内容来生成准确的摘要,从而节省大量时间。例如,经理和高级管理人员是忙碌的人,他们没有时间筛选大量报告。
借助 RAG 驱动的应用程序,他们可以快速从文本数据中获取最关键的发现,并更有效地做出决策,而不必阅读冗长的文档。
个性化推荐
RAG 系统可用于分析客户数据,例如过去的购买和评论,以生成产品推荐。这将增加用户的整体体验,并最终为组织带来更多收入。
例如,RAG 应用程序可用于根据用户的观看历史和评级在流媒体平台上推荐更好的电影。它们还可用于分析电子商务平台上的书面评论。
由于 LLM 擅长理解文本数据背后的语义,因此 RAG 系统可以为用户提供比传统推荐系统更细致入微的个性化建议。
商业智能
组织通常通过密切关注竞争对手的行为和分析市场趋势来做出业务决策。这是通过仔细分析业务报告、财务报表和市场研究文件中的数据来完成的。
借助 RAG 应用程序,组织不再需要手动分析和识别这些文档中的趋势。相反,可以使用法学硕士来有效地获得有意义的见解并改进市场研究过程。
实施RAG系统的挑战和最佳实践
虽然 RAG 应用程序使我们能够弥合信息检索和自然语言处理之间的差距,但它们的实现带来了一些独特的挑战。在本节中,我们将研究构建 RAG 应用程序时面临的复杂性,并讨论如何缓解这些复杂性。
集成复杂性
将检索系统与 LLM 集成可能很困难。当存在多个不同格式的外部数据源时,这种复杂性会增加。输入到 RAG 系统的数据必须一致,并且生成的嵌入需要在所有数据源中保持一致。
为了克服这一挑战,可以设计单独的模块来独立处理不同的数据源。然后,可以对每个模块中的数据进行预处理以确保均匀性,并且可以使用标准化模型来确保嵌入具有一致的格式。
可扩展性
随着数据量的增加,保持 RAG 系统的效率变得越来越具有挑战性。需要执行许多复杂的操作,例如生成嵌入、比较不同文本片段之间的含义以及实时检索数据。
这些任务是计算密集型的,并且随着源数据大小的增加,可能会降低系统速度。
为了应对这一挑战,您可以在不同的服务器之间分配计算负载,并投资于强大的硬件基础设施。为了缩短响应时间,缓存经常被询问的查询也可能是有益的。
矢量数据库的实施还可以缓解 RAG 系统中的可扩展性挑战。这些数据库允许您轻松处理嵌入,并可以快速检索与每个查询最接近的向量。
数据质量
RAG 系统的有效性很大程度上取决于输入其中的数据的质量。如果应用程序访问的源内容较差,则生成的响应将不准确。
组织必须投资于勤奋的内容策划和微调过程。有必要细化数据源以提高其质量。对于商业应用,在RAG系统中使用数据集之前,让主题专家审查并填补任何信息空白可能是有益的。
最后的思考
RAG 是目前最知名的技术,它利用了 LLM 的语言功能以及专门的数据库。这些系统解决了使用语言模型时遇到的一些最紧迫的挑战,并在自然语言处理领域提出了创新的解决方案。
然而,与任何其他技术一样,RAG 应用程序也有其局限性,尤其是它们对输入数据质量的依赖。为了充分利用 RAG 系统,在此过程中包括人工监督至关重要。
对数据源的细致管理以及专业知识对于确保这些解决方案的可靠性至关重要。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 设置弹窗随鼠标位置移动
- 02 SQL更新语句是如何执行的
- 一文读懂半导体晶圆形貌厚度测量的意义与挑战
- c++ 访问字符串的底层字符数组
- python+selenium如何做接口自动化测试?
- clickhouse 优化实践,万级别QPS数据毫秒写入和亿级别数据秒级返回 | 京东云技术团队
- HCIP —— BGP 基础实验
- arduino声波测距
- 代码随想录算法训练营day1|704.二分查找、27.移除元素
- 关于多跳通信和单跳通信两种方式有什么区别