使用LLaMA-Factory微调ChatGLM3
发布时间:2023年12月25日
1、创建虚拟环境
略
2、部署LLaMA-Factory
(1)下载LLaMA-Factory
https://github.com/hiyouga/LLaMA-Factory
(2)安装依赖
pip3 install -r requirements.txt
(3)启动LLaMA-Factory的web页面
CUDA_VISIBLE_DEVICES=0 python src/train_web.py
得到如下页面:

3、ChatGLM3模型微调
设置如下参数,点击开始即可:
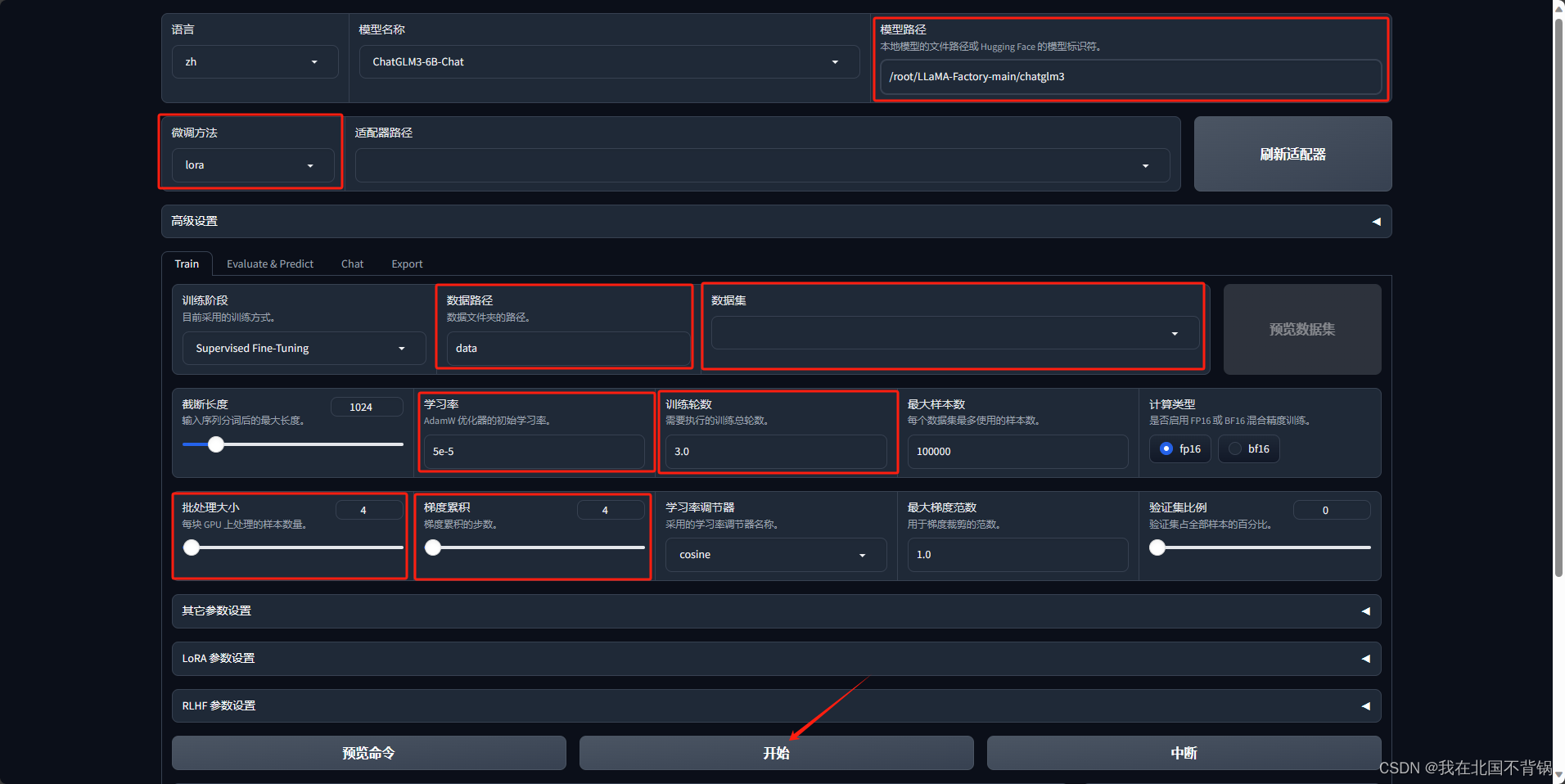
点击“预览命令”,可以看到要执行的python脚本,如下所示:
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--do_train \
--model_name_or_path /root/LLaMA-Factory-main/chatglm3\
--dataset alpaca_gpt4_zh \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
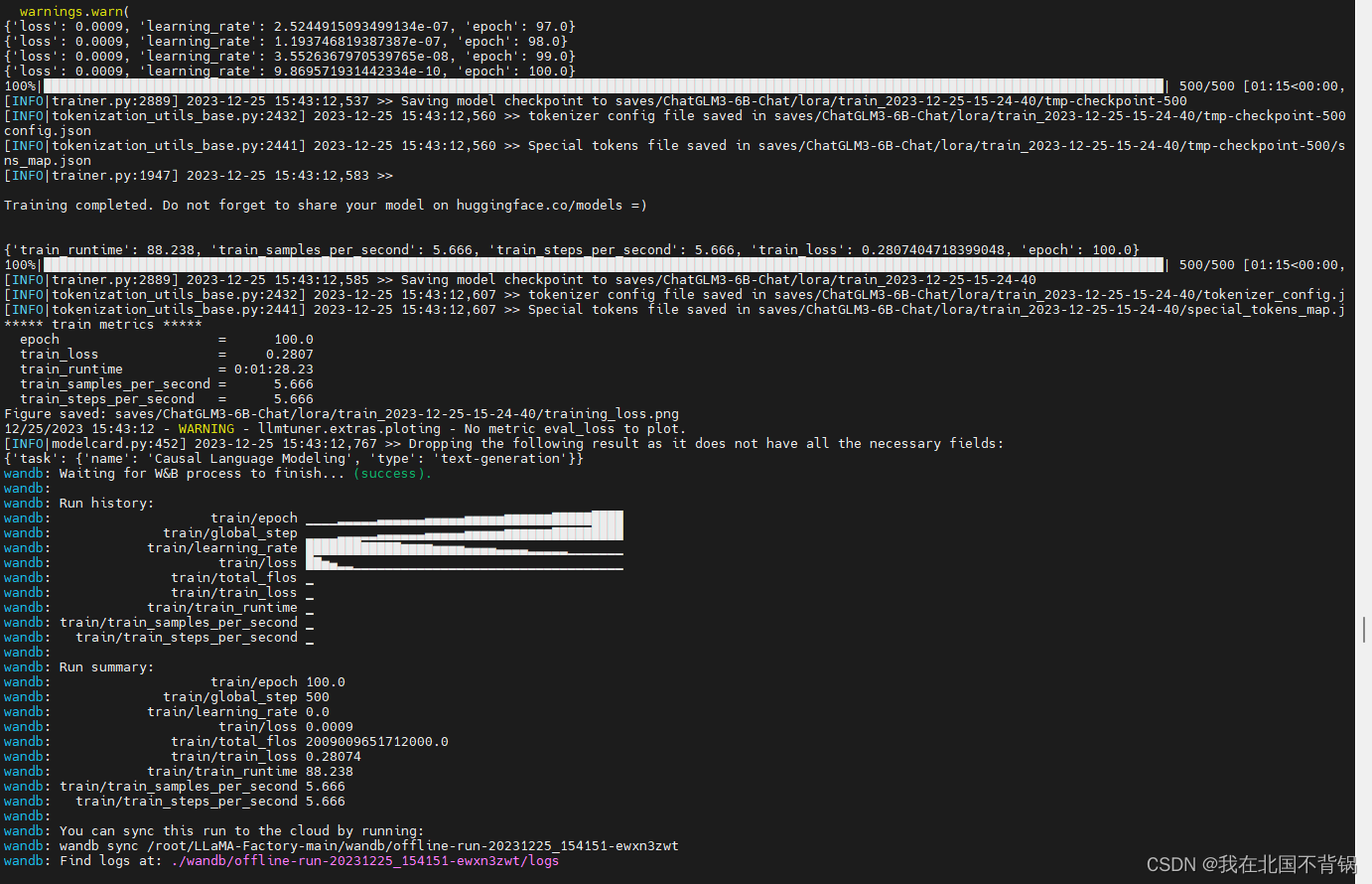
web页面和后台都会显示日志信息
4、推理测试
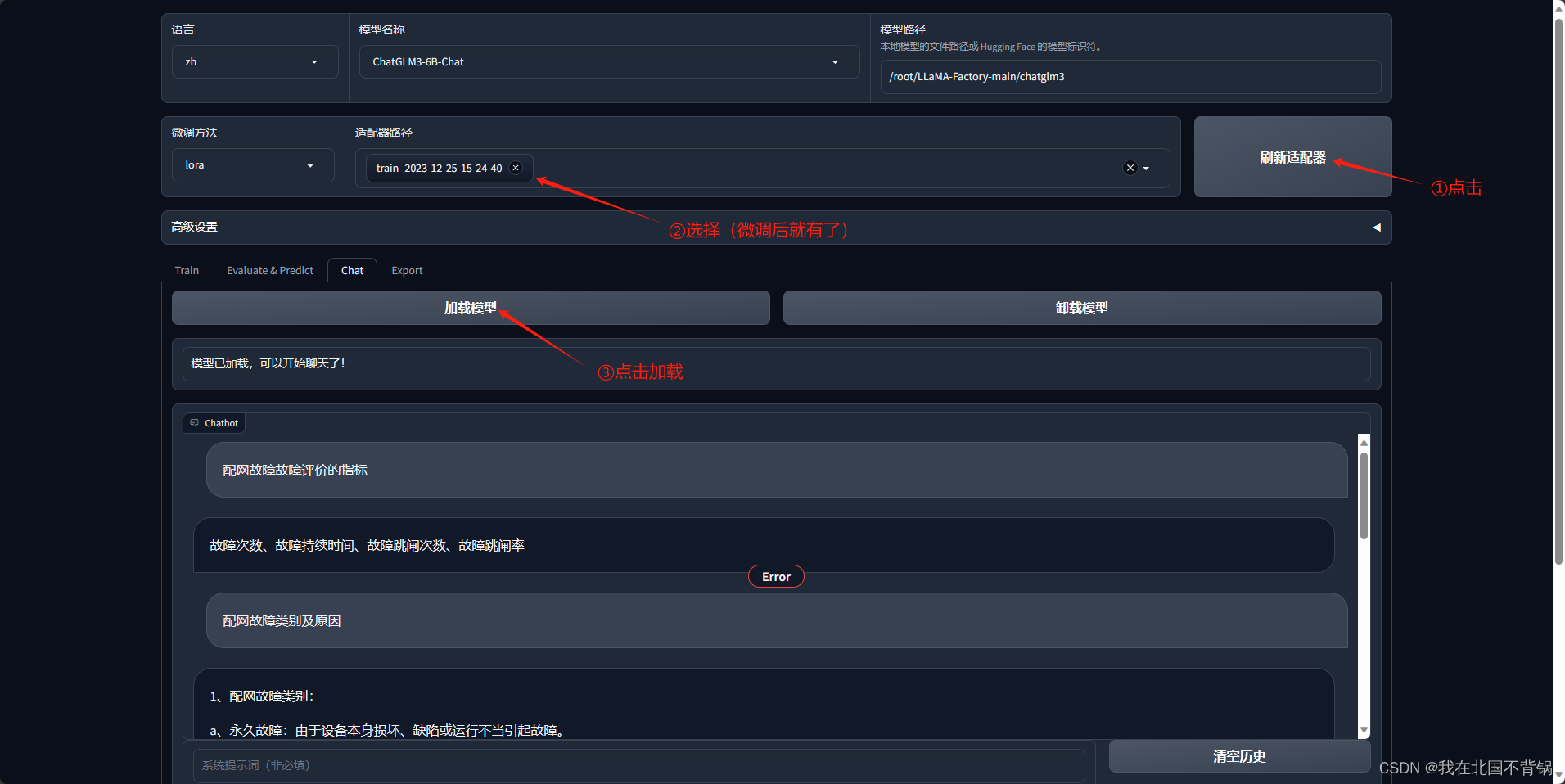
输入微调数据中的问题,回答贴合数据集,微调成功。
5、模型合并导出
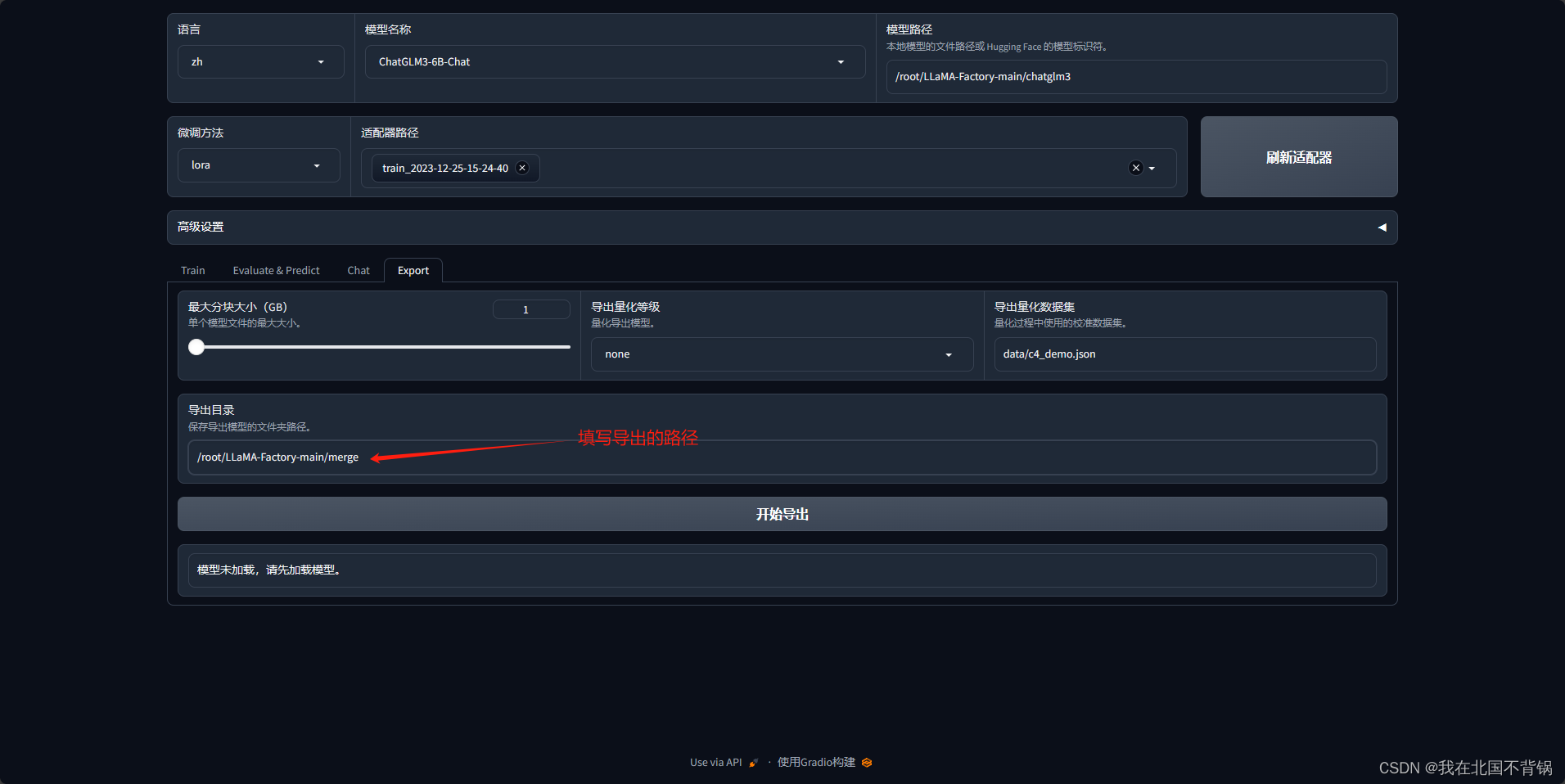
待执行完,即可看到/root/LLaMA-Factory-main/merge路径下有了合并的模型了。
6、使用官方项目运行微调合并后的模型
可以看到也是没问题的。

7、过程中的问题
(1)合并后的模型无法加载,报错信息如下:
AttributeError: property 'eos_token' of 'ChatGLMTokenizer' object has no setter
解决方法:将源模型中除了bin文件和pytorch_model.bin.index.json 以外的文件全部复制到导出目录中覆盖。
(2)模型微调时使用自己的数据集
该项目目前支持两种格式的数据集:alpaca 和 sharegpt,我是用的是 alpaca 格式,数据集按照以下方式组织:
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]

将数据梳理好之后上传到data目录下。
接下来需要修改data/dataset_info.json,对于上述格式的数据,dataset_info.json 中的 columns 格式应为:
"数据集名称": {
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
我这里写的是:
"chatglm3": {
"file_name": "chatglm3_train.json",
"file_sha1": "e655af3db557a4197f7b0cf92e1986b08fae6311",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
文章来源:https://blog.csdn.net/weixin_44455388/article/details/135202632
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 操作系统--磁盘存储器的管理
- 【一】vue3的helloworld项目
- 微信小程序 引导地址授权 获取位置信息 uniapp
- 基于JavaWeb实验室预约管理系统(源码+数据库+文档)
- java设计模式-工厂方法模式
- 传感器原理与应用复习--磁电式与霍尔传感器
- Verilog 和 System Verilog 的区别
- Java电子招投标采购系统源码-适合于招标代理、政府采购、企业采购、等业务的企业
- npm 报错 request to https://registry.cnpmjs.org/vue failed, reason:
- 5_js数组常用函数与let与const关键字