西北工业大学计算机组成原理实验报告——verilog后两次
在单周期CPU的基础上开发实现流水线CPU
说明:
1. 该PDF带有大纲功能,点击大纲中的对应标题,可以快速跳转。
2. 目录层级为:
一、一级标题
(二)二级标题
(3)三级标题
4.四级标题
e)五级标题
3. 波形分析见实验过程中对应实现的末尾。
-
实验要求:
- 掌握CPU流水线执行指令的过程和原理;
- 对CPU流水线的各种冒险问题和解决方法有深入的了解;
- 学习使用Verilog HDL语言实现流水线处理器,并进行调试,使其通过仿真;
- 提高自己设计和解决更复杂硬件系统的能力;
- 培养对硬件设计的兴趣。
-
实验过程:
(一)不考虑冒险的流水线搭建
把单周期的CPU升级为流水线的CPU,最重要的是使得各个阶段互相独立,互不影响。由于触发器仅仅在时钟上升沿的时候写入数据,在其他时刻数据均不发生变化,所以可以通过4级流水线寄存器把原来的数据通路分为5级
四级流水线寄存器的名字以上一级以及下一级的名称来命名:
首先列表分析各个寄存器所需要保存的数据:
| 流水线寄存器 | 保存数据 | 保存控制信号 |
| if_id | instruction, | 未译码,无 |
| id_exe | pc_add_4, | op(操作码), |
| exe_mem | pc_add_4, | mem_write, |
| mem_wb | pc_add_4, | reg_write, |
然后使用verilog对四个流水线寄存器进行实现。
为了增强可读性,我单独定义了4个流水线寄存器,每一个流水线寄存器中的所有信号全部列出。
eg.对于if_id流水线寄存器如下:
| module if_id( ? ? input clock, input reset, ? ? input write_enable, ? ? output reg [31:0] instruction, ? ? output reg [31:0] pc_add_4, ? ? input [31:0] nxt_instruction, ? ? input [31:0] nxt_pc_add_4 ); always @(posedge clock) begin ? ? if (!reset) ? ? ? ? begin ? ? ? ? ? ? instruction <= 32'b0; ? ? ? ? ? ? pc_add_4 <= 32'b0; ? ? ? ? end ? ? else if(write_enable) ? ? ? ? begin ? ? ? ? ? ? instruction <= nxt_instruction; ? ? ? ? ? ? pc_add_4 <= nxt_pc_add_4; ? ? ? ? end end endmodule |
其他寄存器采用类似的方法进行定义。
这一种定义的原因:
①可读性更好,可以通过对应名称确定流水线寄存器中这一项的作用,而不必去计算每一个功能对应的位。
②如果在后面需要增加新的控制信号,那么可以直接增加,旧有的内容不需要改变,便于进行增量式设计。
对于顶层模块,参考下图,对元器件进行连接。
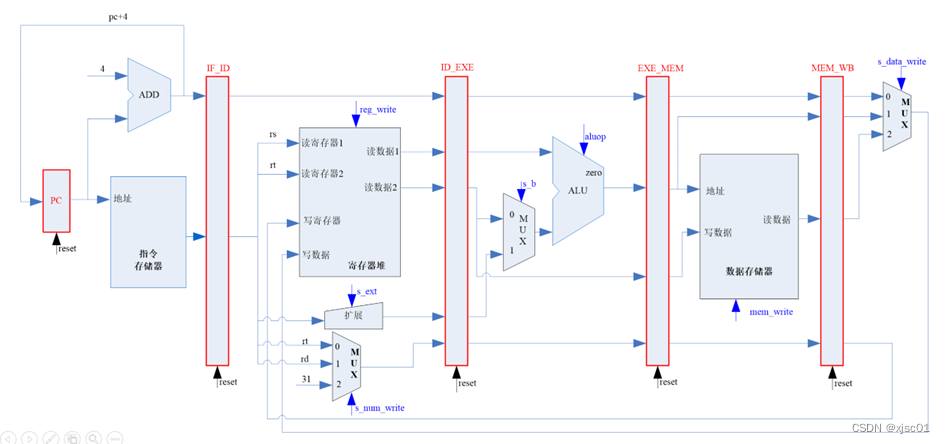
在顶层模块定义线网,按照如下格式:
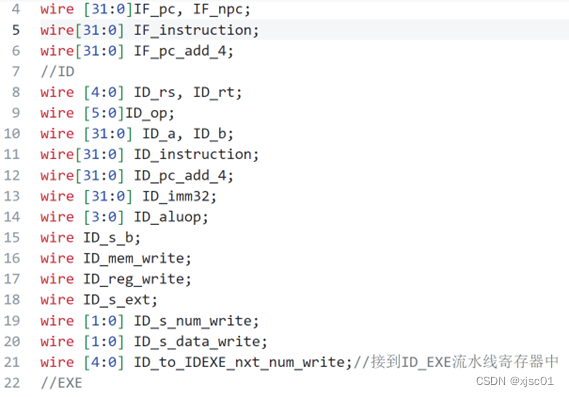
这样可以通过前面的标识符表示区分这一个线网究竟是哪一个阶段的,使得可读性更好。
对于if_id流水线寄存器的连线如下:
| if_id IF_ID( //out ? ? .clock(clock), ? ? .reset(reset), ? ? .write_enable(IF_ID_write_enable),//表示是否对寄存器进行写 ? ? .instruction(ID_instruction),? //表示把寄存器的instruction与ID级的相连 ? ? .pc_add_4(ID_pc_add_4), //in ?这一个寄存器的下一个指令由IF给出 .nxt_instruction(IF_instruction),//该D触发器的D端的数据。 //当下一个时钟上升沿到来的时候,使用这些值来更新原有的值。 ? ? .nxt_pc_add_4(IF_pc_add_4) ); |
其余结构的连线详细见平台提交的代码。
对于多路选择器,由于在数据通路中使用的频次很高,所以使用更为简单的条件运算符进行实现:
| .nxt_num_write( ? ? ? (ID_s_num_write == 2'b00) ? ID_instruction[20:16] : ? ? ? (ID_s_num_write == 2'b01) ? ID_instruction[15:11] : ? ? ? (ID_s_num_write == 2'b10) ? 31: ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 31 ? ? ? ), |
波形分析:
为了便于展现流水线CPU各个指令的传输,采用不同阶段的OP字段进行表示。
汇编代码:
| addi ? $2, $zero, 1 addiu $3, $zero, 1 andi ? $4, $zero, 1 ori ?? $5, $zero, 1 addi ? $6, $zero, 1 addiu $7, $zero, 1 |
得到的波形:

在波形中可以看到,一条指令随着时间的流逝,在流水级中不断向后方传递,每当到达一个新的周期,就会有新的指令被取入,这大大加快了指令的执行。
(二)处理流水线中的数据冒险
(1)数据冒险总体概述
在流水线中,指令被分成五个阶段(IF,ID,EXE,MEM,WB),每个阶段都有独立的硬件执行,所以指令的不同阶段可以并行执行。
但是流水线中会遇到一些问题,即后续指令需要使用前一个指令的执行结果,而前一个指令还没有写回的时候,会产生数据冒险。
在这种情况下,如果不进行干预,后续指令无法获得前一个指令的正确结果,导致计算错误或结果不确定。
进行干预有多种选择,如果使用阻塞,那么执行的结果的正确性可以保证,但是会严重影响流水线的速度,所以要尽可能采用旁路机制,以实现对于数据冒险的处理,如果由于某些情况无法通过旁路处理,则还要进行阻塞。
(2)产生数据冒险的情况分析
在这里假设前面的指令的需要写入的寄存器单元的编号与后面的指令需要的编号相同:
首先,画出流水线的时空图,对于可能出现的数据冒险进行分析:
| TIME | CC1 | CC2 | CC3 | CC4 | CC5 | CC6 | CC7 | CC8 | CC9 | |
| 前面的指令 | IF | ID | EX | MEM | WB |
|
|
|
| |
| 后面的指令 | 一阶 |
| IF | ID | EX | MEM | WB |
|
|
|
| 二阶 |
|
| IF | ID | EX | MEM | WB |
|
| |
| 三阶 |
|
|
| IF | ID | EX | MEM | WB |
| |
| 四阶 |
|
|
|
| IF | ID | EX | MEM | WB | |
在MIPS的指令集体系架构中,数据写回寄存器全部是在WB阶段发生的,现在对上图进行分析:
- 一阶指令:读取寄存器数据在CC3进行,但是前面的指令在CC5才可以写回数据,所以会产生冒险。
- 二阶指令:读取寄存器数据在CC4进行,但是前面的指令在CC5才可以写回数据,所以会产生冒险。
- 三阶指令:这里需要进行具体分析,如果寄存器支持先写后读,那么在同一个周期中,三阶指令的ID可以读取到前一条指令的WB写回的数据。
但是在本次实验中,规定所有的写操作全部是在时钟周期的上升沿进行的,所以在CC5这一个周期仍然会发生冒险。 - 四阶指令:对于四阶指令,读取数据在CC6,已经在前面的指令的WB阶段之后,所以并不会发生冒险。
从上所述:前三阶的指令会发生数据冒险。第四阶以及之后的指令不会发生数据冒险。
(3)解决数据冒险详细分析
1.对于后面的指令为一阶指令:
进行分类讨论:
a)前面的指令为EXE型
如表:
| TIME | CC1 | CC2 | CC3 | CC4 | CC5 | CC6 | |
| 前面的指令(A) | IF | ID | EXE | MEM | WB |
| |
| 后面的指令(B) | 一阶 |
| IF | ID | EXE | MEM | WB |
在下面记前面的指令为A,后面的二阶指令为B
在表中可以看到,A在CC3阶段得到运算结果,在CC4可以从EXE/MEM流水线寄存器中读出A写入寄存器堆的数据。
B指令在CC4需要数据进行运算,所以可以采用MEM-EXE旁路策略。
b)前面的指令为MEM型
如表:
| TIME | CC1 | CC2 | CC3 | CC4 | CC5 | |
| 前面的指令(A) | IF | ID | EXE | MEM | WB | |
| 后面的指令(B) | 一阶 |
| IF | ID | EXE | MEM |
在表中可以看到,A在CC4阶段得到运算结果,在CC5可以从MEM/WB流水线寄存器中读出A写入寄存器堆的数据。
这一个时候,对于B指令进行细分。
- 若B在EXE阶段需要得到数据,那么必须阻塞一个周期,同时进行WB-EXE旁路。
- 若B在MEM阶段需要得到数据(sw指令),那么可以不进行阻塞,直接进行WB-MEM旁路策略。
2.对于后面的指令为二阶指令:
| TIME | CC1 | CC2 | CC3 | CC4 | CC5 | CC6 | CC7 | |
| 前面的指令(A) | IF | ID | EXE | MEM | WB |
|
| |
| 后面指令(B) | 二阶 |
|
| IF | ID | EXE | MEM | WB |
在下面记前面的指令为A,后面的二阶指令为B
- 如果A是EXE型,那么结果在CC3的末尾产生,在CC4以及CC5周期均可以提前得到A写回的值。
- 如果A是MEM型,那么结果在CC4的末尾产生,在CC5周期可以提前得到A写回的值。
为了简单起见,对于A指令,不论是EXE型还是MEM型,都可以从A的WB级把A需要更改的寄存器的值旁路到B的EXE阶段,使得在B执行的时候使用的值是A运算出来的最新的结果,即WB-EXE旁路。
3. 对于后面的指令为三阶指令:
| TIME | CC1 | CC2 | CC3 | CC4 | CC5 | CC6 | CC7 | CC8 | |
| 前面的指令(A) | IF | ID | EXE | MEM | WB |
|
|
| |
| 后面的指令(B) | 三阶 |
|
| IF | ID | EXE | MEM | WB | |
在下面记前面的指令为A,后面的二阶指令为B
在图中可以看到,无论A是EXE型还是MEM型指令,在CC5的WB阶段可以得到A指令写入寄存器的值。
对于B,无法在CC6以及CC7阶段进行旁路,因为在CC6和CC7阶段,A的相关信息已经不在流水线中了,所以无法完成旁路。
但是在CC5阶段可以进行旁路。可以把A的MEM/WB流水线寄存器中的写入寄存器堆的数据旁路到B的ID级流水线寄存器,这样,后面的指令就可以使用A指令运算得到的值了,即使用WB-ID旁路策略。
(4)解决数据冒险总体分析
根据上一个步骤,现在把解决数据冒险进行以下总体概括:
1. 总体方案:
| 前面指令 | EXE | MEM | ||||
| 后面指令 | 一阶 | 二阶 | 三阶 | 一阶 | 二阶 | 三阶 |
| EXE | MEM-EXE | WB-EXE | WB-ID | 等待一个周期 | WB-EXE | WB-ID |
| MEM | WB-MEM | |||||
2. 多种冒险冲突分析:
为了分析方便,给指令起以下名字:
| NO.1 | A |
| NO.2 | B |
| NO.3 | C |
| NO.4 | D |
这四条指令顺序执行。
- 对于同一个寄存器单元,如果D指令与C构成一阶冒险,那么就必须采用一阶冒险的旁路策略。即使D与B或者A存在冒险,也无需考虑,因为C指令的值是最新的,要把最新的值进行旁路。
- 同理,对于同一个寄存器单元,如果D指令与B构成二阶冒险,那么无需考虑指令D与A的关系,直接按照二阶冒险进行处理。
综上所述,冒险的处理有着优先级,即先考虑一阶冒险,然后考虑二阶冒险,最后考虑三阶冒险。
(5) WB2EXE以及MEM2EXE的处理
WB2EXE以及MEM2EXE是可以处理一阶(第一条指令为EXE型)以及二阶的冒险
根据之前的分析,
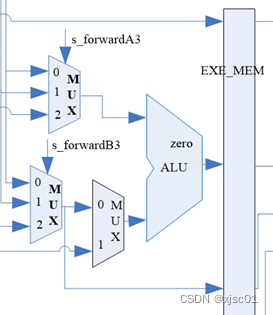
如图,s_forwardA3或者s_forwardA4选择0,表示MEM-EXE旁路;选择1表示WB旁路;选择2表示不进行旁路,直接使用ID/EXE流水线寄存器中的值。
根据“(4)解决数据冒险总体分析”中的分析,如果具有一阶的冒险,那么直接进行MEM-EXE旁路,如果具有与二阶的冒险,那么进行WB-MEM旁路。
判断是否冒险我认为有三个要素:
- 后面的指令需要的寄存器编号与前面的指令的目的寄存器号(可能为rt或者rd,在ID阶段之后可以确定)一致;
- 前面的指令改写的寄存器号不为0;
- 前面的指令写寄存器信号有效。
我在实际的代码中,通过if-else判断来决定优先级。
| always @(*) begin?? //对于A3的值进行控制 ? ? if(MEM_reg_write == 1 && MEM_num_write != 0//判断我上文中提到的三个条件 ? ? && MEM_num_write == EXE_rs)//如果产生一阶的数据冒险 ? ? ? ? s_forwardA3 = 0; ? ? else if(WB_reg_write == 1 && WB_num_write != 0 ? ? && WB_num_write == EXE_rs) //如果产生二阶的数据冒险 ? ? ? ? s_forwardA3 = 1; ? ? else ? ? ? ? s_forwardA3 = 2;//不产生冒险 end always @(*) begin?? //对于B3的值进行控制 ? ? if(MEM_reg_write == 1 && MEM_num_write != 0//判断我上文中提到的三个条件 ? ? && MEM_num_write == EXE_rt) //如果产生一阶的数据冒险 ? ? ? ? s_forwardB3 = 0; ? ? else if(WB_reg_write == 1&& WB_num_write != 0 ? ? && WB_num_write == EXE_rt) //如果产生二阶的数据冒险 ? ? ? ? s_forwardB3 = 1; ? ? else ? ? ? ? s_forwardB3 = 2; //不产生冒险 end |
波形分析:
编写具有WB2EXE以及MEM2EXE冒险的汇编代码对CPU进行测试:
| addi?? $1, $zero, 5 addi?? $1, $zero, 6 addi?? $2, $1, 0? #上面是测试MEM到EXE addi?? $1, $zero, 5 sll ?? $zero, $zero, 0 addi?? $2, $1, 0? #此处测试WB到EXE |
波形如下
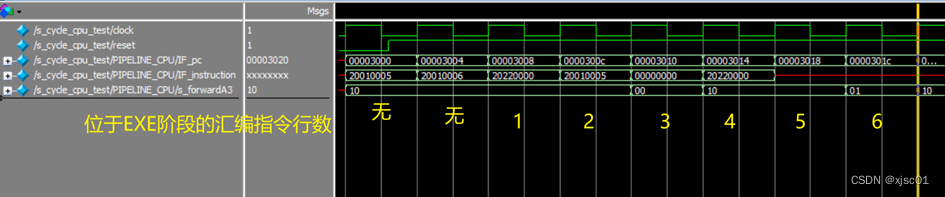
对于汇编指令第三行,其与第一行构成二阶冒险,与第二行构成一阶冒险,在这里应该优先使用一阶冒险,所以应该从MEM阶段进行旁路。对应波形图中s_forwardA3为0
对于汇编指令第六行,与第四行构成二阶数据冒险,波形图中s_forwardA3为1,从WB进行旁路
其余情况没有数据冒险,所以s_forwardA3 = 2’b10,表示不进行旁路,使用从ID阶段寄存器文件中得到的值。
(6)WB2ID的实现
这一个旁路是专门针对三阶冒险进行的。
如果检测到WB需要写入寄存器的编号与ID的寄存器编号一致且不为0,那么就进行这一个旁路。
优先级分析:
按照“(4)解决数据冒险总体分析”中的分析,这一种旁路应该是优先级最底的。在对于WB2ID直接实现就好,不需要特殊判断是不是有一阶或者二阶冒险。
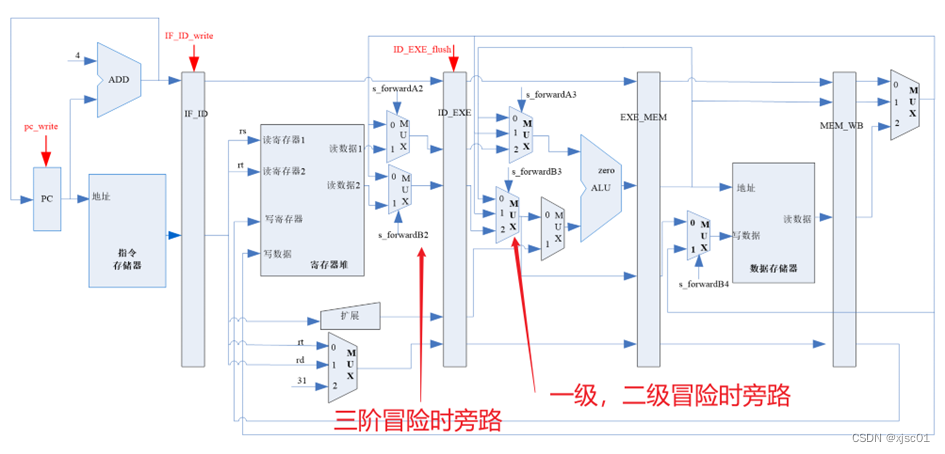
在图中可以看到:如果当前指令有一级或者是二级冒险,那么在ID阶段得到的值在后面会被忽略(后面的MUX不会选择ID/EXE阶流水线寄存器中的值),即一二级冒险的优先级由于数据通路的设计,高于三级冒险。所以在此处发现冒险之后可以直接旁路,而不必关心有没有一二级冒险。
s_ forwardB3的控制模块:
| always @(*) begin ? ? if(WB_reg_write == 1 && WB_num_write != 0 ? ? && WB_num_write == ID_rs) ? ? ? ? s_forwardA2 = 0; ? ? else ? ? ? ? s_forwardA2 = 1; end always @(*) begin ? ? if(WB_reg_write == 1 && WB_num_write != 0 ? ? && WB_num_write == ID_rt) ? ? ? ? s_forwardB2 = 0; ? ? else ? ? ? ? s_forwardB2 = 1; end |
波形分析:
编写汇编代码,其中具有三阶冒险。
| addi?? $1, $zero, 5 sll ?? $zero, $zero, 0 sll ?? $zero, $zero, 0 addi?? $2, $1, 0? ?????? #与第一行的指令构成三阶冒险 |
波形如下:

可以看到,在ID级的指令为前三行的代码不会出现冒险,所以旁路到ID级的多路选择器的选择信号为2,对应gpr中读出来的数据。对于第四条指令,与第一条汇编指令发生三阶冒险,所以选择信号为1.以读取最新的值。
备注:MUX选择信号为1:WB-ID;选择信号为2:从gpr中读取。
(7)halt+WB2EXE的实现
在前面的讨论中,除了前面的指令为lw指令的情况下的一阶冒险没有考虑完之外,其他的冒险已经考虑完成。
对于前面的指令为lw并且为一阶冒险的情况,分为两种情况进行讨论。
1.如果后面的指令为EXE型指令(非sw指令)
根据下表:
| TIME | CC1 | CC2 | CC3 | CC4 | CC5 | |
| 前面的指令(A) | IF | ID | EXE | MEM | WB | |
| 后面的指令(B) | 一阶 |
| IF | ID | EXE | MEM |
必须阻塞一个周期,然后实现WB-EXE旁路。
在之前的讨论中,已经实现了WB到EXE的旁路,所以为了应对这一种情况,仅仅需要添加阻塞逻辑就可以了。
为了实现阻塞的效果,需要进行以下操作:
- 保持PC不变(使得原来在IF的指令在下一个周期仍然在IF进行执行)
- 保持IF_ID不变(使得原来在ID的指令在下一个周期仍然在ID进行执行)
- 使得ID_EXE清零(这一条指令为空指令,把流水线寄存器清零就可以实现把“空指令”的写寄存器以及写存储器的控制信号清零,从而对系统没有任何的影响,相当于是执行了空指令)
同时需要注意I型指令,I型指令的rt是I型指令写入的寄存器号,而不是I型指令执行所需要用到的信号,所以I型指令的rt并不参与冒险判断。
| always @(*) begin ? ? if((//满足条件即阻塞 ? ? ? EXE_is_load_word && EXE_num_write != 0 ? ? ? && EXE_num_write == ID_rt //检查rt字段是否与前面的指令要写的寄存器相同 ? ? ? && ID_op != `instruction_op_ADDI//对于I型指令,不关心rt ? ? ? && ID_op != `instruction_op_ADDIU ? ? ? && ID_op != `instruction_op_ANDI ? ? ? && ID_op != `instruction_op_ORI ? ? ? && ID_op != `instruction_op_LUI ? ? ? && ID_op != `instruction_op_SW ? ? ? && ID_op != `instruction_op_LW ? ? ) ? ? || ? ? ( ? ? ? EXE_is_load_word && EXE_num_write != 0 ? ? ? && EXE_num_write == ID_rs //检查rs字段是否与前面要写的寄存器号相同 ? ? ) ? ? ) ? ? ? ? begin//阻塞的逻辑,保持PC以及IF_ID寄存器不变,把ID_EXE清零 ? ? ? ? ? IF_ID_write_enable = 0; ? ? ? ? ? PC_write_enable = 0; ? ? ? ? ? ID_EXE_flush = 1; ? ? ? ? end ? ? else ? ? ? ? begin ? ? ? ? ? IF_ID_write_enable = 1; ? ? ? ? ? PC_write_enable = 1; ? ? ? ? ? ID_EXE_flush = 0; ? ? ? ? end end |
波形分析:
首先编写以下的汇编代码
| addi??? $1, $zero, 5 sw? $1, 0($zero) lw? $2, 0($zero) addi??? $3, $2, 0?? #与第三条指令有数据冒险 |
波形如下:
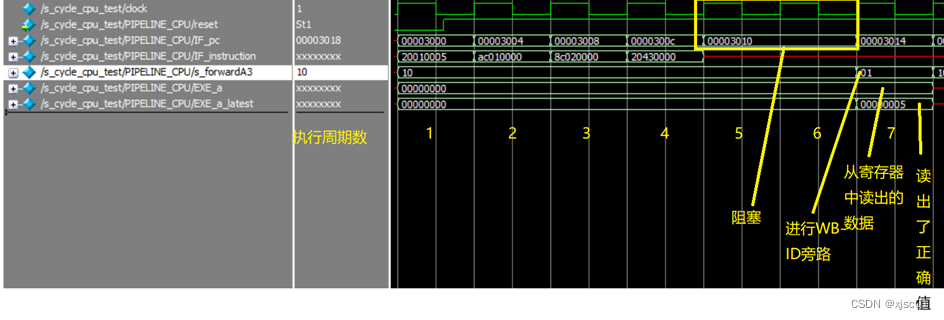
从波形中可以看到,在第四条指令位于ID级的时候,发生了阻塞,导致PC在第五条指令处停滞了两个周期。
在波形图的倒数第3行,表示旁路信号。在阻塞了一个周期之后,正常旁路。倒数第2行可以看出,寄存器中的值仍然为初始值0,但是通过旁路,在a_latest中得到了正确的值(第三条汇编指令写入的5)
2.如果后面的指令为sw型指令
在这个时候可以通过WB-MEM进行实现,由数据通路图可以知道,如果有这样一种冒险,那么优先级是最高的。
具体实现如下:
| always @(*) begin ? ? if( ? ? ? ? WB_op == `instruction_op_LW ?????//判断前一条指令为lw ? ? ? ? && MEM_op == `instruction_op_SW //判断后一条指令为sw ? ? ? ? && WB_num_write != 0 ? ? ? ? && WB_num_write == MEM_rt ? ? ) ? ? ? ? s_forwardB4 = 1; ? ? else ? ? ? ? s_forwardB4 = 0; end |
波形分析:
首先编写如下的汇编代码:
| addi?? $1, $zero, 5 sw? $1, 0($zero) lw? $2, 0($zero) sw? $2, 4($zero) |
得到以下的波形结果:
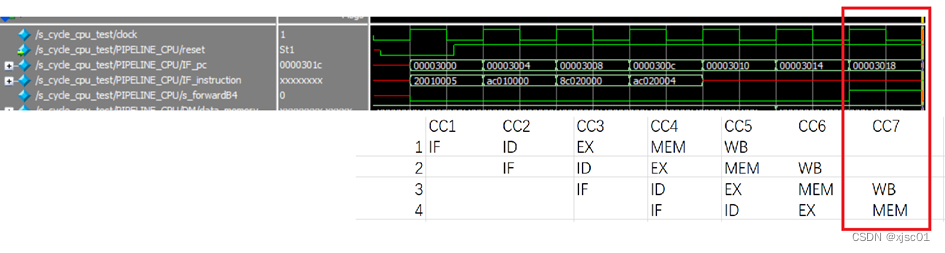
在波形图中,可以看到,在最后一条sw位于mem的时候,旁路信号发生作用,实现WB-MEM的旁路。
检查存储器,发现:

地址为4($zero)的存储器被正确写入数字5。
(三)处理控制冒险
(1)控制冒险概述
控制冒险是指在计算机程序中由于分支指令(beq,j,jal,jr等)的执行可能导致的流水线停顿或指令执行顺序的错乱。
为了解决控制冒险,有以下的方法:
①使用阻塞。阻塞可以处理任何的冒险,后果就是使得程序执行的时间大大增加,所以应该尽量避免使用阻塞。
②把分支应用提前到ID级。通过增加多余的硬件,在ID级得到分支的地址,并在时钟的上升沿更改PC的值,这样只需要清除一条指令(阻塞一个周期)
③采用分支预测。当预测的准确度比较高,并且预测错误的代价比较小的时候,可以采用预测来事先执行,而不是等到需要执行的时候进行执行。预测主要有预测分支发生,预测分支不发生以及动态预测
④采用延时槽,在跳转指令之后放置一条与跳转不相关的指令,这样的话,无论分支是否发生,均不会形成阻塞。
在该实验中,采用在ID级应用分支的结果,采用分支总不发生的预测,同时在必须的时候使用阻塞。
(2)j,jal,jr控制冒险的处理
如下图:
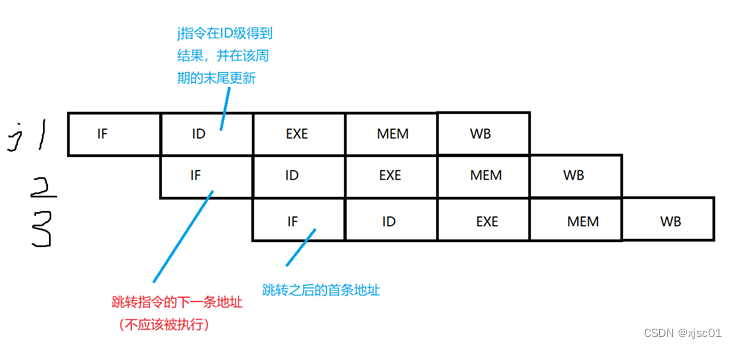
在图中可以看到,对于这一类的指令,主要需要处理两个方面:
①在ID级确定需要跳转的地址
②把跳转指令取到的下一条指令清空(对应图中的第二行)
要完成操作②,进行以下分析:
由于跳转指令的目标地址是在ID级确定的,因此在下一个时钟周期,已经进入IF级的指令将被无效化并阻塞执行。为了实现指令的清空,可以使用NOP指令代替已进入IF级的指令,将其机器码设置为0x0000_0000。为了实现设置机码的功能,可以给流水线寄存器增加一个flush信号,如果其有效,那么就同步复位。
在我的设计中,由于流水线寄存器有异步复位端口,所以我重用异步复位端口,其输入为(reset && (!flush) ),这样,就不必为流水线寄存器增加新的端口。
Flush的操作逻辑如下:
| always @(*) begin//j,jr,jal指令阻塞,面对IF_ID ? ? if(ID_op == `instruction_op_J ? ? || ID_op == `instruction_op_JAL ? ? || (ID_op == `instruction_op_R_type && ID_funct == 6'b001000))begin ? ? ? ? IF_ID_flush = 1; end end |
之前的代码在置位的时候是把所有的控制信号设置为0,但是在这里需要把指令设置为全0,这一条指令代表sll,即逻辑左移运算。为了保证处理器得到正确的结果,必须把这一条指令进行实现。
查阅MIPS手册,得知这一条指令的格式如下:
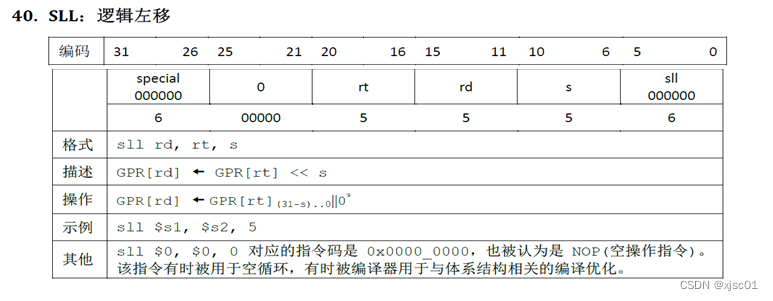
这一条指令相比于之前的指令,增加了shamt字段。所以需要对流水线寄存器做出修改。详细设计步骤如下:
- 为ID_EXE流水线寄存器增加shamt字段
- 为ALU模块增加shamt输入
- 修改ALU内部逻辑,使得其可以处理移位运算。
- 增加ALU操作宏定义alu_op_sll
- 修改控制模块,使得对于移位指令得到ALU控制信号alu_op_sll
| 控制信号 | s_npc | s_data_write | mem_write | s_num_write | s_b | s_ext | aluop | reg_write |
| 取值 | 3 | 1 | 0 | 1 | 0 | 1 | `alu_op_sll | 1 |
此时,控制信号设置完成。
计算地址的功能按照之前单周期的方式,进行连接即可。但是要注意,对于PC+4,这一个值来自于IF阶段,对于其他的地址来源于ID阶段。
波形分析:
在波形中使用j指令进行说明。
编写下面的汇编代码
| addi?? $2, $zero, 1??? //line 1 beq ? $zero, $zero, L1??? //line 2 addi?? $3, $zero, 3??? //line 3 L1: addi?? $4, $zero, 4??? //line 4 |
在第二行指令位于ID级的时候,发生跳转。此时IF已经取了第三行的指令,所以应该进行清除。
对波形进行观察:
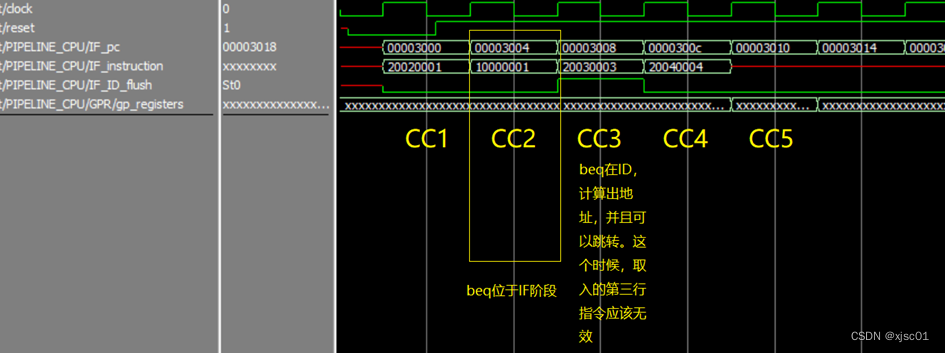
在波形中可以发现,IF_ID_flush按照预期置位为1,这表示清除掉j指令后面取的指令。
下图为寄存器的图,从图片中可以看到,第三条指令并未执行。

(3)beq指令的控制冒险处理
对于控制冒险(在EXE级使用分支结果),如果单纯使用阻塞,那么需要两个周期,显然比较浪费时间。为此,有以下两种优化方式:
- 将分支比较操作提前到指令解码阶段(ID级),以便在下一个时钟周期尽早确定分支目标地址。
- 采用分支预测技术,在这里采用的是预测分支永远不发生。如果预测正确,将不会产生阻塞!
当把指令提前到ID级进行执行的话,如果使用加法器进行比较是否相等,那么会严重拖慢ALU的速度,所以需要采用异或运算,如果得到全零,那么就代表寄存器文件中的两个值是相等的。
使用异或实现的细节:
| assign ID_zero = ~(|(ID_a_latest^ID_b_latest)); |
- ID_a_latest表示在ID级的经过旁路处理的寄存器A的值(消除了数据冒险,即在旁路控制信号控制的MUX之后的值),ID_b_latest同理。
- ID_a_latest^ID_b_latest用于对ID_a_latest和ID_b_latest两个信号进行逻辑异或操作。
- | 表示缩减运算符,可以把异或结果的每一个进行或,得到一位结果。
- 如果|(ID_a_latest^ID_b_latest)为0,代表两个数字相等,所以应该取反。
Flush可以复用(1)中的flush模块,仅仅需要加入对于beq型指令的清空逻辑。如果分支跳转,那么把IF/ID流水线寄存器清空。否则正常执行(预测成功)
具体实现如下:
| else if(ID_op == `instruction_op_BEQ)begin ? ? ? ? if(ID_zero == 1) IF_ID_flush = 1;//跳转,那么清空 ? ? ? ? else IF_ID_flush = 0;//预测成功,正常执行 end |
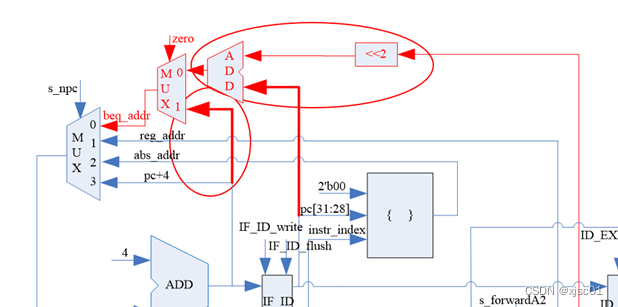
按照图示连接好数据通路即可。
波形分析:
由于在该CPU中使用分支不发生预测,所以如果分支不跳转,那么则执行beq指令之后相当于没有发生任何事情。
编写如下的汇编代码:
| addi?? $1, $zero, 1 nop nop nop ?? #用于处理数据冒险 beq ?? $zero, $1, L1 addi?? $2, $zero, 2 L1: addi?? $3, $zero, 3 |
在该汇编代码中,分支不发生,预测正确,那么PC仍然按照原有的顺序执行。
波形图如下:

通过波形图可以看出,假如预测正确的话,那么就不采取行动,让原来的指令按照顺序执行即可。
(4)beq中数据冒险的分析
由于分支结果在ID级就必须产生,所以在ID级也有可能产生数据冒险。对于ID级的数据冒险,分析如下:
1.对于EXE ID型指令
| TIME | CC1 | CC2 | CC3 | CC4 | CC5 | CC6 | CC7 | CC8 | CC9 | |
| 前面的指令 | IF | ID | EXE | MEM | WB |
|
|
|
| |
| 后面的指令 | 一阶 |
| IF | ID | EXE | MEM | WB |
|
|
|
| 二阶 |
|
| IF | ID | EXE | MEM | WB |
|
| |
| 三阶 |
|
|
| IF | ID | EXE | MEM | WB |
| |
| 四阶 |
|
|
|
| IF | ID | EXE | MEM | WB | |
- 对于一阶,由于ID与EXE阶段重合,无法获得数据,所以必须阻塞一个周期,然后使用旁路MEM-ID
- 对于二阶,直接进行MEM-ID旁路即可
- 对于三阶,由于寄存器堆只有在一个周期结束的时候才进行写回,所以需要进行WB-ID旁路。
- 对于四阶,ID级在WB阶段之后,没有冒险
2.对于MEM ID型指令
| TIME | CC1 | CC2 | CC3 | CC4 | CC5 | CC6 | CC7 | CC8 | CC9 | |
| 前面的指令(MEM) | IF | ID | EXE | MEM | WB |
|
|
|
| |
| 后面的指令 | 一阶 |
| IF | ID | EXE | MEM | WB |
|
|
|
| 二阶 |
|
| IF | ID | EXE | MEM | WB |
|
| |
| 三阶 |
|
|
| IF | ID | EXE | MEM | WB |
| |
| 四阶 |
|
|
|
| IF | ID | EXE | MEM | WB | |
- 对于一阶,由于ID在MEM阶段之前,无法获得数据,所以必须阻塞两个周期,然后使用旁路WB-ID
- 对于二阶,由于ID与MEM阶段重合,无法获得数据,所以必须阻塞一个周期,然后使用旁路WB-ID
- 对于三阶,使用旁路WB-ID
- 对于四阶,ID级在WB阶段之后,没有冒险
3.所以总的处理方式如下
| ?????????? 前面的指令 数据产生阶段 后面的指令 数据使用阶段 | EXE | MEM | ||||||
| 一阶 | 二阶 | 三阶 | 四阶 | 一阶 | 二阶 | 三阶 | 四阶 | |
| ID | 阻塞一个周期,MEM-ID旁路 | MEM-ID | WB-ID | 无冒险 | 阻塞两个周期,WB-ID旁路 | 阻塞一个周期,WB-ID旁路 | WB-ID | 无冒险 |
(5)阻塞+MEM2ID分析
(说明:(5)以及(6)先对相应的冒险进行分析,在(7)中做具体的实现)
前一条指令为EXE型指令,根据上表进行设计。
1.对于一阶的情况:
阻塞是在ID级进行阻塞,所以与数据冒险的阻塞情况相似,可以使用与MEM EXE型数据冒险使用同一根阻塞控制线。
其中阻塞的条件是:
ID级的指令为beq,而EXE级的指令①进行了写寄存器;②写寄存器目的地址不是0;③写寄存器目的地址与beq指令的rs,rt相同。
对于MEM-ID旁路,在数据冒险阶段并没有实现,所以在这里需要进行添加。
该旁路的条件为:
- MEM级指令进行了写入寄存器的操作
- MEM级指令写寄存器号与ID级的rs或者rt相同
- MEM级写寄存器号不为0
对于优先级问题,旁路到ID级的优先级为:
- 首先处理MEM-ID旁路(二级冒险),然后处理WB-ID旁路(三级冒险)
- 对于一级冒险,其会在下一个周期的MEM-EXE阶段进行旁路,覆盖之前的结果,所以符合优先级的关系。
综上所述,先处理MEM-ID旁路,再处理WB-ID旁路。
2.对于二阶情况
旁路已经实现
3.对于三阶情况
旁路已经在数据冒险阶段实现,无需再次实现。
(6)阻塞+WB2ID分析
对于旁路机制,已经在数据冒险阶段实现了从WB到ID级的旁路,所以在这里仅仅需要考虑阻塞。
1.对于一阶冒险的阻塞:
需要阻塞两个周期,阻塞均发生在ID阶段。对于第一个阻塞,与数据冒险中的lw-EXE型指令相同;对于第二个阻塞,判断条件为:
①MEM为lw且ID为beq
②MEM的写寄存器编号不为0
③MEM的写寄存器编号与ID级的rs或者rt相同
2.对于二阶冒险的阻塞:
与一阶冒险的阻塞中的第二个阻塞相同,无需实现。
(7)处理ID级计算地址的数据冒险
首先,增加旁路机制(MEM-ID旁路)
| always @(*) begin ? ? if(MEM_reg_write == 1 && MEM_num_write != 0???? //优先MEM-ID ? ? && MEM_num_write == ID_rs) ? ? ? ? s_forwardA2 = 0; ? ? else if(WB_reg_write == 1 && WB_num_write != 0? //然后考虑WB-ID ? ? && WB_num_write == ID_rs) ? ? ? ? s_forwardA2 = 1; ? ? else ? ? ? ? s_forwardA2 = 2; |
对于s_forwardB2同理。
然后按照数据通路示意图修改数据通路,完成旁路的工作。
然后再处理阻塞的情况,定义如下几个变量:
| reg one_cycle_stall_judge1; reg one_cycle_stall_judge2; wire one_cycle_stall; reg second_cycle_stall; assign one_cycle_stall = one_cycle_stall_judge1 || one_cycle_stall_judge2; |
- 对于one_cycle_stall阻塞,有两种判决条件,任意一种生效,那么判定为one_cycle_stall
- second_cycle_stall表示(6)中的一阶冒险的第二次阻塞以及(6)中的二阶冒险的阻塞
- 无论one_cycle_stall发生还是second_cycle_stall发生,均会进行阻塞(使得PC值不变,IF/ID流水线寄存器不变,ID/EXE流水线寄存器清零)
- one_cycle_stall_judge1的判断条件为数据冒险中的lw EXE型冒险
- one_cycle_stall_judge2实现(5)中的阻塞
定义如下:(具体的分析见(5) )
| if( (EXE_reg_write && EXE_num_write != 0 && ? ? ? ?EXE_num_write == ID_rs && ID_op == `instruction_op_BEQ ? ? ? ) ? ? ? || ? ? ? ( ? ? ? ? EXE_reg_write && EXE_num_write != 0 && ? ? ? ? EXE_num_write == ID_rt && ID_op == `instruction_op_BEQ ? ? ? ) ? ? ) ? ? ? one_cycle_stall_judge2 = 1; ? else ? ? one_cycle_stall_judge2 = 0; |
对于second_cycle_stall,具体实现如下(判断条件见(6)的一阶冒险的第二个阻塞)
| ? if( MEM_op == `instruction_op_LW && ID_op == `instruction_op_BEQ ? ? ? ? ? ? ? ? && MEM_num_write != 0 ?&& ? ? ? ? ? ? ? ? ? (MEM_num_write == ID_rs || MEM_num_write == ID_rt) ? ? ) ? ? second_cycle_stall = 1; ? else ? ? second_cycle_stall = 0; |
到此,完成了控制冒险以及前移分支判断所新增加的数据冒险的处理。
波形分析:
编写如下的汇编代码进行测试
| addi?? $1, $zero, 7 addi?? $2, $zero, 8 beq $1, $2, L1 addi?? $3, $zero, 3 L1: addi?? $4, $zero, 4 |
对于测试指令的分析:Beq指令与第二行的指令构成了一阶冒险,需要进行阻塞。在阻塞完成之后,beq与第一行指令构成三阶冒险,应该采用WB-ID旁路。与第二行指令构成二阶冒险,应该采用MEM-ID旁路。
综合得到波形如下:

在波形中可以看出来,CPU在beq指令位于ID级的时候进行了阻塞。阻塞一个周期之后,对于rs,采用WB-ID旁路;对于rt,采用MEM-ID进行旁路。
通过旁路之后,a_latest与b_latest为正确的值。
-
遇到的问题和解决方法:
问题一:

提交之后,提示我的指令instruction出现问题,编写testbench检查:
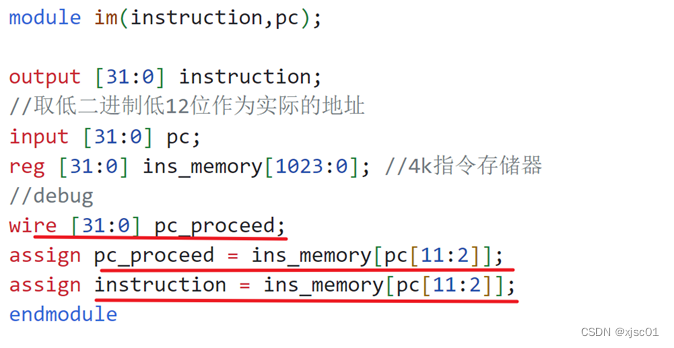
增加了一个临时的输出pc_proceed

发现对于同样的assign赋值语句,输出的结果却不一样。
检查顶层模块,发现如下:
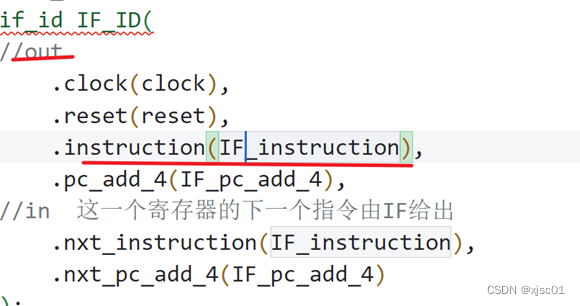
把IM的输出以及IF_ID的输出接到了一起,所以导致了结果不确定。
问题二
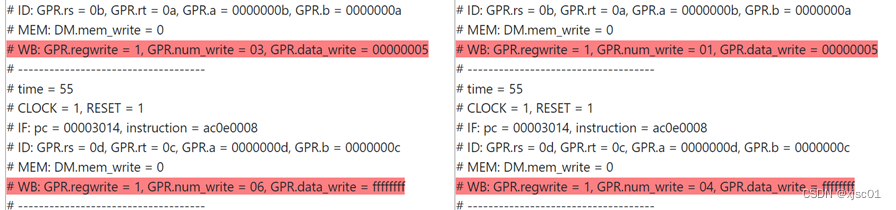
经过检查是指令译码的接线错误
问题三:

在红色部分本来需要进行阻塞,但是我的代码并没有阻塞,使用仿真,编写以下代码:
| .text lw $t5, 0($a2) addu $t7, $t5, $t6 add $t1, $a0, $v1 |
使用上述的汇编代码进行仿真:

发现接线位数不对(如图中的黄色部分),继续检查代码
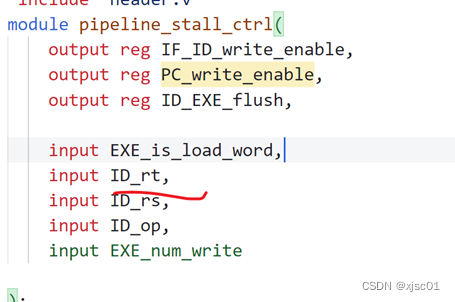
把相关的位数进行更正。
继续仿真,还是发现有错误,


发现在test测试信号显示正常的情况下,nxt_is_load_word值错误。
再仔细检查,发现没有标明为二进制数,只需要把
| ID_instruction[31:26] == 100011 ? 1 : 0 |
改为
| ID_instruction[31:26] == 6'b100011 ? 1 : 0 |
更改之后发现可以正常阻塞
![]()
问题四
发现了仅有的一条错误:

由于在前面进行过阻塞,怀疑阻塞部分出现问题。

红色的框中应该为&&
问题五
更改问题四之后,出现最后错误

前述的控制信号等等均没有问题,偏偏在写存储器的时候出现了问题。
推测是发生了数据冒险,检查发现,我没有处理红框框起来的冒险。

但是在增加对印的控制模块之后,还是存在冒险。
推测冒险是MEM,编写以下汇编指令:
| .text addi ???? $t4, $zero, 5 sw?? ?? $t4, 4($zero)#事先向1号存储单元存入5 add ????? $t5, $zero, $zero addu ??? $t7, $t5, $t6 add ????? $t1, $a0, $v1 lw?? ?? $2, 4($zero)#从1号存储单元读出 sw?? ?? $2, 8($zero)#存入2号存储单元、 |
发现在我的代码中,MEM_op传递出现问题:

添加EXE_MEM流水线寄存器中的op以及nxt_op,发现信号位数不对(下图中最上面的信号),接线错误

在更改之后,op信号可以正常传递。
问题六
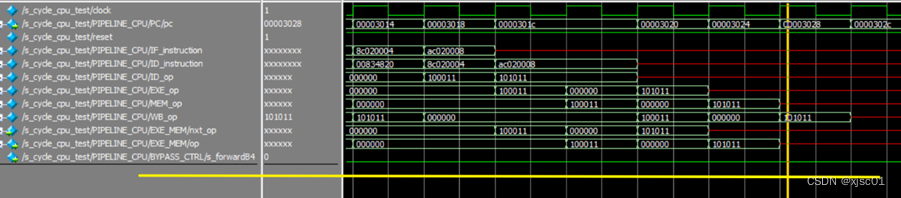
更正问题五之后,s_forwardB4(使用黄线标出)没有按照预期进行变化。
经过检查,未按照预期,多出一个阻塞

当指令不明确时,可能会产生以上问题,所以在原有的指令后面添加一些无关紧要的指令
| .text addi ? $t4, $zero, 5 sw? ?? $t4, 4($zero)#事先向1号存储单元存入5 add ?? $t5, $zero, $zero addu ? $t7, $t5, $t6 add ?? $t1, $a0, $v1 lw? ?? $2, 4($zero)#从1号存储单元读出 sw? ?? $2, 8($zero)#存入2号存储单元 addu ? $t7, $t5, $t6 #后面填充指令,防止执行过程中出现指令不明确 add ?? $t1, $a0, $v1 addu ? $t7, $t5, $t6 add ?? $t1, $a0, $v1 |
再次仿真,发现仍然有阻塞,检查对印代码:

根据汇编指令,在0x301c处出现阻塞,这个时候lw在EXE级,sw在ID级,阻塞控制模块识别到lw在EXE,同时ID级的I型指令rt字段需要使用数据,所以发生了阻塞
| if((//满足条件即阻塞 ? ? ? EXE_is_load_word && EXE_num_write != 0 ? ? ? && EXE_num_write == ID_rt ? ? ? && ID_op != `instruction_op_ADDI//对于I型指令,不关心rt ? ? ? && ID_op != `instruction_op_ADDIU ? ? ? && ID_op != `instruction_op_ANDI ? ? ? && ID_op != `instruction_op_ORI ? ? ? && ID_op != `instruction_op_LUI ? ? ? && ID_op != `instruction_op_SW ? ? ? && ID_op != `instruction_op_LW ? ? ) ? ? || ? ? ( ? ? ? EXE_is_load_word && EXE_num_write != 0 ? ? ? && EXE_num_write == ID_rs ? ? ) ) |
在代码中可以看到,我的代码已经考虑了如果是I型指令,那么rt与lw写寄存器的寄存器号一致时,不会阻塞。进行波形仿真:

在黄色框内,发现op字段位数不对(本来是6位,但是我这里只有5位),进行更改。

更正完成之后,顺利通过测试
问题七

在实现上一条指令为EXE型的一阶数据冒险的时候,发现流水线寄存器被意外清零。
回忆发现:在之前解决控制冒险的时候,对IF/ID这一个流水线寄存器进行过置零。
我在代码中,使用ID级的比较器进行判断。即,如果比较器的输出zero为1,则发生跳转,清空IF/ID级的寄存器;否则正常执行。
具体实现如下:
| always @(*) begin//j,jr,jal指令阻塞,面对IF_ID ? ? if(ID_op == `instruction_op_J ? ? || ID_op == `instruction_op_JAL ? ? || (ID_op == `instruction_op_R_type && ID_funct == 6'b001000))begin ? ? ? ? IF_ID_flush = 1; ? ? end ? ? else if(ID_op == `instruction_op_BEQ)begin? //判断逻辑为这两句: ? ? ? ? if(ID_zero == 1) IF_ID_flush = 1; ? ? ? ? else IF_ID_flush = 0; ? ? end ? ? else ? ? ? begin ? ? ? ? IF_ID_flush = 0; ? ? ? end end |
在之前的设计中,没有考虑冒险,所以只要遇到ID级位beq指令,如果zero为0,那么直接把刚取的指令清零。
但是如果由于ID级所需要的数据在这一时刻无法通过旁路得到,那么就必须要发生阻塞,阻塞的时候,不可以对IF/ID级流水线进行置0.把控制逻辑修改如下:
其中one_cycle_stall表示是否为阻塞一个周期的情况。
| if(ID_zero == 1 && (~one_cycle_stall)) IF_ID_flush = 1; ? ? ? ? else IF_ID_flush = 0; |
问题八

在测试样例中部的时候,我的逻辑控制没有问题,但是数据部分出现错误,推测是数据通路连接不正常。由于问题出现在MEM阶段,检查我的数据通路。
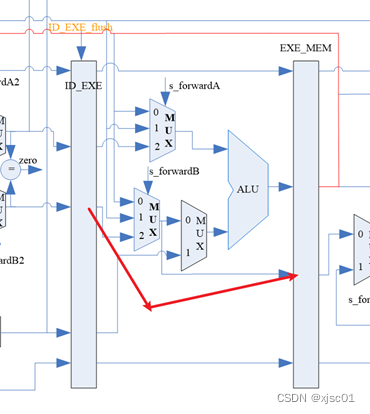
发现我的流水线寄存器的输入并不是经过数据冒险处理之后的,而是直接把ID级的数据赋给了EXE/MEM流水线寄存器。(如图中红色的线)
错误代码如下:
| exe_mem EXE_MEM( ……… .nxt_b(EXE_b), ……… ) |
需要把下一级流水线的输入与多路选择器的输出进行连接。
问题九
发现在第二次阻塞时出现问题。

本来需要两次,但是我的程序仅仅阻塞了一次。编写汇编代码进行测试:
| addi??? $t1, $zero, 20 sw? $t1, 4($zero) addi??? $2, $zero, 20 lw? $1, 4($zero) beq $1, $2, L1 sll $zero, $zero, 0 sll $zero, $zero, 0 sll $zero, $zero, 0 sll $zero, $zero, 0 L1: sll $zero, $zero, 0 |
在代码中,beq指令前面有一条lw指令,可以用来测试我的CPU
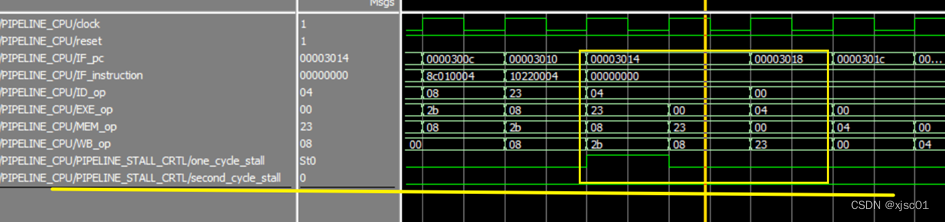
波形图如图,第二次阻塞的控制信号为second_cycle_stall,黄色方框圈出来的就是我的程序需要阻塞的周期,明显看到,是因为second_cycle_stall信号出现了问题。
在代码中进行检查,发现:IF/ID级的寄存器同样被清空,根据 问题七 中的情况,迅速定位到控制冒险中。

红色框圈住的为新增加的语句。
问题十:
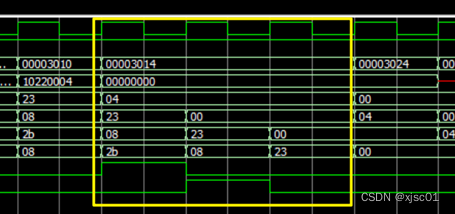
在问题九的内容得到了修正之后,发现second_cycle_stall的值还是不正常。为此,根据确定second_cycle_stall的条件语句进行拆分,见代码:
| wire test1; wire test2; wire test3; assign test1 = MEM_op == `instruction_op_LW && ID_op == `instruction_op_BEQ; assign test2 = MEM_num_write != 0 ; assign test3 = (MEM_num_write == ID_rs || MEM_num_write == ID_rt); |
然后继续仿真,得到的波形如图:

在图中发现,if中的条件表达式全部为x(即test1, test2, test3,均不确定),猜测可能没有完成接线。检查代码发现对于新增加的MEM_op和MEM_num_write没有接线。
更改之后,发现正常
- 单周期CPU与流水线CPU性能的比较
单周期CPU:一个周期执行一条指令,所需要的时钟周期是由最慢的那一条指令来决定的(即lw),包含了IF,ID,EXE,MEM,WB的时间之和。
流水线CPU:把单周期CPU的执行阶段划分为5个阶段,在同一时间,在每一个阶段执行不同的指令。由于指令是“重叠”执行的,所以流水线CPU的CPI与单周期的CPU一致,均为1。但是由于阶段的划分,使得流水线CPU的时钟周期约为单周期CPU时钟周期的五分之一。
评价性能,主要是考虑一条指令的执行延迟以及单位时间内执行的指令数。
对于执行单条指令的延迟,以lw指令为例子。单周期CPU执行这一条指令的时间就是时钟周期T。但是对于流水线而言,如果流水级划分不均匀,那么最慢的流水级的执行时间大于T/5,所以执行这一条指令的时间也大于T。
由此可见,流水线CPU如果在流水级划分不均匀的情况下,执行单条指令的速度比单周期CPU更慢。
对于程序运行的时候,有大量的指令需要执行,这些指令可以填满流水级,使得各个部件满负荷运转。此时,单周期CPU与流水线CPU的CPI可以认为近似为1.而流水线CPU的时钟周期约为单周期CPU时钟周期的1/5,所以流水线CPU更快。
综上所述:流水线CPU相对于单周期CPU并没有提高单条指令的执行时间。但是对于一个程序而言,其有许多的指令,流水线CPU对于大量指令的执行时间是单周期CPU的1/5,执行的效率显著提高,对于用户而言,等待的时间减短。
- 实验总结:
- 深入理解了CPU的流水线的工作方式。CPU的流水线是把多条指令“重叠” 使得IF,ID,EXE,MEM,WB的功能部件同时运转,形成宏观上并行,微观上串行的执行模式。为了让五个部件在不同的时刻对于不同的指令进行执行,流水线中需要有流水线寄存器把五个阶段分隔成为五个部分,这样,各个部分就可以互不影响,进行运行。
- 学会以波形的方式观察流水线的执行情况。流水线的工作方式通常采用单周期流水线图以及双周期流水线图来进行表示。在实验中,采用了波形来对流水线的工作进行观察,最上面的clock而言,可以确定每一个时钟周期的时间,相当于是一个多周期流水线图。通过添加不同的信号来进行展示,我观察到了相应的信号在流水线中的传递,更加深刻地理解了其工作方式。
- 增加了数据冒险的理解。在本次实验中,使用旁路和阻塞来解决数据冒险,总共有5条旁路来处理相关的冒险。对于lw-EXE型指令以及beq指令,还需要配合使用阻塞完成。通过这一次实验,使得我对于数据冒险控制单元的处理逻辑有了深刻的认识。对于旁路,不管需不需要,都可以旁路最新的值。但是对于阻塞,必须仔细把握需要阻塞的条件以防止产生没有必要的阻塞。
- 学习了如何对CPU进行阻塞。我学会了对CPU进行阻塞的方法,若在ID级进行阻塞,那么需要使得EXE,MEM,WB的指令向后继续执行,IF,ID指令保持不变,下一个周期EXE指令为NOP指令。要使IF,ID指令保持不变,需要是对应的PC寄存器和IF/ID寄存器保持不变,并把ID/EXE清零。
- 了解了简单的分支预测的实现。如果对于beq指令,不进行操作,取的指就是beq下一条指令,这代表这分支不发生。所以实现分支预测仅仅需要判断是否发生跳转。如果跳转,那么把IF/ID寄存器清空,表示预测失败。都这不进行任何操作。
- 学习了如何把已经读入的指令清除。由于每一级的控制信号都是由流水线寄存器给出,所以要把某一级的指令设置为NOP指令,仅仅需要把对应的流水线寄存器设置为0.
- 增强了自己的调错能力。在本次实验中,我同样遇到了很多的BUG,在单周期CPU的设计中,我学会了如何自己手写代码进行汇编,然后通过testbentch导入到CPU中进行执行。在这一次实验中,我同样使用了这样的方法进行调试,并解决出了隐藏的问题,调试能力的提升对于我编写复杂的代码有了更好的支撑。
- 加深了对层次化程序设计的理解。我在实验中把流水线的阻塞模块放置入了pipeline_stall_ctrl模块,集中产生阻塞的信号,在bypass_ctrl中解决旁路信号的产生。把相应的功能放置在较小的模块中,这样可以实现功能的封装,简化顶层模块的设计,同时便于对相应的功能进行调错。
- Verilog设计的能力得到了很大的提高。在流水线CPU的设计中,我可以使用verilog语言来实现不同的功能模块,并且通过顶层模块中的模块实例化以及连线,将各个部件组合在一起。对于数据冒险,控制冒险的情况,我学会了独立分析其应该产生的控制信号和优先级,然后采用组合逻辑进行描述。
- 激发了自己对于硬件设计的兴趣。对于一个流水线CPU,从最初的PC,IM等等基本模块,再到单周期CPU,然后处理了所有的数据冒险以及控制冒险,得到了比较完善的流水线CPU。随着增量式设计的进行,CPU的功能不断完善。在完成CPU的设计之后,我感到了一种前所未有的成就感和自豪感。我亲手创造了一个奇迹,我可以通过Mars把汇编语言翻译为16进制指令,然后放入我的CPU进行运行,在指令执行完成之后,可以从最终的寄存器以及存储器波形图上得到CPU的运行结果。通过这一次的实验,我感悟到了硬件设计的魅力,我会在之后的学习生活主动去多接触硬件,了解硬件设计。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 不是小米SU7买不起,而是17.58万的银河E8更有性价比
- 关于达梦DMHS实时同步工具开启预提交参数后导致同步日志报错问题的分析
- 软件测试基础篇(超详细整理)
- Java设计模式-桥接模式
- AI伦理边界:探索人工智能伦理计算
- Matlab 建文件夹保存本次仿真图表数据和参数
- Embedchain聊天机器人开发简明教程【开源RAG框架】
- 柔性数组和C语言内存划分
- 迅软科技丨适合企业用的文档加密软件!
- 网络安全B模块(笔记详解)- 内存取证