用python对航空公司客户价值进行聚类分析
发布时间:2023年12月24日
1.实验目的
1.会用Python创建KMeans聚类分析模型;
2.使用KMeans模型对航空公司客户价值进行聚类分析;
3.会对聚类结果进行分析
2.实验设备
Jupyter notebook
3.实验原理

4.实验内容
使用sklearn.cluester的KMeans类对航空公司客户数据进行聚类分析,把乘客分到不同的类别中。
数据集:air_data.csv
数据集大小:62052条不重复数据
原数据有40个属性,为了大家训练模型方便,本实验使用预处理后的标准化数据,该数据有5个属性。
数据说明:
ZL:入会至当前时长,反应可能的活跃时间
ZR:最近消费时间间隔,反应最近一段时间活跃程度
ZF:消费频次,反应客户忠诚度
ZM:消费里程总额,反应客户对乘机的依赖程度
ZC:舱位等级对应折扣系数,一般舱位等级越高,折扣系数越大
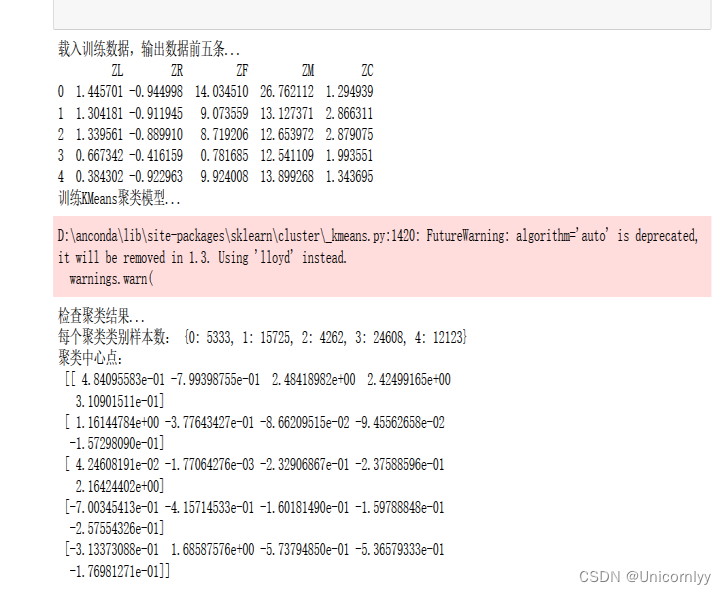
载入训练数据、显示读入数据的前5行
训练KMeans聚类模型,把数据聚成5类
1.
from sklearn.cluster import KMeans
k=5
model=KMeans(algorithm=’auto’,copy_x=True,init=’k-means++’,
Max_iter=300,n_clusyers=5,n_init=10,n_jobs=None,
Precompute_distances=’auto’,random_state=None,tol=0.0001,verbose=0)
检查每个聚类类别样本数、每个聚类类别中心点,统计聚类个数及中心点
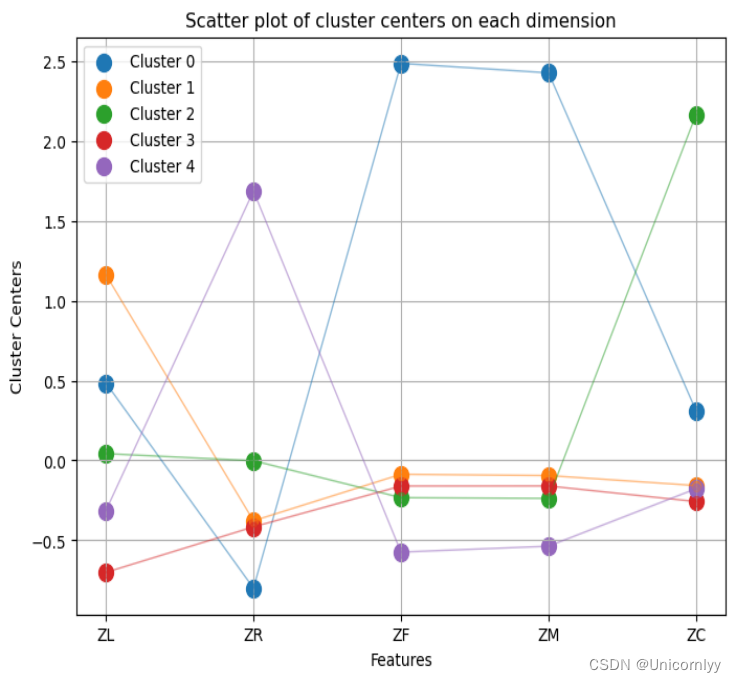
画出5个聚类中心点在每个维度上的散点图,并按统一类别把聚类中心用线连接起来
分析聚类结果
5实验结果分析
6附录(代码)
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import numpy as np
# 载入数据
print("载入训练数据,输出数据前五条...")
data = pd.read_csv(r'D:\D\Download\360安全浏览器下载\air_data.csv')
# 显示前5行数据
print(data.head())
# 选取特征属性
features = ['ZL', 'ZR', 'ZF', 'ZM', 'ZC']
X = data[features]
# 训练KMeans模型并进行聚类
print("训练KMeans聚类模型...")
# num_clusters = 5
# kmeans = KMeans(n_clusters=num_clusters)
# kmeans.fit(X)
k=5
model=KMeans(algorithm='auto',copy_x=True,init='k-means++',max_iter=300,n_clusters=5,
n_init=10,random_state=None,tol=0.0001,verbose=0)
model.fit(X)
print("检查聚类结果...")
# 统计每个类别的样本数
labels = kmeans.labels_
unique, counts = np.unique(labels, return_counts=True)
cluster_counts = dict(zip(unique, counts))
print("每个聚类类别样本数:", cluster_counts)
# 获取聚类中心点
centers = kmeans.cluster_centers_
print("聚类中心点:\n", centers)
# 画出5个聚类中心点在每个维度上的散点图,并按统一类别把聚类中心用线连接起来
# 获取每个特征的列索引
feature_indices = [data.columns.get_loc(feature) for feature in features]
# 绘制散点图
plt.figure(figsize=(8, 6))
for i in range(num_clusters):
plt.scatter(feature_indices, centers[i], label=f'Cluster {i}', s=100)
plt.plot(feature_indices, centers[i], label='', linestyle='solid', linewidth=1, alpha=0.5, marker='o')
plt.xlabel('Features')
plt.ylabel('Cluster Centers')
plt.title('Scatter plot of cluster centers on each dimension')
plt.xticks(ticks=feature_indices, labels=features)
plt.legend()
plt.grid(True)
plt.show()
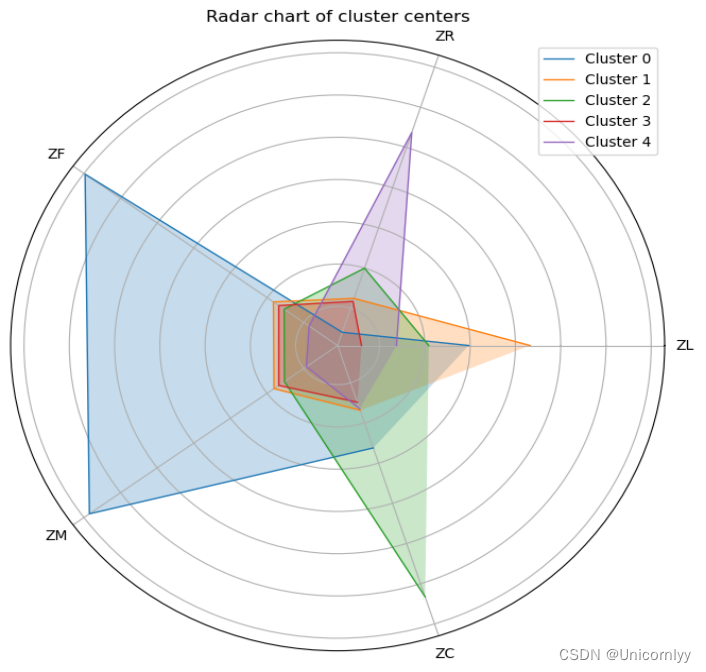
# 画出雷达图
labels = ['ZL', 'ZR', 'ZF', 'ZM', 'ZC']
# 创建一个雷达图
angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False).tolist()
fig, ax = plt.subplots(figsize=(8, 8), subplot_kw=dict(polar=True))
# 绘制每个类别的雷达图
for i in range(num_clusters):
cluster_center = centers[i]
ax.plot(angles, cluster_center, label=f'Cluster {i}', linewidth=1, linestyle='solid')
ax.fill(angles, cluster_center, alpha=0.25)
ax.set_yticklabels([])
ax.set_thetagrids(np.degrees(angles), labels)
plt.title('Radar chart of cluster centers')
plt.legend()
plt.show()
文章来源:https://blog.csdn.net/m0_68165821/article/details/135095804
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Gamma LUT PG285笔记
- 鸿蒙开发笔记(二十四):动画--页面内动画
- Android Studio 如何实现软件英文变中文教程
- 如何开发属于自己的小程序?
- 【Java 并发】三大特性
- MySQL-DQL
- 【基础知识】Class A/B/AB等放大器的区别
- Bytetrack学习笔记
- Origin 或 Referer 的关系和区别
- 【一起学Rust | 框架篇 | Tauri2.0框架】Tauri2.0环境搭建与项目创建