【刷题】leetcode 1 . 两数之和
发布时间:2024年01月16日

两数之和

1 思路一 (简单突破)
最简单的思想: 遍历 从头开始逐个遍历。
首先选定 加数1 然后寻找 加数2 ,如果两者之和满足条件 target 。返回相应下标即可!
int* twoSum(int* nums, int n, int target, int* returnSize) {
for(int i = 0;i < n;i++){
//加数1 从头开始
for(int j = i + 1;j < n;j++){
//加数2 从加数1 后一位开始
if(nums[i]+nums[j] == target){
//满足条件即可返回对应下标
int* a = (int*)malloc(2*sizeof(int)) ;
a[0] = i;
a[1] = j;
//返回的数组大小
*returnSize = 2;
//返回数组
return a;
}
}
}
//如果全不满足 返回NULL
*returnSize = 0;
return NULL;
}
提交! 过啦!!!
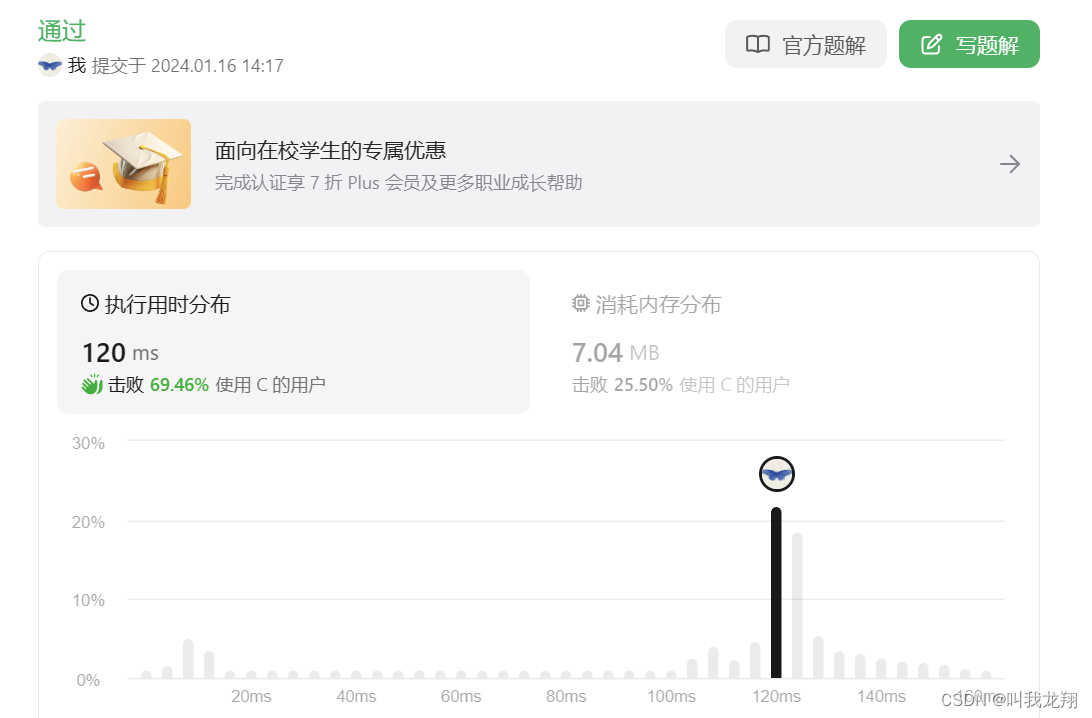
但是看看运算时间,居然这么慢!确实咱们的算法时间复杂度是O(n^2),不够快速。
才打败了 69% 的用户。我们不能满足当下,让我们思考有没有其他思路。
2 思路二 (进行优化)
- 仔细想想,上面的遍历属实比较费时间,那我们如何改进它呢?
- 我的想法是从选择数上下手,取消逐个遍历,改用 二分查找。
- 二分查找的效率比逐个遍历快许多。但是进行二分查找 的前提是 数组有序!
- 如果我们进行简单的排序,那数组下标就被打乱了,无法返回正确值。
- 所以我们有必要创建一个新数组,而且是二维数组,储存值和对应下标
- 然后不断将和与target 比较,进行二分查找,即可。
//qsort 的比较函数 注意我们传的数据类型是 int*
static int compare(int* n1 , int* n2){
return n1[0] - n2[0] ;
}
int* twoSum(int* nums, int numsSize, int target, int* returnSize) {
int n = numsSize;
int arr[n][2]; // 分别储存下标和值大小 保证同时移动
// 将原数组的值以及它对应的下标存入临时数组中
for (int i = 0; i < n; i++) {
arr[i][0] = nums[i]; // 值
arr[i][1] = i; // 该值对应的下标
}
//排序
qsort(arr,n,sizeof(arr[0]),compare);
//二分寻找
for(int i = 0; i < n;i++){
int left = 0 ,right = n-1;//区间[0 , n-1]
while(left <= right){
int mid = (left + right) / 2;//区间中点
//检查是否和为target 并且 两数下标不能相同(否则就是同一个数)
if(arr[mid][0] + nums[i] == target && i != arr[mid][1] )
{
*returnSize = 2 ; //两个数
//开辟两个int类型的空间
int* ret = (int*)malloc(sizeof(int)*2);
//记录两个数下标
ret[0] = i;
ret[1] = arr[mid][1];
return ret;
}
//如果大于target 则在小区间寻找
else if(arr[mid][0] + nums[i] > target){
right = mid-1;
}
//如果小于target 则在大区间寻找
else {
left = mid + 1;
}
}
}
//没有找到
*returnSize = 0;
return NULL;
}
提交! 过啦!!!!!!!
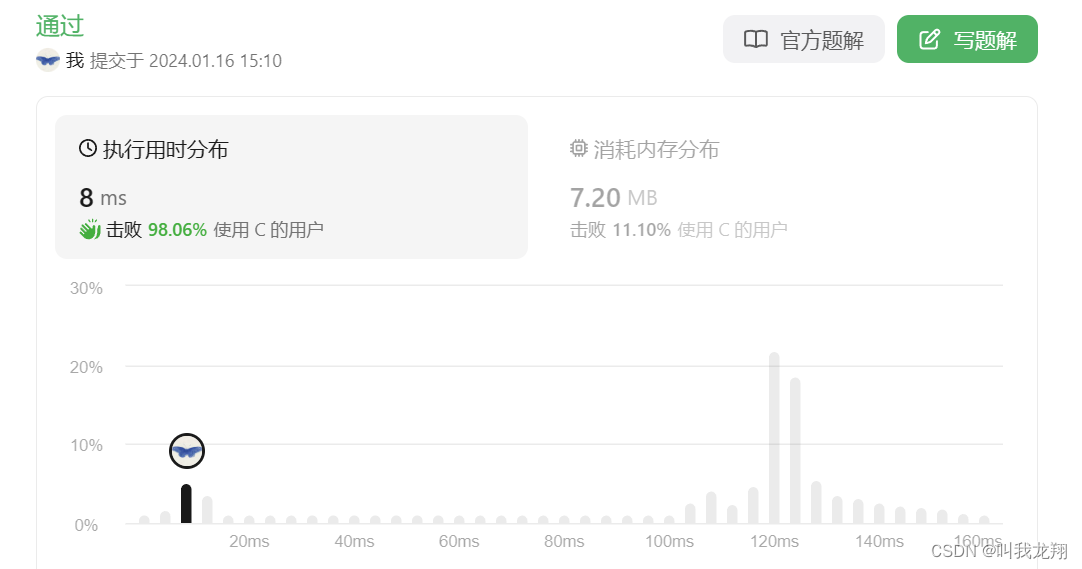
这下子打败了98%的用户。我们从 120 ms 一下子来到 8 ms。
时间复杂度来到O(nlogn).
简直就是飞机和马车的差距
那么问题来到为什么还有 2% 比我们快????????
我看了大佬们的代码,使用到了哈希表 而我现在还不会!哭了。
o(╥﹏╥)oo(╥﹏╥)o!o(╥﹏╥)oo(╥﹏╥)o!o(╥﹏╥)oo(╥﹏╥)o!
3 思路三 (哈希表 我还不会)
下面给大家看一下大佬的 0 ms 的代码。
#define HashSize 107 // 哈希表大小
typedef struct Node { // 哈希结点
int value; // 值
int index; // 下标
struct Node* next; // 下指针
}Node;
int* twoSum(int* nums, int numsSize, int target, int* returnSize) {
int n = numsSize; // 数组长度
Node* hash[HashSize]; // 哈希表
for (int i = 0; i < HashSize; i++) { // 初始化哈希表
hash[i] = (Node*)malloc(sizeof(Node));
hash[i]->value = hash[i]->index = -1;
hash[i]->next = NULL;
}
for (int i = 0; i < n; i++) { // 遍历一遍原数组
int pos = abs(target - nums[i]) % HashSize; // 找到target - nums[i]在哈希表中对应的位置
Node* head = hash[pos];
while (head->next && head->next->value != target - nums[i]) head = head->next; // 找该位置是否有target - nums[i]这个值
if (head->next) { // 找到符合题意的值
*returnSize = 2;
int* ans = (int*)malloc(sizeof(int) * 2);
ans[0] = i; ans[1] = head->next->index; // 写入答案
for (int i = 0; i < HashSize; i++) free(hash[i]);
return ans;
}
pos = abs(nums[i]) % HashSize; // 找到nums[i]在哈希表中对应的位置
head = hash[pos];
while (head->next) head = head->next; // 写在这个位置的末尾
head->next = (Node*)malloc(sizeof(Node));
head->next->value = nums[i]; // 写入该值
head->next->index = i; // 写入该值对应的下标
head->next->next = NULL;
}
for (int i = 0; i < HashSize; i++) free(hash[i]);
*returnSize = 0;
return NULL;
}
作者:星开祈灵
链接:https://leetcode.cn/problems/two-sum/solutions/2326455/1-liang-shu-zhi-he-by-xing-kai-qi-ling-vxt6/
来源:力扣(LeetCode)
著作权归作者所有。
C语言的缺陷 , 需要手撕哈希表。
来看大佬 C++ 的代码,真的非常美观!!!!
美!!!! 帅!!!! 炸裂!!!!
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
map<int,int> a;//提供一对一的hash
vector<int> b(2,-1);//用来承载结果,初始化一个大小为2,值为-1的容器b
for(int i=0;i<nums.size();i++)
{
if(a.count(target-nums[i])>0)
{
b[0]=a[target-nums[i]];
b[1]=i;
break;
}
a[nums[i]]=i;//反过来放入map中,用来获取结果下标
}
return b;
};
};
作者:陈乐乐
链接:https://leetcode.cn/problems/two-sum/solutions/4361/liang-shu-zhi-he-by-gpe3dbjds1/
来源:力扣(LeetCode)
著作权归作者所有。
谢谢阅读Thanks?(・ω・)ノ
下一篇文章见!!!
文章来源:https://blog.csdn.net/JLX_1/article/details/135623703
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 通信入门系列——连续卷积定理、循环卷积、离散卷积定理
- 力扣labuladong一刷day57天队列实现栈以及栈实现队列
- 倾斜摄影与数字孪生:重塑城市未来的技术利器
- vue3新建项目,配置路由vue-router,引入element-plus
- 【第31例】IPD产品开发计划阶段详解
- 如何在 Edge 浏览器中设置自动刷新?
- ubuntu 22.04 安装mysql服务
- 宋仕强论道之华强北精神和文化(二十一)
- sCrypt Inscribe 已支持 BSV20 v2
- 1.5 互联网五层模型