关于本人java面试实际碰到的问题记录 第一章初稿
目录
String、StringBuffer、StringBuilder? --- 这个刚毕业那会面试官好像特喜欢问这个
为什么重写 equals() 就一定要重写 hashCode() 方法
深拷贝和浅拷贝有什么区别? ? ? ? --- 这个问的也多
maven的package、install、deploy命令的区别
Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
基础
网站是如何访问的?
1、输入域名,回车
2、先去本机C盘 System32 的drivers文件下检查有没有这个域名映射
有:返回对应的IP地址,并直接访问该IP地址
无:去DNS服务器找,找到就返回,找不到就返回找不到
String、StringBuffer、StringBuilder? --- 这个刚毕业那会面试官好像特喜欢问这个
String、StringBuffer都是线程安全的
String是不可变长度,StringBuffer、StringBuilder是可变长度 通过append()进行追加
String:final修饰,不可变长度
StringBuffer:方法有synchronized关键字,由于它加锁,会涉及资源竞争等待,所以速度比StringBuilder慢
微服务和分布式的区别
微服务:基于业务边界将一个大的服务拆成一个个小的服务,各个服务之间独立运行。
分布式:将服务部署在不同的机器上。
两者都可以通过RPC进行调用。
SpringCloud的优缺点
优点:
1、服务独立部署
2、代码复用:每个服务提供 RestAPI 通过接口远程调用
3、服务快速启动,拆分后,依赖少了,启动变快
4、团队分供明确:每个团队只用负责自己的业务
缺点:
需要处理分布式缓存、分布式事务。
你使用过哪些springCloud组件?
1、服务的祖册发现:Eureka
2、负载均衡:Ribbon
3、网关:Zuul
4、分布式配置:config
5、断路器:Hystrix
负载均衡有哪些策略?
1、随机 2、轮询 3、ip (每个请求按访问ip的hash结果分配)
4、最少连接 (把请求转发给连接数较少的后端服务器) 5、响应时间
断路器解决了什么问题?
当某个服务出现故障时,故障不会沿着服务的调用链路在系统中蔓延,最终导致整个服务的瘫痪。
实现目标:
1、防止故障扩散:防止故障扩散到其他服务
2、提供降级:失败会调用兜底方法
3、保护线程资源:防止单个服务故障耗尽系统中所有的线程资源
反射
不修改源代码的情况下,可以动态获取到类实例
反射的实现方式
1、Class.forName("类的全路径");
2、类名.class
3、对象名.getClass
缺点:需要解析字节码,数据量大的时候,性能低
接口和抽象类的区别
相同:都不能被实例化
不同:
1、类是继承某个单个类,接口是可以实现多个个接口
2、抽象类可以有非抽象的方法,抽象类并不需要覆盖重写父类的非抽象的方法!
3、抽象类可以有构造器,接口不能有构造器 抽象类的构造器通过子类构造器中的supper(...);进行赋值
Java中的四种引用类型
强引用:内存不足也不会被回收
软引用:内存不足会被回收
弱引用:垃圾回收器发现就会被回收
虚引用:与弱引用类似
final finally 和finalize的区别
1、final final修饰类 该类不可以被继承 ? ? final修饰方法 该方法不可以被覆盖重写 ? final修饰变量 ? 该变量值不可被修改. ? ? 2、finally 不管有没有异常被抛出、捕获,finally块都会被执行。 try块中的内容是在无异常时执行到结束。 catch块中的内容,是在try块内容发生catch所声明的异常时,跳转到catch块中执行。 ? ? 3、finalize是方法名 垃圾收集器在确定某个对象没有被引用时,调用该方法进行垃圾回收处理。 它是在object类中定义的,因此所有的类都继承了它。
拓展:
try里面有return,finally会执行吗?
会!finally的执行早于try里面的return,不管有没有异常,finally块中的代码都会执行
final 与 abstract不能同时使用
final修饰类,类不可以继承 abstract修饰类为抽象类,需要有实现
抽象类中的非抽象方法,可以不用在子类中重写。
static
首先肯定:静态变量是被对象共享的 jdk8之前:放在方法区 jdk8及以后:存放在堆中反射的class对象(即类加载后会在堆中生成一个对应的class对象)的尾部
-
静态方法只能访问静态成员
-
非静态方法可以访问所有成员
静态代码块只执行一次,运行一开始就会开辟内存。
被static/transient修饰的成员变量,不能被序列化
静态变量和静态方法.也就是被static所修饰的变量/方法都属于【类的静态资源】,类实例所共享.除了静态变量和静态方法之外
static也用于静态块,多用于初始化操作。
此外static也多用于修饰内部类,此时称之为静态内部类.最后一种用法就是静态导包,即 import static .import static是在JDK 1.5之后引入的新特性,可以用来指定导入某个类中的静态资源,并且不需要使用类名,可以直接使用资源名。
static修饰的变量可以是线程安全的,也可以是非线程安全的,这取决于具体的实现方式和并发访问的场景。如果一个static变量被多个线程同时访问,而且没有采取任何线程同步机制(比如锁、原子操作等),那么它就是非线程安全的,可能会导致数据竞争和并发访问问题。但是,如果一个static变量被设计成只读(即不可变的),那么它就是线程安全的,因为它不会发生并发访问问题。 final修饰的变量是线程安全的,因为final变量在初始化之后就不能再被修改,不存在并发访问问题。final变量在多线程环境下可以被同时访问,不需要额外的线程同步机制。需要注意的是,如果final变量引用了一个可变对象,那么该对象本身并不是线程安全的,需要采取相应的线程同步措施来保证其线程安全。
使用 Spring Cloud 有什么优势?
1. 易于开发和维护:Spring Cloud采用了微服务架构,能够帮助开发人员快速构建、部署和维护跨多平台、多语言的微服务应用。同时,Spring Cloud还提供了丰富的组件和工具,使得开发人员能够更加灵活地选择所需的功能组件。 2. 高可用性:Spring Cloud可通过负载均衡和服务注册中心等功能,实现对微服务的自动化管理和扩展。这可以提高微服务的可用性和可扩展性,帮助应用系统保持高可用性。 3. 安全性:Spring Cloud提供了多种安全机制和技术,可以确保微服务之间的通信安全性和数据保护。同时,Spring Cloud还提供了身份验证、授权和凭证管理等功能,能够帮助开发人员保障应用系统的安全性。 4. 透明性:Spring Cloud的各个部件都具有高度的可扩展性和可配置性,能够帮助开发人员更好地实现应用系统的透明性和可维护性。同时,针对微服务架构中的跨服务链路追踪等问题,Spring Cloud还提供了相应的解决方案。
为什么重写 equals() 就一定要重写 hashCode() 方法
两个对象相等,其哈希值也相等
如果只重写equals方法,不重写hashcode方法,可能导致 a.equals(b) 表达式成立,但是hashcode不同,违反了下图描述

当n等于2的次幂时,"hash%n"和"hash&(n-1)"等价
HashMap -> key 的[hashcode]对桶的长度 取模 得到数组索引下标
当落到同一个索引下标,也就是hash冲突的时候,通过拉链法来解决,形成单链表,再比较键的[equals]是否相等
Java创建对象的方式
new 反射 clone方法 序列化
序列化和反序列化
序列化:将内存中的对象,以流的方式写到磁盘中,一个个的对象片段
反序列化:将磁盘中的一个个对象片段,以流的方法读取到内存中,组成一个对象
Object类有哪些常用方法
wait notify notifyAll toString equals equals toString
重写和重载
重写(Override): 发生在父子类之间,方法名、参数列表、返回类型必须与父类相同
重载(Overload): 同名方法,参数列表不同
==和equals
==
比较两个对象时,永远比较的是对象的地址是否相等
比较基本数据类型时,比较的是值是否相等
equals
如果两个对象重写了toString方法,比较值,否则和 == 一样,比较地址
String、Integer等这些引用类型的数据,内部java已经帮我们重写了toString方法
“==”比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象。比较的是真正意义上的指针操作。 equals用来比较的是两个对象的内容是否相等 由于所有的类都是继承自java.lang.Object类的,所以适用于所有对象,如果没有对该方法进行覆盖的话,调用的仍然是Object类中的方法,而Object中的equals方法返回的却是==的判断。
int和Integer的区别
int是基本数据类型,Integer是包装类型
int默认值是0 integer默认值是null 假设某个人缺考考试,成绩为null更为合理
Integer符合面向对象编程,可以调用方法,比如 Integer.MAX_VALUE
int比较使用== integer比较使用equals integer在(-128,127)之间可以使用== 直接从缓存中获取
深拷贝和浅拷贝有什么区别? ? ? ? --- 这个问的也多
首先,拷贝根据基本数据类型和引用数据类型来进行一个区分
基本数据类型:值直接拷贝给新的变量
引用数据类型:
1、浅拷贝: Person p1 = new Person(23,"zhangsan"); Person p2 = p1;
p1,p2指向同一个对象 新旧对象还是共享同一块内存
2、深拷贝: Person p2 = (Person)p1.clone();
p1,p2指向不同对象
JDK和JRE的区别
JDK = JRE + 编译、运行等开发工具
JRE = JVM + JAVA系统类库(extenal libraries idea项目左下角外部jar包)
maven的package、install、deploy命令的区别
package :命令完成了项目编译、单元测试、打包功能,
jar包(war包或其它形式的包)[没有布署到本地maven仓库和远程maven私服仓库]
install :命令完成了项目编译、单元测试、打包功能
jar包(war包或其它形式的包)[布署到本地maven仓库,但没有布署到远程maven私服仓库]
deploy :命令完成了项目编译、单元测试、打包功能
jar包(war包或其它形式的包)[布署到本地maven仓库和远程maven私服仓库]
双亲委派机制
当父类加载器在接收到类加载请求后,类加载器发现自己也无法加载这个类(这个情况通常是因为这个类的Class文件在父类的加载路径中不存在)这时父类会把这个信息反馈给子类,并向下委派子类加载器来加载这个类,直到这个请求被成功加载,但是一直到自定义加载器都没有找到,JVM就会抛出ClassNotFund异常。
首先,通过委派的方式,可以避免类的重复加载,当父加载器已经加载过某一个类时,子加载器就不会再重新加载这个类。
另外,通过双亲委派的方式,还保证了安全性。因为Bootstrap ClassLoader在加载的时候,只会加载JAVA_HOME中的jar包里面的类,如java.lang.Integer,那么这个类是不会被随意替换的,除非有人跑到你的机器上, 破坏你的JDK。
那么,就可以避免有人自定义一个有破坏功能的java.lang.Integer被加载。这样可以有效的防止核心Java API被篡改。
如果你想定义一个自己的类加载器,并且要遵守双亲委派模型,那么可以继承ClassLoader,并且在findClass中实现你自己的加载逻辑即可。
哪些数据适合放入缓存
1、即时性、数据一致性要求不高的数据。
2、访问量大且更新频率不高的数据。
类加载
加载:查找并加载类的二进制数据。将二进制数据放到运行时数据区的方法区内,通过创建java.lang.Class对象来封装类在方法区中的数据结构。
连接:
? 1-验证:确保被加载类的正确性。 ? ? 2-准备:为类的静态变量分配内存,并将其初始化为默认值。 ? ? 3-解析:把类中的符号引用转换为直接引用。
初始化:为类的静态变量赋正确的初始值。
类的实例化:
1-为新对象分配内存
2-为实例变量赋默认值
3-为实例变量赋正确的初始值
4-java编译器为每一个类都至少生成一个实例初始化方法(构造方法) ,对应class文件中的<init>
#{}和${}的区别是什么?
#{}是预编译处理,${}是字符串替换。
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
Mybatis在处理${}时,就是把${}替换成变量的值。
使用#{}可以有效的防止SQL注入,提高系统安全性。
Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
?
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude{ DataSourceAutoConfiguration.class })。
?
@ComponentScan:Spring组件扫描。
线程---重点
JUC包下的锁是本地锁,无法应付分布式开发。分布式锁,使用redis。
线程两次调用start会有问题吗?
IllegalThreadStateException 非法线程状态
第一次调用start,线程可能处于新建、就绪、运行状态,第二次调用就要去打破他正在执行的状态,从线程安全角度考量不太好。
线程有哪些基本状态(以及生命周期)??
1、初始状态(New)。 线程对象被创建,即为初始状态。只在堆中开辟内存,与常规对象无异。 2、就绪状态(Ready)。 调用start()方法后,线程就进去了就绪状态。等待操作系统选择,并分配时间片。 3、运行状态(Running)。 获得时间片之后,进入运行状态,如果时间片到期,则返回就绪状态,继续等待。 4、终止状态(Terminated)。 主线程main()或者独立线程run()结束,进入终止状态,并释放持有的时间片。 5、线程等待(Waiting)。 TIMED_WAITING(时间等待):使用sleep方法时,触发的等待是有时间限制的,称为期限等待。 WAITING:使用join方法时,需要等当前线程执行完毕或者中断,这个时间是无法确定的,称为无限期等待。 6、线程阻塞(Blocked)。 处理运行状态的线程,因为某种原因放弃了CPU的使用权,而停止运行。此时线程进入阻塞状态,知道其进入就绪状态,并重新获取到CPU的使用权才会重新进入运行状态。 ?
Java中实现多线程有几种方法?
继承Thread类; 实现Runnable接口; 实现Callable接口通过FutureTask包装器来创建Thread线程; 使用ExecutorService、Callable、Future实现有返回结果的多线程(也就是使用了ExecutorService来管理前面的三种方式)
volatile和synchronized有什么区别
volatile 本质是告诉JVM当前工作内存中的值是不确定的,需要从主内存中获取 synchronized 锁住资源,只有抢到的锁的线程才可以执行,其他线程阻塞 ? volatile仅能保证变量修改的可见性,不能保证原子性 ? synchronized既能变量修改的可见性,也能保证原子性 ? volatile仅能使用在变量上 ? synchronized可以使用在变量、方法和类上
synchronized和lock的区别
synchronized是java内置的关键字 Lock是java类
锁的状态:synchronized 无法判断 lock.tryLock(); 可以判断
锁的释放:synchronized 自动释放锁 lock.unLock(); 手动释放,加了几次,就得释放几次
性能:synchronized 是重量级锁,适合于少量的同步代码块
sleep和wait有什么区别
sleep是Thread类中的方法 wait是Object类中的方法
sleep:让出CPU线程,但是监控状态保持,所以线程不会释放对象锁
wait:线程释放对象锁,进入等待 notify进行唤醒
线程有哪些方法
start:开启一个新的线程
run:JVM进行调度,不会启动新的线程
join:将其他线程合并到当前线程,当前线程阻塞,直到其他线程执行结束
yield:暂停当前线程,重新抢夺CPU资源
sleep:睡眠,不会释放锁
interrupt :中断线程的睡眠,依靠java的异常处理机制
currentThread().getId
currentThread().getName
守护线程
setDaemon 设置守护线程 (发音:低们 )? ?小弟们跟着大哥走,大哥死了,小弟也得死
public class ThreadTest14 {
? ?public static void main(String[] args) throws InterruptedException {
? ? ? ?Thread t = new Secondary();
? ? ? ?t.setName("备份数据的线程");
? ? ? ?// 启动线程之前将Secondary线程设置为守护线程
? ? ? ?t.setDaemon(true);
? ? ? ?t.start();
? ? ? ?// 主线程
? ? ? ?for (int i = 0; i < 10; i++) {
? ? ? ? ? ?System.out.println(Thread.currentThread().getName() + "--->" + i);
? ? ? }
? ? ? ?Thread.sleep(1000);
? }
}
?
class Secondary extends Thread{
? ?public void run() {
? ? ? ?int i = 0;
? ? ? ?while (true) {
? ? ? ? ? ?System.out.println(Thread.currentThread().getName() + "--->" + (++i));
? ? ? ? ? ?try {
? ? ? ? ? ? ? ?Thread.sleep(1000);
? ? ? ? ? } catch (InterruptedException e) {
? ? ? ? ? ? ? ?e.printStackTrace();
? ? ? ? ? }
? ? ? }
? }
}
Executor线程中内部出现数据不一致怎么办
可以使用线程安全的集合和原子变量
池化技术的作用
1、不需要每次创建和销毁,节约资源,响应更快
2、限制个数,避免系统运行缓慢/崩溃
3、资源复用
线程池(Java中有哪些方法获取多线程)? --- 重点
前言
获取多线程的方法,我们都知道有三种,还有一种是实现Callable接口
-
实现Runnable接口
-
实现Callable接口
-
实例化Thread类
-
使用线程池获取
Callable接口
callable接口,重写实现其方法的时候,有返回值,而且可以感知异常
class MyRunnable implements Runnable{
?
? ?@Override
? ?public void run() {
?
? }
}
?
class MyCallable implements Callable{
?
? ?@Override
? ?public Object call() throws Exception {
? ? ? ?return 1024;
? }
}
思考: Thread类的构造方法没有Callable接口,那我怎么使用Callable呢? ? Thread类的构造方法有Runnable接口,可以让 Runnable接口 和 Callable接口 产生联系! 既然需要 Runnable接口,那就准备一个 Runnable接口 的实现类 FutureTask 然后在 FutureTask 类传入 Callable接口 就能直接使用 但是为了后期更好的拓展 FutureTask 可以将 FutureTask 上层再写一个接口 ? RunnableFuture接口 让 RunnableFuture接口 既实现 Runnable接口 , 又实现 Future接口 这样满足要求的情况下,FutureTask其父接口也可以进行拓展!

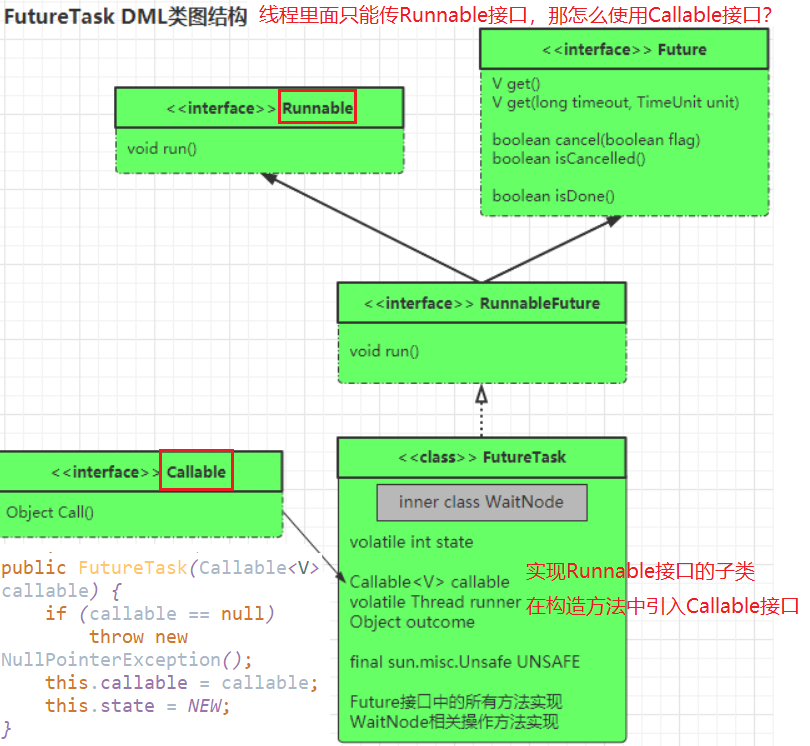
Futuretask 未来任务,可以先让之后要做的某个任务先抽出来,得到返回值后,再和其他任务汇合!

class MyCallable implements Callable<Integer>{
?
? ?@Override
? ?public Integer call() throws Exception {
? ? ? ?System.out.println("call() 方法被调用");
? ? ? ?return 1024;
? }
}
?
?
?
public class CallableDemo {
? ?public static void main(String[] args) throws ExecutionException, InterruptedException {
? ? ? ?FutureTask<Integer> futureTask = new FutureTask<>(new MyCallable());
? ? ? ?new Thread(futureTask,"AA").start();
? ? ? ?int result = 100;
? ? ? ?System.out.println(futureTask.get() + result);
? }
}
最后需要注意的是 要求获得Callable线程的计算结果,如果没有计算完成就要去强求结果,会导致阻塞,直到计算完成
所以一般将 futureTask.get(); 放置在最后,否则会阻塞其他线程
线程池的好处
多核处理的好处是:省略的上下文的切换开销
原来我们实例化对象的时候,是使用 new关键字进行创建,到了Spring后,我们学了IOC依赖注入,发现Spring帮我们将对象已经加载到了Spring容器中,只需要通过@Autowrite注解,就能够自动注入,从而资源复用!
现在需要线程也是类似,new Thread();
因此使用多线程有下列的好处
-
降低资源消耗。通过重复利用已创建的线程,降低线程创建和销毁造成的消耗。
-
提高响应速度。当任务到达时,任务可以不需要等到线程创建就立即执行。
-
提高线程的可管理性。线程是稀缺资源,如果无限创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
架构说明
Java中线程池是通过Executor框架实现的,该框架中用到了Executor,Executors(代表工具类),ExecutorService,ThreadPoolExecutor这几个类。

工作原理

文字说明
-
在创建了线程池后,等待提交过来的任务请求
-
当调用execute()方法添加一个请求任务时,线程池会做出如下判断
-
如果正在运行的线程池数量小于corePoolSize,那么马上创建线程运行这个任务
-
如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列
-
如果这时候队列满了,并且正在运行的线程数量还小于maximumPoolSize,那么还是创建非核心线程like运行这个任务;
-
如果队列满了并且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行
-
-
当一个线程完成任务时,它会从队列中取下一个任务来执行
-
当一个线程无事可做操作一定的时间(keepAliveTime)时,线程池会判断:
-
如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉
-
所以线程池的所有任务完成后,它会最终收缩到corePoolSize的大小。
-
常用三种创建线程池方式
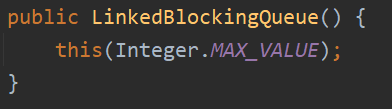
newFixedThreadPool newSingleThreadExecutor 上面这两种使用 LinkedBlockingQueue 队列最大长度为 Integer.MAX_VALUE 候客区21亿把椅子? newCacheThreadPool 这种 maximumPoolSize 最大为 Integer.MAX_VALUE ? 办理窗口21亿个窗口? 底层 都是 ThreadPoolExecutor ? 注意:工作中,这三种都不用!生产中,只用自定义的!

线程池执行方法 submit,带返回值task execute 不带返回值

-
Executors.newFixedThreadPool(int i) :创建一个拥有 i 个线程的线程池 【一池固定线程】
-
执行长期的任务,性能好很多
-
创建一个定长线程池,可控制线程数最大并发数,超出的线程会在队列中等待
-
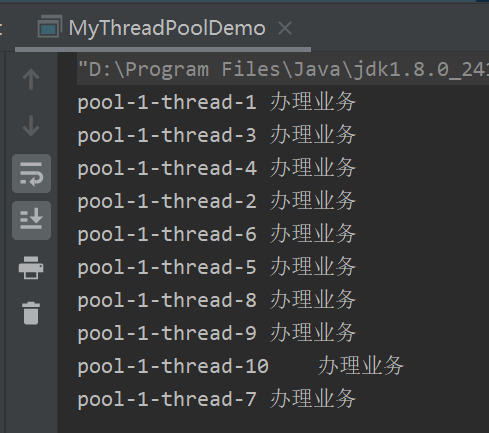
public class MyThreadPoolDemo {
? ?public static void main(String[] args) {
? ? ? ?// 银行有5个窗口
? ? ? ?ExecutorService executor = Executors.newFixedThreadPool(5);
? ? ? ?// 模拟10个业务
? ? ? ?try {
? ? ? ? ? ?for (int i = 1; i <= 10; i++) {
? ? ? ? ? ? ? ?executor.execute(()->{
? ? ? ? ? ? ? ? ? ?System.out.println(Thread.currentThread().getName() + "\t办理业务");
? ? ? ? ? ? ? });
? ? ? ? ? }
? ? ? } catch (Exception e) {
? ? ? ? ? ?e.printStackTrace();
? ? ? }finally {
? ? ? ? ? ?executor.shutdown();
? ? ? }
? }
}

-
Executors.newSingleThreadExecutor:创建一个只有1个线程的 单线程池 【一池单线程】
-
一个任务一个任务执行的场景
-
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行
-
public class MyThreadPoolDemo {
? ?public static void main(String[] args) {
? ? ? ?// 银行有1个窗口
? ? ? ?ExecutorService executor = Executors.newSingleThreadExecutor();
? ? ? ?// 模拟10个业务
? ? ? ?try {
? ? ? ? ? ?for (int i = 1; i <= 10; i++) {
? ? ? ? ? ? ? ?executor.execute(()->{
? ? ? ? ? ? ? ? ? ?System.out.println(Thread.currentThread().getName() + "\t办理业务");
? ? ? ? ? ? ? });
? ? ? ? ? }
? ? ? } catch (Exception e) {
? ? ? ? ? ?e.printStackTrace();
? ? ? }finally {
? ? ? ? ? ?executor.shutdown();
? ? ? }
? }
}

-
Executors.newCacheThreadPool(); 创建一个可扩容的线程池 【一池多线程】
-
执行很多短期异步的小程序或者负载教轻的服务器
-
创建一个可缓存线程池,如果线程长度超过处理需要,可灵活回收空闲线程,如无可回收,则新建新线程
-
public class MyThreadPoolDemo {
? ?public static void main(String[] args) {
? ? ? ?// 银行有N个窗口
? ? ? ?ExecutorService executor = Executors.newCachedThreadPool();
? ? ? ?// 模拟10个业务
? ? ? ?try {
? ? ? ? ? ?for (int i = 1; i <= 10; i++) {
? ? ? ? ? ? ? ?executor.execute(()->{
? ? ? ? ? ? ? ? ? ?System.out.println(Thread.currentThread().getName() + "\t办理业务");
? ? ? ? ? ? ? });
? ? ? ? ? ? ? ?// 睡眠一秒,那只有一个线程执行
// ? ? ? ? ? ? ? try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {e.printStackTrace();}
? ? ? ? ? }
? ? ? } catch (Exception e) {
? ? ? ? ? ?e.printStackTrace();
? ? ? }finally {
? ? ? ? ? ?executor.shutdown();
? ? ? }
? }
}
-
Executors.newScheduledThreadPool(int corePoolSize):线程池支持定时以及周期性执行任务,创建一个corePoolSize为传入参数,最大线程数为整形的最大数的线程池
七大参数
线程池在创建的时候,一共有7大参数
corePoolSize: 核心线程数,线程池中的常驻核心线程数 ? 默认长期工作的线程 在创建线程池后,当有请求任务来之后,就会安排池中的线程去执行请求任务,近似理解为今日当值线程 当线程池中的线程数目达到corePoolSize后,就会把到达的队列放到缓存队列中 ? maximumPoolSize: 线程池能够容纳同时执行的最大线程数,此值必须大于等于1、 相当有扩容后的线程数,这个线程池能容纳的最多线程数,队列满了,最大线程数 - 核心线程数 去处理任务 ? keepAliveTime: 多余的空闲线程存活时间 当线程池数量超过corePoolSize时,当空闲时间达到keepAliveTime值时,多余的空闲线程会被销毁 直到 只剩下corePoolSize个线程为止 默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用 ? unit: keepAliveTime 的单位 ? workQueue: 任务队列,被提交的但未被执行的任务(类似于银行里面的候客区) LinkedBlockingQueue: 链表阻塞队列 SynchronousBlockingQueue: 同步阻塞队列 ? threadFactory: 表示生成线程池中工作线程的线程工厂,用于创建线程池 一般用默认即可 ? handler: 拒绝策略 当队列满了并且工作线程大于线程池的最大线程数时,如何来拒绝请求执行的Runnable的策略
// ? 七大参数 corePoolSize:[5] ? 相当于new了5个Thread,但是没有接收任务来start 核心线程数[一直存在,除非设置了allowCoreThreadTimeOut]; 线程池创建好以后就准备就绪的线程数量,就等待来接收异步任务 ? ? maximumPoolSize:最大线程数量;控制资源,避免一直 new start ? ? keepAliveTime:存活时间。 当前的线程数量大于核心线程数的前提下,只要空闲的线程大于指定的keepAliveTime,则释放空闲线程。 空闲线程:(maximumPoolSize - corePoolSize) ? ? 类似于:空闲的时候解雇临时工 ? ? TimeUnit unit:时间单位(比如:存活多久?) ? ? BlockingQueue<Runnable> workQueue:阻塞队列。 如果任务有很多,就会将目前多的任务放在队列里面。 只要有线程空闲,就会去队列里面取出新的任务继续执行。 ? ? ThreadFactory threadFactory:线程的创建工厂 ? ? RejectedExecutionHandler handler:如果队列满了,按照我们指定的拒绝策略拒绝执行任务 ? ? ? ? 面试题: ? 现在有一个线程池,核心线程数是7个,最大线程数是20个,队列最大为50。若有100个并发请求进来怎么分配? ? ? 7个线程会立即得到执行,50个会进入队列,队列满了,再开启13个新线程执行。剩下的30个使用拒绝策略。
拒绝策略
人员变多,超过MAX后,执行拒绝策略
人员变少,值班窗口比人员还多的时候,销毁多余的空闲线程

以下所有拒绝策略都实现了 RejectedExecutionHandler 接口 AbortPolicy: ? ? 默认,直接抛出 RejectedExcutionException(拒绝执行)异常,阻止系统正常运行 DiscardPolicy: ? ? 直接丢弃后来的任务,不予任何处理也不抛出异常,如果允许任务丢失,这是一种好方案 CallerRunsPolicy: ? 该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者 DiscardOldestPolicy: 抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交当前任务
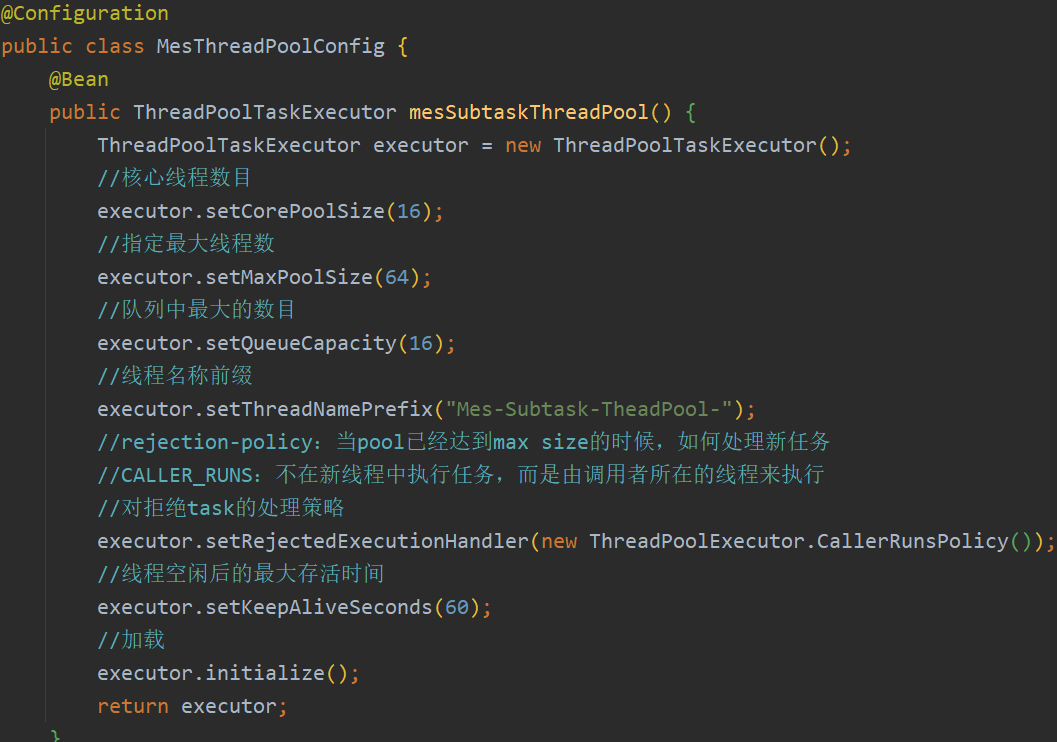
自定义线程池
避免 newFixedThreadPool newSingleThreadExecutor 使用 LinkedBlockingQueue 队列长度太长,例如下面给了 3
避免 newCacheThreadPool 的最大线程数太大,例如下面给了 5

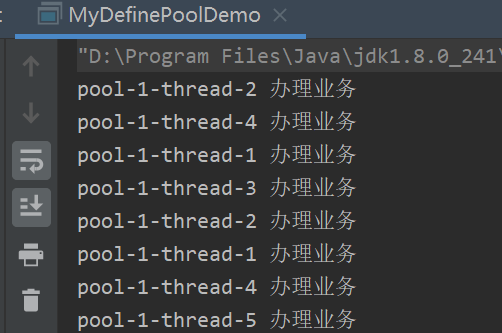
// 9超过了最大线程数 5 + 队列数 3 AbortPolicy 会直接抛异常 new ThreadPoolExecutor.AbortPolicy() ? ? for (int i = 1; i <= 9; i++)

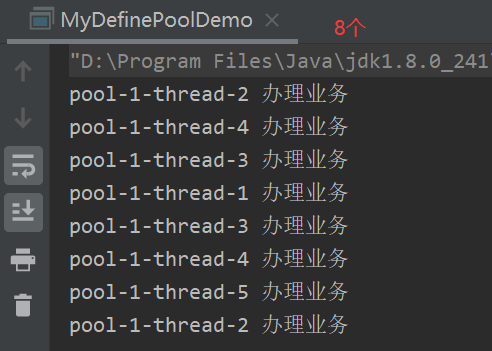
// CallerRunsPolicy 不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者 // 例如下面,main线程来调用的 executor,那么对应回退了两个个main线程 new ThreadPoolExecutor.CallerRunsPolicy() ? ? for (int i = 1; i <= 10; i++)

// DiscardOldestPolicy ? 抛弃队列中等待最久的任务 new ThreadPoolExecutor.DiscardOldestPolicy() ? ? for (int i = 1; i <= 10; i++)
线程池的合理参数设置
生产环境中如何配置 corePoolSize 和 maximumPoolSize ?
// java中查看CPU核数 打印12 说明是六核十二线程 System.out.println(Runtime.getRuntime().availableProcessors());

@Bean作用在方法上,方法名作为 bean对象的id,返回类型做为bean对象的类型 xml中: <bean id class />
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ESP32-HTTP_webServer库(Arduino)
- C#的StringBuilder属性
- 使用 Apache POI 更新特定的单元格
- JCF:Java集合框架
- 建造者模式
- 丰田金融服务公司被勒索800万美元
- 基于51单片机的pwm直流电机调速霍尔元件测速系统(可实现按键控制、蓝牙控制、语音控制)(包含所有资料)
- C++的面向对象学习(6):运算符的重载
- SpringBoot+RocketMQ集群(dledger)部署完整学习笔记
- 【MySQL】计算时间段内满足是首次登录的用户(根据时间统计首次登录用户人数)