【基础】【Python网络爬虫】【5.数据解析】bs4、Xpath、Parsel模块、正则表达式(附大量案例代码)(建议收藏)
Python网络爬虫基础
数据解析
1. 为何数据解析
- 概念:可以将一整张页面中局部的指定数据进行提取。
- 作用:可以实现聚焦爬虫
- 数据解析通用原理:
- 在一张页面源码中,想要爬取的数据是存在于相关的html的标签中进行的存储
- 可以将指定的标签定位到,然后提取该标签中的相关的内容
- 简单描述:
- 1.标签定位
- 2.提取定位到标签中的文本内容
- 聚焦爬虫编码流程
- 指定url
- 发起请求
- 获取响应数据
- 数据解析
- 持久化存储
2. 常见的数据类型
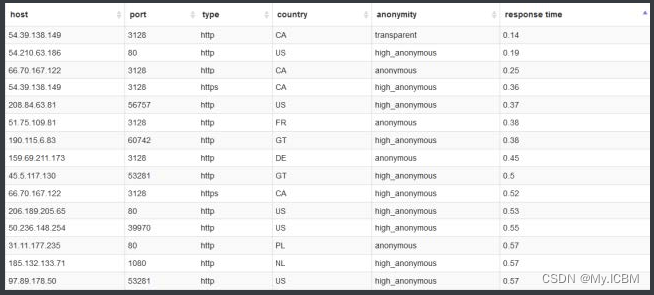
结构化数据
结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
半结构化数据
非关系模型的、有基本固定结构模式的数据,例如日志文件、XML文档、JSON文档等。http://www.bejson.com/jsoneditoronline/ 这个也是json文件。
非结构化数据
顾名思义,就是没有固定结构的数据。各种文档、图片、视频/音频等都属于非结构化数据。对于这类数据,我们一般直接整体进行存储,而且一般存储为二进制的数据格式。
总结:能看懂的就是结构化的数据,看不懂的,就是非结构化数据
3. 爬虫项目实现步骤
"""
爬虫项目实现步骤:
1. 找数据对应的请求地址
2. 通过代码发送地址请求
3. 提取需要的数据内容, 剔除不需要的
一下来那个两种方式是专门在html中提取数据的方法
css选择器
xpath节点提取
正则表达式: 只要是字符串数据, 都能使用正则提取, 万能的匹配方式, 可以用于其他的所有计算机语言中在爬虫中用于少范围的数据提取
4. 保存数据
"""
数据解析模块
1. Bs4
环境安装
# 安装两个第三方库
- pip install bs4
- pip install lxml
bs4解析流程
1.实例化一个BeautifulSoup的对象,然后把即将被解析的页面源码数据加载到该对象中
- BeautifulSoup(fp,‘lxml’):fp表示本地的一个文件,该种方式是将本地存储的html文件进行数据解析
- BeautifulSoup(page_text,‘lxml’):page_text是网络请求到的页面源码数据,该种方式是直接将网络请求到的页面源码数据进行数据解析
2.调用BeautifulSoup对象中相关的属性和方法实现标签定位和数据提取
// 当前目录下新建一个test.html文件,然后将下述内容拷贝到该文件中
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>测试bs4</title>
</head>
<body>
<div>
<p>百里守约</p>
</div>
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
<a href="http://www.song.com/" title="赵匡胤" target="_self">
<span>this is span</span>
宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a>
<a href="" class="du">总为浮云能蔽日,长安不见使人愁</a>
<img src="http://www.baidu.com/meinv.jpg" alt="" />
</div>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li>
<li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li>
<li><a href="http://www.126.com" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li>
<li><a href="http://www.sina.com" class="du">杜甫</a></li>
<li><a href="http://www.dudu.com" class="du">杜牧</a></li>
<li><b>杜小月</b></li>
<li><i>度蜜月</i></li>
<li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li>
</ul>
</div>
</body>
</html>
# 有了test.html文件后,就可以操作练习。
from bs4 import BeautifulSoup
fp = open('test.html', 'r')
# 1.创建一个BeautifulSoup的工具对象,然后把即将被解析的页面源码数据加载到该对象中
# 参数1:被解析的页面源码数据
# 参数2:固定形式的lxml(一种解析器)
soup = BeautifulSoup(fp, 'lxml')
# 2.可以调用BeautifulSoup对象的相关函数和属性进行标签定位和数据提取
''' 标签定位-方式1:soup.tagName(只可以定位到第一次出现的该标签) '''
title_tag = soup.title
p_tag = soup.p
''' 标签定位-方式2(属性定位):soup.find(tagName,attrName='value') '''
# 注意:find只可以定位满足要求的第一个标签,如果使用class属性值的话,find参数class_
# 定位到了class属性值为song的div标签
div_tag = soup.find('div', class_='song')
# 定位到class属性值为du的a标签
a_tag = soup.find('a', class_='du')
# 定位到了id的属性值为feng的a标签
a_tag = soup.find('a', id='feng')
''' 标签定位-方式3(属性定位):soup.find_all(tagName,attrName='value') '''
# 注意:find_all可以定位到满足要求的所有标签
tags = soup.find_all('a', class_='du')
''' 标签定位-方式4(选择器定位): '''
# 常用的选择器:class选择器(.class属性值) id选择器(#id的属性值)
tags = soup.select('#feng') # 定位到id的属性值为feng对应的所有标签
tags = soup.select('.du') # 定位到class属性值为du对应的所有标签
# 层级选择器:>表示一个层级 一个空格可以表示多个层
tags = soup.select('.tang > ul > li > a')
tags = soup.select('.tang a')
# print(tags)
''' 定位到标签内部数据的提取 '''
# 方式1:提取标签内的文本数据
# tag.string:只可以将标签直系的文本内容取出
# tag.text:可以将标签内部所有的文本内容取出
tag = soup.find('a', id='feng')
content = tag.string
div_tag = soup.find('div', class_='tang')
content = div_tag.text
# 方式2:提取标签的属性值 tag['attrName']
img_tag = soup.find('img')
img_src = img_tag['src']
print(img_src)
案例 - bs4碧血剑文本爬取
import requests
from bs4 import BeautifulSoup
import os
# 创建一个文件夹
dirName = 'xiaoshuo'
# exists(dirName):如果dirName文件夹存在返回True,否则返回False
if not os.path.exists(dirName):
os.mkdir(dirName)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
url = 'https://bixuejian.5000yan.com/'
response = requests.get(url=url, headers=headers)
# 设置响应对象的编码格式,处理中文乱码
response.encoding = 'utf-8'
page_text = response.text
# 数据解析
soup = BeautifulSoup(page_text, 'lxml')
# 解析章节的标题和章节的内容
a_list = soup.select('.paiban > li > a')
for a in a_list:
title = a.string
detail_url = a['href']
# 需要对详情页的url发请求,获取详情页的页面源码数据,解析其中的章节内容
rep = requests.get(url=detail_url, headers=headers)
rep.encoding = 'utf-8'
detai_page_text = rep.text
# 注意:重新给详情页创建一个解析对象
detail_soup = BeautifulSoup(detai_page_text, 'lxml')
div_tag = detail_soup.find('div', class_='grap')
content = div_tag.text
fileName = title + '.txt' # haha.txt
filePath = dirName + '/' + fileName # xiaoshuo/haha.txt
with open(filePath, 'w', encoding='utf-8') as fp:
fp.write(title + '\n' + content)
print(title, ':下载保存成功!!!')
2. Xpath
环境安装
pip install lxml
xpath解析的编码流程
- 1.创建一个etree类型的对象,然后把即将被解析的页面源码数据加载到该对象中
- 2.调用etree对象的xpath方法结合着不同形式的xpath表达式,进行标签定位和数据提取
xpath表达式如何理解?
- html中的标签是遵从树状结构的。
- 切记 :xpath表达式中不可以出现tbody标签,如果有直接将其删除跨过即可!
from lxml import etree
# 1.创建一个etree的工具对象,然后把即将被解析的页面源码数据加载到该对象中
tree = etree.parse('test.html') # etree.parse 解析本地数据
# 2.调用etree对象的xpath函数然后结合着不用形式的xpath表达式进行标签定位和数据提取
# xpath函数返回的是列表,列表中存储的是满足定位要求的所有标签
# /html/head/title定位到html下面的head下面的title标签
title_tag = tree.xpath('/html/head/title')
# //title在页面源码中定位到所有的title标签
title_tag = tree.xpath('//title')
''' 属性定位 '''
# 定位到所有的div标签
div_tags = tree.xpath('//div')
# 定位到class属性值为song的div标签 //tagName[@attrName='value']
div_tag = tree.xpath('//div[@class="song"]')
''' 索引定位://tag[index] '''
# 注意:索引是从1开始的
div_tag = tree.xpath('//div[1]')
''' 层级定位 '''
# /表示一个层级 //表示多个层级
a_list = tree.xpath('//div[@class="tang"]/ul/li/a')
a_list = tree.xpath('//div[@class="tang"]//a')
''' 数据提取 '''
# 1.提取标签中的文本内容:/text()取直系文本 //text()取所有文本
a_content = tree.xpath('//a[@id="feng"]/text()')[0]
div_content = tree.xpath('//div[@class="song"]//text()')
# 2.提取标签的属性值://tag/@attrName
img_src = tree.xpath('//img/@src')[0]
print(img_src)
案例 - 简历模板下载
'''
https://sc.chinaz.com/jianli/free.html
- 下载当前页所有的建立模板
- 简历名称+简历的下载链接
- 根据简历的下载链接 下载简历文件
- 根据下载地址下载的压缩包,压缩包是二进制的数据
'''
import requests
from lxml import etree
import os
# 创建一个文件夹
dirName = 'jianli'
# exists(dirName):如果dirName文件夹存在返回True,否则返回False
if not os.path.exists(dirName):
os.mkdir(dirName)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
url = 'https://sc.chinaz.com/jianli/free.html'
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
page_text = response.text
# 数据解析:简历的标题和详情页的url
tree = etree.HTML(page_text) # etree.HTML 解析从互联网请求下来的数据
div_list = tree.xpath('//div[@id="container"]/div')
for div in div_list:
# 局部数据解析:./表示局部的div表示的标签
title = div.xpath('./p/a/text()')[0] + '.rar'
detail_url = div.xpath('./p/a/@href')[0]
detail_response = requests.get(url=detail_url, headers=headers)
detail_page_text = detail_response.text
detail_tree = etree.HTML(detail_page_text)
# 简历的下载地址
download_url = detail_tree.xpath('//*[@id="down"]/div[2]/ul/li[1]/a/@href')[0]
# 请求下载到了简历压缩包数据(二进制形式)
data = requests.get(url=download_url, headers=headers).content
path = dirName + '/' + title
with open(path, 'wb') as fp:
fp.write(data)
print(title, '下载保存成功!')
案例 - 爬取空气质量数据网
'''
https://www.aqistudy.cn/historydata/
- 爬取热门城市和全部城市的名称
- 该网址不是安全链接,因此需要verify=False关闭安全认证
'''
# 第一种写法
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
url = 'https://www.aqistudy.cn/historydata/'
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
# 解析热门城市
hot_cities = tree.xpath('//div[@class="bottom"]/ul/li/a/text()')
# 解析全部城市
all_cities = tree.xpath('//div[@class="bottom"]/ul/div[2]/li/a/text()')
print('热门城市:', hot_cities)
print('全部城市:', all_cities)
# 第二种写法
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
url = 'https://www.aqistudy.cn/historydata/'
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
# xpath(表达式1 | 表达式2):满足表达式1或者表达式2的所有数据都会被定位提取到
cities = tree.xpath('//div[@class="bottom"]/ul/li/a/text() | //div[@class="bottom"]/ul/div[2]/li/a/text()')
print(cities)
案例 - (彼岸图)图片数据爬取
'''
http://pic.netbian.com/4kmeinv/
- 将爬取到的图片存储到指定的文件夹中
'''
#### 爬取一页数据 ####
from lxml import etree
import requests
import os
# 新建一个文件夹
dirName = 'girls'
if not os.path.exists(dirName): # 如果文件夹不存在,则新建,否则不新建
os.mkdir(dirName)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
url = 'https://pic.netbian.com/4kmeinv/index.html'
response = requests.get(url=url, headers=headers)
response.encoding = 'gbk'
page_text = response.text
# 数据解析:图片地址+图片名称
tree = etree.HTML(page_text) # HTML()专门用来解析网络请求到的页面源码数据
# 该列表中存储的是每一个li标签
li_list = tree.xpath('//div[@class="slist"]/ul/li')
for li in li_list:
# 局部解析:将li标签中指定的内容解析出来
img_title = li.xpath('./a/b/text()')[0] + '.jpg' # 左侧./表示xpath的调用者对应的标签
img_src = 'https://pic.netbian.com' + li.xpath('./a/img/@src')[0]
# 对图片发起请求,存储图片数据
img_data = requests.get(url=img_src, headers=headers).content
# girls/123.jpg
img_path = dirName + '/' + img_title
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_title, '下载保存成功!')
#### 爬取多页数据 ####
from lxml import etree
import requests
import os
# 新建一个文件夹
dirName = 'girls'
if not os.path.exists(dirName): # 如果文件夹不存在,则新建,否则不新建
os.mkdir(dirName)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
# 创建一个通用的url:除了第一页其他页码的通用url
url = 'https://pic.netbian.com/4kmeinv/index_%d.html'
for page in range(1, 6):
if page == 1:
new_url = 'https://pic.netbian.com/4kmeinv/index.html'
else:
new_url = format(url % page)
print('----------正在请求下载第%d页的图片数据----------' % page)
response = requests.get(url=new_url, headers=headers)
response.encoding = 'gbk'
page_text = response.text
# 数据解析:图片地址+图片名称
tree = etree.HTML(page_text) # HTML()专门用来解析网络请求到的页面源码数据
# 该列表中存储的是每一个li标签
li_list = tree.xpath('//div[@class="slist"]/ul/li')
for li in li_list:
# 局部解析:将li标签中指定的内容解析出来
img_title = li.xpath('./a/b/text()')[0] + '.jpg' # 左侧./表示xpath的调用者对应的标签
img_src = 'https://pic.netbian.com' + li.xpath('./a/img/@src')[0]
# 对图片发起请求,存储图片数据
img_data = requests.get(url=img_src, headers=headers).content
# girls/123.jpg
img_path = dirName + '/' + img_title
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_title, '下载保存成功!')
3. Parsel 模块
python 的一个强大的第三方库 Parsel,里面包含 Xpath,bs4,css,re等四种数据提取方式的一个整合强大的库。
parsel这个库可以解析HTML与XML,并支持Xpath与CSS选择器对内容的提取和修改,同时也支持正则表达式的提取功能。parsel是Python最流行的爬虫框架scrapy的底层支持。
pip install parsel
CSS
在 CSS 中,选择器是一种模式,用于选择需要添加样式的元素。那么我们就可以使用css选择器,在html中找到数据所对应的标签。此方式也是一个专门在html中提取数据的方法。
| 选择器 | 例子 | 描述 |
|---|---|---|
| .class | .intro | 选择 class=“intro” 的所有元素 |
| #id | #firstname | 选择 id=“firstname” 的所有元素 |
| * | * | 选择所有元素 |
| element | p | 选择所有 元素 |
| element,element | div,p | 选择所有
元素和所有
元素 |
| element element | div p | 选择
元素内部的所有
元素 |
| element > element | div>p | 选择父元素为
元素的所有
元素 |
| [attribute] | [target] | 选择带有 target 属性所有元素 |
标签选择器
标签选择器其实就是我们经常说的html代码中的标签。例如html、span、p、div、a、img等等;比如我们想要设置网页中的p标签内一段文字的字体和颜色,那么css代码就如下所示:
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top python">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<div id="contend">具有id属性的标签</div>
<span> 我是一个span标签</span>
<li class="top" id="res">组合选择器</li>
</body>
</html>
"""
import parsel # 数据解析模块, 第三方, pip install parsel
# 1. 转化对象
selector = parsel.Selector(html) # Selector 就具有一系列数据解析的方法 css/xpath
print(selector)
# 2. 解析数据
"""标签选择器"""
# 所有通过css选择则器解析出来的数据都是一个对象(Selector)
# p 代表根据标签的名字做定位, 叫做标签选择器
# get() 从 Selector 对象中提取第一个数据, 直接返回字符串数据给我们
# result = selector.css('p').get()
# getall() 从 Selector 对象中提取提取所有数据, 返回一个列表
result = selector.css('p').getall()
print(result)
print('-' * 100 + '\n')
类选择器
类选择器在我们今后的css样式编码中是最常用到的,它是通过为元素设置单独的class来赋予元素样式效果。使用语法:(我们这里为p标签单独设置一个class类属性,代码就如下所示)
import parsel # 数据解析模块, 第三方, pip install parsel
# 1. 转化对象
selector = parsel.Selector(html) # Selector 就具有一系列数据解析的方法 css/xpath
print(selector)
# 2. 解析数据
"""类选择器"""
# . 代表提取标签的类型(class)
# 具有相同类属性的标签都会被提取
# 类选择器是通过标签的类属性(class属性)精确定位到你想要的标签
result2 = selector.css('.top').getall()
print(result2)
# 如果类属性值是带空格的, 那么空格需要用 . 代替
result3 = selector.css('.top .python').getall()
print(result3)
print('-' * 100 + '\n')
ID选择器
ID选择器类似于类选择符,作用同类选择符相同,但也有一些重要的区别。
"""ID选择器"""
# '#' 使用 id 选择器提取数据
# contend 代表 id 属性的属性值
# id 在 html中一般是唯一的
result4 = selector.css('#contend').getall()
print(result4)
print('-' * 100 + '\n')
组合选择器
可以多个选择器一起使用,就是组合选择器
"""组合选择器"""
# 组合选择器主要是加约束
result5 = selector.css('li#res.top').getall()
print(result5)
# 如果使用组合选择器, 标签选择器必须放最前面
result5 = selector.css('li#res.top').getall()
print(result5)
result5 = selector.css('li.top#res').getall()
print(result5)
"""
以上选择器的作用是用于做定位
"""
伪类选择器
可以用
:指定选择想要提取的第几个标签
| 语法 | 示例 | 描述 |
|---|---|---|
| :last-of-type | p:last-of-type | 选择满足p语法元素的最后一个元素 |
| :not(selector) | :not§ | 选择所有p以外的元素 |
| :nth-child(n) | p:nth-child(2) | 选择满足p语法元素的第二个元素 |
| :nth-last-child(n) | p:nth-last-child(2) | 选择满足p语法元素的倒数的第二个元素 |
import parsel
# 1. 转化对象
selector = parsel.Selector(html)
print(selector)
# 2. 解析数据
# : 表示伪类选择器
# nth-child 满足标签的第几个元素
# (1) 选择满足标签的第二个元素, 类似索引, 从1开始取
# 伪类主要是在同级标签中定位到指定的第几个
result = selector.css('p:nth-child(2)::text').getall()
print(result)
案例 - css解析小说1
import parsel
import requests
url = 'https://www.bqg78.com/book/1031/1.html'
response = requests.get(url=url)
html_data = response.text
print(html_data) # 在解析数据前, 一定要打印数据查看是否请求到了
selector = parsel.Selector(html_data)
title = selector.css('h1.wap_none').getall()
print(title)
contend = selector.css('#chaptercontent').getall()
print(contend)
提取属性和文本数据
可以用
::提取标签包含的属性
# 简化的html标签
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标签选择器</title>
</head>
<style>
p{
color: #f00;
font-size: 16px;
}
</style>
<body>
<p class="top python">css标签选择器的介绍</p>
<p class="top">标签选择器、类选择器、ID选择器</p>
<a href="https://www.baidu.com">百度一下</a>
<div id="contend">具有id属性的标签</div>
<span> 我是一个span标签</span>
<li class="top" id="res">组合选择器</li>
</body>
</html>
"""
import parsel
# 1. 转化对象
selector = parsel.Selector(html)
print(selector)
# 2. 解析数据
# :: 表示属性选择器, 当你提取到标签之后, 需要对标签特定的值进行提取(标签包含的文本内容, 标签的属性)
result = selector.css('a::text').getall()
print(result)
# ::attr(href) 根据标签中包含的属性名字提取属性值
# href a标签属性的名字
result = selector.css('a::attr(href)').getall()
print(result)
案例 - css解析小说2
import parsel
import requests
url = 'https://www.bqg78.com/book/1031/1.html'
response = requests.get(url=url)
html_data = response.text
print(html_data) # 在解析数据前, 一定要打印数据查看是否请求到了
selector = parsel.Selector(html_data)
title = selector.css('h1.wap_none::text').getall()
print(title)
contend = selector.css('#chaptercontent::text').getall()
print(contend)
案例 - 解析小说二次提取
import parsel
import requests
url = 'https://www.bqg78.com/book/1031/'
response = requests.get(url=url)
html_data = response.text
print(html_data) # 在解析数据前, 一定要打印数据查看是否请求到了
selector = parsel.Selector(html_data)
# 第一次数据提取: 取所有符合条件的标签
dds = selector.css('.listmain dd') # 取所有的dd标签
print(dds)
# 第二次提取: 在标签中中取多次结果
for dd in dds:
title = dd.css('a::text').get()
href = dd.css('a::attr(href)').get()
print(title, href)
案例 - 微医网css解析
import parsel
import requests
url = 'https://www.guahao.com/expert/61409/%E5%86%85%E7%A7%91'
response = requests.get(url=url)
html_data = response.text
# 在解析数据前, 一定要打印查看数据是请求到了
# print(html_data)
selector = parsel.Selector(html_data)
lis = selector.css('.g-doctor-items.to-margin>ul>li')
for li in lis:
doctor_name = li.css('.wrap>a::text').get()
doctor_level = li.css('dl>dt::text').getall()[1].strip()
doctor_kind = li.css('dd>p:nth-child(1)::text').get()
doctor_Belonging = li.css('dd>p:nth-child(2)>span::text').get()
doctor_score = li.css('.star>em::text').get()
doctor_inquiry = li.css('.star-count>span:nth-child(2)>i::text').get()
doctor_goodFor = li.css('.skill>p::text').get().strip().replace('\n', '').replace(' ', '')
result = li.css('.star-count>span:nth-child(1)::text').get()
print(result)
Xpath
什么是xpath
XPath (XML Path Language)是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML 文档中对元素和属性进行遍历。W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
html和xml的区别

html_str = """
<div>
<ul>
<li class="item-1">
<a href="link1.html">第一个</a>
</li>
<li class="item-2">
<a href="link2.html">第二个</a>
</li>
<li class="item-3">
<a href="link3.html">第三个</a>
</li>
<li class="item-4">
<a href="link4.html">第四个</a>
</li>
<li class="item-5">
<a href="link5.html">第五个</a>
</li>
</ul>
</div>
"""
import parsel
# # 转换数据类型, 能够把缺失的html标签补充完整
selector = parsel.Selector(html_str)
# print(selector)
# # selector.xpath()
"""根节点的使用"""
result = selector.xpath('/html/body/div/ul/li/a').getall()
print(result)
"""
xpath语法规则中
/ 表示从根节点开始提取(用得少),还表示取下一级标签
如果你打算从根节点提取, 那么必须从html这个节点开始提取
"""
print('-' * 100 + '\n')
"""跨节点的使用"""
result2 = selector.xpath('//a').getall()
result3 = selector.xpath('/html//a').getall()
print(result2)
print(result3)
"""
xpath语法规则中(用的极多)
// 表示跨节点提取, 而不用考虑节点位置
"""
print('-' * 100 + '\n')
"""选取当前节点"""
# 选中<ul>标签, 然后提取<ul>标签下面所有的<li>标签
result = selector.xpath('//ul')
result4 = result.xpath('./li').getall()
print(result4)
"""
xpath语法规则中
. 表示取当前节点
使用场景: 需要对选取的标签进行二次提取的时候,需要用到 .
"""
print('-' * 100 + '\n')
"""选取当前节点的父节点"""
# 选取<a>节点的父节点
result = selector.xpath('//a')
result5 = result.xpath('..').getall()
print(result5)
"""
xpath语法规则中
.. 表示取当前节点的父节点(用的极少)
"""
print('-' * 100 + '\n')
"""@属性定位和属性取值"""
# 获取第四个<a>标签, 并获取其href属性值
result = selector.xpath('//a[@href="link4.html"]').getall()
print(result)
result = selector.xpath('//a[@href="link4.html"]/@href').getall()
print(result)
"""
xpath语法规则中
@ 有两个用途
1. 根据标签特有的属性(class,href,src,id,title等等)精确定位到想要的标签
2. 可以根据已经定位好的标签, 指定标签内属性的名字, 获取属性值
"""
print('-' * 100 + '\n')
"""获取标签包含的文本内容"""
# 获取第四个<a>标签, 取其包含的文本内容
result = selector.xpath('//a[@href="link4.html"]/text()').getall()
print(result)
"""
xpath语法规则中
text() 作用在于获取指定标签后, 可以提取标签包含的文本内容
"""
print('-' * 100 + '\n')
"""同级标签精确定位"""
# 获取第三个li标签的节点
result = selector.xpath('//li[3]').getall()
print(result)
"""
xpath语法规则中
对于获取到的多个标签, 可以用 [] 精确定位获取标签的第几个
[] 内部填标签的排列的顺序, 类似于索引取值, 索引从1开始
"""
print('-' * 100 + '\n')
"""多条件查询"""
# 获取所有<li>标签的属性值和<a>标签包含的文本, 只能使用一行 xpath 解决
result = selector.xpath('//li/@class|//a/text()').getall()
print(result)
"""
xpath语法规则中
| 表示多条件查询, 左右两边分别是两个条件, 满足其中一个条件的标签都会被找到(逻辑或)
用的不多
"""
print('-' * 100 + '\n')
案例 - xpath采集图片
import os.path
import re
import parsel
import requests
def change_title(title):
pattern = re.compile("[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
url = 'https://www.jdlingyu.com/dm/zb'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}
response = requests.get(url=url, headers=headers)
html_data = response.text
# print(html_data)
# 解析数据
selector = parsel.Selector(html_data)
lis = selector.xpath('//div[@id="post-list"]/ul/li')
for li in lis:
# xpath语法中二次提取一定要加.
pic_title = li.xpath('.//h2/a/text()').get()
pic_href = li.xpath('.//h2/a/@href').get()
print(pic_title, pic_href)
new_title = change_title(pic_title)
if not os.path.exists('img\\' + new_title):
os.mkdir('img\\' + new_title)
# 发送相册详情页请求, 因为图片地址在详情页
response_pic = requests.get(url=pic_href, headers=headers).text
# 解析详情页地址
selector_pic = parsel.Selector(response_pic)
# 提取详情页所有地址
pic_url_list = selector_pic.xpath('//div[@class="entry-content"]//img/@src').getall()
for pic_url in pic_url_list:
pic_data = requests.get(url=pic_url, headers=headers).content # 请求图片数据
# 文件名
file_name = pic_url.split('/')[-1]
with open(f'img\\{new_title}\\{file_name}', mode='wb') as f:
f.write(pic_data)
print('下载完成:', file_name)
案例 - 豆瓣250
"""
使用 css 选择器将豆瓣250 十页的全部电影信息全部提取出来。
目标网址:https://movie.douban.com/top250
title(电影名)
info(导演、主演、出版时间)
score(评分)
follow(评价人数)
提取出来print()打印即可
"""
import parsel
import requests
for page in range(0, 226, 25):
url = f'https://movie.douban.com/top250?start={page}&filter='
headers = {
'Cookie': 'll="118267"; bid=VrC8tT1GWz8; __yadk_uid=iHqVKZD4ZHIVREbOrlu9k4uWFSsAdZtO; _pk_id.100001.4cf6=b39d476add4f5658.1683638062.; __utmz=30149280.1687782730.8.7.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmz=223695111.1687782730.4.4.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1687952054%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DqdlD_RZvrHI0sXUZ08wSSKbkKLAWA_R84aALUkbWwp__yA2hUL-2C_Ej15saTpe7%26wd%3D%26eqid%3Dfdfaeaeb0001b3f60000000664998548%22%5D; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.1169382564.1682168622.1687782730.1687952054.9; __utmb=30149280.0.10.1687952054; __utmc=30149280; __utma=223695111.1640817040.1683638062.1687782730.1687952054.5; __utmb=223695111.0.10.1687952054; __utmc=223695111; __gads=ID=744f53c3cb2ebb52-22841ef3a4e00021:T=1683638065:RT=1687952056:S=ALNI_MZhRKuML1OBDnNRafe3qd6-ndhaiQ; __gpi=UID=00000c03bafcda5c:T=1683638065:RT=1687952056:S=ALNI_MbkLLsUm467wiS6ZZ6Mn2ohKIWBZw',
'Host': 'movie.douban.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.text
# print(html_data)
"""解析数据"""
# 转对象
selector = parsel.Selector(html_data)
# 第一次提取
lis = selector.css('.grid_view>li')
# 二次提取
for li in lis:
title = li.css('.hd>a>span:nth-child(1)::text').get()
info = li.css('.bd>p:nth-child(1)::text').getall()
info = '//'.join([i.strip() for i in info])
score = li.css('.rating_num::text').get()
follow = li.css('.star>span:nth-child(4)::text').get()
print(title, info, score, follow)
print('=' * 100 + '\n')
案例 - 穷游网
"""
目标网址: https://place.qyer.com/china/citylist-0-0-1/
需求:
1、用xpath采集数据
2、采集以下信息
city_name # 城市名
travel_people # 去过的人数
travel_hot # 热门景点
img_url # 城市图片url
解析到数据用print()函数打印即可
请在下方编写代码:
"""
import parsel
import requests
url = f'https://place.qyer.com/china/citylist-0-0-1/'
response = requests.get(url=url)
html_data = response.text
print(html_data)
selector = parsel.Selector(html_data)
lis = selector.xpath('//*[@class="plcCitylist"]/li')
for li in lis:
city_name = li.xpath('.//h3/a/text()').get()
travel_people = li.xpath('.//*[@class="beento"]/text()').get()
travel_hot = li.xpath('.//*[@class="pois"]/a/text()').getall()
travel_hot = '-'.join([i.strip() for i in travel_hot])
img_url = li.xpath('.//*[@class="pics"]//img/@src').get()
print(city_name, travel_people, travel_hot, img_url)
正则表达式
text = """
回复(2)4楼2018-07-04 11:48
哥哥口袋有糖
初识物联1
346504108@qq.com
收起回复5楼2018-07-04 14:10
Super劫Zed: 540775360@qq.com
2018-8-8 16:00回复
我也说一句
RAVV2017
物联硕士4
以上的邮箱,已发,还需要的请回复邮箱。两套物联网学习资料。
回复(4)7楼2018-07-04 16:06
儒雅的刘飞3
初识物联1
397872410@qq.com,谢谢楼主
收起回复8楼2018-07-04 16:20
RAVV2017: 已发送,麻烦请查收,谢谢
2018-7-4 16:23回复
我也说一句
"""
import re # 内置模块, 正则表达式模块
"""
pattern 正则表达式的匹配规则, 根据规则在字符串中匹配数据
string 需要匹配的字符串
flags 默认参数, 匹配模式
"""
result = re.findall('Super劫Zed: (.*?)@qq.com', text)
print(result) # re.findall返回的结果是一个列表
元字符
text = """
回复(2)4楼2018-07-04 11:48
哥哥口袋有糖
初识物联1
346504108@qq.com
收起回复5楼2018-07-04 14:10
Super劫Zed: 540775360@qq.com
2018-8-8 16:00回复
我也说一句
RAVV2017
物联硕士4
以上的邮箱,已发,还需要的请回复邮箱。两套物联网学习资料。
回复(4)7楼2018-07-04 16:06
儒雅的刘飞3
初识物联1
397872410@qq.com,谢谢楼主
收起回复8楼2018-07-04 16:20
RAVV2017: 已发送,麻烦请查收,谢谢
2018-7-4 16:23回复
我也说一句_
"""
import re
# 默认情况下一个元字符只能匹配到一个字符串
"""
. 在默认情况下, 可以匹配除了换行符以外的任意字符
re.S 匹配模式, 能够让 . 匹配到换行符
"""
# 在元字符的前后加字符串的约束, 那么匹配的数据也要满足约束条件
# 如果有字符串即满足约束条件也满足元字符规则, 那么就会被匹配到
# 如果没有字符串满足正则表达式规则, 那么就会返回空列表
result = re.findall('Super劫Zed: .................', text, re.S)
print(result)
"""
\d 匹配一个数字字符
\D 匹配一个非数字字符
"""
result = re.findall('Super劫Zed: \d\d\d\d\d\d\d\d\d', text)
print(result)
result = re.findall('Super劫Zed: \d\d\d\d\d\d\d\d\d\D\D\D\D\D\D\D', text)
print(result)
"""
\s 匹配一个空白字符(换行,空格,\t, tab键)
\S 匹配一个非空白字符
"""
result = re.findall('\s', text)
print(result)
result = re.findall('\S', text)
print(result)
"""
\w 匹配一个单词字符, 即a-z、A-Z、0-9、_、包括各个国家语言文字
\W 匹配一个非单词字符
"""
result = re.findall('\w', text)
print(result)
result = re.findall('\W', text)
print(result)
"""
+ 匹配前一个字符一次或者多次(最少要出现一次)
* 匹配前一个字符零次或者多次(最少可以是零次)
.+ 匹配一次或者多次
.* 匹配零次或者多次
"""
result = re.findall('Super劫Zed: .\d+', text)
print(result)
result = re.findall('Super劫Zed: \d*\D*', text)
print(result)
result = re.findall('Super劫Zed: \s+', text)
print(result)
result = re.findall('Super劫Zed: \s*', text)
print(result)
贪婪匹配和非贪婪匹配
text = """
回复(2)4楼2018-07-04 11:48
哥哥口袋有糖
初识物联1
346504108@qq.com
收起回复5楼2018-07-04 14:10
Super劫Zed: 540775360@qq.com
Super劫Zed: 254551236@qq.com
Super劫Zed: 654545454@qq.com
2018-8-8 16:00回复
我也说一句
RAVV2017
物联硕士4
以上的邮箱,已发,还需要的请回复邮箱。两套物联网学习资料。
"""
import re
result = re.findall('Super劫Zed: \d+@qq.com', text, re.S)
print(result)
"""
贪婪匹配: 默认匹配模式, 会尽可能的在满足规则的前提下, 多匹配数据
? 匹配1次或者0次
.* 匹配除了换行符以外的任意字符, 默认是贪婪模式
.*? 非贪婪匹配, 在符合规则的前提下, 匹配一次返回一次
"""
result = re.findall('Super劫Zed: .*@qq.com', text)
print(result)
result = re.findall('Super劫Zed: .*?@qq.com', text, re.S)
print(result)
精确匹配
text = """
回复(2)4楼2018-07-04 11:48
哥哥口袋有糖
初识物联1
346504108@qq.com
收起回复5楼2018-07-04 14:10
Super劫Zed: 540775360@qq.com
Super劫Zed: 254551236@qq.com
Super劫Zed: 654545454@qq.com
2018-8-8 16:00回复
我也说一句
RAVV2017
物联硕士4
以上的邮箱,已发,还需要的请回复邮箱。两套物联网学习资料。
"""
import re
"""
精确匹配: 先根据正则语法规则匹配数据, 然后提取()内的数据部分
() 表示精确匹配
"""
result = re.findall('Super劫Zed: (.*?)@qq.com', text, re.S)
print(result)
数量词
text = """
回复(2)4楼2018-07-04 11:48
哥哥口袋有糖
初识物联1
346504108@qq.com
收起回复5楼2018-07-04 14:10
Super劫Zed: 54077@qq.com
Super劫Zed: 254551@qq.com
Super劫Zed: 6545454@qq.com
2018-8-8 16:00回复
我也说一句
RAVV2017
物联硕士4
以上的邮箱,已发,还需要的请回复邮箱。两套物联网学习资料。
"""
import re
result = re.findall('Super劫Zed: \d{5}@qq.com', text, re.S)
print(result)
result = re.findall('Super劫Zed: \d{6}@qq.com', text, re.S)
print(result)
# {start,stop} 表示数量词, 限制前一个字符的匹配数量, 闭区间
result = re.findall('Super劫Zed: \d{5,6}@qq.com', text, re.S)
print(result)
字符集
text = """
回复(2)4楼2018-07-04 11:48
哥哥口袋有糖
初识物联1
346504108@qq.com
收起回复5楼2018-07-04 14:10
Super劫Zed: 54077@qq.com
Super劫Zed: 54078@qq.com
Super劫Zed: 254551@qq.com
Super劫Zed: 6545454@qq.com
2018-8-8 16:00回复
我也说一句
RAVV2017
物联硕士4
以上的邮箱,已发,还需要的请回复邮箱。两套物联网学习资料。
"""
import re
# 一个[]只能匹配一个字符串, 只有字符集里面罗列的内容才可以匹配到
result = re.findall('Super劫Zed: [0123456789]*@qq.com', text)
print(result)
result = re.findall('Super劫Zed: [0-9]*@qq.com', text)
print(result)
result = re.findall('Super劫Zed: [a-zA-Z0-9]*@qq.com', text)
print(result)
result = re.findall('[:1]', text)
print(result)
"""
.*? 站位
(.*?) 精确匹配
"""
re.match
import re
string = 'PythonahsdgjasghPythonasdjajsk'
# re.match 匹配字符串中第一个内容, 如果字符串的最前面没有你要查找的内容就会报错, 只会找头部
# result 得到的结果是一个对象, 用group()在对象中把数据取出来
result = re.match('Python', string)
print(result)
print(result.group())
re.search
import re
string = ' PythonahsdgjasghPythonasdjajsk'
# re.search 可以在字符串中的任意位置查找指定的字符串, 找到了就返回, 有且仅返回一次数据
result = re.search('Python', string)
print(result)
print(result.group())
# 192.168.0.1
re.split
import re
"""
pattern 匹配规则
string 匹配的字符串
maxsplit 最大分割次数
flags 匹配模式
"""
string = 'Pythonasdkjasd 464654 adhuiaghsdk 564654 akjsdhkashdkja'
result = re.split('\d+', string)
print(result)
result = re.split('\d+', string, maxsplit=1)
print(result)
re.compile
import re
str1 = "540775360@qq.com"
str2 = "python = 9999, c = 7890, c++ = 12345"
str3 = "python = 997"
# re.compile 将正则表达式规则编译成一个对象
# 在python解释器底层, 首先会对正则表达式语法进行编译
# 已经编译好的正则对象, 在python解释器底层就不会编译了
# 编译好的对象可以重复多次使用
pattern = re.compile('\d+')
print(pattern)
result = re.findall(pattern, str1)
print(result)
result = re.findall(pattern, str2)
print(result)
result = re.findall(pattern, str3)
print(result)
re.sub
import re
"""
pattern 匹配规则
repl 匹配到的数据需要替换成什么--> (可以是字符串, 也可以是函数规则)
string 在哪里匹配
count 替换次数
flags 匹配模式
"""
string = 'Pythonasdkjasd Java adhuiaghsdk Java akjsdhkashdkja'
# 字符串的替换方法
result = re.sub('Java', 'python牛逼', string)
print(result)
result = re.sub('Java', 'python牛逼', string, count=1)
print(result)
def func(x):
print('匹配到的数据会放到此参数当中来:', x.group())
return x.group().replace('a', '@')
result = re.sub('Java', func, string, count=1)
print(result)
# re.finditer()
案例 - 匹配特殊字符
import re
html = """
<script type="text/javascript">
var fp = new FlexPaperViewer(
'http://bulletin.sntba.com/FlexPaperViewer',
'viewerPlaceHolder', {
config : {
SwfFile : escape('http://bulletin.sntba.com/project//2020-01/noticeFile/Z6101002181N01555001/8aa946a756a24b09aded43c7bdd5f348.swf'),
EncodeURI : true,
Scale : 0.6,
ZoomTransition : 'easeOut',
ZoomTime : 0.5,
ZoomInterval : 0.05,
FitPageOnLoad : true,
FitWidthOnLoad : true,
PrintEnabled: false,//是否支持打印
FullScreenAsMaxWindow : false,
ProgressiveLoading : true,
MinZoomSize : 0.05,
MaxZoomSize : 5,
SearchMatchAll : false,
InitViewMode : 'Portrait',
ViewModeToolsVisible : true,
ZoomToolsVisible : true,
NavToolsVisible : true,
CursorToolsVisible : true,
SearchToolsVisible : false,
localeChain : 'zh_CN'
}
});
</script>
"""
# SwfFile : escape('(.*?)'),
"""
在字符串中, 如果出现了元字符, 会影响我们匹配数据,
因为元字符在正则表达式中有特殊含义, 所以需要在正则表达式中对元字符转义
"""
result = re.findall("SwfFi.*?scape\('(.*?)'\),", html, re.S)
print(result)
匹配开头和结尾
import re
email_list = ["xiaoWang@163.com", "xiaoWang@163.comheihei", ".com.xiaowang@qq.com"]
for email in email_list:
result = re.match('^\w*@163.com$', email)
if result:
print(f'{email} 是规范的邮箱地址, 地址是{result.group()}')
else:
print(f'{email} 不是规范的邮箱地址')
# {'你好': '你好python/www.baidu.com/你很好'}{'你好': '你好python/www.douban.com/你不好'}
案例 - 正则练习
"""
删除 xml_str 字符串里面多余的空行。并将每一行字符串内容顶格输出
"""
xml_str = """<?xml version="1.0" encoding="UTF-8"?>
<TowerRouteTask>
<FileVer>TowerRouteTask-1.0</FileVer>
<CreateTime>2020-05-09 13:47</CreateTime>
<TaskName>崇玉线_04#</TaskName>
<TowerNum>1</TowerNum>
<PointNum>17</PointNum>
<UseRtk>true</UseRtk>
</TowerRoute>
</TowerRouteTask>"""
"""在下方实现代码"""
import re
# result = re.sub('\t', '', xml_str)
# # print(result)
# result2 = re.sub('\n+', '\n', result)
# print(result2)
# \s
# {2,} --> 限制最少出现2次, 最多没有线
# result = re.sub('\s{2,}', '\n', xml_str)
# print(result)
result = re.sub('[\t\n]+', '\n', xml_str)
print(result)
案例 - 电话加密
"""
根据下方出现的电话号码进行加密
需求:
最终效果: 181****5458
请用正则表达式解决
"""
import re
# 方法一
def func(x):
# print(x)
str_ = x.group()
return str_[:3] + '****' + str_[-4:]
tel = "18123115458"
result = re.sub('\d{11}', func, tel)
print(result)
# 方法二
tel = "18123115458"
result = re.sub('\d{11}', lambda x: x.group()[:3] + '****' + x.group()[-4:], tel)
print(result)
# 方法三
tel = "18123115458"
# 分组匹配
# (\d{3}) 分组一 (\d{4}) 分组二 (\d{4}) 分组三
# \\1 取分组一
result = re.sub('(\d{3})(\d{4})(\d{4})', '\\1****\\3', tel)
print(result)
案例 - 正则解析 Json 数据
"""
1. 采集网址 https://haokan.baidu.com/tab/gaoxiao_new
2. 采集目标
- 采集当前页面里面的数据
- 需要需要采集以下数据:
title 视频标题
duration 视频时长
fmplaycnt 播放量
- 用正则表达式采集
"""
import re
import requests
url = 'https://haokan.baidu.com/web/video/feed?tab=gaoxiao_new&act=pcFeed&pd=pc&num=23&shuaxin_id=16881261110000'
headers = {
'Cookie': 'BIDUPSID=A8D9EA340531252B16551CBD43A8D395; PSTM=1681976911; BAIDUID=A8D9EA340531252BDEF2C13A73AFA5E7:FG=1; H_WISE_SIDS=131862_114552_216844_213346_214803_219942_110085_243887_244712_249892_256348_256447_256739_254317_257586_257996_258372_258375_230288_259102_259287_258772_234207_234295_253022_260335_260806_259299_253631_261575_261718_261459_261983_259782_260440_261793_259629_236312_262490_262452_261869_262607_262677_262597_262604_249411_259519_259948_262743_262746_262913_263190_256998_263221_263306_263279_243615_263343_261683_263434_254299_261411_263584_257289_262439_262533_263644_262408_262910_257169_262289_263906_263363_256419_264175_264089_264228_257442_256225_262260_255224_264018_264368_259558_256083_264383_264423_264452_264285_256152_264626_264246_258698_264749_261934_264820_264136_261035_261663; ZFY=CMMricp5SfogOfi1RswFaP4NBZN6t5zy:Axurblw8al4:C; BAIDUID_BFESS=A8D9EA340531252BDEF2C13A73AFA5E7:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BA_HECTOR=800lag2h0hahag258401000m1i9qvr81p; H_PS_PSSID=36550_38860_38958_38956_38918_38802_38640_26350; Hm_lvt_4aadd610dfd2f5972f1efee2653a2bc5=1688126064; Hm_lpvt_4aadd610dfd2f5972f1efee2653a2bc5=1688126112; ariaDefaultTheme=undefined; ab_sr=1.0.1_MjgyMzZjN2IxMjY5NzIyYzY2ZWQ2NTAzNGQ2YTcwNzRmZDczYjM5NDZiMDdkMGE0YWQyNTQ1YWVjN2YzNzExYmIyMmFlMjcyYzk2YzJjNjMyM2JjMDVhNDE5NDYyNTQ3MTM2MmU5M2Y1NDZlODYyNjg3YzlhODY0OWEwMGFlMzJjMTE5YzI4NDdhZDMyNzQ4MDA1YmYwZTE5YmNhMDkwZA==; reptileData=%7B%22data%22%3A%2287bae13ee8ed99ddf87f67f1f31fdf4ce6014e09f0fe8e757434c4500b3b88612312e5a033baaef9b71a836a58b6f53f35de74fc20152f9f3cb09bab3f2e4594dee3f7002bdc220ab39023b9f7742f316ca7e0e203afad9be69125ddc36dc865%22%2C%22key_id%22%3A%2230%22%2C%22sign%22%3A%22b50b7367%22%7D; RT="z=1&dm=baidu.com&si=0ea9a6fe-6353-4f02-829c-8039b1c56a1b&ss=ljiio6p3&sl=2&tt=31r&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=13gd&nu=47t5yjyw&cl=1b5h"',
'Authority': 'haokan.baidu.com',
'Referer': 'https://haokan.baidu.com/tab/gaoxiao_new',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
json_data = response.json()
print(json_data)
print(type(json_data))
json_data = str(json_data)
# {'id': '9266673592642073145', 'title': '分手的原因终于找到了,原来是一起挂的同心圆被别人给剪啦!', 'poster_small': 'https://f7.baidu.com/it/u=2557173170,2348383163&fm=222&app=106&f=JPEG@s_0,w_660,h_370,q_80', 'poster_big': 'https://f7.baidu.com/it/u=2557173170,2348383163&fm=222&app=106&f=JPEG@s_0,w_660,h_370,q_80', 'poster_pc': 'https://f7.baidu.com/it/u=2557173170,2348383163&fm=222&app=106&f=JPEG@s_0,w_660,h_370,q_80,f_auto', 'source_name': '就这么搞笑', 'play_url': 'http://vd4.bdstatic.com/mda-pdc4ueypmq7b5isj/cae_h264/1681516229583661512/mda-pdc4ueypmq7b5isj.mp4?v_from_s=hkapp-haokan-nanjing', 'duration': '01:04', 'url': 'https://haokan.hao123.com/v?vid=9266673592642073145&pd=pc&context=', 'show_tag': 0, 'publish_time': '04月13日', 'is_pay_column': 0, 'like': '1', 'comment': '5', 'playcnt': '84', 'fmplaycnt': '84次播放', 'fmplaycnt_2': '84', 'outstand_tag': '', 'previewUrlHttp': 'https://vd4.bdstatic.com/mda-pdc4ueypmq7b5isj/cae_h264/1681516229583661512/mda-pdc4ueypmq7b5isj.mp4?v_from_s=hkapp-haokan-nanjing&auth_key=1688128351-0-0-55ae631ce80b6d3563a979677b4e18ef&bcevod_channel=searchbox_feed&pd=1&vt=1&cd=0&watermark=0&logid=0151184955&vid=9266673592642073145&pt=4&cr=0&sle=1&sl=573&split=501264', 'third_id': '1760852045386443', 'vip': 0, 'author_avatar': 'https://gips0.baidu.com/it/u=3423469398,1093432278&fm=3012&app=3012&autime=1687938807&size=b200,200&fmt=auto'},
# {'id': '.*?', 'title': '(.*?)',.*?'duration': '(.*?)',.*?'fmplaycnt': '(.*?)',.*?},
# \{'id': '.*?', 'title': '(.*?)',.*?'duration': '(.*?)',.*?'fmplaycnt': '(.*?)',.*?\},
result = re.findall("\{'id': '.*?', 'title': '(.*?)',.*?'duration': '(.*?)',.*?'fmplaycnt': '(.*?)',.*?\},", json_data)
print(result)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 快乐学Python,数据分析之获取数据方法「公开数据或爬虫」
- 【Java】面向对象程序设计 期末复习总结
- 内网环境横向移动——横向移动威胁
- 未进行信道估计和进行最小二乘(LS)估计后的误比特(Matlab)
- OpenShift 4 - 管理和使用 OpenShift AI 运行环境
- LLM 和搜索引擎是一样的吗?
- Copilot插件:开启AI编程新篇章
- 工业信息采集平台 软件界面介绍
- 使用WAF防御网络上的隐蔽威胁之代码执行攻击
- The most simple way to use Postman