机器学习中基于树的模型
掌握机器学习中基于树的模型:决策树、随机森林和 GBM 的实用指南

作者在Canva上创作的图片
一、说明
????????有没有想过机器是如何做出复杂决策的?就像一棵树分叉一样,机器学习中基于树的模型也做了类似的事情。它们是人工智能决策过程的支柱。
????????在接下来的几节中,我们将探讨不同类型的基于树的模型。我们从基础开始:决策树。然后,我们扩展到随机森林和梯度提升机器。每个都有其独特的处理数据和决策的方式。
????????但是,这些模型如何应用于实际场景呢?从财务分析到医疗保健预测,基于树的模型具有重大影响。最后,我们还将看到障碍及其解决方案。让我们开始吧!
二、基于树的模型的类型
????????在本节中,我们将探讨机器学习中基于树的模型。我们从决策树开始,了解它们的基础知识和功能。接下来,我们将讨论随机森林及其相对于单个决策树的优势。
????????最后,我们研究了梯度提升机(GBMs),重点关注它们的独特之处以及与随机森林的比较。本概述将向您介绍基于树的关键模型。
三、决策树
????????机器学习中的决策树就像流程图,根据数据做出决策。它们在需要清晰、合乎逻辑的决策的场景中特别有用。
????????对于我们的 Python 示例,我们将使用 scikit-learn 中著名的鸢尾花数据集,其中包括鸢尾花及其物种的测量值。我们将根据这些测量结果预测物种。我们还将对树进行可视化,以了解决策是如何做出的。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Create and train the decision tree
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# Visualize the decision tree
plt.figure(figsize=(20,10))
plot_tree(model, filled=True, feature_names=iris.feature_names, class_names=list(iris.target_names))
plt.show()让我们看看输出。
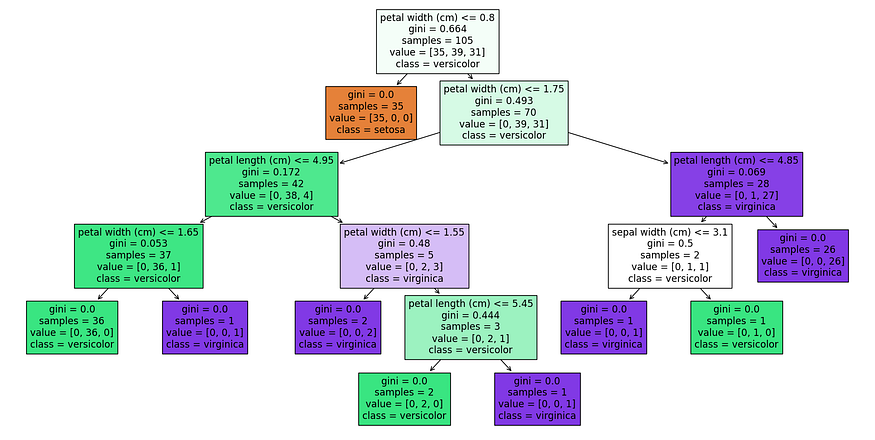
你看我们画的决策树。
- 分裂标准:树根据花瓣的长度和宽度进行分裂,表明这些是分类的关键特征。
- 节点的纯度:基尼指数为 0 的节点是完全纯净的,这意味着该节点上的所有样本都属于一个类。
- 类分布:每个叶节点显示每个类中分类的样本数。例如,最左边的叶子有 36 个样本,全部归类为杂色。
四、随机森林
随机森林是一种集成学习方法,其中多个决策树聚集在一起以做出更准确的预测。
可以把它想象成一个专家团队,每个成员都提供自己的意见,最终决定是根据多数票做出的。此方法通常比单个决策树更准确。
以下是我们如何使用 scikit-learn 库在 Python 中实现随机森林:
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Splitting dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Creating and training the Random Forest model
random_forest_model = RandomForestClassifier(n_estimators=100)
random_forest_model.fit(X_train, y_train)
# Making predictions
predictions = random_forest_model.predict(X_test)
# Evaluating the model
print("Accuracy:", accuracy_score(y_test, predictions))在此代码中,我们使用相同的鸢尾花数据集。但是,我们使用的不是单个决策树,而是使用 100 棵树的随机森林 (n_estimators=100)。
训练后,我们预测测试集中鸢尾花的种类。这些预测的准确性通常超过单个决策树的准确性,展示了随机森林在处理数据科学中复杂数据集方面的优势。
这是输出。
![]()
现在让我们想象一下。
# Visualize one of the trees in the forest
plt.figure(figsize=(20,10))
tree_index = 0 # Choose the index of the tree you want to visualize
plot_tree(random_forest_model.estimators_[tree_index], filled=True, feature_names=iris.feature_names, class_names=list(iris.target_names))
plt.show()这是输出。
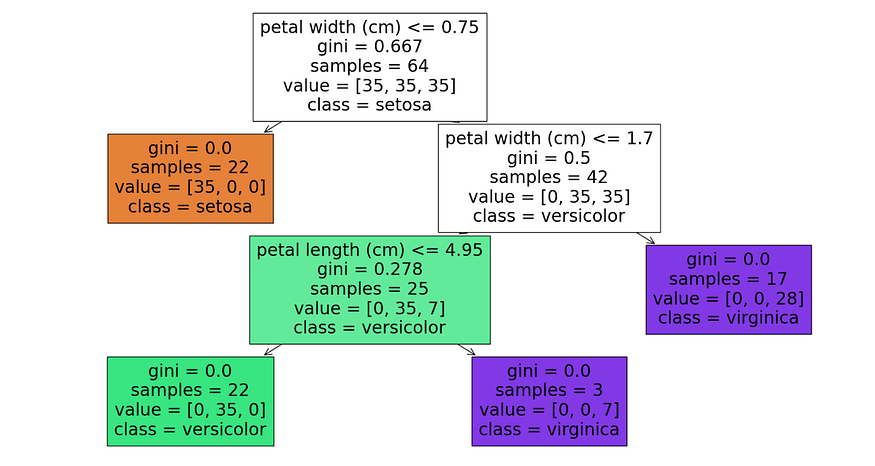
这是来自随机森林模型的单个决策树,特别是第一个树,假设tree_index设置为 0.,它成功地分离了鸢尾花物种,节点的基尼指数为 0,表示纯分类。
它首先根据花瓣宽度进行分类,然后根据花瓣长度进一步细化,展示了该模型区分物种的能力,尤其是 setosa 和 virginica。
五、梯度增压机 (GBM)
????????梯度提升机 (GBM) 是另一种类型的集成学习技术,但它们的工作方式与随机森林不同。随机森林独立构建树木,而 GBM 则按顺序构建树木。
???????每棵新树都有助于纠正前一棵树所犯的错误。这就像序列中的每棵树都在从其前辈的错误中吸取教训,使整个模型更加准确。
让我们使用 Python 的 scikit-learn 库实现一个 GBM:
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Splitting the dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Creating and training the GBM model
gbm_model = GradientBoostingClassifier(n_estimators=100)
gbm_model.fit(X_train, y_train)
# Making predictions and evaluating the model
predictions = gbm_model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))????????这是输出。
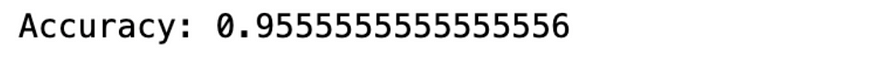
????????在此示例中,我们使用 GradientBoostingClassifier 来预测鸢尾花的种类。该模型构建了 100 棵树 (n_estimators=100),每棵树都从前一棵树的错误中学习。这种改进通常会导致高精度,使 GBM 成为数据科学中解决复杂问题的强大工具。
????????让我们想象一下。
# Plotting the Mean Squared Error
test_score = np.zeros((100,), dtype=np.float64)
for i, y_pred in enumerate(gbm_model.staged_predict(X_test)):
test_score[i] = mean_squared_error(y_test, y_pred)
plt.figure(figsize=(12, 6))
plt.title('Mean Squared Error Over Boosting Iterations')
plt.plot(np.arange(100) + 1, test_score, 'r-', label='Test Set MSE')
plt.legend(loc='upper right')
plt.xlabel('Boosting Iterations')
plt.ylabel('Mean Squared Error')
plt.show()这是输出。
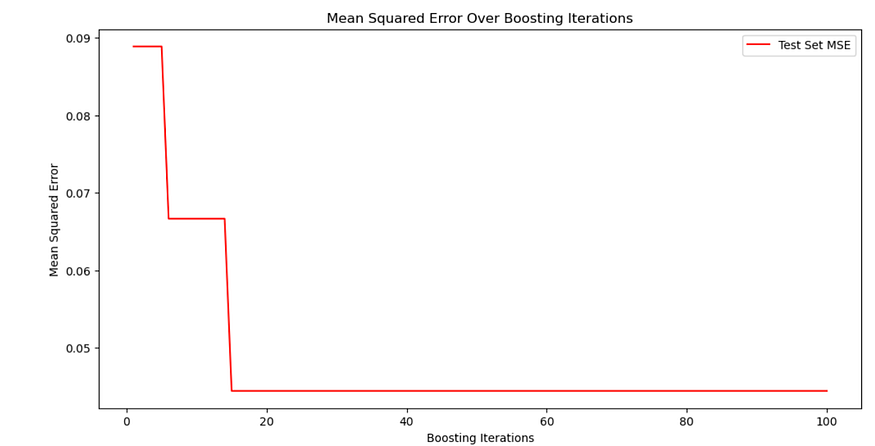
????????上图显示了梯度提升模型在测试集上预测的均方误差 (MSE),超过 100 次提升迭代。MSE 在初始迭代中急剧下降,表明模型性能有了显著提高。
????????经过大约 20 次迭代后,MSE 趋于稳定,这表明额外的迭代对进一步减少错误没有多大贡献。这可能意味着模型很早就达到了最佳性能,额外的迭代并没有增加价值,这是模型收敛的一个很好的迹象。
六、决策树 & 随机森林 & 梯度提升机
现在,让我们讨论决策树、随机森林和 GBM 之间的区别:
- 决策树:在我们的示例中,我们使用单个决策树对鸢尾花物种进行分类。决策树简单明了,易于解释,但容易过度拟合。它们适用于简单的任务,但在更复杂的场景中可能表现不佳。
- 随机森林:我们实现的随机森林模型使用多个决策树来做出更准确的预测。与单个决策树不同,随机森林通过对许多树的结果求平均值来降低过拟合的风险。这使得它们更加健壮和准确,尤其是在更复杂的数据集中。
- 梯度提升机 (GBM):如我们的示例所示,GBM 一次构建一个树,其中每个新树都有助于纠正以前树所犯的错误。这种连续的构建过程可以产生高度精确的模型。但是,如果数据嘈杂,则 GBM 可能对过拟合更敏感,并且比随机森林更难调整。
这些方法中的每一种都有其优点和缺点,它们之间的选择取决于您的数据和问题的具体要求。
七、应用决策树的障碍
作者在Canva上创作的图片
在机器学习中应用决策树时,可能会出现一些挑战或障碍。了解这些挑战是在数据科学项目中有效使用决策树的关键。
- 过拟合:决策树最常见的问题之一是过度拟合,即模型对训练数据的学习效果太好,包括其噪声和异常值。这会导致看不见的数据性能不佳。过度拟合尤其发生在树太深、捕获太多细节和复杂性时。
- 解决方案:实施剪枝技术来限制树的深度,并使用交叉验证来确保模型能够很好地泛化到看不见的数据。
2. 处理连续变量:决策树可能会与连续变量作斗争。他们在不同的点拆分这些变量,但找到最佳拆分点可能很棘手,尤其是当连续变量没有清晰、离散的边界时。
- 解决方案:使用离散化方法将连续变量转换为分类变量,从而简化决策过程。
3. 数据不平衡的偏向树:如果训练数据不平衡(即某些类的代表性不足),决策树可能会偏向主导类。这种偏见可能会扭曲预测,以牺牲少数阶级为代价,偏袒多数阶级。
- 解决方案:在训练之前应用 SMOTE(合成少数过采样技术)等技术或调整类权重以平衡数据集。
4. 大型数据集的复杂性:虽然决策树可以有效地处理中小型数据集,但对于非常大的数据集,它们的性能可能会降低。训练树的时间显着增加,树结构可能变得过于复杂,使其更难解释。
- 解决方案:使用降维技术或特征选择来减小数据集的大小和复杂性,使树更易于管理。
5. 仅限于线性决策边界:决策树主要创建线性决策边界,在特征与目标变量之间的关系更复杂或非线性的情况下,线性决策边界可能会受到限制。
- 解决方案:将决策树与其他算法(如 SVM(支持向量机))相结合,这些算法可以捕获非线性关系。
6. 对数据微小变化的敏感性:决策树对训练数据的微小变化可能非常敏感。微小的变化可能会导致树的结构明显不同。在数据频繁更改的动态环境中,这种缺乏稳定性可能是一个问题。
- 解决方案:使用随机森林或梯度提升等集成方法,这些方法对小数据变化不太敏感,但稳定性更高。
如果您想了解更多关于机器学习算法的信息,这里有一个很好的资源→您必须了解的机器学习算法。
八、最后的思考
????????我们研究了机器学习中基于树的模型的世界,揭示了决策树、随机森林和 GBM 的细微差别。 使用 Iris 数据集,我们看到了这些模型的运行情况,从简单的可视化到应对复杂的数据挑战。我们还克服了常见的障碍,提供了实用的解决方案来提高模型性能。
????????实践是数据科学的关键。试验这些模型,调整它们,看看它们在处理不同数据时的表现如何。您遇到和克服的每一个挑战都会进一步提高您的技能。
????????加入我们的平台,进一步学习。参与真实世界的数据项目,为您在数据科学领域的职业生涯做好准备。访问我们,应用您的知识,并继续成长为崭露头角的数据科学家。您的旅程才刚刚开始,还有很多东西等着你去探索和实现!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机Java项目|古诗词数字化平台
- 找不到msvcr120.dll无法执行代码的解决手段,msvcr120.dll有什么用?
- 冒泡排序之C++实现
- FIO测试参数与linux内核IO栈的关联分析-part2
- 点云从入门到精通技术详解100篇-基于改进动态图卷积的点云分类模型
- 算法基础之二分与前缀和 day 6
- 计算机网络问题
- Super capacitor超级电容能当成电池用吗?
- k8s的二进制部署
- 计算机网络中的可靠传输机制