基于电商场景的高并发RocketMQ实战-NameServer内存中核心数据模型分析、内核级Producer发送消息流程
发布时间:2023年12月23日
NameServer 内存中核心数据模型分析
NameServer 中关键的数据模型结构如下:
-
clusterAddrTable:存储 Broker 集群表,其中 Broker01 表示第一个 Broker 分组
clusterAddrTable: { BrokerCluster01: [Broker01, Borker02] } -
brokerAddrTable:存储 Broker 地址表,存储了每个 Broker 分组的信息,以及该 Broker 分组中每个主从 Broker 的地址
brokerAddrTable: [ { Broker01: { cluster: BrokerCluster01, brokerAddrs: [ 0/*brokerId,用于区分主从*/: ip:port, 1/*brokerId,用于区分主从*/: ip:port ] }, Broker02: { cluster: BrokerCluster01, brokerAddrs: [ 0/*brokerId,用于区分主从*/: ip:port, 1/*brokerId,用于区分主从*/: ip:port ] } } ] -
brokerLiveTable:存储活跃的 Broker,其中
haServerAddr存储与当前 Broker 互为主备的 Broker 地址brokerLiveTable: { ip:port: { lastUpdateTimestamp: xxxx, haServerAddr: ip:port } } -
topicQueueTable:存储 Topic 在每个 Broker 中的队列数量
topicQueueTable: { Topic01: [ { brokerName: Broker01, readQueueNums: 4, writeQueueNums: 4 }, { brokerName: Broker02, readQueueNums: 4, writeQueueNums: 4 } ] }?
内核级 Producer 发送消息流程
消息生产者发送消息根据 Topic 进行发送:
- 根据 Topic 找到这个 Topic 的 Queue 再每台 Broker 上的分布,进行负载均衡
- 通过负载均衡选择一个队列,根据
topicQueueTable可以知道该 Queue 是属于哪一个 Broker 的 - 那么接下来就查找到 Broker 主节点(根据 brokerId 判断),将数据发送到这个 Broker 主节点中,再写入对应的 Queue
那么如果当前消息发送到当前 Broker 组失败的话,在一段时间内就不会选择当前出现故障的 Queue了,会重新选择其他的 Broker 组中的 Queue 进行发送
选择 Broker 以及发送失败流程图如下图黄色部分所示:
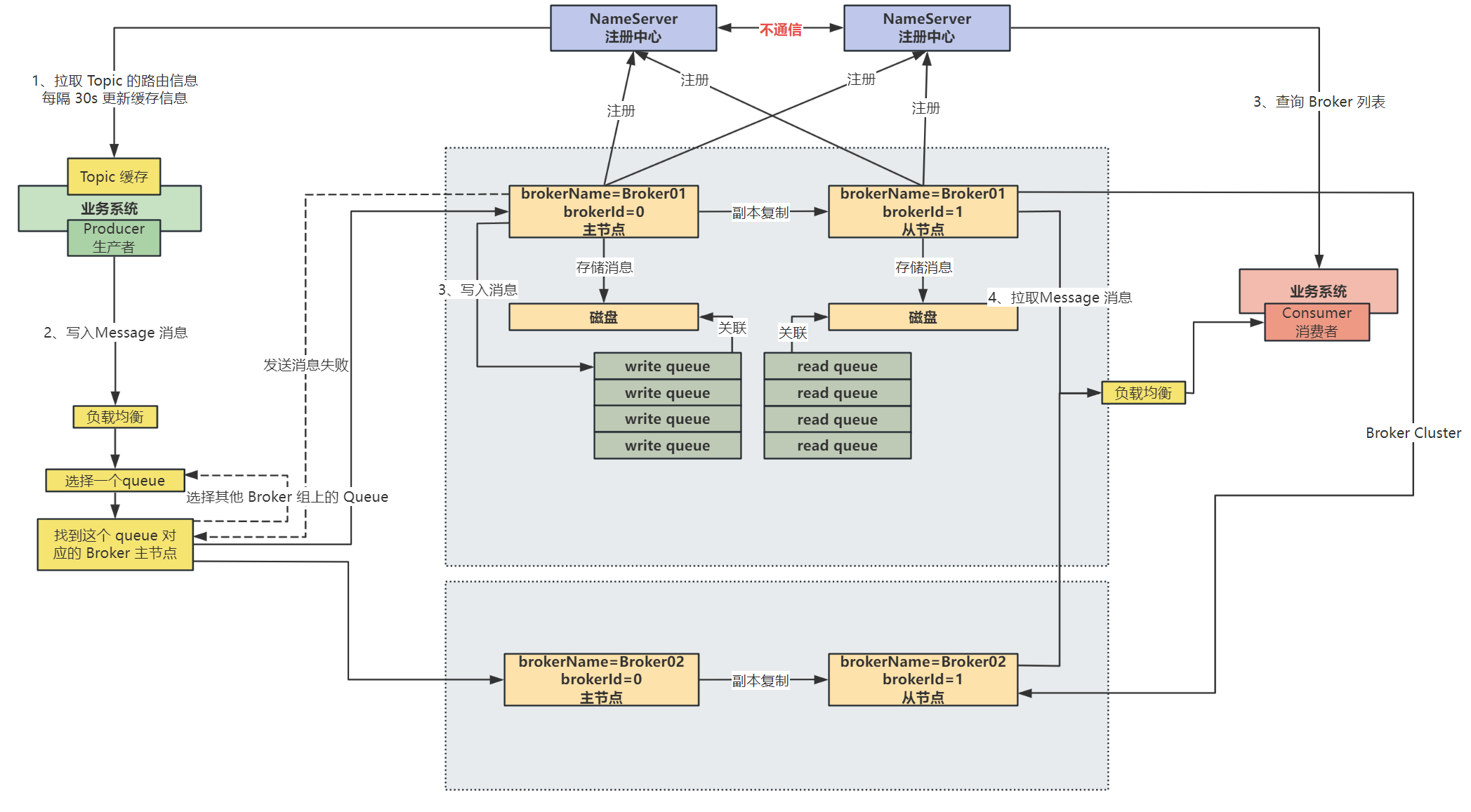
RokcetMQ 的 NameServer 中是有 故障的延迟感知机制 ,即当 Broker 出现故障时,对于生产者来说,并不会立即感知到该 Broker 故障
NameServer 中虽然每隔 10s 中会去检查是否有故障 Broker,将故障 Broker 剔除掉,但是此时生产者的 Topic 缓存中还是有故障 Broker 的信息的,只有等 30s 之后刷新,才可以感知到这个 Broker 已经故障了
通过这个 故障的延迟感知机制 可以避免去做许多麻烦的操作,如果 Broker 挂掉之后,要让生产者立马感知到,需要通过 NameServer 去通知许多 Producer,并且如果通知丢失,还是有向故障 Broker 发送消息的可能!
文章来源:https://blog.csdn.net/qq_45260619/article/details/135164807
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 生日蜡烛C语言
- LeetCode 2865. 美丽塔 I,前后缀分离+单调栈
- Linux: dev: gcc: plugin: annobin
- 拧巴的 tcp
- 微信游戏开发:休闲乐趣新时代
- 基于Levenberg-Marquardt算法改进的BP神经网络-公式推导及应用
- win10系统计算机名称查看及重命名操作方法
- Spring Boot的Web之旅
- 深度学习记录--学习率衰减(learning rate decay)
- varChar(100)和 varChar(10)的区别是什么?