NLP论文阅读记录 -ICLR 2023 | 您只需要复制即可
文章目录
前言

COPY IS ALL YOU NEED(2305)
0、论文摘要
主要文本生成模型通过从固定词汇表中顺序选择单词来组成输出。
在本文中,我们将文本生成表述为从现有文本集合中逐步复制文本段(例如单词或短语)。
我们计算有意义的文本片段的上下文表示,并使用高效的向量搜索工具包对它们进行索引。
然后,文本生成的任务被分解为一系列复制和粘贴操作:在每个时间步骤,我们从文本集合中寻找合适的文本范围,而不是从独立的词汇表中进行选择。标准语言建模基准(WikiText-103)上的实验表明,根据自动和人工评估,我们的方法实现了更好的生成质量。
此外,由于解码步骤的减少,其推理效率可与令牌级自回归模型相媲美。我们还表明,我们的方法只需切换到特定领域的文本集合即可实现有效的领域适应,而无需额外的培训。
最后,我们观察到,我们的方法通过简单地扩展到更大的文本集合而获得了额外的性能提升,同样无需进一步训练。1
一、Introduction
1.1目标问题
大多数神经语言模型(LM)通过以自回归方式进行一系列下一个标记预测来处理文本生成任务(Radford et al., 2019; Dai et al., 2019; Khandelwal et al., 2020; Shi et al., 2020)。 ,2022)。
具体来说,LM 在固定词汇表上为任何给定前缀生成下一个令牌分布。然后,通过选定的解码方法选择下一个标记,例如贪婪搜索和核采样(Holtzman 等人,2020)。该过程持续进行,直到达到某个停止条件。例如,发出特殊的生成结束令牌,或者生成的文本达到最大长度限制。
与传统的神经语言模型不同,我们通过从现有文本集合中复制文本片段来重新构建文本生成。文本段的长度可以是可变的,包括单个单词和多单词短语。为了清楚起见,我们将使用术语“短语”来指代任何连续的文本段,单个单词也可以被视为长度为 1 的短语。我们为每个短语计算上下文向量表示并将它们打包到离线索引中。在每个解码步骤中,都会从离线索引中检索合适的短语并将其附加到当前前缀。换句话说,传统神经语言模型中的下一个标记预测被一系列复制粘贴操作所取代。
1.2相关的尝试
1.3本文贡献
我们提出的模型名为 COG(COPY-GENERATOR 的缩写),具有以下优点。
首先,我们的方法选择特定上下文中的短语,而不是固定词汇表中的独立标记。它可能允许更准确的候选人代表和选择。
其次,我们的方法允许无需培训即可适应新的知识源,因为文本集合可以以即插即用的方式更新。它可以使领域适应和数据扩展/过滤等应用场景受益。
第三,我们的方法允许多个标记的序列(即多词短语)一步生成。它可以减少解码步骤的总数,从而提高推理效率。
我们进行了大量的实验来验证我们提出的 COG 的有效性。
在标准语言建模基准(WikiText-103)上,我们提出的 COG 在自动指标(26.14 vs. 23.43 MAUVE(Pillutla et al., 2021))和人类评估(48% vs. 28% 人类偏好)方面明显优于标准基线。
此外,当我们直接将文本集合从 WikiText-103 语料库切换到特定领域语料库 Law-MT(Koehn & Knowles,2017)时,我们提出的 COGout 在此域适应设置上表现出强大的基线(28.14 vs. 26.85 MAUVE 和52% vs. 36% 人类偏好),无需任何特定领域的培训。
此外,当我们将 COG 的文本集合扩大到更大的 En-Wiki 数据集时,我们获得了额外的增益(26.97 vs. 23.43 MAUVE),同样无需任何进一步的训练。
总之,我们的贡献如下:
? 我们提出COG,一种将文本生成任务重新表述为一系列现有文本集合的复制和粘贴操作的方法。
? 我们表明,在现有语言建模基准上,COG 的性能优于标准神经语言模型基线。
? 我们证明COG 允许无需培训即可适应更大的文本集合和特定领域的文本集合。
二.相关工作
2.1密集检索
密集检索技术(Karpukhin et al., 2020)已广泛应用于许多下游 NLP 任务,例如开放域问答(Karpukhin et al., 2020; Lee et al., 2021)、开放域对话系统(Lan 等人,2021)和机器翻译(Cai 等人,2021)。与传统的稀疏检索系统(例如 BM25 和 TF-IDF(Robertson & Zaragoza,2009))不同,密集检索学习查询和文档的共享向量空间,其中相关的查询和文档对具有更小的距离(即更高的相似性) )比不相关的对。与我们的研究最密切相关的工作是 DensePhrase (Lee et al., 2021)。 DensePhrase 将问答任务重新表述为短语检索问题,其中直接检索短语并作为事实问题的答案返回。不同的是,我们的工作旨在通过多轮短语检索生成连贯的文本延续。由于在文本生成任务中两个相邻短语之间的连接必须连贯且流畅,因此难度要大得多。
检索增强文本生成(RAG) 检索增强文本生成最近引起了越来越多的关注。大多数先前的工作通过将生成基于一组检索到的材料(例如相关文档)来提高语言模型的生成质量(例如信息量)(Li et al., 2022; Guu et al., 2020; Hashimoto et al., 2022)。 ,2018;Weston 等,2018;Cai 等,2019a;b;Khandelwal 等,2020;Wu 等,2019;Guu 等,2020;Lewis 等,2020;Borgeaud 等., 2022; Yang 等人, 2023)。我们的工作就是在这方面进行研究,但向前迈出了根本性的一步。与之前构建检索和生成组合的工作不同,检索就是 COG 中的生成。 Min 等人的一项当代工作是我们的工作。 (2022),它分享了用非参数短语表替换固定词汇的想法。然而,敏等人。 (2022)专注于掩码语言建模,而我们的重点是因果语言建模和文本生成。
三.本文方法
3.1 背景:神经文本生成
神经文本生成可以分为两类:(1)无条件文本生成; (2)条件文本生成。
无条件文本生成(或语言建模)旨在生成给定前缀的连贯文本延续。在这种情况下,语言模型使用序列 pθ(x) 上的密度估计来执行生成。
条件文本生成旨在生成具有某些条件 c 的文本,并估计 pθ(x|c) 的概率。其典型应用包括机器翻译(Sutskever et al., 2014;Bahdanau et al., 2015)、摘要(See et al., 2017)。
在本文中,我们的讨论将集中在无条件文本生成上,但是,我们的方法也可以很容易地适应条件文本生成。
语言建模的规范方法以自回归从左到右的方式 pθ(x0:n) = Qn i=1 p(xi|x<i) 来影响生成。在这种情况下,文本生成被简化为根据到目前为止生成的部分序列(即前缀)重复预测下一个标记的任务 p(xi|x<i)。
该模型通常由两部分组成:(1) 前缀编码器和 (2) 一组标记嵌入。
前缀编码器通常由 Transformer 架构参数化(Vaswani et al., 2017),它将任何前缀转换为固定大小的向量表示 hi ∈ Rd = PrefixEncoder(x<i)。然后,下一个标记为 w 的概率计算为

其中 vw 是表示标记 w 的上下文无关标记嵌入,V 是由所有可能标记组成的预定义词汇表。基于所选的解码方法,例如贪婪搜索和核采样(Holtzman 等人,2020),根据固定词汇 V 上的概率分布选择下一个标记。该过程以自回归方式重复,直到达到某个停止条件,例如,达到生成的最大长度。
3.2 复制生成器
与传统语言模型在通常由单词或子词组成的固定词汇上计算下一个标记分布不同(Sennrich et al., 2016; Kudo & Richardson, 2018),我们提出的 COG 具有动态“词汇”,即取决于可用的源文本集合。 “词汇表”中的每个项目对应于源文本集合中的一个文本片段(本文中称为短语)。重要的是,所有短语都是上下文相关的。
也就是说,相同的短语在不同的上下文中被认为是不同的。整体框架如图1所示。
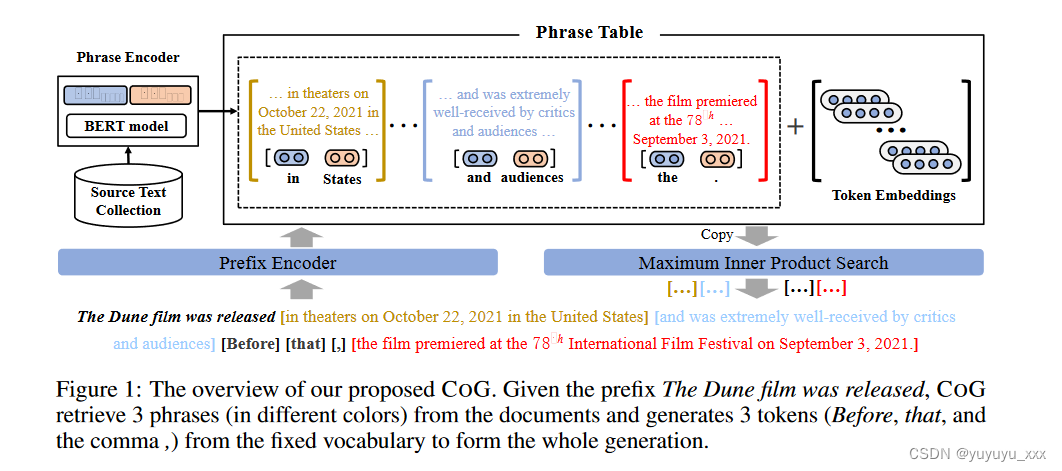
形式上,我们的方法假设一组源文档 {D1, . 。 。 ,Dn} 可用。对于每个文档 Di,可以提取长度为 e ? s + 1 的短语 k = Di s:e,其中 s 和 e 标记开始和 分别是该短语在文档中的位置。我们将源文本集合中的所有短语表示为 P。对于给定的前缀 x<i,我们的目标是选择可以在前缀之后形成连贯文本延续的最佳短语。为此,我们使用短语编码器计算每个短语 pk ∈ Rd = PhraseEncoder(s, e, Di) 的上下文表示。这样,就可以构造一个短语表{(k,pk)|k ∈ P}。与传统语言模型类似,在测试时,COG 也采用前缀编码器将前缀 x<i 映射为向量表示 qi。然后,短语 k 对前缀 x<i 的适合度通过其向量表示 pk 和 qi 的点积来测量:

在每个时间步,选择合适的短语并相应地附加到当前前缀。请注意,短语表的大小可能高达数十亿。为了搜索这个大型候选池,我们预先计算短语表示,并使用基于最大内积搜索 (MIPS) 的从粗到细的搜索管道(Johnson 等人,2019)。详细信息请参阅第 4.2 节。此外,为了支持没有合适短语可用的场景,我们还将标准 LM 中与上下文无关的标记嵌入 {(w, vw)|w ∈ V } 添加到短语表中。
道德考虑 COG 生成的文本包含从其他文档复制的文本片段,这可能会在实际应用中引起版权纠纷。因此,需要考虑以下几点:
(1)需要仔细检查源文本文档的版权。不应使用受严格版权保护的文件和/或私人信息;
(2) 建议明确引用原始出处,尤其是当检索到的短语较长时。
3.2.1 模型架构
如图 1 所示,我们提出的模型由三个主要组件组成:
(1)前缀编码器,将前缀映射到固定大小的表示;
(2) 上下文相关的短语编码器,用于计算源文本集合中短语的向量表示;
(3) 一组上下文无关的标记嵌入,类似于标准神经语言模型中使用的标记嵌入。
前缀编码器
前缀编码器负责将前缀 x<i 编码为用于下一个短语预测的向量表示。我们将前缀视为一系列标记(之前预测的短语也被拆分为标记),并使用带有因果注意力的标准 Transformer 架构对其进行编码(Vaswani 等人,2017 年;Radford 等人,2019 年)。因果注意力只允许输入序列中的每个位置关注其前面的位置。因此,前缀表示可以随着生成的进行而增量计算,从而加快推理速度。具体来说,前缀编码器将长度为i的前缀x<i转换为矩阵Hi ∈ Ri×dL,其中d是隐藏维度,L是Transformer层数。计算可以写为:
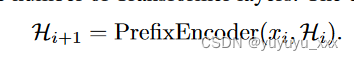
我们使用最后一个标记的隐藏状态作为前缀表示 qi。
短语编码器
给定一组源文档{D1,…,Dn},短语编码器计算文档中所有短语的向量表示。受之前工作的启发(Lee et al., 2016; Seo et al., 2018; Lee et al., 2021),我们构建了上下文相关的短语表示,如下所示。对于文档 D = D1,. 。 。 ,长度为 m 的 Dm,我们首先应用深度双向 Transformer (Devlin et al., 2019) 来获得上下文化的令牌表示 D ∈ Rm×dt ,其中 dt 是令牌表示的维度。然后,我们应用两个 MLP 模型 MLPstart 和 MLPend,将 D 分别转换为开始和结束标记表示 Dstart,Dend ∈ Rm× d 2 :
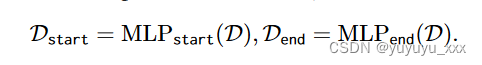
对于文档中从 s 开始到 e 结束的每个短语 Ds:e,我们使用相应的开始和结束向量的串联作为短语表示。
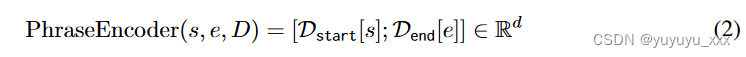
上述表示方法的优点是:
(1)我们只需对文档进行一次编码即可获得所有短语表示;
(2)我们只需要存储所有的标记表示而不是所有的短语表示。
上下文无关的令牌嵌入
虽然 COG 可以从其他文档复制短语,但我们希望保留使用独立令牌组成输出的泛化能力。当源文本集合中没有合适的短语时,这尤其有用。因此,我们还将传统的上下文无关的标记嵌入 V ∈ R|V |×d 添加到我们的短语表中。这些标记可以被视为长度为 1 的短语,没有任何上下文信息。
3.2.2 模型训练
COG 将文本生成任务分解为一系列复制和粘贴操作:
在每个时间步骤,它从源文本集合或固定标记词汇表中选择下一个短语。
换句话说,短语被用作文本生成的基本构建块。为了训练 COG,训练集中的每个文档都按照类似的精神分成一系列短语。
具体来说,我们提出了一种基于前向最大匹配的贪婪分割算法。取一个文档 D = D1, . 。 。 ,以 m 个标记的 Dm 为例,我们的算法从左到右对文档进行分段。如果前 i 个标记可以在其他文档中作为子序列找到,并且 i 是最大有效值,则将其作为短语删除。重复以上过程,直到所有的token都被切掉。请注意,当找不到正确的匹配时,某些结果短语可能是固定标记词汇表中的单个标记。短语分割算法的详细解释可以在附录D中找到。
假设文档 D 已被拆分为 n 个短语 D = p1,…。 。 。 ,pn。如果第 k 个短语 pk 是从另一个文档复制而来,令 Dk 为源文档,令 sk、ek 为 pk 在 Dk 中的起始和结束位置,短语编码器用于提取其上下文相关的短语表示 PhraseEncoder( sk, ek, Dk) (方程 2)。另一方面,如果 pk 是从固定标记词汇表中复制的,我们可以直接检索 pk 的上下文无关标记嵌入。如方程式所示。 1,COG依赖于前缀和短语表示的共享向量空间,其中语义一致的前缀和短语的表示应该彼此更接近,而其他的表示应该被推开。我们通过使用带有批内负数的 InfoNCE 损失来定义下一个短语预测的训练损失(Karpukhin 等人,2020):
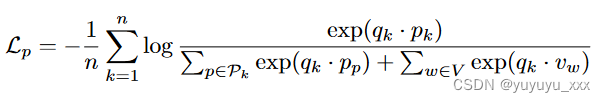
其中Pk由源文档Dk中的所有短语组成,V是token词汇表中所有token的集合,qk表示D中短语pk之前的前缀的表示。此外,为了保留token-level的能力一代,我们还使用标准令牌级自回归损失来训练 COG。
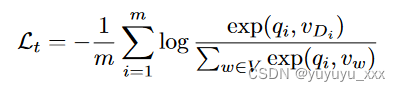
其中 qi 表示 D 中标记 Di 之前的前缀表示。最后,训练损失是这两个损失的总和:

四 实验效果
4.1数据集
4.2 对比模型
? Transformer(Vaswani 等人,2017)已成为神经语言模型事实上的模型。具体来说,我们在实验中对预训练的 GPT2 模型(Radford et al., 2019)进行了微调。 ? kNN-LM(Khandelwal 等人,2020)是一种检索增强生成模型,它通过使用 k 最近邻(kNN)模型线性插值其下一个标记分布来扩展预训练的神经语言模型。 ? RETRO(Borgeaud 等人,2022)2 是另一种检索增强生成模型,它结合了冻结 BERT 检索器、可微编码器和分块交叉注意机制来预测下一个标记。由于没有可以访问的预先训练的 RETRO 模型,我们在 WikiText-103 数据集上从头开始训练它。
4.3实施细节
所有基线和我们的源代码都基于流行的 Huggingface 转换器包(Wolf 等人,2020)。为了公平比较,Transformer、kNN-LM 和 COG 中的前缀编码器使用与预训练 GPT2 模型相同的模型架构(12 层、12 个头和 768 个隐藏维度)(Radford 等人,2019)。对于 COG 中的短语编码器,我们对预训练的 BERT-base-cased 模型进行了微调(Devlin 等人,2019)(12 层、12 个头和 768 个隐藏维度)。我们在 8 个 Tesla-V100 GPU 上训练 400,000 步的基线和 COG。对于所有基线,学习率、dropout 率和梯度裁剪分别设置为 5e-5、0.1 和 1.0。由于内存限制,批量大小设置为包含 256 个短语。对于短语编码器中的 BERT 模型,最大序列长度设置为 256。对于前缀编码器中的 GPT2 模型,最大序列长度设置为 512。我们提出的 COG 包含来自 BERT 和 GPT2 模型的总共 248M 参数,并且其他基线包含超过 124M 的参数。正如 Borgeaud 等人所建议的。 (2022)中,kNN-LM的超参数λ和α分别设置为0.118和0.00785。
为了提高COG的推理效率,我们对源文本集合中的所有文档进行离线编码。请注意,从如此庞大的短语集合中检索在工程方面面临着严峻的挑战。本文使用从粗到细的管道来应对这一挑战。具体来说,我们首先使用文档检索器来检索每个给定前缀的前 k 个相关文档。然后,收集它们对应的短语表示以供选择。在本文中,使用流行的语义匹配模型 DPR (Karpukhin et al., 2020) 和向量搜索工具包 FAISS (Johnson et al., 2019) 作为文档检索器,它可以召回具有相似主题的文档前缀。 k值根据经验设置为1024。
COG 可以与贪婪搜索和核采样一起使用。对于贪婪搜索,COG 选择在每个时间步具有最高适应度分数的短语。对于核采样,我们首先通过对所有候选短语的适应度分数使用 softmax 函数来获得下一个短语分布。然后,在此分布上对下一个短语进行采样。实施的更多细节可以在附录 A 和 B 中找到。
4.4评估指标
对于测试集中的每个文档,我们使用前 32 个标记作为前缀。基线和我们提出的 COG 基于相同的前缀生成长度为 128 的文本延续。下列的遵循惯例(Welleck 等人,2020;Su 等人,2022),我们在整个实验中使用贪婪搜索和核采样(Holtzman 等人,2020)(p = 0.95)。遵循之前的工作(Welleck 等人,2020;Su 等人,2022)并报告以下评估指标的结果:
? MAUVE(Pillutla et al., 2021)是一种高效、可解释、实用的自动评估,与人类判断高度一致,广泛用于评估现代文本生成模型(Su et al., 2022;Krishna et al., 2022) 。在本文中,MAUVE利用GPT2large模型来生成分数,缩放因子设置为2.0。
? Rep-n(Welleck 等人,2020)将序列级重复测量为生成文本中重复 n 元语法的部分(Welleck 等人,2020)。对于生成文本 x,Rep-n 可以表示为:100 × (1.0 ? |unique n?gram(x)| |total n?gram(x)| )。较高的Rep-n表示世代间严重的退化问题。
? 多样性(Welleck et al., 2020)衡量世代的多样性,其公式为 Π4n=2(1 ? Rep?n 100 ))。多样性得分较高的一代人通常信息更丰富。
请注意,之前的工作(Khandelwal et al., 2020;Dai et al., 2019)经常使用困惑度作为主要评估指标来衡量语言建模的性能。然而,由于我们提出的 COG 不计算固定词汇表上的下一个标记分布,因此困惑度的比较不可靠,因此被省略。然而,我们可以使用外部语言模型来测试生成文本的困惑度,结果如附录C所示。
4.5 实验结果
在本文中,我们在三种不同的设置中评估基线和我们提出的 COG:(1)标准语言建模; (2)领域适应; (3)扩大短语索引。
4.5.1 WikiTEXT-103 上的语言建模
在此设置中,模型在 WikiText-103 数据集的训练集上进行训练,并在其测试集上进行评估。 WikiText-103 数据集(Merity 等人,2017)包含超过 1 亿字的维基百科文章的广泛集合,广泛用于评估通用语言建模的性能(Khandelwal 等人,2020;Dai 等人,2020)。 ,2019;Su 等人,2022)。
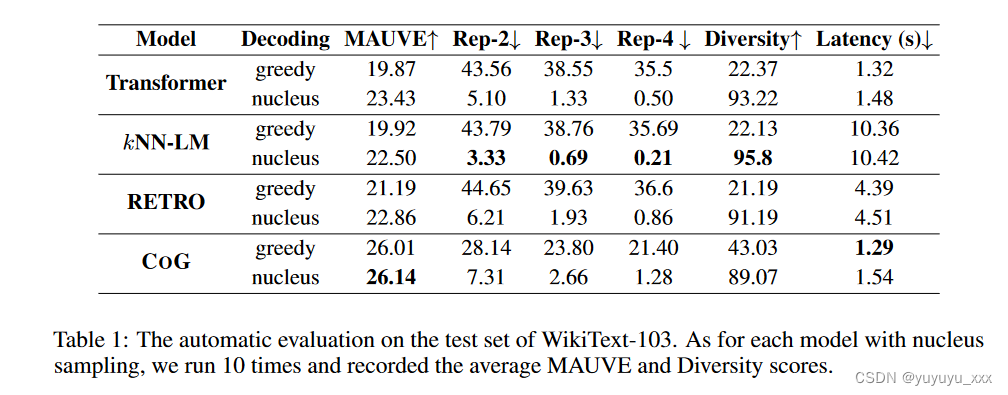
结果
表 1 显示了基线与我们提出的 COG 在 WikiText-103 语料库测试集上的性能比较。可以发现,我们提出的 COG 在大多数指标上都远远优于 Transformer 和 kNN-LM 基线。具体来说,COG 将 MAUVE 分数从最佳基线(带核采样的 Transformer)从 23.43 提高到 26.14,提高了 2.71%。有趣的是,尽管众所周知贪婪搜索可能会引发严重的退化问题(Welleck et al., 2020),但带有贪婪搜索的 COG 仍然优于带有核采样的标准 Transformer 基线,比 MAUVE 提高了 2.58%。这观察表明 CORG 更稳健并且不易出现退化问题,这可以被视为额外的好处。

推理速度
此外,我们还比较了不同方法在测试集上完成生成的平均时间成本。由于 COG 中的短语表示是离线预先计算的,因此不包括其编码时间成本。结果如表 1 所示。如图所示,COGstill 实现了与标准 Transformer 基线相当的推理效率。原因是复制的短语通常包含多个标记(短语长度统计如表2所示)。因此,COG 在生成相同长度的文本时使用更少的解码步骤。与使用从粗到细的搜索管道的 COG 不同,kNN-LM 在每个解码步骤都进行大规模矢量搜索。它的推理延迟远高于 Transformer 和 COG,这与之前的工作一致(Alon 等人,2022)。

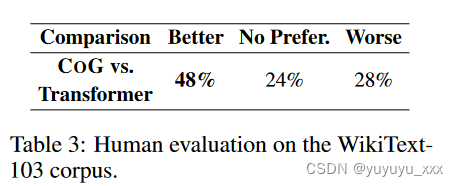
人工评估 为了确保评估的可靠性,我们还与来自第三方评分平台的三名母语评分者进行人工评估。具体来说,我们随机选择100个测试提示。对于每个测试提示,注释器都会以随机顺序获得两个延续,分别由 COG 和 Transformer 生成。
要求注释者通过考虑以下几个方面来决定哪一个更好:
? 流畅性:生成的文本是否流畅且易于理解。 ? 信息性:生成的文本是否多样化并包含有趣的内容。当注释者对同一个样本做出不同的决定时,我们会要求他们进行讨论并做出最终决定。
如表 3 所示,我们提出的 COG 模型显着优于强大的 Transformer 基线,表明其更好的生成质量。
案例分析
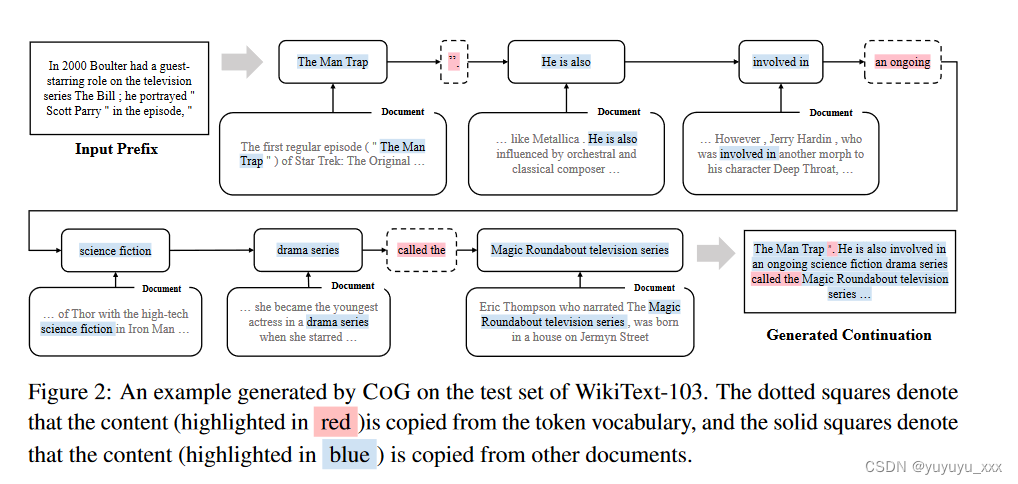
为了更好地理解 COG 的性能,我们在图 2 中展示了我们提出的 COG 生成的文本延续的示例。可以发现,COG 可以检索给定前缀的语义连贯且流畅的短语。例如,在第二个解码步骤中,COG从预定义词汇中生成标点符号[”,.]以结束电影名称“The Man Trap”和句子。此外,在第九步解码时,COG直接从相关文档中复制了命名实体Magic Roundabout电视剧。更多示例可以在附录 E 中找到。
五 总结
在本文中,我们将文本生成重新表述为从大量文本集合中逐步复制短语。在这种形式化之后,我们提出了一种新颖的神经文本生成模型,名为 COG,它通过从其他文档中检索语义连贯且流畅的短语来生成文本。实验结果证明了 COG 相对于标准语言建模 (WikiText-103)、领域适应 (Law-MT) 和扩大短语索引 (En-Wiki) 三个实验设置的强大基线的优势。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!