一文解读Transformer神经网络中的注意力机制
原创 | 文 BFT机器人?

PART 1
神经注意力简介
为了最好地直观地理解自我注意力,我们需要快速回顾过去十年自然语言处理(NLP)架构的前景。我们将保持这个讨论的独立性,不需要熟悉NLP领域,我们在这里的主要关注点是思想的演变,而不是每个架构的确切数学细节,考虑到这一点,让我们回顾一下NLP中的思想流。
1.1递归神经网络
在机器学习文献中,人们已经很好地认识到,自然语言中的句子是序列,因此可以处理序列的模型比“无状态”模型(如原版全连接深度神经网络)更适合NLP任务。因此,提出了循环模块,其原理图如下图所示。其基本思想是,句子可以在深度神经网络中逐字处理,从而将前一个单词的表示注入到当前单词的隐藏层中。这允许RNN将数据的时间性质显式地合并到模型中。
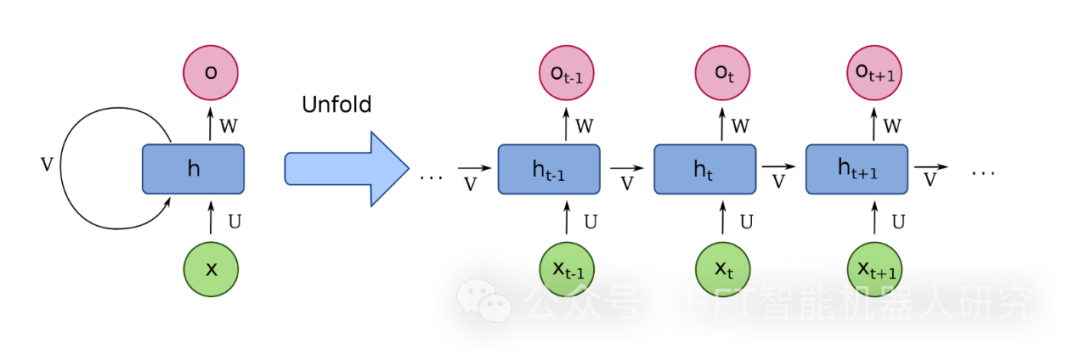
循环阻滞示意图(来源:维基百科)
尽管RNN背后的动机思想非常深刻,但它们的数学公式无法对长序列进行建模。RNN将序列建模为隐藏的单词表示之间的乘法交互。因此,尝试对长序列进行建模会导致梯度爆炸和消失。需要对RNN的设计进行修改以稳定训练。
1.2长短期记忆网络
长短期记忆网络(LSTM)修改了原版RNN的架构以稳定训练。Schmidhuber教授和他的同事们通过专门研究RNNs的缺点提出了LSTM。从概念上讲,LSTMs的关键创新是用加法相互作用取代RNNs的乘法相互作用。因此,梯度值在反向传播过程中不会衰减,因为它们是相加分布的,而不是乘法分布的。
因此,在LSTM中,梯度的大小不会爆炸或消失,因此可以对长序列进行建模。作为计算机视觉领域的专家,您可能已经注意到,He等人在设计ResNet时使用了相同的加互概念,这些网络被称为残差块。
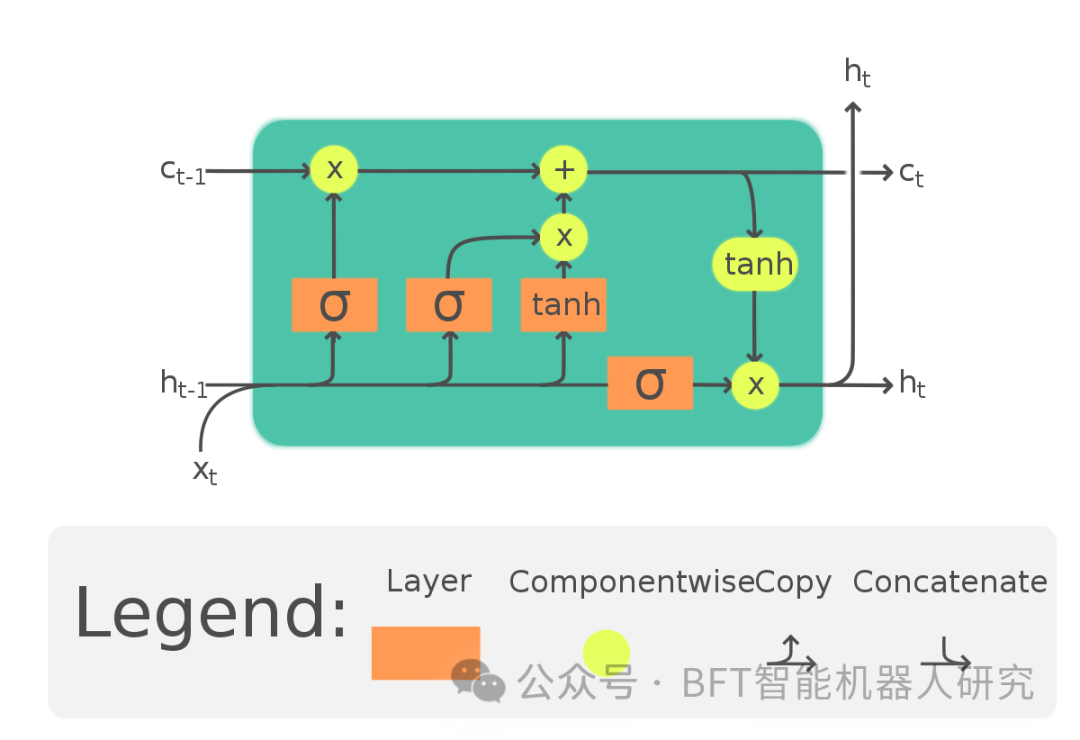
LSTM单元示意图
在这里,我们看到了第一个证据,证明同样的想法被用于改进NLP和计算机视觉模型。随着视觉变压器的设计,这一趋势得到了明确的推动。尽管LSTM改进了RNN,但对非常长的序列进行建模的问题仍然存在。此外,LSTM就像普通的RNN一样,按顺序处理单词,即一个接一个地处理单词,因此,对长序列的推理速度很慢。
1.3神经自注意力机制
虽然LSTM旨在解决RNN的数学缺陷,但神经自注意力机制(或简称注意力机制)回到了绘图板,从一开始就重新思考了RNN背后的动机。虽然句子确实是单词的序列,但人类不会按顺序、一个接一个地处理单词,而是分块处理。此外,有些单词与预测下一个单词高度相关,但大多数则不然。
LSTM被迫按顺序处理所有单词,而不管它们的相关性如何,这限制了模型可以学习的内容。有没有一种机制可以让我们允许模型将特定单词的相关性纳入其自身?换句话说,在预测下一个词时,我们应该注意前面的哪些词?这就是注意力机制起源背后的动机问题。事实证明,答案不仅与语言模型相关,而且还导致了ViT的发展。
PART 2
神经自注意力机制的直观解释
注意力机制不是序列,而是将输入处理为块,没有任何明确的时间联系。让我们看看它是如何在对句子中的下一个单词进行建模的上下文中逐步工作的。
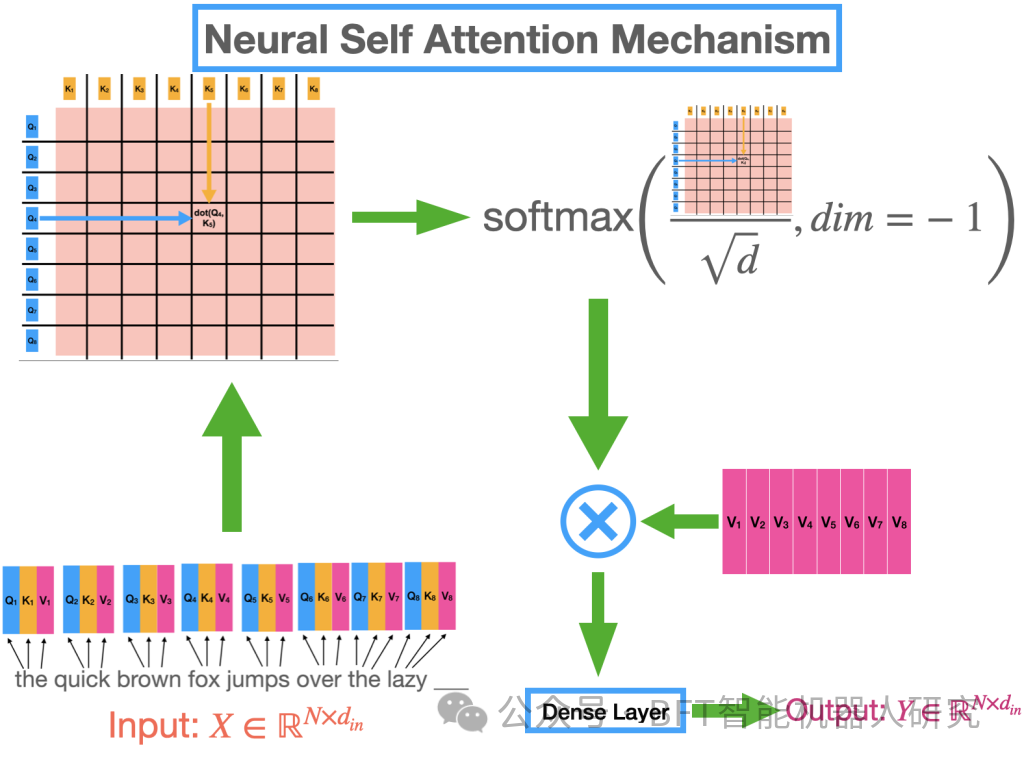
注意力机制的第1步
第一步:查询、键值
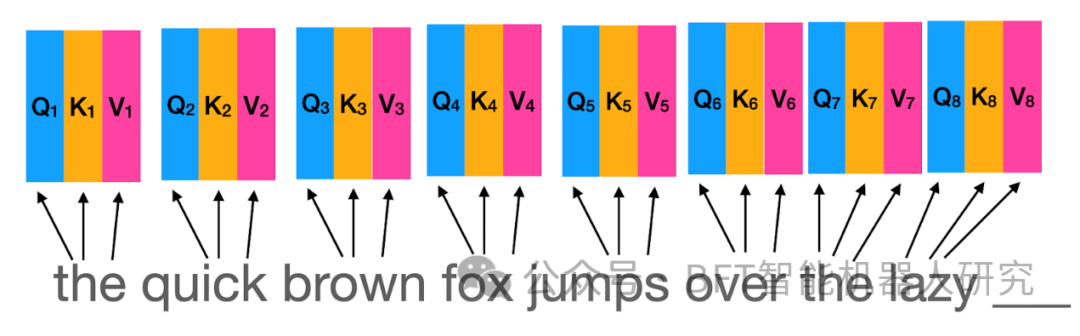
就像RNN一样,句子中的每个单词都“发出”一个隐藏的表示。为了让该机制能够模拟相关性,我们让每个单词提出问题并获得答案。
当一个词提出的问题与另一个词发出的答案相匹配时,我们会将其解释为两个词彼此具有高度相关性。一个单词使用“查询”向量,向量序列中的所有单词提出相同的问题。同样,它使用“键”向量为所有单词提供相同的答案。
在注意力机制最常用的变体中,还使用单独的“值”向量来允许模型以非线性方式组合查询和关键向量的输出,这增加了模型的表现力。所有三种类型的向量都是其单独的密集层的输出,并且所有三种类型的向量都具有相同的大小,例如d。
总而言之,在注意力机制的第1步中,如图所示,句子中的每个单词都使用三个独立的密集层发出三个独立的表示形式,称为查询Q、键K和值V向量。
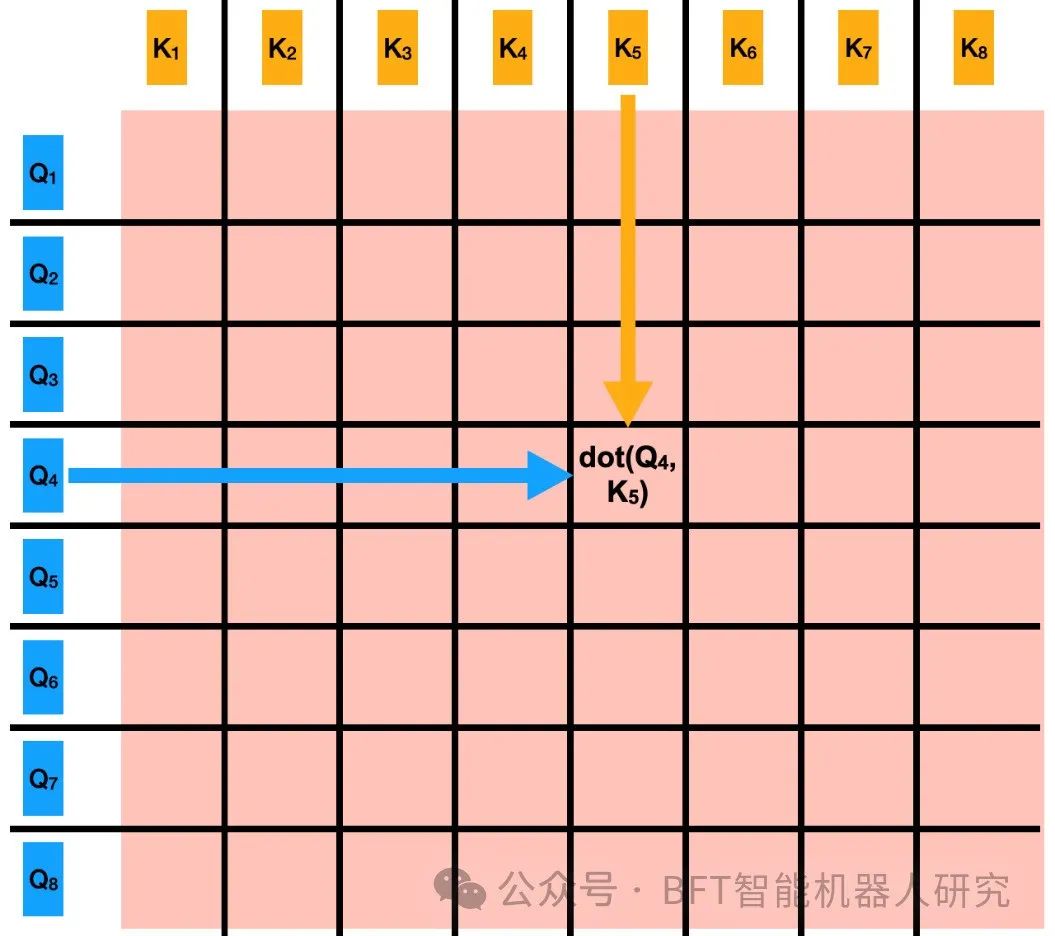
第2步,从查询和关键向量计算注意力矩阵
第二步:计算注意力矩阵
如果我们用N个单词对一个句子进行建模,那么在步骤1之后,我们有N个查询、N个键和N个值向量。那么,一个词究竟是如何提出问题并获得答案的呢?这是由注意力矩阵完成的,注意力矩阵是注意力机制的核心。
我们将所有N个查询向量与所有N个键向量的点积取,如图所示。由于两个向量(无论多大)的点积只是一个数字,因此这些NxN点积的结果是一个NxN矩阵,其每个元素Aij都是第i个查询向量的点积A,第j个键向量。
这里有三件重要的事情需要注意:
1、由于每个单词在计算注意力矩阵时都与其他单词交互,因此输入没有时间顺序。因此,普通注意力机制不考虑输入的顺序性。
2、计算注意力矩阵的计算复杂度为N2。因此,如果我们想用两倍的单词数对句子进行建模,它将需要4倍的计算资源。
3、我们注意到,自我注意力中的“自我”是指我们也将给定单词查询的点积与它自己的键向量联系起来。注意力机制有一些早期的变体,它们跳过了计算的自相关性,导致输出具有NxN–N元素(矩阵的所有对角线元素都缺失)。但是,自注意力变体效果最好,并且在现代GPU上具有高度可并行性。这就是这种机制得名自我关注的地方。
第三步:归一化和注意力分数
如上计算所示,注意力矩阵将包含一些大数字和一些小数字。我们将大数字解释为代表高相关性,将小相关性解释为低相关性。
在这一点上,我们可以通过几种方式使用这个矩阵。我们可以使用max pooling操作在每行中挑选出最大元素,并将它们用于进一步处理,但是这会丢弃大部分信息。此外,有时给定的单词可能需要来自多个先前单词的上下文才能正确建模数据,因此我们应该尽可能地保持表现力。另一个重要的要求是,我们选择使用注意力矩阵,它应该保持模型的可微性,因为模型需要通过反向传播进行训练。
softmax层满足了所有这些要求,因此我们取注意力矩阵的逐行softmax,得到一个NxN矩阵,其每行是一个概率分布。这里的一个小实现细节是,在获取softmax之前,我们将注意力矩阵除以每个查询向量维度的平方根,这充当了一个合适的比例因子来“软化”生成的概率分布。
缩放后,大概率值和小概率值之间的差异会减小,梯度可以相对均匀地流入多个单词位置。这类似于知识蒸馏算法如何将“温度”合并到教师模型的对数中,就像在知识蒸馏领域一样,通过温度因子将输入缩放到softmax可以改善梯度流动并允许更快的训练。
第四步:参加
我们将上一步中获得的归一化注意力分数的点积与值向量相得益彰。在数学上,这表示为:
![]()
由于使用密集层为每个单词获得值向量V,因此注意力机制的输出有N个向量,与输入单词的数量相同。最后,为了获得自注意力层的输出,我们将h向量转换为与具有密集层的输入相同的大小。在上面的等式中,圆形符号代表点积,而不是矩阵乘法。在矩阵乘法方面,该操作可能取决于查询和键向量的形状。
PART?3
多头自我关注
您可能对卷积网络非常熟悉。卷积运算是CNN的基本构建块。同样,上面介绍的自注意力机制是所有Transformer模型的基本构建块,包括大型语言模型和视觉Transformer。
继续类比,人们永远不会设计一个只有一个卷积滤波器的卷积层,因为一个滤波器不足以模拟自然图像的复杂性。事实上,在一层中可以看到>500个卷积滤波器的修道院是很常见的。同样,如上所述,单个注意力层不足以模拟自然语言的所有复杂性。
因此,我们在同一序列中并行应用多个注意力块,称为“头部”。生成的层称为多头自注意力(MHSA)。与卷积的区别在于,一个注意力头比单个卷积滤波器更具表现力。因此,我们不需要使用~500个注意力头,但只需几十个就可以了。ViT中注意力头数量的一些常见选择是12、24和32。与卷积的另一个区别是,在CNN中,每个后续层的过滤器数量都会增加,而最流行的ViT中的注意力头数量通常是恒定的,比如12个。
总而言之,自注意力机制超越了密集层、卷积层和LSTM单元,并提出了一种全新的通用计算机制来模拟数据中的关系。在NLP中,数据具有顺序性,但在计算机视觉中,它可能不是。然而,在本系列的下一部分中,我们将看到使用注意力机制构建的视觉转换器在计算机视觉应用中非常有效。
一些注意事项:
在本系列文章中,我们的目标是介绍视觉转换器。到目前为止,我们已经使用自然语言处理的例子来激励自我注意力机制的引入。但是,从现在开始,我们将离开NLP,专注于视觉转换器。MHSA在计算机视觉(CV)与NLP中的使用方式存在细微差别。
具体而言,此阶段的两个显着差异是:
1、视觉转换器模型一般不使用掩蔽注意力(自监督学习除外)
2、视觉转换器模型不使用交叉注意力(DETR等对象检测模型除外)
随着本系列的进展,我们将在适当的时候介绍这些变体,但就目前而言,请注意,有一些变体,这篇博文的其余部分将仅介绍视觉转换器中最常用的MHSA版本。
PART?4
自注意力机制的数学公式
考虑一个图像,它(以某种方式)被分割成一系列X1,...,XN的斑块,其中每个Xi斑块都是一个维度的扁平向量din。在这里,将图像分割成斑块的确切方法并不重要,让我们构造矩阵,X使得第一维是长度N,第二维是din。
如前所述,我们将使用密集层来获取查询、键和值表示形式。然而,这些密集层将在没有任何偏置项和激活函数的情况下使用,因此密集层只是简单的矩阵乘法。然后,这三个层的参数分别是WQ、WK、WV用于查询、键和值,使得WQ、WK、WV,还使用了另一个具有权重和偏置的致密层。
步骤1:查询、键和值矩阵(这些是矩阵,因为我们在一个步骤中计算序列中所有单词的向量)的计算公式为:

这里是一个超参数,dattn它是键、查询和值向量的维度。通常,dattn比din小得多。
步骤2:注意力矩阵的计算公式为:
![]()
请注意,单个操作计算所有单词的注意力矩阵,包括具有同一单词查询的键的点积。因此,它完全实现了自我关注机制。
步骤3:缩放和softmax实现为:
![]()
在这里,dim=-1表示softmax是跨行而不是跨列获取的(这没有意义)。
步骤4:注意力的输出计算如下:
![]()
注意力层的输出计算公式为:
![]()
因此,输出的大小与输入的大小相同。
虽然我们在这里只制定了单头自注意力,但推广到多头版本包含多个独立的查询、键和值权重矩阵,并且非常简单。
PART?5
PyTorch自我关注的实现
现在我们已经对自注意力层有了直观和数学的掌握,让我们在PyTorch中实现它。
在开始之前,有几点需要注意:
1、由于在自注意力机制中使用了大量的致密层,因此存在过拟合的危险。因此,在MHSA的实际实现中大量使用压差层,以避免过拟合。
2、PyTorch有一个名为nn的模块,这实现了完整的转换器架构(编码器和解码器),而我们将只实现模型的一部分(仅限编码器)。
Einops层:Einops是一个很棒的库,用于张量操作、重塑和调整大小。我们可以使用einops的Rearrange层,而不是使用torch. reshape,它有一个更好的API,并与PyTorch、TensorFlow、JAX和numpy无缝集成。
若您对该文章内容有任何疑问,请与我们联系,我们将及时回应。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【ITK库学习】使用itk库进行图像分割(四):水平集分割
- 黑马axios案例之地区查询
- xbox无法登录、没有反应解决方法分享
- mysql服务多实例运行
- Serverless架构:无服务器应用与AWS Lambda-读书笔记
- mac pycharm 启动报错 cannot connect to already running ide instance
- 刷题总结1.18 下午 (堆)
- Javascript 嵌套函数 - 递归函数 - 内置函数详解
- 1301:大盗阿福
- 探索vue2框架的世界:简述常用的vue2选项式API (二)