数据库原理与应用快速复习(期末急救)
文章目录
- 第一章
- 数据库系统概述
- 数据、数据库、数据库管理系统、数据定义、数据组织、存储和管理、数据操纵功能、数据库系统的构成
- 数据管理功能、数据库管理的3个阶段以及特点
- 数据库的特点、共享、独立、DBMS数据控制功能
- 数据模型
- 两类数据模型、逻辑模型主要包括什么
- 数据模型的组成要素
- 概念模型:实体、属性、码、域、实体型、实体集、联系、实体之间的联系、E-R
- 最常用个数据模型:层次、网状、关系、面向对象、对象关系
- 关系模型:数据结构(关系、元组、属性、码、域等)、关系模型的完整性质、存储结构、关系模型的优缺点
- 数据库系统的结构
- 数据库系统模式的概念
- 数据库系统的三级模式结构:模式、外模式、内模式
- 概念模型的E-R图表示方法(会画图)
- 第二章
- 第三七八九章关系数据库标准语言SQL
- 第四章 数据库设计与编程
- 第五章 认识SQL Server 2016
- 第十章 存储过程和触发器
- 第十一章 数据库安全
- 数据库系统概论(第5版王珊)
- 第九章 数据查询处理和查询优化
- 第十章 数据库恢复技术
- 第十一章 并发控制
- 练习题
第一章
- 1. 数据库系统概述
- 2. 数据、数据库、数据库管理系统、数据定义、数据组织、存储和管理、数据操纵功能、数据库系统的构成
- 数据管理功能、数据库管理的3个阶段以及特点
- **数据库的特点、共享、独立、**DBMS数据控制功能
- 数据模型
- 两类数据模型、逻辑模型主要包括什么
- 数据类型的组成要素
- 概念模型:实体、属性、码、域、实体型、实体集、联系、实体之间的联系、E-R
- 最常用个数据模型:层次、网络、关系、面向对象、对象关系
- 关系模型:数据结构(关系、元组、属性、码、域等)、关系模型的完整性质、存储结构、关系模型的优缺点
- 数据库系统的结构
- 数据库系统模式的概念
- 数据库系统的三级模式结构:模式、外模式、内模式
- 二级映射与数据的独立性
- 概念模型的E-R图表示方法(会画图)
第二章
- 关系数据结构以及形式化定义
- 关系、域笛卡尔积、关系(目、单元关系、二元关系、候选码、全码等)
- 关系模式定义
- 关系数据库概念
- 关系操作
- 基本的关系操作:常用的关系操作、查询操作、基本操作、关系操作的特点
- 关系的完整性(三类完整性约束):实体、参照、用户定义
- 关系代数:集合运算、专门的关系运算、连接、投影、选择等
- 关系模式和范式理论
- 关系模式与属性依赖(一道大题):1、范式的基本概念2、5个判定定理3、依赖关系图4、分解法划分范式(到BCNF)
第三七八九章
- 数据的定义
- 数据查询
- 数据更新
- 视图
- SQL语言是重点
- having where子句
- 简单查询和复合查询、嵌套查询(txt文档以及书上例题)
第四章
- 数据库设计的步骤
- 数据库设计中的各级模式
第五章
- 认识符
- 常量与变量
- 运算符
- 表达式
- 控制流语句
- 常用函数
第十章
- 触发器
- 创建触发器
- 管理触发器
第十一章
数据库系统概论(第5版王珊)
- 第九章 数据查询处理和查询优化
- 优化树
- 代数优化(查询优化)
第十章 数据库恢复技术
- 事务的基本概念
- 故障的种类
- 恢复实现技术
- 数据传输
- 登记日志文件
第十一章 并发控制
- 并发控制概述
- 封锁
- 活锁和死锁
第一章
数据库系统概述
数据库系统主要涉及数据、数据库、数据库管理系统和数据库系统4个基本概念
①数据结构化
②数据的共享性高,冗余度低而且容易扩充
③数据独立性高:物理独立性(应用程序与物理存储相互独立,数据的物理存储改变,应用程序不改变),逻辑独立性(应用程序与逻辑结构相互独立,数据的逻辑结构改变,应用程序不改变)
④数据由数据库管理系统统一管理和控制
数据、数据库、数据库管理系统、数据定义、数据组织、存储和管理、数据操纵功能、数据库系统的构成
①数据data:描述事物的符号,数据库中存储的基本对象
②数据库 DataBase,DB: 长期存储在计算机内的、有组织的、可共享的大量数据的集合
③数据库管理系统 DataBase Management System,DBMS: 位于用户与操作系统之间的一层数据管理软件
④数据库系统 DataBase System,DBS: 由数据库、数据库管理系统、应用程序和数据库管理员(DBA)组成
⑤数据组织 Data Organization 是按照一定的方式和规则对数据进行归并、存储、处理的过程
⑥数据的存储与管理 :数据库出现前的两个阶段 :①人工管理 ②文件系统。其中①的特点:数据不保存,应用程序管理数据,数据不能共享,数据没有独立性。②的特点:数据长期保留,有文件系统管理数据,数据的共享性和独立性差,冗余度大。
⑦数据操纵功能:通过数据库查询语言实现:插入,查询,更新,删除,事务控制,存储过程与触发器,视图。
⑧数据库系统构成:计算机硬件、包含数据库、数据库管理系统在内的计算机软件和数据库用户构成
数据管理功能、数据库管理的3个阶段以及特点
数据库管理三个阶段 :
数据库出现前的两个阶段 :①人工管理, ②文件系统。其中①的特点:数据不保存,应用程序管理数据,数据不能共享,数据没有独立性。②的特点:数据长期保留,有文件系统管理数据,数据的共享性和独立性差,冗余度大。
数据库出现后:数据结构化,数据共享性,独立性高,冗余度低,易扩充,并且有数据库系统统一管理和控制。
数据库的特点、共享、独立、DBMS数据控制功能
数据库的特点
①数据结构化
②数据的共享性高,冗余度低而且容易扩充
③数据独立性高:物理独立性(应用程序与物理存储相互独立,数据的物理存储改变,应用程序不改变),逻辑独立性(应用程序与逻辑结构相互独立,数据的逻辑结构改变,应用程序不改变)
④数据由数据库管理系统统一管理和控制
数据模型
数据模型包括概念模型(信息模型)和逻辑模型(物理模型)
概念模型按用户的观点建模,用于数据库设计,表示方法有 E-R
模型逻辑模型按计算机的观点建模,用于 DBMS 实现,包括网状模型、层次模型、关系模型等等
物理模型是对数据最底层的抽象,是指逻辑模型在计算机中的存储结构
两类数据模型、逻辑模型主要包括什么
概念模型:包括一些基本概念:实体,属性,码,域,实体型,实体集,联系。
包括实体型之间的联系:1:1 , 1:n , n : m。
包括单个实体型内的联系:1:1 , 1:n , n : m。
表示方法:E-R图
逻辑模型:信息世界到计算机世界的抽象,成熟的模型:层次模型(树结构),网状模型(图结构),关系模型(二维表(关系))。
层次模型:无双亲,自上而下,一对多
优点:简单,查询效率高
缺点:不是适用非层次联系
网状模型:一个以上节点可以没有双亲结点,一个节点可以有多个双亲结点,多对多
优点:良好的性能以及存储方式
缺点:数据结构复杂,数据模式和系统实现均不理想
关系模型:每个关系的数据结构都是一张规范化的二维表
优点:概念单一结构简单,易懂
缺点:效率较低,不如层次模型和网状模型
数据模型的组成要素
由数据结构、数据操作、完整性约数条件三个部分组成
数据结构:数据对象的集合
数据操作:数据库允许执行操作的集合
完整性约束条件:数据完整性规则的集合
概念模型:实体、属性、码、域、实体型、实体集、联系、实体之间的联系、E-R
实体:世界客观存在并且可以相互区别的事务
属性:实体具有的某一特性
码:唯一标识实体的属性集合
域:属性取值范围
实体型:实体名的表现形式,用来刻画实体的共同特征和性质
实体集:同一类型实体集合
联系:分为实体型内部的联系和实体型之间的联系
E-R:概念模型的表示方法
最常用个数据模型:层次、网状、关系、面向对象、对象关系
层次模型:最早的数据的逻辑模型,树状结构,结构清晰简单,但是数据结构比较复杂
网状模型:非层次模型,节点之间多对多,性能好高效率,但是数据模式和系统实现不理想
关系模型:最重要的数据模型,数据结构是一张规范的二维表,实体之间联系使用关系表示,数据独立性更高更好的安全保密性,但是查找效率低
关系模型:数据结构(关系、元组、属性、码、域等)、关系模型的完整性质、存储结构、关系模型的优缺点
数据结构
- 关系(Relation): 表示为二维的表格,由行和列组成,每个关系都有一个唯一的名称。
- 元组(Tuple): 表示关系中的一行,包含不同属性的值。
- 属性(Attribute): 表示关系表中的列,每个属性描述了一种数据类型。
- 码(Key): 属性或属性组合的集合,可以唯一标识元组。
- 域(Domain): 属性的取值范围。
完整性质
- 实体完整性规则: 保证每行都有唯一标识,常用主键实现。
- 参照完整性: 确保外键引用的数据是有效存在的,维持表间关系。
- 用户定义完整性: 允许用户定义自己的完整性规则。
存储结构
- 表格式存储结构: 数据以表格形式存储,易于理解和操作。
- 索引结构: 通过索引优化数据访问速度。
优缺点
- 优点:
- 结构化数据存储,易于理解和使用。
- 支持数据独立性,修改结构不影响数据访问。
- 提供了丰富的完整性约束,确保数据质量和一致性。
- 缺点:
- 复杂查询性能较差,特别是对大规模数据操作时。
- 有些数据不适合以关系模型存储,比如复杂的非结构化数据。
数据库系统的结构
数据库系统的结构通常包括三个主要层次:外模式(外部层)、概念模式(逻辑层)和内模式(物理层)。
数据库系统模式的概念
数据库系统中的模式(Schema)指的是数据库中数据的逻辑结构和组织方式的描述。它描述了数据库中存储的数据对象(表、视图等)以及这些对象之间的关系。
- 数据结构和类型: 描述了数据库中的实体和实体之间的联系,每个实体的属性和数据类型。
- 数据约束条件: 包括主键、外键、唯一约束、检查约束等,用于确保数据的完整性和一致性。
- 视图定义: 描述了对数据库中数据的逻辑视图,这是一个基于表的查询结果,可以简化用户对数据的访问。
- 安全性约定: 说明了数据库中数据对象的访问权限和控制措施,包括哪些用户可以访问、修改或删除数据。
数据库系统的三级模式结构:模式、外模式、内模式
课本P11
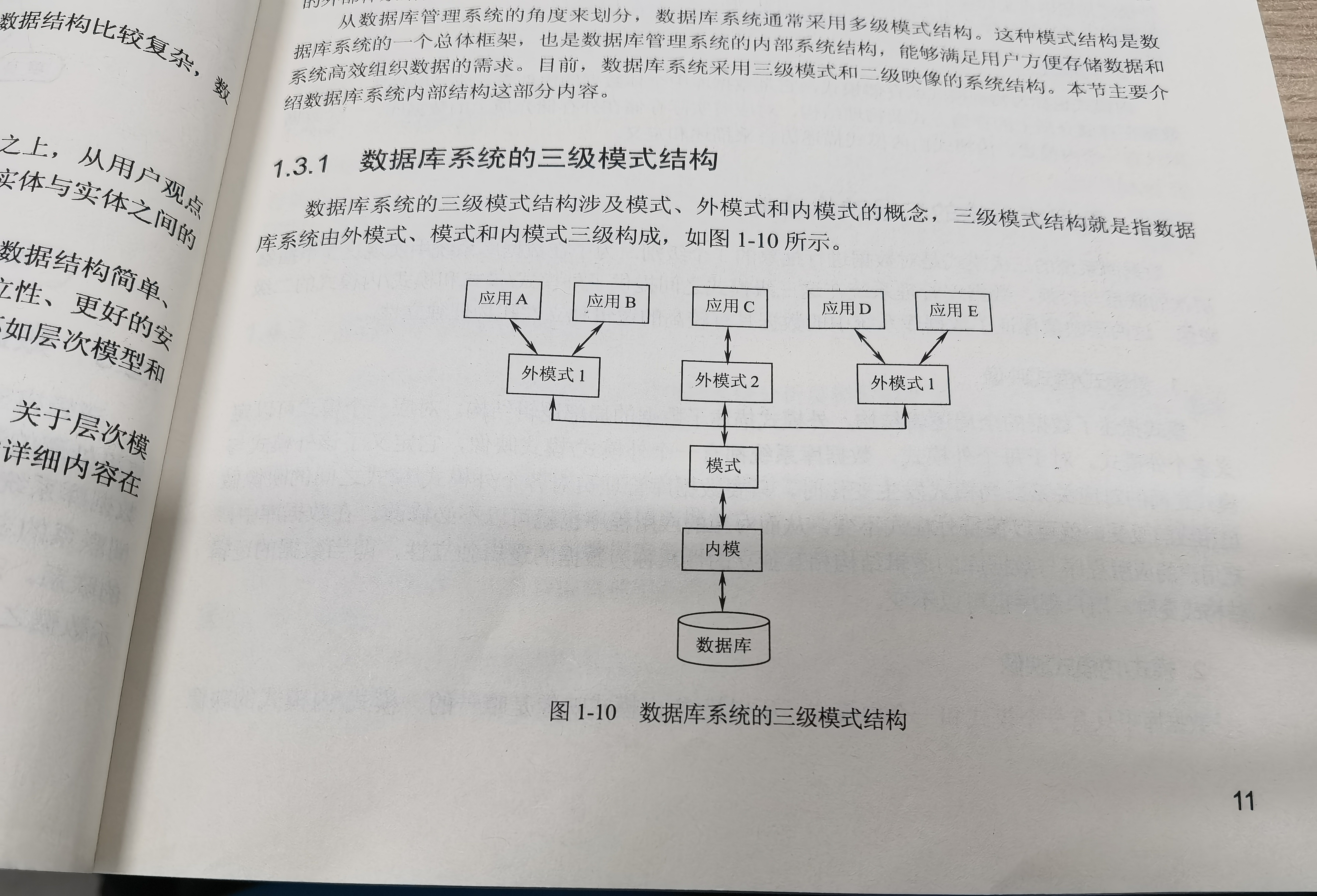
模式:也称为逻辑模式或者概念模式,是由数据库设计者在统一考虑用户需求的基础上,用某种数据模型对数据库中的全部数据的逻辑结构和特征总体描述
外模式:也称为子模式或者用户模式,是数据库用户能够看到和使用的局部数据的逻辑结构和特征描述,是数据库客户的数据视图
内模式:也称物理模式或者存储模式,是数据库中全体数据的内部表述或者底层描述,描述的数据在存储介质上的存储方式以及物理结构,对应着实际存储存储在外存储介质上的存储方式以及物理结构
概念模型的E-R图表示方法(会画图)

第二章
关系数据结构以及形式化定义
关系(Relation)
- 一个关系通常代表着一个表格,包含了多个元组。
- 形式上,一个关系可以用以下方式定义:R = {A1, A2, …, An},其中 R 代表关系名,A1, A2, …, An 是属性或字段的集合。属性用于描述关系中的列。
元组(Tuple)
- 元组代表表格中的一行,它包含了多个属性值,每个属性值对应于关系中的一个属性。
- 形式上,一个元组可以表示为:t = (v1, v2, …, vn),其中 v1, v2, …, vn 是对应属性的值。
属性(Attribute)
- 属性定义了关系中的列,每个属性包含了相关的数据类型和语义信息。
- 形式上,属性包括属性名和对应的数据类型。
形式化定义举例
例如,考虑一个简单的学生信息数据库:
假设有一个关系表格 Students,包含了以下属性:学生ID(StudentID)、姓名(Name)、年龄(Age)、班级(Class)。
形式化定义如下: Students = {StudentID, Name, Age, Class}
其中,每个学生可以用一个元组表示: t1 = (101, ‘Alice’, 20, ‘A101’) t2 = (102, ‘Bob’, 21, ‘B102’)
关系、域笛卡尔积、关系(目、单元关系、二元关系、候选码、全码等)
关系(Relation)
- 在数据库中,关系是指一张表格,由行和列组成,每行表示一个记录,每列表示一个属性。
- 形式化地表示为:R = {A1, A2, …, An},其中 R 是关系名,A1, A2, …, An 是属性或字段的集合。
域(Domain)
- 域指的是属性可以取值的范围或者类型。例如,在一个学生关系中,学生的年龄可以构成一个域。
笛卡尔积(Cartesian Product)
- 笛卡尔积是两个集合之间的运算,用来产生所有可能的元组对组成的集合。在数据库中,当进行多个关系的连接查询时会用到笛卡尔积。
单元关系(Atomic Relation)
- 单元关系指的是关系中的每个元素都是不可再分的,不能进一步拆分成更小的关系。
二元关系(Binary Relation)
- 二元关系是一种特殊类型的关系,其中每个元组都有两个属性。例如,一个关系表中包含姓名和年龄,每个元组都有两个属性值。
候选码(Candidate Key)
- 候选码是能够唯一标识关系中元组的最小属性集合,也就是能够保证每个元组都唯一且最小冗余。
- 候选码的选择不唯一,可能有多个候选码。
全码(Primary Key)
- 从候选码中选定的用来标识元组的主要属性。
- 主键必须满足唯一性和非空性的要求。
关系模式定义
关系模式是描述关系数据库中表的结构和特性的方式。它定义了表中包含的列、列的数据类型以及列之间的约束条件。关系模式描述了数据库表的逻辑设计。
关系数据库概念
关系数据库是一种基于关系模型的数据库系统,它以表格形式组织和存储数据。这些表格被称为关系或表,每个关系包含了元组(也称为行或记录)以及属性(也称为列或字段)。
关系操作
包括查询操作和更新操作两大部分
基本的关系操作:常用的关系操作、查询操作、基本操作、关系操作的特点
常用的关系操作:
- 选择(Selection):从一个关系中选取满足特定条件的元组。
- 投影(Projection):从一个关系中选择特定的属性列。
- 并(Union):将两个关系的元组合并成一个新的关系,要求两个关系具有相同的属性集。
- 交(Intersection):找出两个关系中共同存在的元组。
- 差(Difference):找出在第一个关系中存在但在第二个关系中不存在的元组。
查询操作:
- 查询(Query):使用 SQL 或类似的查询语言从数据库中检索特定的数据。
基本操作:
- 插入(Insert):向关系中添加新的元组。
- 删除(Delete):从关系中删除特定的元组。
- 更新(Update):修改关系中的特定元组。
关系操作的特点:
- 封闭性(Closure):关系操作的结果仍然是一个关系。
- 可嵌套性(Nesting):关系操作可以嵌套在其他操作中使用。
- 无序性(Unordered):关系操作不依赖于元组的物理存储顺序,操作的结果和顺序无关。
- 确定性(Deterministic):对于相同的输入,关系操作总是产生相同的输出。
关系的完整性(三类完整性约束):实体、参照、用户定义
- 实体完整性约束(Entity Integrity):
确保关系中的每个元组都具有唯一标识符。通常通过以下方式实现:
主键(Primary Key):定义一个关系中的唯一标识符,保证每个元组都有唯一的标识符。主键必须保证非空且唯一。
2. 参照完整性约束(Referential Integrity):
确保关系之间的一致性。通过外键引用另一个关系中的主键来实现:
外键(Foreign Key):在一个关系中,指向另一个关系的主键,用于保证引用完整性。外键的值必须是另一个关系中存在的主键值或者为空(如果允许的话)。
3. 用户定义的完整性约束(User-Defined Integrity):
由用户根据特定业务规则定义的完整性约束,可以是业务规则、限制条件等。
自定义规则:根据特定业务需求定义的约束条件,例如保证价格大于零、日期在特定范围内等。
关系代数:集合运算、专门的关系运算、连接、投影、选择等
- 集合运算:
并(Union):合并两个关系,并去除重复的元组。
差(Difference):从一个关系中删除在另一个关系中存在的元组。
交(Intersection):获取两个关系中同时存在的元组。 - 专门的关系运算:
选择(Selection):按照给定条件从关系中选取满足条件的元组。
投影(Projection):从关系中选择特定的列,生成一个包含指定属性的新关系。
连接(Join):将两个关系合并,根据一个或多个共同属性(关联属性)进行匹配,产生一个新的关系。 - 其他关系操作:
笛卡尔积(Cartesian Product):返回两个关系的所有可能的组合。
除(Division):根据给定的条件从一个关系中选择出满足条件的元组组合,通常用于解决关系的分解问题。
关系模式和范式理论
关系模式指的是数据库中表的结构,描述了表的字段名、数据类型、键和约束等信息。它是一个关系的描述性信息,规定了数据如何被组织、存储和操作。
范式理论是数据库设计中的重要概念,用于确保数据库的结构和关系模式满足特定的规范和标准,以减少数据冗余和提高数据的一致性。范式分为多个级别(如第一范式至第五范式),每个级别都有特定的规则和条件
关系模式与属性依赖(一道大题):1、范式的基本概念2、5个判定定理3、依赖关系图4、分解法划分范式(到BCNF)
范式的基本概念:
范式分为多个级别,每个级别都有一组规则,以确保数据库设计中的数据组织结构达到特定的标准。
- 第一范式(1NF):确保每个属性具有原子性,不可再分。
- 第二范式(2NF):属性完全依赖于候选键,消除部分函数依赖。
- 第三范式(3NF):消除传递依赖,非主属性不能依赖于其他非主属性。
- BCNF(巴斯-科德范式):消除主属性对候选键的部分和传递依赖。
5个判定定理:
- 第一范式(1NF):属性是原子的。
- 第二范式(2NF):必须满足1NF,非主属性完全依赖于候选码。
- 第三范式(3NF):必须满足2NF,消除传递依赖。
- 巴斯-科德范式(BCNF):消除主属性对候选键的部分和传递依赖。
- 第四范式(4NF):消除多值依赖。
依赖关系图:
依赖关系图描述了数据模式中属性之间的依赖关系,可以用来分析范式。

分解法划分范式(到BCNF):
参考这篇博客:
【通俗易懂】关系模式范式分解教程 3NF与BCNF口诀!小白也能看懂-CSDN博客
在设计数据库时,如果一个关系模式不符合BCNF,就需要进行分解。这种分解通常使用函数依赖和依赖图,根据范式理论将关系模式分解为符合BCNF的子模式。
- 函数依赖:属性之间的依赖关系,用箭头表示。比如,A → B 表示 B 依赖于 A。
- 依赖图:用来描述函数依赖关系的图形化工具。
最小依赖集求法:
口诀: 右侧先拆单,依赖依次删。
** 还原即可删,再拆左非单。**


将关系模式R<U,F>分解为一个BCNF的基本步骤是
BCNF分解
1)先求最小依赖集,候码非码成子集
2)余下左侧全候码,完成BCNF题。
例.关系模式R,有U={A,B,C,D,E,G},F={B->G,CE->B,C->A,CE->G,B->D,C->D},将关系模式分解为3NF且保持函数依赖
将关系模式分解为3NF且保持函数依赖:
第一步:先求最小依赖集。可以发现CE->G多余,因此最小依赖集为F={B->G,CE->B,C->A,B->D,C->D}。
第二步:候码非码成子集。由于候选码为(CE)因此将CE->B划分出子集(BCE),而B->G,B->D左侧均不含主属性(C、E)中的任何一个故划分出(BG),(BD)
第三步:此时剩余依赖F={C->A,C->D}剩余元素{A,C,D}检查发现函数依赖左侧都是候选码即完成BCNF分解,如果不满足则继续分解余下的。
于是BCNF分解的最后结果为{(BG),(BD),(ACD),(BCE)}。
第三七八九章关系数据库标准语言SQL
数据的定义
数据查询

数据更新

视图

having where子句
简单查询和复合查询、嵌套查询(txt文档以及书上例题)
第四章 数据库设计与编程
数据库设计的步骤
需求分析
概念结构设计
逻辑结构设计
物理结构设计
数据库设计
数据库运行和维护
数据库设计中的各级模式

第五章 认识SQL Server 2016
认识符
p151
常量与变量
运算符
表达式
控制流语句
常用函数
第十章 存储过程和触发器
触发器
创建触发器
管理触发器
第十一章 数据库安全
数据库系统概论(第5版王珊)
第九章 数据查询处理和查询优化
(大题)优化树
- 首先拿到关系代数的式子,写成语法树形式
- 可以下移的选择移动到最底
- 把不需要的列投影去掉
- 分组:一个笛卡尔积(二元运算)分为一组
代数优化(查询优化)
第十章 数据库恢复技术
考试要点:概念题
事务的基本概念
事务
事务是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。事务和程序是两个概念。一般地讲,一个程序中包含多个事务。事务的开始与结束可以由用户显式控制。如果用户没有显式地定义事务,则由数据库管理系统按默认规定自动划分事务。在 SQL 中,定义事务的语一般有三条:
BEGIN TRANSACTION
COMMIT;
ROLLBACK:
事务的 ACID 特性
(1)原子性
事务是数据库的逻辑工作单位,事务中包括的诸操作要么都做,要么都不做。
(2)一致性
事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。
(3)隔离性
一个事务的执行不能被其他事务干扰。即一个事务的内部操作及使用的数据对其他并发事务是隔离的,并发执行的各个事务之间不能互相干扰。
(4持续性
持续性也称永久性 (Permannce),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其执行结果有任何影响。
故障的种类
1.事务内部的故障
事务内部的故障有的是可以通过事务程序本身发现的,有的是非预期的,不能由事务程序处理。事务故障意味着事务没有达到预期的终点(COMMIT 或者显式的 ROLLBACK),因此,数据库可能处于不正确状态。恢复程序要在不影响其他事务运行的情况下,强行回滚该事务,即撤销该事务已经作出的任何对数据库的修改,使得该事务好像根本没有启动一样。这类恢复操作称为事务撤销(UNDO)。
2.系统故障
系统故障是指造成系统停止运转的任何事件,使得系统要重新启动。发生系统故障时,一些尚未完成的事务的结果可能已送入物理数据库,从而造成数据库可能处于不正确的状态。为保证数据一致性,需要清除这些事务对数据库的所有修改。
3.介质故障
系统故障常称为软故障 (soft crash),介质故障称为硬故障 (hard crash)。硬故障指外存故障,如磁盘损坏磁头碰撞,瞬时强磁场干扰等。这类故障将破坏数据库或部分数据库,并影响正在存取这部分数据的所有事务。这类故障比前两类故障发生的可能性小得多,但破坏性最大。
4.计算机病毒
计算机病毒是一种人为的故障或破坏,是一些恶作剧者研制的一种计算机程序。这种程序与其他程序不同,它像微生物学所称的病毒一样可以繁殖和传播,并造成对计算机系统包括数据库的危害。
恢复实现技术
数据转储
(1)定义
转储即数据库管理员定期地将整个数据库复制到磁带、磁盘或其他存储介质上保存起来的过程。这些备用的数据称为后备副本(backup)或后援副本。
(2)方法
当数据库遭到破坏后可以将后备副本重新装入,但重装后备副本只能将数据库恢复到转储时的状态,要想恢复到故障发生时的状态,必须重新运行自转储以后的所有更新事务。转储是十分耗费时间和资源的,不能频繁进行。数据库管理员应该根据数据库使用情况确定一个适当的转储周期。
登记日志文件
(1)日志文件的格式和内容日志文件是用来记录事务对数据库的更新操作的文件。日志文件主要有以下两种格式:
①以记录为单位的日志文件
对于以记录为单位的日志文件,日志文件中需要登记的内容包括: 各个事务的开始标记;各个事务的结束标记:各个事务的所有更新操作。
每个日志记录的内容主要包括:事务标识: 操作的类型操作对象:更新前数据的旧值:更新后数据的新值
②以数据块为单位的日志文件
日志记录的内容包括事务标识和被更新的数据块。
(2)日志文件的作用
①事务故障恢复和系统故障恢复必须用日志文件。
②在动态转储方式中必须建立日志文件,后备副本和日志文件结合起来才能有效地恢复发生故障时的数据库。
③在静态转储方式中,也可以建立日志文件。当数据库毁坏后可重新装入后援副本把数据库恢复到转储结束时刻的正确状态,然后利用日志文件,把已完成的事务进行重做处理,对故障发生时尚未完成的事务进行撤销处理。这样不必重新运行那些已完成的事务程序就可把数据库恢复到故障前某一时刻的正确状态。
(3登记日志文件
为保证数据库是可恢复的,登记日志文件时必须遵循两条原则:
①登记的次序严格按并发事务执行的时间次序。
②必须先写日志文件,后写数据库。
第十一章 并发控制
考试要点(概念题)
并发控制概述
1. 并发控制的责任
事务是并发控制的基本单位,保证事务acid特性是事务处理的重要任务,而事务acid特性可能遭到破坏的原因之一是多个事务对数据库的并发操作造成的。为了保证事务的隔离性和一致性,DBMS需要对并发操作进行正确调度。这些就是数据库管理系统中并发控制机制的责任。
2.数据不一致及其原因
并发操作带来的数据不一致性主要包括丢失修改,不可重复读和读脏"数据。产生三类数据不一致性的主要原因是并发操作破坏了事务的隔离性。并发控制就是要用正确的方式调度并发操作,使一个用户事务的执行不受其他事务的干扰,从而避免造成数据的不一致性。并发控制的主要技术有封锁(locking),时间戳(timesamp)和乐观控制法,商用的dbms一般都采用封锁方
法。
封锁
封锁是事务 T 在对某个数据对象例如表、记录等操作之前,先向系统发出请求,对其加锁。加锁后事务 T就对该数据对象有了一定的控制,在事务T释放它的锁之前,其他事务不能更新此数据对象。
基本的封锁类型有两种: 排他锁 (exclusive locks,简称X锁) 和共享锁 (sharelocks,简称 S 锁)。
(1)排他锁
排他锁又称为写锁。若事务T对数据对象 A 加上X锁,则只允许T读取和修改 A,其他任何事务都不能再对 A 加任何类型的锁,直到 T释放A上的锁为止。
(2)共享锁
共享锁又称为读锁。若事务T对数据对象 A 加上 S 锁,则事务T可以读 A 但不能修改 A,其他事务只能再对A加S锁,而不能加锁,直到T释放A 上的S锁为止。
活锁和死锁
活锁
活锁是并发控制中的一种情况,类似死锁,但不同之处在于活锁是指系统一直在尝试重新执行一组操作,但最终无法进行,导致系统无法进展,尽管没有真正发生死锁。

死锁
死锁是指在多任务处理系统中,两个或多个进程或线程互相等待对方持有的资源而导致的一种僵局状态。在这种情况下,每个进程都在等待另一个进程所持有的资源,而同时又不释放自己持有的资源,导致所有进程都无法继续执行。

练习题
数据库系统~期末习题案例解析
设计题:
1.图书出版管理数据库中有两个基本表:
图书 (书号,书名,作者编号,出版社,出版日期);
作者 (作者编号,作者名,年龄,地址);
试用SQL语句写出下列查询:检索年龄低于作者平均年龄的所有作者的作者名、书名和出版社。
:::tips
解答:
SELECT 作者名,书名,出版社
FROM 图书,作者
WHERE 图书.作者编号 = 作者.作者编号
AND 年龄 < = (SELECT AVG (年龄) FROM 作者);
:::
2.学校有多名学生,财务处每年要收一次学费。为财务处收学费工作设计一个数据库,包括两个关系:
学生 (学号,姓名,专业,入学日期)
收费 (学年,学号,学费,书费,总金额)
假设规定属性的类型:学费、书费、总金额为数值型数据;学号、姓名、学年、专业为字符型数据;入学日期为日期型数据。列的宽度自定义。
试用SQL语句定义上述表的结构,(定义中应包括主键子句和外键子句)。
解答:
CREATE TABLE 学生
(学号 CHAR (8),
姓名 CHAR (8),
专业 CHAR (13),
入学日期 DATE,
PRIMARY KEY (学号));
CREATE TABLE 收费
(学年 CHAR (10),
学号 CHAR (8),
学费 NUMERIC (4),
书费 NUMERIC (5,2),
总金额 NUMERIC (7,2),
PRIMARY KEY (学年,学号),
FOREIGN KEY (学号) REFERENCES 学生 (学号));
3.现有关系数据库如下:
学生(学号,姓名,性别,专业,奖学金)
课程(课程号,名称,学分)
学习(学号,课程号,分数)
用关系代数表达式实现下列1—4小题:
(1).检索“英语”专业学生所学课程的信息,包括学号、姓名、课程名和分数。
(2).检索“数据库原理”课程成绩高于90分的所有学生的学号、姓名、专业和分数;
(3).检索不学课程号为“C135”课程的学生信息,包括学号,姓名和专业;
(4).检索没有任何一门课程成绩不及格的所有学生的信息,包括学号、姓名和专业;
用SQL语言实现下列5—8小题:
(5).检索不学课程号为“C135”课程的学生信息,包括学号,姓名和专业;
(6).检索至少学过课程号为“C135”和“C219”的学生信息,包括学号、姓名和专业;
(7).从学生表中删除成绩出现过0分的所有学生信息;
(8).定义“英语”专业学生所学课程的信息视图AAA,包括学号、姓名、课程号和分数。
解答:
(1).П学号,姓名,课程名,分数(σ专业=‘英语’(学生∞学习∞课程))
(2).П学号,姓名,专业,分数(σ分数>90∧名称=‘数据库原理’(学生∞学习∞课程))
(3).П学号,姓名,专业(学生)-П学号,姓名,专业(σ课程号=‘C135’(学生∞学习))
(4).П学号,姓名,专业(学生)-П学号,姓名,专业(σ分数<60(学生∞学习))
(5).SELECT 学号,姓名,专业
FROM 学生
WHERE 学号 NOT IN
(SELECT 学号
FROM 学习
WHERE 课程号=‘C135’);
(6).SELECT 学号,姓名,专业
FROM 学生
WHERE 学号 IN
(SELECT X. 学号
FROM 学习 AS X, 学习AS Y
WHERE X.学号=Y.学号 AND X.课程号=‘C135’ AND Y 课程号=’C219’);
(7).DELETE FROM 学生
WHERE 学号 IN
(SELECT 学号
FROM 学习
WHERE 分数=0)
(8).CREATE VIEW AAA(学号,姓名,课程号,分数);
AS SELECT 学号,姓名,课程号,分数
FROM 学生,学习
WHERE 学生.学号 =学习.学号 AND 专业=’英语’;
4.假设某商业集团数据库中有一关系模式R如下:
R (商店编号,商品编号,数量,部门编号,负责人)
如果规定:
(1) 每个商店的每种商品只在一个部门销售;
(2) 每个商店的每个部门只有一个负责人;
(3) 每个商店的每种商品只有一个库存数量。
试回答下列问题:
(1) 根据上述规定,写出关系模式R的基本函数依赖;
(2) 找出关系模式R的候选键;
(3) 试问关系模式R最高已经达到第几范式?为什么?
(4) 如果R不属于3NF,请将R分解成3NF模式集。
解答:
(1) 有三个函数依赖:(商店编号,商品编号) →部门编号
(商店编号,部门编号) →负责人
(商店编号,商品编号) →数量
(2) R的候选键是 (商店编号,商品编号)
(3) 因为R中存在着非主属性“负责人”对候选键 (商店编号、商品编号)的传递函数依赖,所 以R属于2NF,R不属于3NF。
(4) 将R分解成:R1 (商店编号,商品编号,数量,部门编号)
R2 (商店编号,部门编号,负责人)
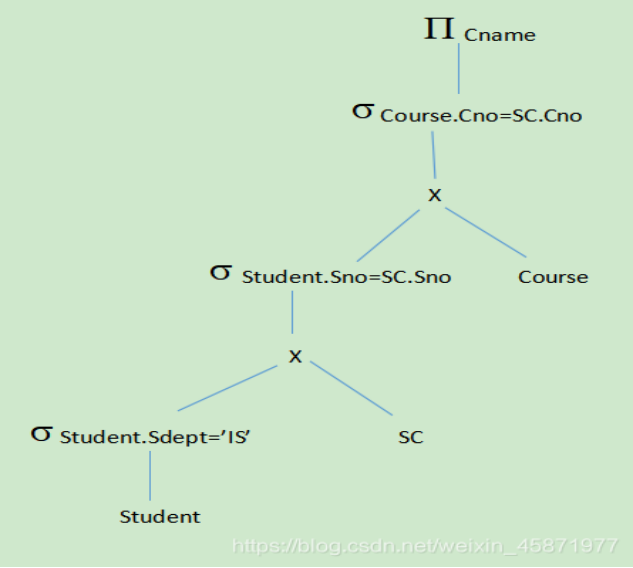
5.对学生-课程数据库,查询信息系学生选修了的所有课程名称。
试画出用关系代数表示的语法树,并用关系代数表达式优化算法对原始的语法树进行优化处理,画出优化后的标准语法树。
语法树:
解答:
SQL查询:
SELECT Cname
FROM Student,Course,SC
WHERE Student.Sno=SC.Sno AND Course.Cno=SC.Cno AND Student.Sdept=‘IS’;
原始的查询语法树:
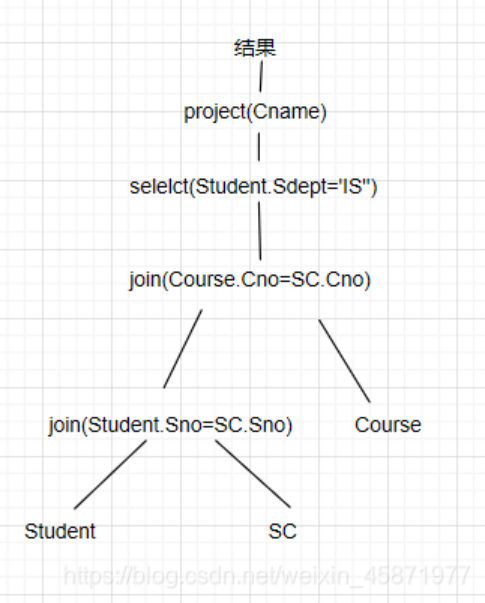
关系代数语法树:

优化后的关系代数语法树:
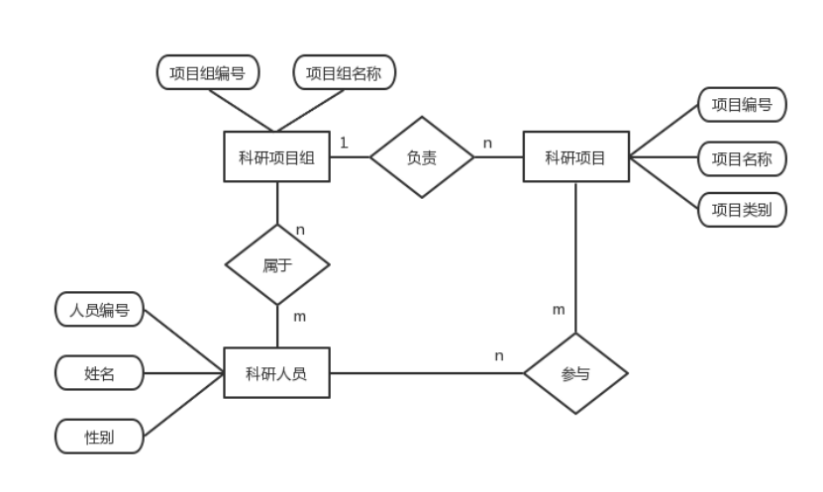
6.请设计某单位科研项目管理数据库,主要实体包括:
科研项目组,科研人员和科研项目。他们之间关系如下:每个科研项目组可以有多个科研人员,每个科研人员可以属于多个科研项目组;
每个科研项目组可以负责多个科研项目,每个科研项目只能有一个科研项目组负责;
每个科研人员可以参与多个科研项目的工作,每个科研项目由多个科研人员参与工作。
自己设计每类实体的主要属性,画出E-R图
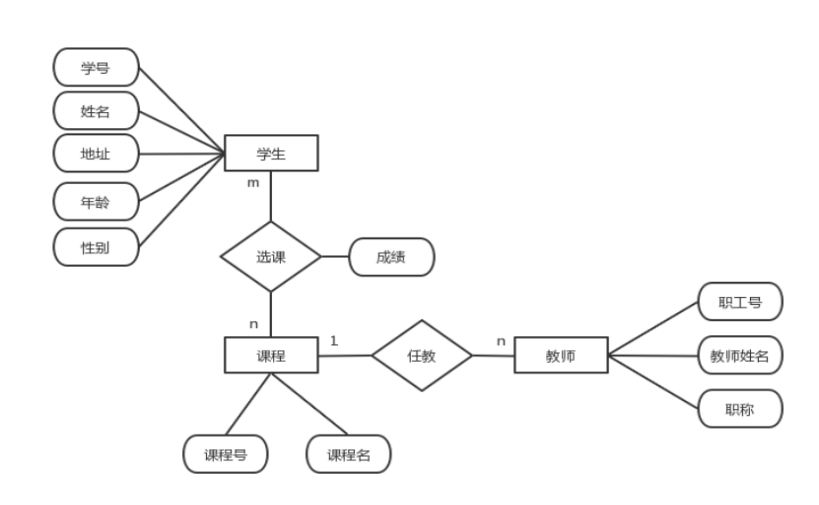
7.假设每个学生选修若干门选修课,每个教师只担任一门课的教学,一门课由若干教师任教。
“学生”属性为:学号,姓名,地址,年龄,性别;
“教师”属性为:职工号,教师姓名,职称;
“课程”属性为:课程号,课程名。
画出E-R图
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 蓝底白字车牌的定位与字符分割识别 MATLAB 仿真
- JAVA复习四——MultiThread、JDBC、Network programming
- 书生·浦语 LMDeploy 大模型量化部署原理
- 面试-面对面沟通题
- 【Vue3源码】第五章 实现 reactive 和 readonly 嵌套对象绑定响应式
- 会员互动服务平台,商协会会员管理解决方案
- React Query 实战教程:在 React 中如何优雅的管理接口数据状态?
- 平凯数据库亮相 2023 信息技术应用创新论坛
- 总线协议:GPIO模拟SMI(MDIO)协议(3):SMI协议测试
- 传输大咖02|「影视行业」大文件数据传输的高效加速利器