【RL】(task1)绪论、马尔科夫过程、动态规划、DQN(更新中)
note
一、马尔科夫过程
- 递归结构形式的贝尔曼方程计算给定状态下的预期回报,这样的方式使得用逐步迭代的方法就能逼近真实的状态/行动值。
有了Bellman equation就可以计算价值函数了 - 马尔科夫过程描述了一个具有无记忆性质的随机过程,未来状态只依赖于当前状态,与过去状态无关,类似于一个人在空间中的随机游走。
二、动态规划
动态规划:多阶段决策问题的方法,它将问题分解为一系列的子问题,并通过保存子问题的解来构建整体问题的解。
贝尔曼方程
\qquad 类比于回报公式 G t = R t + 1 + γ G t + 1 G_{t} = R_{t+1}+\gamma G_{t+1} Gt?=Rt+1?+γGt+1?,也可以对状态价值函数和动作价值函数做一个类似的推导,如下:
V π ( s ) = E π [ G t ∣ S t = s ] = E π [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + ? ∣ S t = s ] = E [ R t + 1 ∣ s t = s ] + γ E [ R t + 2 + γ R t + 3 + γ 2 R t + 4 + ? ∣ S t = s ] = R ( s ) + γ E [ G t + 1 ∣ S t = s ] = R ( s ) + γ E [ V π ( s t + 1 ) ∣ S t = s ] = R ( s ) + γ ∑ s ′ ∈ S P ( S t + 1 = s ′ ∣ S t = s ) V π ( s ′ ) = R ( s ) + γ ∑ s ′ ∈ S p ( s ′ ∣ s ) V π ( s ′ ) \begin{aligned} V_{\pi}(s) & =\mathbb{E}_{\pi}\left[G_t \mid S_t=s\right] \\ & =\mathbb{E}_{\pi}\left[R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\cdots \mid S_t=s\right] \\ & =\mathbb{E}\left[R_{t+1} \mid s_t=s\right]+\gamma \mathbb{E}\left[R_{t+2}+\gamma R_{t+3}+\gamma^2 R_{t+4}+\cdots \mid S_t=s\right] \\ & =R(s)+\gamma \mathbb{E}\left[G_{t+1} \mid S_t=s\right] \\ & =R(s)+\gamma \mathbb{E}\left[V_{\pi}\left(s_{t+1}\right) \mid S_t=s\right] \\ & =R(s)+\gamma \sum_{s^{\prime} \in S} P\left(S_{t+1}=s^{\prime} \mid S_{t}=s\right) V_{\pi}\left(s^{\prime}\right)\\ & =R(s)+\gamma \sum_{s^{\prime} \in S} p\left(s^{\prime} \mid s\right) V_{\pi}\left(s^{\prime}\right) \end{aligned} Vπ?(s)?=Eπ?[Gt?∣St?=s]=Eπ?[Rt+1?+γRt+2?+γ2Rt+3?+?∣St?=s]=E[Rt+1?∣st?=s]+γE[Rt+2?+γRt+3?+γ2Rt+4?+?∣St?=s]=R(s)+γE[Gt+1?∣St?=s]=R(s)+γE[Vπ?(st+1?)∣St?=s]=R(s)+γs′∈S∑?P(St+1?=s′∣St?=s)Vπ?(s′)=R(s)+γs′∈S∑?p(s′∣s)Vπ?(s′)?
\qquad 其中 R ( s ) R(s) R(s) 表示奖励函数, P ( S t + 1 = s ′ ∣ S t = s ) P(S_{t+1}=s^{\prime} \mid S_{t}=s) P(St+1?=s′∣St?=s)就是前面讲的状态转移概率,习惯简写成 p ( s ′ ∣ s ) p\left(s^{\prime} \mid s\right) p(s′∣s),这就是贝尔曼方程(Bellman Equation)。贝尔曼方程的重要意义就在于前面所说的满足动态规划的最优化原理,即将前后两个状态之间联系起来,以便于递归地解决问题。
\qquad 类似地,动作价值函数贝尔曼方程推导为:
Q π ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S p ( s ′ ∣ s , a ) ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) Q π ( s ′ , a ′ ) Q_{\pi}(s,a) = R(s,a) + \gamma \sum_{s^{\prime} \in S} p\left(s^{\prime} \mid s,a\right) \sum_{a^{\prime} \in A} \pi\left(a^{\prime} \mid s ^{\prime} \right)Q_{\pi}\left(s^{\prime},a'\right) Qπ?(s,a)=R(s,a)+γs′∈S∑?p(s′∣s,a)a′∈A∑?π(a′∣s′)Qπ?(s′,a′)
\qquad 前面我们提到状态价值函数的定义就是按照某种策略 π \pi π进行决策得到的累积回报期望,换句话说,在最优策略下,状态价值函数也是最优的,相应的动作价值函数也最优。我们的目标是使得累积的回报最大化,那么最优策略下的状态价值函数可以表示为:
V ? ( s ) = max ? a E [ R t + 1 + γ V ? ( S t + 1 ) ∣ S t = s , A t = a ] = max ? a ∑ s ′ , r p ( s ′ , r ∣ s , a ) [ r + γ V ? ( s ′ ) ] \begin{aligned} V^{*}(s)&=\max _a \mathbb{E}\left[R_{t+1}+\gamma V^{*}\left(S_{t+1}\right) \mid S_t=s, A_t=a\right] \\ &=\max_a \sum_{s',r}p(s',r|s,a)[r+\gamma V^{*}(s')] \end{aligned} V?(s)?=amax?E[Rt+1?+γV?(St+1?)∣St?=s,At?=a]=amax?s′,r∑?p(s′,r∣s,a)[r+γV?(s′)]?
\qquad
这个公式叫做贝尔曼最优方程(Bellman optimality equation),它对于后面要讲的策略迭代算法具有一定的指导意义。对于动作价值函数也是同理,如下:
Q
?
(
s
,
a
)
=
E
[
R
t
+
1
+
γ
max
?
a
′
Q
?
(
S
t
+
1
,
a
′
)
∣
S
t
=
s
,
A
t
=
a
]
=
∑
s
′
,
r
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
max
?
a
′
Q
?
(
s
′
,
a
′
)
]
\begin{aligned} Q^{*}(s, a) & =\mathbb{E}\left[R_{t+1}+\gamma \max _{a^{\prime}} Q^{*}\left(S_{t+1}, a^{\prime}\right) \mid S_t=s, A_t=a\right] \\ & =\sum_{s^{\prime}, r} p\left(s^{\prime}, r \mid s, a\right)\left[r+\gamma \max _{a^{\prime}} Q^{*}\left(s^{\prime}, a^{\prime}\right)\right] \end{aligned}
Q?(s,a)?=E[Rt+1?+γa′max?Q?(St+1?,a′)∣St?=s,At?=a]=s′,r∑?p(s′,r∣s,a)[r+γa′max?Q?(s′,a′)]?
DQN算法
DQN算法的基本思想是使用一个深度神经网络作为智能体的Q函数近似器。Q函数表示在给定状态下采取某个动作的预期回报值。算法通过不断地在环境中与智能体的交互过程中,收集样本数据,然后使用这些数据来训练Q网络,使其能够预测最优的行动选择。
DQN算法的训练过程可以分为以下几个步骤:
- 初始化一个深度神经网络作为Q函数的近似器。
- 在每个时间步,智能体观察当前的状态,并根据当前状态选择一个动作。选择动作时可以使用ε-greedy策略,即以ε的概率随机选择动作,以1-ε的概率选择当前Q值最高的动作。
- 智能体执行选择的动作,与环境进行交互,并观察得到的奖励和下一个状态。
- 将当前状态、选择的动作、得到的奖励和下一个状态组成一个样本,存储在经验回放缓冲区中。
- 从经验回放缓冲区中随机采样一批样本,用于训练Q网络。训练过程中使用目标Q网络和当前Q网络的差异来计算损失,并通过反向传播算法来更新网络参数。
- 定期更新目标Q网络的参数,将当前Q网络的参数复制给目标Q网络。
- 重复步骤2至步骤6,直到达到预先设定的停止条件或训练轮数。
通过这样的训练过程,DQN算法能够逐步优化Q网络的参数,使其能够更准确地预测每个状态下的最优动作,并实现智能体在环境中做出最优决策的能力。
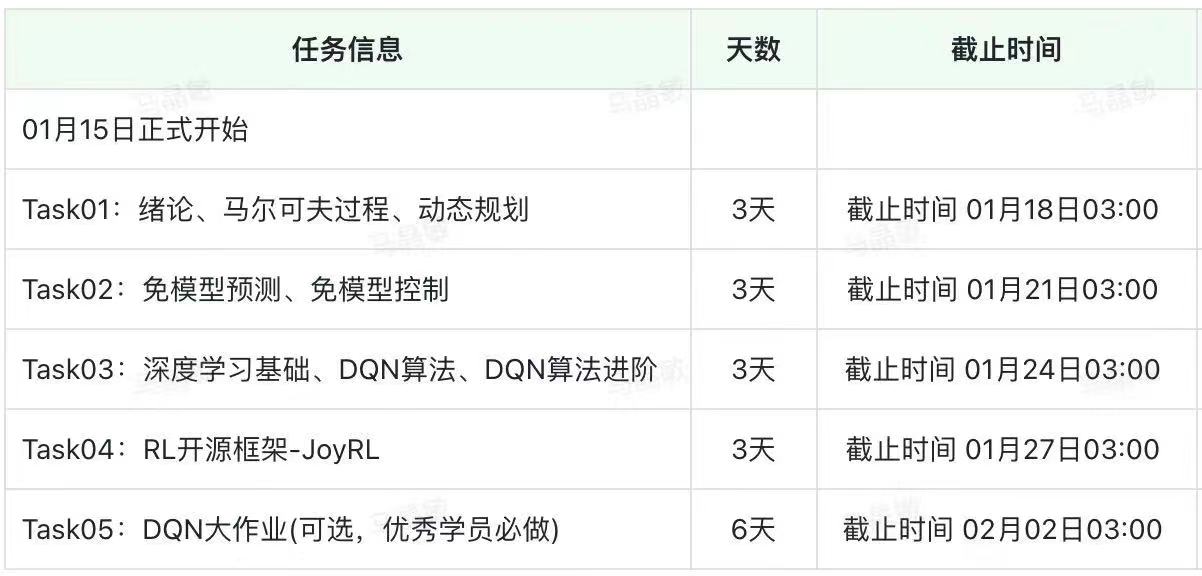
时间安排
| 任务 | 天数 | 截止时间 | 注意事项 |
|---|---|---|---|
| Task01: 绪论、马尔可夫过程、动态规划 | 3天 | 1月15周一-17日周三 | |
| Task02: 免模型预测、免模型控制 | 3天 | 1月18日周四-20周六 | |
| Task03: 深度学习基础、DQN算法、DQN算法进阶 | 3天 | 1月21日周日-23日周二 | |
| Task04: RL开源框架-JoyRL | 3天 | 1月24日周三-26日周五 | |
| Task05: DQN大作业 | 6天 | 1月27日周六-2月1号周四 |
Reference
[1] 开源内容https://linklearner.com/learn/detail/91
[2] https://github.com/datawhalechina/joyrl-book
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 文件管理秘籍:如何实现批量移动,每个文件夹仅存一个文件
- 合宙“全球通“模组Air795UG上市,支持4G+2G全球频段
- 数字经济浪潮:科技公司如何引领财经未来
- SpringBoot核心原理之事件和监听器(生命周期监听、事件触发、监听器、自定义事件发布和订阅)和配置类和Bean加载的时机
- 国科大图像处理2023速通期末——汇总2017-2019
- YOLOv8涨点技巧:一种新颖的多尺度滑窗注意力,助力小目标和遥感影像场景
- holo3:Event Time Column(Segment Key)聚簇索引Clustering Key
- 【代码学习】einops,更简单的张量变化
- 如何禁用USB接口?这些方法你都可以试试
- 对数器的作用(找bug)