【大模型】1、LoRA | 大模型高效微调技术

论文:LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
代码:https://github.com/microsoft/LoRA
出处:微软
一、背景
1.1 什么是秩
矩阵的秩是指其行(或列)向量生成的最大线性无关集合的大小。简单来说,就是一个矩阵中线性无关的行或列的最大数量。
矩阵的秩实际上表示了矩阵中线性无关向量(或者说信息)的数量。如果一个矩阵有很高的秩,那么它包含了大量不同方向或维度上的信息。换句话说,这个矩阵中包含了许多不同方向或维度上变化的数据。
相反,如果一个矩阵有很低的秩(比如接近0),那么它可能包含了大量冗余信息。也就是说,其中一些行或列可能只是其他行或列标量倍数操作得到。
因此,在处理数据时,理解和利用矩阵秩可以帮助我们识别和减少冗余信息,并专注于真正重要、能提供新见解和知识点的数据维度。
例如:
A = [ 1 2 3
4 5 6
7 8 9]
这个矩阵的秩为 2,我们可以看到第三行减去第二行等于第二行减去第一行(即[7 8 9] - [4 5 6] = [4 5 6] - [1 2 3]),因此这三个向量并不都是线性无关的。实际上,在这个例子中只有两个线性无关向量(例如,前两个),所以我们说这个矩阵的秩为2。
A = [[1, 2, 3],
[2, 4, 6],
[3, 6, 9]]
这个矩阵的秩为 1,我们可以看到第二行是第一行的两倍,第三行是第一行的三倍。因此,这三个向量(即矩阵的行)并不都是线性无关的。实际上,在这个例子中只有一个线性无关向量(例如,任意一个就行,也就是说任何一行都可以作为基来表示整个矩阵空间),所以我们说这个矩阵的秩为1。
1.2 为什么要用低秩
在大模型中,很多下游应用都是通过对大模型的微调来实现的,微调可以冻结部分参数,也可以不冻结参数,全部进行微调
一个大模型可能经过了好几个月的训练,参数量巨大,比如 GPT-3 有 175B 参数,一般很难微调
所以本文提出了低秩适配方法 Low-Rank Adaptation (LoRA) approach,冻结预训练大模型的参数不做改变,训练这里的 A 和 B 两个模块,A 的输入和大模型的输入维度一样,A 的输出为 r,这里的 r 就表示的秩的大小,可以为 1 或 2,B 的输出和大模型的输出维度一样,所以输出可以直接和大模型的输出相加即可。
-
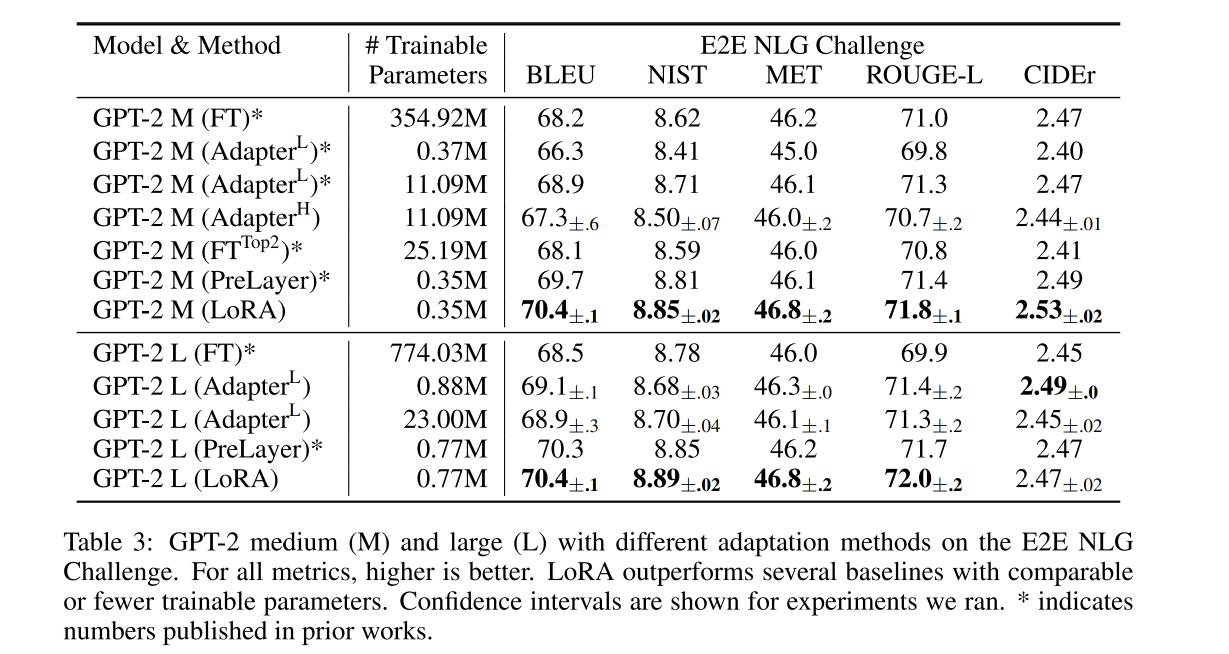
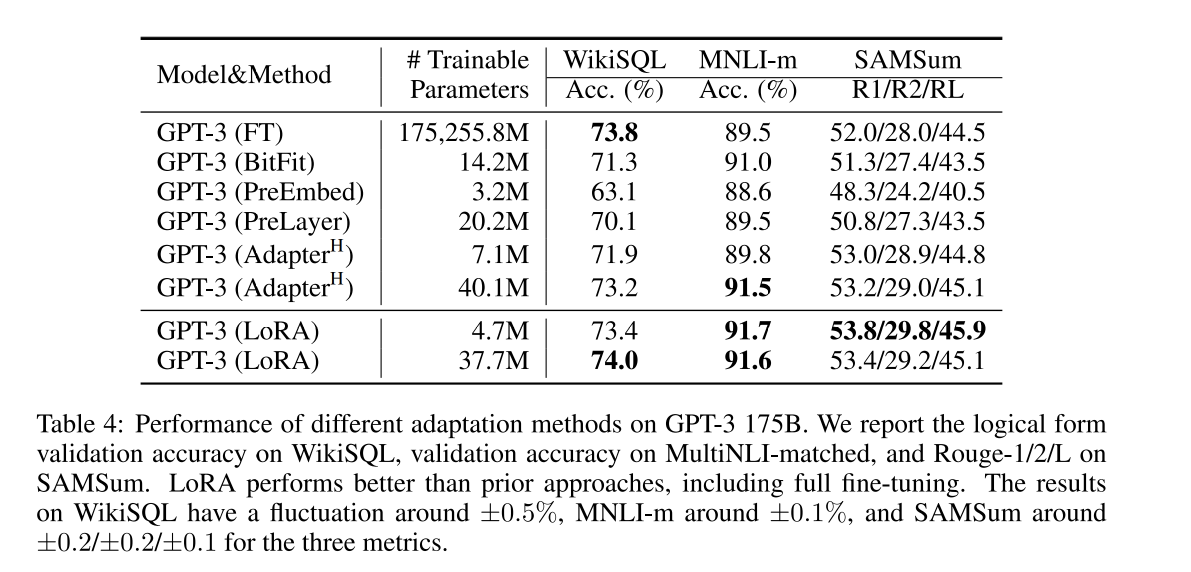
训练:LoRA 利用对应下游任务的数据,只训练新加部分参数来适配下游任务。以 GPT-3 的 175B 参数为例,使用很低的秩足以和使用满秩的结果媲美(满秩的秩为 12288),因此 LoRA 很有效且高效。
-
推理:而当训练好新的参数后,利用重参的方式,将新参数和老的模型参数合并,这样既能在新任务上到达fine-tune整个模型的效果,又不会在推断的时候增加推断的耗时。
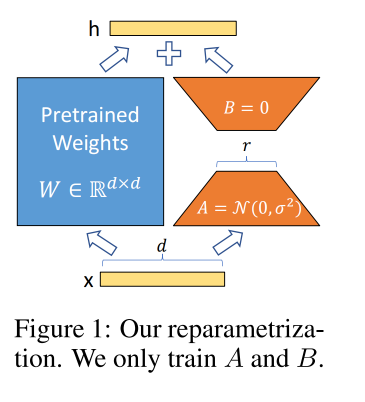
二、方法
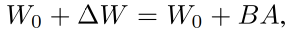
- W0:大模型的参数
- Δ W \Delta W ΔW:微调全参数时参数的变化量
- LoRA 的训练,冻结大模型的参数, 只训练 A 和 B
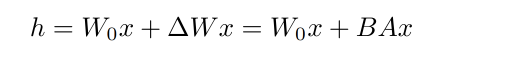
A 使用随机高斯初始化,B 初始化为 0,所以
Δ
W
=
B
A
\Delta W=BA
ΔW=BA 在开始训练的时候是 0,给
Δ
W
\Delta W
ΔW 加上权重系数
α
r
\frac{\alpha}{r}
rα? ,且
α
\alpha
α 是
r
r
r 中的一个常数。
当 α \alpha α 较小时,提取的是信息含量最丰富的维度,此时信息精炼,但不全面;当 α \alpha α 较大时,此时信息更加全面,但有很多冗余
所以,作者刚开始把 r 设置大,且让 α = r \alpha=r α=r,也就是刚开始的时候大模型的参数和新的低秩参数一样重要,随着实验的进行, r r r 降低, α \alpha α 不变,那么低秩参数就会越来越重要
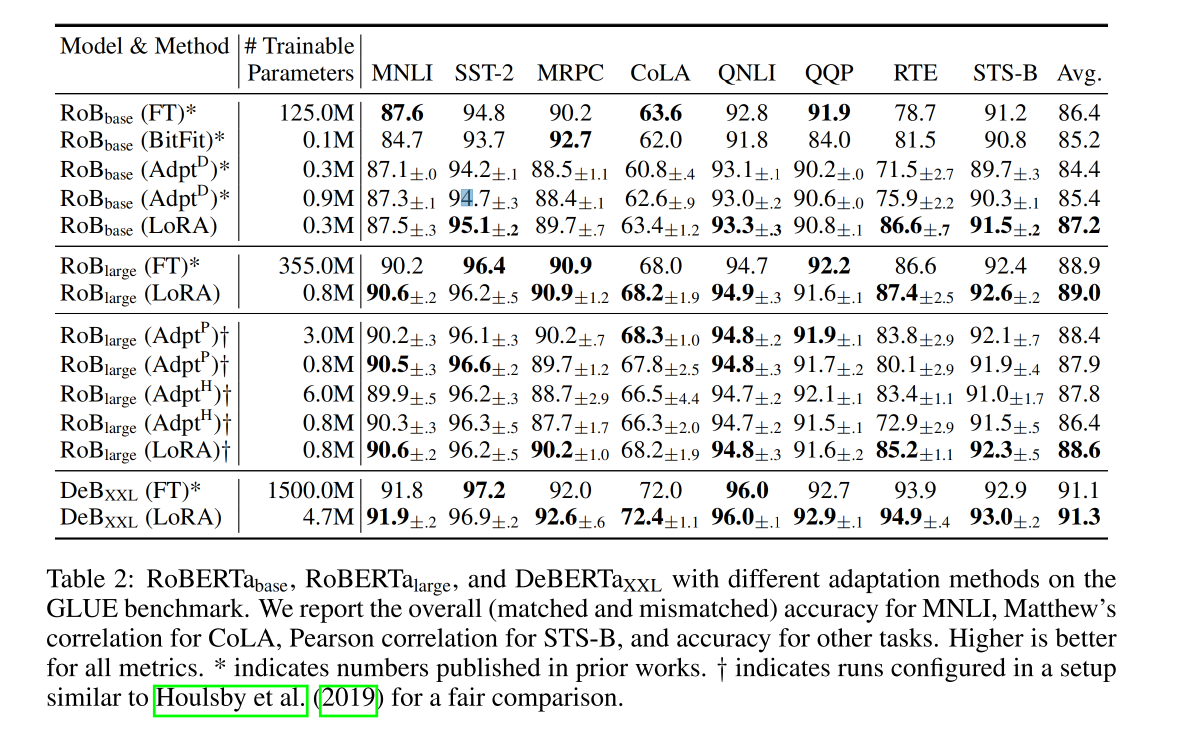
三、效果
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Call to undefined function app\install\controller\mysqli_connect()
- JS - 函数柯里化
- 玩转数据世界:跨工作空间的安全授权与高效查询
- 开发GPT的智能客服应用程序
- Leetcode—1099.小于K的两数之和【简单】Plus
- rk3566-Android11 从驱动到 app 第一章添加驱动程序
- 浅淡A100-4090-性价比
- uniapp组件库Popup 弹出层 的使用方法
- Mindspore 公开课 - BERT
- JAVA算法-查找