深度学习中的知识蒸馏
发布时间:2024年01月06日
一.概念
知识蒸馏(Knowledge Distillation)是一种深度学习中的模型压缩技术,旨在通过从一个教师模型(teacher model)向一个学生模型(student model)传递知识来减小模型的规模,同时保持性能。这个过程涉及到从教师模型的软标签(soft labels)或者特征中提取知识,然后用这些知识来训练一个更小的学生模型。
简单了解一些知识蒸馏的一般步骤和关键概念:
-
教师模型(Teacher Model):
教师模型是一个在任务上表现良好的大型深度神经网络。 它可以是一个复杂的模型,有着较大的参数容量。 -
学生模型(Student Model):
学生模型是一个规模较小的深度神经网络,通常是一个浅层或者窄层的模型,用于蒸馏知识。 -
软标签(Soft Labels):
由于教师模型输出的概率分布被称为软标签。 相对于传统的独热编码的硬标签,软标签包含了更多信息,可以提供模型输出的不确定性。 -
蒸馏过程:
使用教师模型来生成软标签,然后用这些软标签来训练学生模型。 在训练过程中,通常使用交叉熵损失函数来衡量学生模型的预测和教师模型的软标签之间的相似性。 -
特征蒸馏:
除了软标签,还可以通过特征蒸馏传递教师模型的中间层特征给学生模型。 这可以通过计算它们之间的距离(如均方误差)来实现。 -
温度参数(Temperature Parameter):
温度参数用于控制软标签的平滑程度,从而更好地传递知识。 较高的温度会导致软标签的概率分布更平滑。
二.知识蒸馏的优势包括:
知识蒸馏(Knowledge Distillation)具有多方面的优势,使其成为深度学习中一个受欢迎的技术。以下是知识蒸馏的一些主要优势:
模型压缩: 知识蒸馏可以帮助将复杂大模型的知识转移到更小、更轻量的学生模型中,实现模型的压缩。这对于在资源受限的设备上进行部署非常重要,例如移动设备和嵌入式系统。
推广性能提升: 通过从教师模型中蒸馏知识到学生模型,学生模型有可能学习到教师模型在训练数据上的泛化能力。这有助于提高学生模型的泛化性能,特别是在训练数据有限的情况下。
降低计算成本: 小型学生模型通常需要较少的计算资源和内存,可以更快地进行推理,降低了在实时或者边缘设备上运行的成本。
防止过拟合: 知识蒸馏的过程可以被视为一种正则化技术,可以帮助防止学生模型过度拟合训练数据。教师模型的知识的引入可以提供更多的约束,防止学生模型记住训练数据的噪声。
拓展模型应用: 通过知识蒸馏,可以将在大规模任务上训练的复杂模型中的知识迁移到适用于资源有限环境的小型模型,从而扩展了模型在不同应用场景的应用范围。
训练效率提高: 学生模型的训练通常比教师模型更快,因为学生模型更简单,参数更少。这使得在相同的计算资源下,可以更迅速地完成训练过程。
知识蒸馏是一种强大的技术,被广泛应用于各种深度学习任务,包括图像分类、目标检测、自然语言处理等。
三.大模型下的知识蒸馏
在深度学习中,知识蒸馏(Knowledge Distillation)在大模型下尤其有用。大模型通常包含大量的参数,因此在计算和内存方面的要求更高,而知识蒸馏可以帮助将大模型中的知识迁移到小型模型中,从而实现模型的压缩。
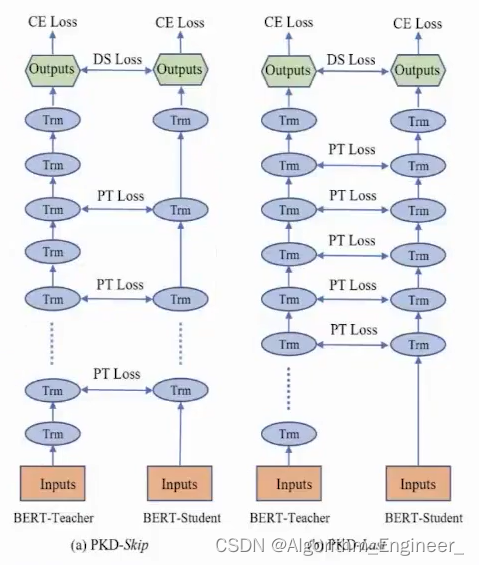
下面的图片来自于
https://arxiv.org/pdf/1908.09355.pdf
具体细节参考相应的论文
知识蒸馏的应用领域:
移动端应用: 在移动设备上,资源有限,而知识蒸馏为在这些设备上运行更轻量的模型提供了解决方案。
边缘计算: 边缘设备上的计算资源有限,因此需要轻量级的模型,知识蒸馏有助于在这些环境中实现高效的深度学习应用。
实时推理: 对于要求实时推理的任务,知识蒸馏使得模型能够更快地进行预测,适应性更强。
节能环境: 通过使用小型模型,可以减少模型的计算需求,从而在云计算等环境中节省能源。
知识蒸馏的挑战和未来发展方向:
泛化性能: 知识蒸馏的一个挑战是确保学生模型在未见过的数据上能够具有较好的泛化性能。
超参数调整: 温度参数和其他超参数的选择可能对知识蒸馏的效果产生显著影响,需要仔细的调整。
对抗攻击: 知识蒸馏可能对对抗性攻击更为敏感,因此需要考虑模型的安全性。
自动化方法: 未来的发展方向可能包括自动化方法,以更有效地确定适用于特定任务的知识蒸馏超参数。
跨模态蒸馏: 将知识蒸馏扩展到跨模态任务,如图像到文本的转换,是一个有趣的研究方向。
文章来源:https://blog.csdn.net/qq_37977007/article/details/135433253
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 仓储物流RFID智能管理设计解决方案
- PWM实现蜂鸣器
- Echarts使用,Echarts图表自适应窗口大小
- Spring——Spring IOC(1)
- 真香!EasyExcel实现Excel百万级数据导入导出,高效低内存占用
- 跨境电商如何通过API选品文章
- 与机器视觉兄弟们共勉,学习上多吃苦多吃亏,否则只能做低级别工作
- TypeScript
- python 解决手机拍的书籍图片发灰的问题
- http网络编程——在ue5中实现文件传输功能