基于Streamlit的中风患者预测
目录
引言
本项目来源于学期末的机器学习实践课程设计,课程要求使用Streamlit制作简易前端进行呈现。其中项目所涉及很多方法也是通过搜索学习和模仿其他大佬的。由于技术有限,完成作业时也遇到了很多问题,如数据不平衡、模型优化等,最终也是勉强完成。故将本次作业记录下来,希望和大家一起学习进步。当然,项目目前仍存在诸多不足,欢迎各位前辈和大佬不吝赐教!
一、项目背景及数据处理
1.1 项目背景和数据来源
中风也叫脑卒中,是中医学对急性脑血管疾病的统称。中风是严重危害人类健康和生命安全的常见的难治性疾病。本项目将基于随机森林、LightGBM等集成学习算法,通过包含年龄、心脏病、高血压等10项诊断指标的数据集学习并挖掘信息,构建一个能够预测患者是否中风的模型,以期帮助大家预防和发现可能的病因,减少中风患病率,增强社会幸福感。
数据来源:Brain Stroke Dataset | Kaggle
1.2?数据预处理
读取数据发现:数据集中并无重复值和缺失值,但特征类别不一。故数据处理部分只做离散特征转换,以便数据可视化中热力图的绘制。

数据处理核心代码:
for col in df.columns:
if df[col].dtype == 'object':
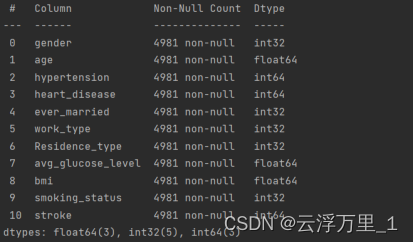
df[col] = LabelEncoder().fit_transform(df[col])效果展示:
二、EDA
本项目从单变量分析到多变量分析,逐个查看各特征与目标值之间的关系,通过对各特征的可视化,对其相关性做出初步判断与预测。注意,这里单变量分析为更清晰看出离散型特征的分布情况,采用未转换前的数据。多变量分析绘制热力图时,采用转换后的数据。
2.1 单变量分析

观察上图:
1.不同性别之间的中风率没有太大的区别。
2.60岁以上容易中风。
3.高血压在高龄人群中常见,且高血压可能会导致中风。
4.患有心脏病中风人数占比17.09%,显而易见比未患有心脏病中风人群占比大。

观察上图:
1.已婚人士的中风率更高。
2.在私有企业和个体自营工作的人群患中风的风险更高。
3.居住类型对中风患者影响差异不大。
4.中风患者的平均血糖水平偏高。
5.BMI和吸烟对中风几率影响不大。
2.2 多变量分析

观察热力图:
扫视整个热力图,哪些区域颜色较深,表示数据值较高,哪些区域较浅则表示值较低,可大致了解数据分布情况。
初步推测: 特征age,hypertension,heart_disease,ever_married与stroke标签是比较相关的。 后续通过特征工程进一步确认。
核心代码:
st.write('#### 1、性别')
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
# ax[0].bar(df['gender'].value_counts().index, df['gender'].value_counts().values)
ax[0].set_title('数据性别分布')
# ax[0].set_xlabel('性别')
# ax[0].set_ylabel('数量')
ax[0].pie(df['gender'].value_counts(), labels=df['gender'].value_counts().index, shadow=True, autopct='%1.1f%%', explode=(0.1,0))
# sns.countplot(data=df, x='gender',ax=ax[0])
sns.countplot(data=df, x='gender', hue='stroke',ax=ax[1])
plt.title('中风性别分布柱状图')
plt.xlabel('性别')
plt.ylabel('数量')
st.pyplot()
st.write('虽然数据集中男女性别并不完全平衡。但还是能够看出,不同性别之间的中风率没有太大的区别')
st.write('---------------------------')
st.write('#### 2、年龄')
# df['age'].nunique() # nunique()函数返回一个整数,表示年龄列中不同年龄的数量。
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
sns.histplot(data=df, x='age', ax=ax[0])
ax[0].set_title('数据年龄分布直方图')
ax[0].set_xlabel('年龄')
ax[0].set_ylabel('数量')
sns.boxplot(data=df, x='stroke', y='age', hue='stroke', ax=ax[1])
plt.title('中风与年龄的关系')
plt.xlabel('中风')
plt.ylabel('年龄')
st.pyplot()
st.write('数据中年龄这一特征几乎包含所有年龄段。')
st.write('由图分析可知,60岁以上容易中风。')
st.write('---------------------------')
st.write('#### 3、高血压')
# fig = plt.figure(figsize=(8, 5))
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
sns.boxplot(data=df, x='hypertension', y='age',hue='hypertension', ax=ax[0])
ax[0].set_title('年龄与高血压的关系')
ax[0].set_xlabel('高血压')
ax[0].set_ylabel('年龄')
sns.countplot(data=df, x='hypertension', hue='stroke', ax=ax[1])
plt.title('高血压与中风的关系')
plt.xlabel('高血压')
plt.ylabel('数量')
st.pyplot()
st.write('如果患者没有高血压,则为0,如果患者患有高血压,则为1。')
st.write('观察发现,高血压在高龄人群中常见,且高血压会可能导致中风。')
st.write('---------------------------')
st.write('#### 4、心脏病')
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
ax[0].set_title('心脏病与中风的关系')
ax[0].set_xlabel('心脏病')
ax[0].set_ylabel('数量')
sns.countplot(data=df, x='heart_disease', hue='stroke', ax=ax[0])
# heart_disease_stroke = df[df['heart_disease'] == 0]['stroke'].value_counts()
# labels = ['No Stroke', 'Stroke']
# ax[0].pie(heart_disease_stroke, labels=labels, shadow=True, autopct='%.2f%%', explode=(0.1,0))
# ax[0].set_title('未患有心脏病中风情况')
heart_disease_stroke = df[df['heart_disease'] == 1]['stroke'].value_counts()
labels = ['No Stroke', 'Stroke']
ax[1].pie(heart_disease_stroke, labels=labels, shadow=True, autopct='%.2f%%', explode=(0.1,0))
plt.title('患有心脏病中风情况')
st.pyplot()
st.write('如果患者没有心脏病,则为0,如果患者患有心脏病,则为1')
st.write('观察饼图,患有心脏病中风人数占比17.09%,显而易见比未患有心脏病中风人群占比大')
st.write('---------------------------')
st.write('#### 5、婚姻状况')
sns.countplot(data=df, x='ever_married', hue='stroke')
plt.title('婚姻状况与中风的关系')
plt.xlabel('婚姻状况')
plt.ylabel('数量')
st.pyplot()
st.write('数据显示已婚人士的中风率更高')
st.write('---------------------------')
st.write('#### 6、工作类型')
sns.countplot(data=df, x='work_type', hue='stroke')
plt.title('工作类型与中风的关系')
plt.xlabel('工作类型')
plt.ylabel('数量')
st.pyplot()
st.write('在私有企业和个体自营工作的人群患中风的风险更高。从未工作过的人中风率非常低')
st.write('---------------------------')
st.write('#### 7、居住类型')
sns.countplot(data=df, x='Residence_type', hue='stroke')
plt.title('居住类型与中风的关系')
plt.xlabel('居住类型')
plt.ylabel('数量')
st.pyplot()
st.write('居住类型对中风患者影响差异不大')
st.write('---------------------------')
st.write('#### 8、血糖水平')
fig = plt.figure(figsize=(8, 5))
sns.boxplot(data=df, x='stroke', y='avg_glucose_level', hue='stroke')
plt.title('血糖水平与中风的关系')
plt.xlabel('中风')
plt.ylabel('血糖水平')
st.pyplot()
st.write('如果患者没有糖尿病,则为0,如果患者患有糖尿病,则为1')
st.write('观察显示:中风患者的平均血糖水平偏高')
st.write('---------------------------')
st.write('#### 9、bmi')
fig = plt.figure(figsize=(8, 5))
df['bmi'].nunique()
sns.boxplot(data=df, x='stroke', y='bmi', hue='stroke')
plt.title('bmi与中风的关系')
plt.xlabel('中风')
plt.ylabel('bmi')
st.pyplot()
st.write('BMI对中风几率影响不大')
st.write('---------------------------')
st.write('#### 10、吸烟')
fig = plt.figure(figsize=(8, 5))
sns.countplot(data=df, x='smoking_status', hue='stroke')
plt.title('吸烟与中风的关系')
plt.xlabel('吸烟')
plt.ylabel('数量')
st.pyplot()
st.write('无论吸烟状况如何,中风的几率都没有太大差异')
st.write('---------------------------')
st.header('二、多变量分析')
corrdf = df.corr()
corrdf = corrdf.sort_values('stroke', ascending=False)
fig = plt.figure(figsize=(8, 5))
sns.heatmap(corrdf, annot=True, cmap='RdBu_r')
st.pyplot()三、特征工程
特征工程是机器学习和数据挖掘过程中非常重要的一个步骤。主要目标是从原始数据中派生出描述数据模式的特征,这些特征可以提高机器学习模型的性能。本项目涉及有数据清洗,特征选择,平衡数据集等步骤。
3.1 离散特征转换
和数据预处理部分一致。只不过为丰富Streamlit网页端,这部分代码又重复放在子页面文件。处理成功读取前五行看一下:

3.2 特征选择
根据之前绘制的热力图,我们已初步判断不是所有的特征都对最终的预测有帮助。因此,为快速选择前 k 个最相关的特征进行模型训练,项目采用了SelectKBest方法。 根据最终结果,我们选取前五个最相关的特征:age、heart_disease、avg_glucose_level、hypertension、ever_married。如图:

核心代码:
classifiers = SelectKBest(score_func=f_classif, k=5)
# 用于计算训练数据的均值和方差
fits = classifiers.fit(df.drop('stroke', axis=1), df['stroke'])
# DataFrame可以存放数值、字符串等,同时DataFrame 可以设置列名columns与行名index
x = pd.DataFrame(fits.scores_)
columns = pd.DataFrame(df.drop('stroke', axis=1).columns)
# concat函数是pandas底下的方法,可以把数据根据不同的轴进行简单的融合
fscores = pd.concat([columns, x], axis=1)
fscores.columns = ['特征', '得分']
# sort_values()是pandas中比较常用的排序方法,其主要涉及以下三个参数:
# by : str or list of str(字符或者字符列表)
# Name or list of names to sort by.
# 当需要按照多个列排序时,可使用列表
# ascending : bool or list of bool, default True
# (是否升序排序,默认为true,降序则为false。如果是列表,则需和by指定的列表数量相同,指明每一列的排序方式)
fscores.sort_values(by='得分', ascending=False)
st.write(fscores)
#直接删除不相关特征
features_to_drop = ['bmi', 'work_type', 'smoking_status', 'Residence_type', 'gender']
data = df.drop(columns=features_to_drop, axis=1)3.3 平衡数据集
从上文可视化显而易见数据是极度不平衡的,这里使用SMOTE算法对训练数据和测试数据进行过采样处理分类问题中的数据不平衡。
相比简单复制少数类样本的过采样,SMOTE生成新的样本,增加了数据集的多样性,减轻了过拟合问题。这里查看前后数据集维度看一下数据平衡如何:

核心代码:
X = data.drop('stroke', axis=1)
y = data['stroke']
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=1)
#平衡数据集
smote = SMOTE(random_state=1)
X_train, y_train = smote.fit_resample(X_train, y_train)
X_test, y_test = smote.fit_resample(X_test, y_test)
st.write('平衡前训练集、测试集的数据维度:', X_train.shape, X_test.shape, y_train.shape, y_test.shape)
st.write('平衡后训练集、测试集的数据维度:', X_train.shape, X_test.shape, y_train.shape, y_test.shape)四、模型构建
本项目为二分类问题,因此我选择了集成学习中的两种典型模型:随机森林和LightGBM。
模型评估部分计算了精确率、准确率、召回率、F1分数和混淆矩阵等指标,来评估模型预测的质量。还绘制了ROC_AUC曲线图。
4.1 随机森林模型
随机森林中使用了“Bagging”的集成学习思想,属于并行集成算法。它通过构建多棵决策树,并在训练和预测中进行投票平均,能很好地减少模型的过拟合问题,提高泛化能力。其参数包括决策树个数,特征子集大小等。
核心代码:
st.sidebar.header('参数滑块控件')
st.sidebar.write('#### 随机森林参数')
n_es = st.sidebar.slider(label='n_estimators',
min_value=100,
max_value=500,
value=300,
step=50)
m_d = st.sidebar.slider(label='max_depth',
min_value=5,
max_value=10,
value=5,
step=1)
rf=RandomForestClassifier(n_estimators=n_es,random_state=1,max_depth=m_d)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
accu = accuracy_score(y_test, y_pred)
prec = precision_score(y_test, y_pred) # 精确率
reca = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
fpr, tpr, thresholds = roc_curve(y_test, y_pred)?
#评估指标
evaluation = pd.DataFrame({'准确率': [],
'精确率': [],
'召回率': [],
'F1 值': []})
evaluation.loc[0] = [accu, prec, reca, f1]
st.write('随机森林模型评估参数')
st.write(evaluation)
st.write('混淆矩阵:')
st.write(confusion_matrix(y_test, y_pred))参数部分我选择了n_estimators(构成随机森林的决策树数量)和max_depth(决策树的最大深度)。前者就是随机森林里的树木数量,通常取100-500之间。树木越多,模型越不易过拟合,但计算复杂度也越高。后者决定了其复杂程度,深度越大则容易过拟合。一般取值在5-10之间。为使结果复现,还使用了随机种子。模型效果展示:

模型各项评估参数不是非常理想,下面使用交叉验证来实现其超参数优化。
核心代码:
# 优化
param_grid = {'n_estimators': [100, 200, 300, 400, 500],
'max_depth': [5, 6, 7, 8, 9, 10]}
rf = RandomForestClassifier()
model = GridSearchCV(rf,param_grid,cv = 5,scoring='roc_auc',error_score='raise')
model.fit(X_test, y_test)
print(f'当前最佳参数{model.best_params_}')
print(f'当前最佳分数{model.best_score_}')
结果显示,GridSearchCV调参优化的最优参数为(400,10)。但调整参数以后,评估参数反倒减小。
可能因为GridSearchCV是在训练集上调参的,但模型最终效果是在测试集上评估的,而训练集和测试集存在分布偏差,结果不同也很常见。下面换一种模型。
4.2 LightGBM模型
LightGBM对稀疏特征和小批量数据处理效果很好。中风预测数据的特征维度高但样本量相对小,LightGBM可以发挥优势。 这里直接进行优化,优化方法采用了验证集和early stopping的组合策略,来训练出一个避免过拟合的LightGBM模型。
核心代码:
#省略了相关参数滑块控件的相关代码,和上文随机森林的大致相似,这里不做赘述。
params = {
'boosting_type': 'gbdt', # 使用gbdt提升方法
'objective': 'binary', # 二分类任务
'metric': 'auc', # 使用AUC作为评估指标
'num_leaves': 30, # 每棵树的叶子节点数
'learning_rate': learning_rate, # 学习率
'feature_fraction': feature_fraction, # 特征子抽样比例
'bagging_fraction': 0.8, # 数据子抽样比例
'bagging_freq': 0, # 每5轮迭代进行一次bagging
'max_bin': max_bin,
'min_data_in_leaf': min_data_in_leaf,
'verbose': -1
}
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train) # 参考数据集lgb_train
callbacks = [early_stopping(stopping_rounds=500)]
gbm = lgb.train(params, # 模型参数
lgb_train, # 训练数据集
num_boost_round=2000, # 迭代次数
valid_sets=lgb_eval,# 验证数据集
callbacks=callbacks)
probs = gbm.predict(X_test, num_iteration=gbm.best_iteration) # print(probs) # [0.]
y_pred_2 = (probs > 0.5).astype(int) # 将预测结果转换为二进制标签
accu = accuracy_score(y_test, y_pred_2)
fpr2, tpr2, thresholds2 = roc_curve(y_test, y_pred_2)
prec = precision_score(y_test, y_pred_2) # 精确率
reca = recall_score(y_test, y_pred_2)
f1 = f1_score(y_test, y_pred_2)
evaluation = pd.DataFrame({'准确率': [],
'精确率': [],
'召回率': [],
'F1 值': []})
evaluation.loc[0] = [accu, prec, reca, f1]
st.write('LightGBM模型评估参数')
st.write(evaluation)
st.write('混淆矩阵:')
st.write(confusion_matrix(y_test, y_pred_2))结果显示:使用LightGBM算法的评估参数相比随机森林提高了不少。

4.3?ROC-AUC曲线图比较
该章节将对本项目所用模型进行汇总,通过绘制ROC_AUC曲线图来直观展示分类模型在不同条件下的表现,是评价和分析模型预测能力的有效工具。
其中ROC曲线直观显示了显示了真正率与假正率的关系。AUC值度量了模型预测正类和负类样本的能力,值越大表示分类性能越好。
核心代码:
st.write('#### 3.ROC-AUC曲线图比较')
fpr, tpr, thresholds = roc_curve(y_test, probs) # 随机森林
fpr2, tpr2, thresholds2 = roc_curve(y_test, probs)
roc_auc = auc(fpr, tpr)
roc_auc2 = auc(fpr2, tpr2)
print(roc_auc2)
fig = plt.figure(figsize=(8, 5))
plt.title('ROC-AUC 曲线图')
plt.plot(fpr, tpr, 'b', label='AUC = %0.3f' % roc_auc)
plt.plot(fpr2, tpr2, 'r', label='AUC2 = %0.3f' % roc_auc2)
plt.legend(loc='best')
plt.plot([0, 1], [0, 1], 'b--') #设置浅蓝色虚线
plt.xlim([0, 1]) #x轴范围
plt.ylim([0, 1]) #y轴范围
plt.ylabel('真正例率(召回率)')
plt.xlabel('假正例率')
st.pyplot(fig)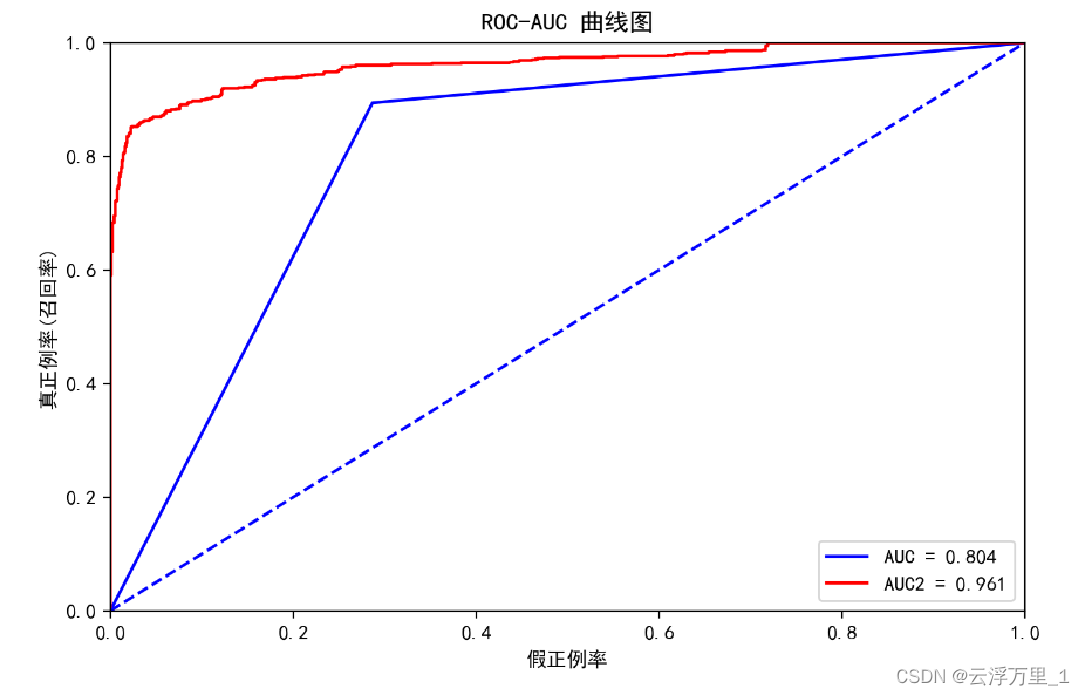
观察上图可以看出:LightGBM模型的预测性能明显优于随机森林模型。因为LightGBM的AUC值为0.961,高于随机森林的0.804。AUC值越高表示模型预测正样本和负样本的能力越好。
这表明LightGBM模型有非常好的区分正负样本的能力。其AUC值接近1,说明模型几乎能够完美地对所有可能的正负样本进行正确的分类。这是一个极好的结果。而随机森林模型的预测能力一般,AUC值为0.804,高于0.5(代表随机猜测)但没有超过0.9的较好水平。模型可能对某些类型的样本存在误分类现象。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- UDP协议基本原理
- 深入解析 Spring 的 @Autowired:自动装配的魔法与细节
- 使用Pycharm给html文件添加浏览器
- 探索TVM:深度学习模型编译与部署的前沿与实践【文末送书-14】
- 每日OJ题_算法_滑动窗口②_力扣3. 无重复字符的最长子串
- Educational Codeforces Round 157 (Rated for Div. 2)
- 【Angular教程240104】01 目录结构分析 创建组件 声明属性的方式、ts定义属性、绑定数据、绑定属性0
- 测试新字符设备驱动代码
- 如何使用网络测试仪构造特殊流量
- 为何浮点数不能精确表示?——浮点数在计算机中的存储方式