C++ UTF-8与GBK字符的转换 —基于Windows (MultiByteToWideChar WideCharToMultiByte)
发布时间:2024年01月06日
1、UTF-8 和 GBK 的区别
GBK:通常简称 GB? (“国标”汉语拼音首字母),GBK 包含全部中文字符。
UTF-8 :是一种国际化的编码方式,包含了世界上大部分的语种文字(简体中文字、繁体中文字、英文、日文、韩文等语言),也兼容 ASCII 码。UTF-8 则包含全世界所有国家需要用到的字符。
2、UTF-8 和 GBK 的作用:
这两种编码方式的的作用就是,在不同的应用环境中使用特定的编码方式
如果输入字符编码是UTF-8,如果想要将信息转换为汉字呈现在显示器上,就必须进行GBK转码操作,才能在显示屏上看到信息;
如果输入字符编码是GBK,如果想要在系统操作中让嵌入式设备或者编程环境认知它,就需要进行UTF-8转码操作。
3、UTF-8 和 GBK 之间如何转换:
在字符转换的过程中,二者不可以直接进行转换,必须借助于unicode
3.1、UTF-8转GBK
UTF-8——unicode——GBK
3.2、GBK转UTF-8
GBK——unicode——UTF-8
4、UTF-8 和 GBK 之间转换——C++代码:
4.1、UTF-8转GBK
首先写一个函数,定义如何转码
4.1.1、统计转换后的字节数 使用内置函数
现在格式是UTF8,即CP_UTF8.
int len = MultiByteToWideChar(CP_UTF8, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);4.1.2、用wtring存储数据,并为其分配大小
wstring udata; //用wstring存储的
udata.resize(len);//分配大小?4.1.3、UTF-8转unicode。
将数据写进去,将数据强转为wchar_t类型,适用于windows和linux。
MultiByteToWideChar(CP_UTF8, 0, data, -1, (wchar_t*)udata.data(), len);?4.1.4、unicode转GBK。
现在格式转成GBK,即CP_ACP。和UTF-8的参数数量不一样哦
len = WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);?4.1.5、配置字符大小,转成GBK
utf8.resize(len);
WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, (char*)utf8.data(), len, 0, 0);4.1.6、 UTF-8转GBK完整代码
string UTF8ToGBK(const char* data)
{
string utf8 = "";
//1、UTF8 先要转为unicode windows utf16
//1.1 统计转换后的字节数
int len = MultiByteToWideChar(CP_UTF8, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);
if (len <= 0)
{
return utf8;
}
wstring udata; //用wstring存储的
udata.resize(len);//分配大小
//开始写进去
MultiByteToWideChar(CP_UTF8, 0, data, -1, (wchar_t*)udata.data(), len);
//2 unicode 转 GBK
len = WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);
if (len <= 0)
{
return utf8;
}
utf8.resize(len);
WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, (char*)utf8.data(), len, 0, 0);
return utf8;
}4.2、GBK转UTF-8
4.2.1、统计转换后的字节数
//1.1 统计转换后的字节数
int len = MultiByteToWideChar(CP_ACP, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);4.2.2、用wstring存储数据,并为其分配大小?
wstring udata; //用wstring存储的
udata.resize(len);//分配大小4.2.3、GBK转unicode?
//开始写进去
MultiByteToWideChar(CP_ACP, 0, data, -1, (wchar_t*)udata.data(), len);?4.2.4、unicode转UTF-8
//2 unicode 转 utf8
len = WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);?4.2.5、配置字符大小,转成UTF-8
GBK.resize(len);
WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, (char*)GBK.data(), len, 0, 0);4.2.6、GBK 转UTF-8 完整代码
string GBKToUTF8(const char* data)
{
string GBK = "";
//1、GBK转unicode
//1.1 统计转换后的字节数
int len = MultiByteToWideChar(CP_ACP, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);
if (len <= 0)
{
return GBK;
}
wstring udata; //用wstring存储的
udata.resize(len);//分配大小
//开始写进去
MultiByteToWideChar(CP_ACP, 0, data, -1, (wchar_t*)udata.data(), len);
//2 unicode 转 utf8
len = WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);
if (len <= 0)
{
return GBK;
}
GBK.resize(len);
WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, (char*)GBK.data(), len, 0, 0);
return GBK;
}5、测试
5.1、测试UTF-8转GBK
int main()
{
//std::cout << "Hello World! 测试\n";
//1、测试utf-8转GBK
string in = u8"测试UTF-8转GBK";
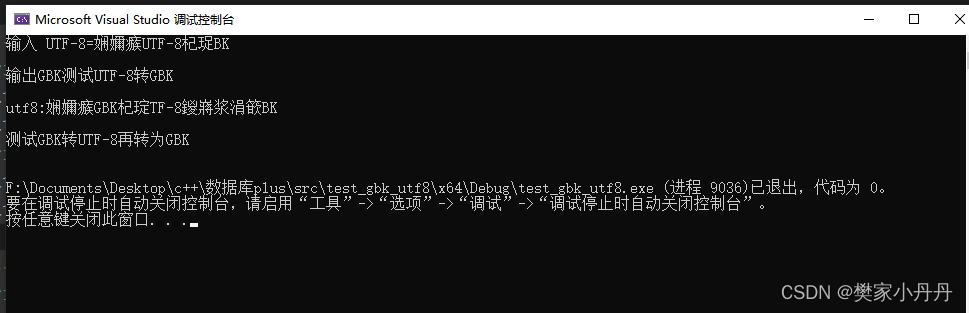
cout << "输入 UTF-8=" << in << endl;
string gbk = UTF8ToGBK(in.c_str());
cout << "输出GBK" << gbk << endl;
}
我们发现如果不进行转码的话,会出现乱码的情况,当通过转码之后,可以正常输出。
5.2、测试GBK转UTF-8
因为都是中文,在这里需要先GBK转UTF-8,再将UTF-8转换为GBK查看效果。
int main{
string utf8 = GBKToUTF8("测试GBK转UTF-8再转为GBK ");//出错的
cout << "utf8:" << utf8 << endl;
cout << UTF8ToGBK(utf8.c_str()) << endl;
}
6、完整可执行代码
//GBK转utf-8
#include<iostream>
#include<string>
using namespace std;
#include<Windows.h>
string UTF8ToGBK(const char* data)
{
string utf8 = "";
//1、UTF8 先要转为unicode windows utf16
//1.1 统计转换后的字节数
int len = MultiByteToWideChar(CP_UTF8, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);
if (len <= 0)
{
return utf8;
}
wstring udata; //用wstring存储的
udata.resize(len);//分配大小
//开始写进去
MultiByteToWideChar(CP_UTF8, 0, data, -1, (wchar_t*)udata.data(), len);
//2、 unicode 转 GBK
len = WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);
if (len <= 0)
{
return utf8;
}
utf8.resize(len);
WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, (char*)utf8.data(), len, 0, 0);
return utf8;
}
string GBKToUTF8(const char* data)
{
string GBK = "";
//1、GBK转unicode
//1.1 统计转换后的字节数
int len = MultiByteToWideChar(CP_ACP, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);
if (len <= 0)
{
return GBK;
}
wstring udata; //用wstring存储的
udata.resize(len);//分配大小
//开始写进去
MultiByteToWideChar(CP_ACP, 0, data, -1, (wchar_t*)udata.data(), len);
//2 unicode 转 utf8
len = WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);
if (len <= 0)
{
return GBK;
}
GBK.resize(len);
WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, (char*)GBK.data(), len, 0, 0);
return GBK;
}
int main()
{
//std::cout << "Hello World! 测试\n";
//1、测试utf-8转GBK
string in = u8"测试UTF-8转GBK";
cout << "输入 UTF-8=" << in << endl;
cout << endl;
string gbk = UTF8ToGBK(in.c_str());
cout << "输出GBK" << gbk << endl;
cout << endl;
//2、测试GBK转utf-8的转换
string utf8 = GBKToUTF8("测试GBK转UTF-8再转为GBK ");//出错的
cout << "utf8:" << utf8 << endl;
cout << endl;
cout << UTF8ToGBK(utf8.c_str()) << endl;
cout << endl;
system("pause");
return 0;
}
文章来源:https://blog.csdn.net/wjl990316fddwjl/article/details/135417012
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Laravel 开发中总结的一些方式方法
- 2.上传图片到Minio服务中
- CSS 彩虹按钮效果
- 苹果Mac电脑甘特图管 EasyGantt最新 for mac
- 用Python制作的一个十分有趣的网站
- 想要拿到中留服认证,需要出境多少天?180天/360天吗??
- kafka中,使用ack提交时,存在重复消费问题
- 【数据库原理】(37)Web与数据库
- 基于Spring Boot和微信小程序的智能小程序商城
- 「优选算法刷题」:在排序数组中查找元素的第一个和最后个位置