Python:正则表达式---贪婪匹配
发布时间:2023年12月21日
在正则表达式中,贪婪匹配是指匹配尽可能多的字符,而非贪婪匹配(也称为懒惰匹配或最小匹配)则是匹配尽可能少的字符。
.* 表示匹配任意数量的任意字符(除换行符外)。贪婪匹配会将尽可能多的字符都作为匹配结果返回。
正则表达式默认是贪婪匹配的,它会尽可能多地匹配满足条件的字符。例如,考虑以下示例:
import re
text = "Hello, my name is John. Nice to meet you, John."
pattern = r'my.*John' # 贪婪匹配
match = re.search(pattern, text)
print(match.group())
输出:

在这个例子中,正则表达式 my.John 匹配了 “my” 后面的任意字符(包括空格、标点符号等),直到最后一个 “John”。如果我们想要匹配 “my” 后面的最小字符串,即遇到第一个 “John” 就停止匹配,我们可以使用非贪婪匹配的符号 ?,将 . 改为 .*? ,
.*? 表示非贪婪的匹配任意数量的任意字符。非贪婪匹配会尽可能少地匹配字符以满足匹配规则
如下所示:
import re
text = "Hello, my name is John. Nice to meet you, John."
pattern = r'my.*?John' # 非贪婪匹配
match = re.search(pattern, text)
print(match.group())
输出:
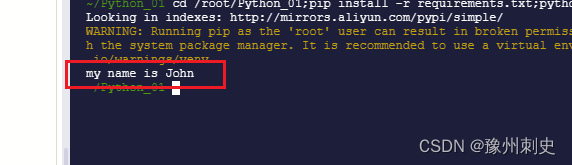
这次,正则表达式 my.*?John 使用了非贪婪匹配,它只匹配到第一个满足条件的 “John” 前面的最小字符串 “my name is John”。通过使用非贪婪匹配,我们可以控制正则表达式尽可能少地匹配字符,从而得到更精确的结果。
参考:
https://blog.csdn.net/m0_66238629/article/details/131603444
文章来源:https://blog.csdn.net/s1_0_2_4/article/details/135123916
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Redis 除了用作缓存还能干吗?
- 代码随想录算法训练营第14天 | 理论基础 递归遍历 迭代遍历 统一迭代
- 信息管理毕设分享(含算法) 深度学习语义分割实现弹幕防遮(源码分享)
- 光学 | 联合Ansys Zemax及Lumerical应对AR/VR市场挑战
- Jmeter、postman、python 三大主流技术如何操作数据库?
- 爬虫工作量由小到大的思维转变---<第三十五章 Scrapy 的scrapyd+Gerapy 部署爬虫项目>
- 面试算法107:矩阵中的距离
- AI文本生图模型Stable Diffusion部署教程
- python3:爬虫代理IP的使用+建立代理IP池
- ansible 加密