子域名收集
目录
在进行渗透的过程中有一个很重要的工作就是信息收集,而信息收集中的子域名收集是很重要的一项工作,在本篇中我会给大家演示使用下面的几种方式来进行子域名收集
?1、OneForAll
(1)首先在github上搜索下载OneForAll项目源码
GitHub - shmilylty/OneForAll: OneForAll是一款功能强大的子域收集工具
(2)将下载的包上传到Ubuntu上,然后解压
(3)进入到解压完成后的OneForAll中可以使用以下命令来查看某网站的子域名

2、利用Google的搜索
Google浏览器提供了很多通配符用于辅助搜索:
- *:在搜索词中使用 * 可以替代任意字符,用于模糊匹配。
- " ":在搜索词中使用双引号可以精确匹配整个短语。
- -:在搜索词前加上减号可以排除特定词语。
- OR:在搜索词中使用大写的 OR 可以进行逻辑或操作。
- site::在搜索词后加上 site: 可以限定搜索结果来自特定网站。
- filetype::在搜索词后加上 filetype: 可以限定搜索特定文件类型的结果。
- intitle::在搜索词后加上 intitle: 可以限定搜索结果标题中包含特定词语的结果。
- inurl::在搜索词后加上 inurl: 可以限定搜索结果网址中包含特定词语的结果。
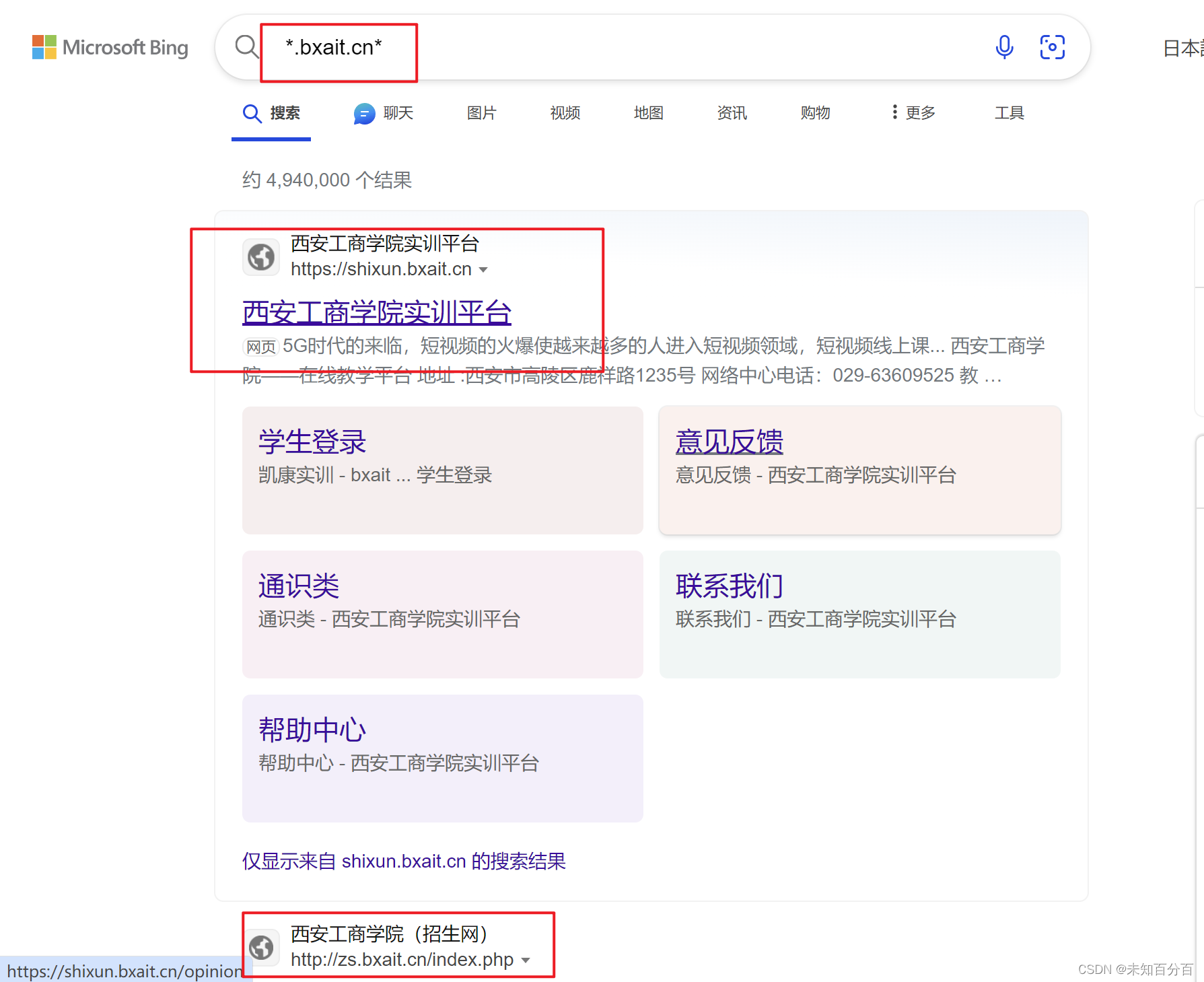
例如:搜索所有包含bxait.cn的域名以及其子域名
3、fofa
fofa在线网站:网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统
fofa的主页面:
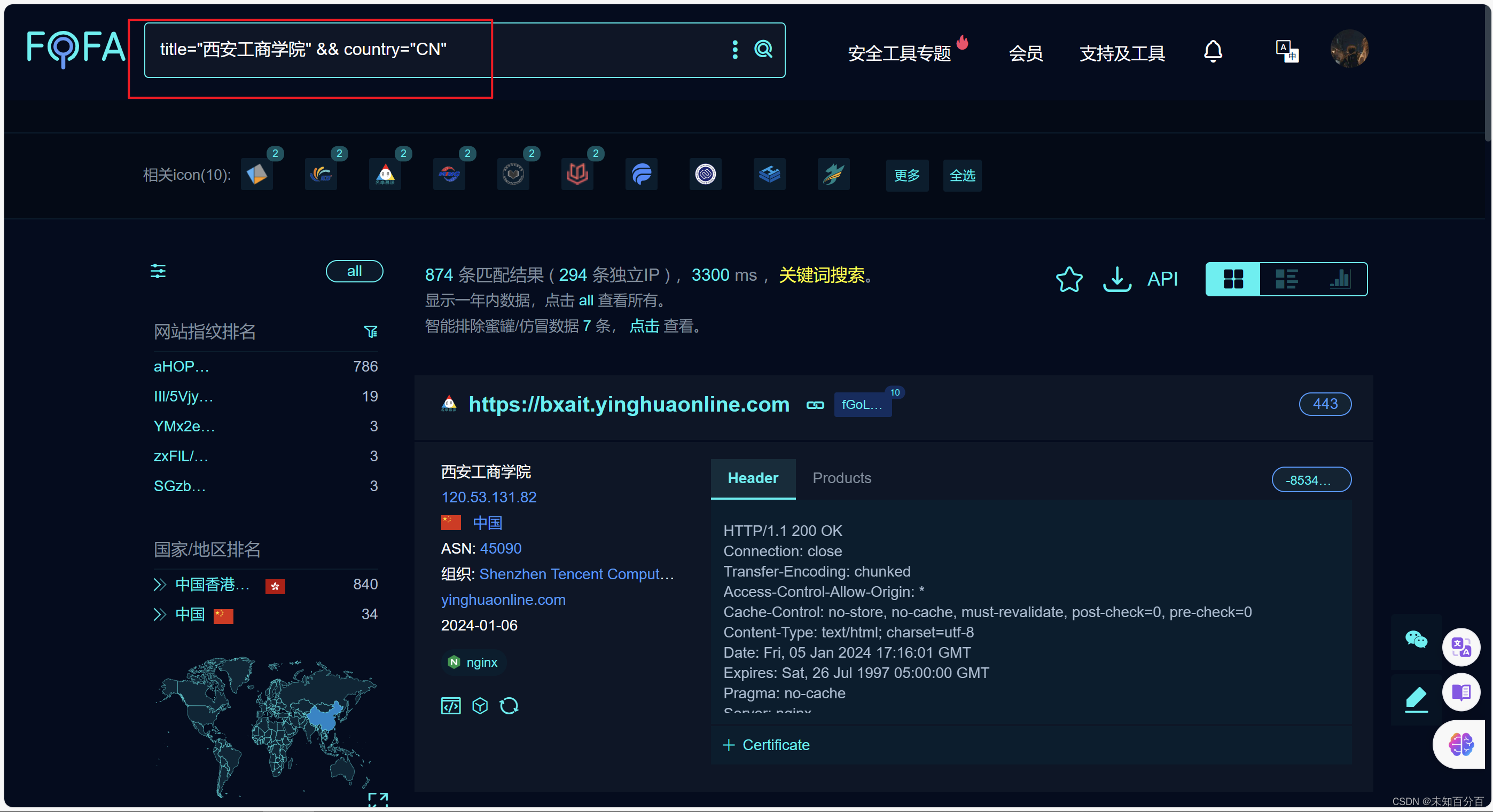
点击查询语法,里面有许多的语法可以辅助我们来进行子域名查询
例如:查询名称为“西安工商学院”且国家是“CN”的所有域名及其子域名
?4、使用在线查询网站查询
bxait.cn的Whois信息 - 站长工具 (chinaz.com)
DNSdumpster.com - dns recon and research, find and lookup dns records

?5、利用ip反查
iP地址查询--手机号码查询归属地 | 邮政编码查询 | iP地址归属地查询 | 身份证号码验证在线查询网 (ip138.com)
使用这个在线网站可以查找到ip对应的所有域名和子域名
6、Layer子域名挖掘机
(1)首先我们先下载Layer工具
这里有百度网的软件包:
链接:https://pan.baidu.com/s/1nKPpI3-aP5ET7OPi_NN72A?pwd=8848?
提取码:8848
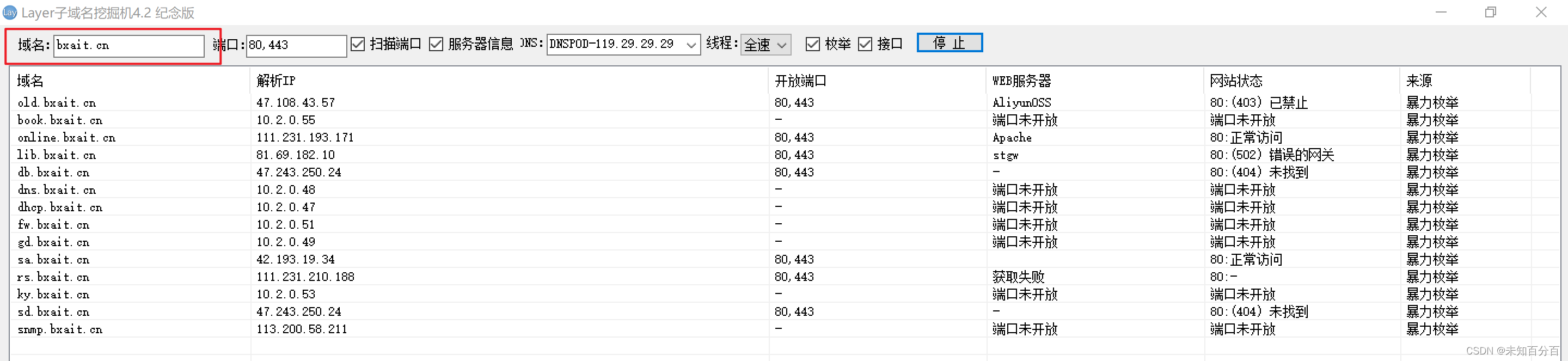
(2)下载完成后我们打开Layer
输入域名后就会开始爆破该域名中的子域名
7、JSFinder
JSFinder是一款用作快速在网站的js文件中提取URL,子域名的工具。
提取URL的正则部分使用的是LinkFinder
JSFinder获取URL和子域名的方式:

用法
-
简单爬取
python JSFinder.py -u http://www.jd.com这个命令会爬取 http://www.jd.com 这单个页面的所有的js链接,并在其中发现url和子域名
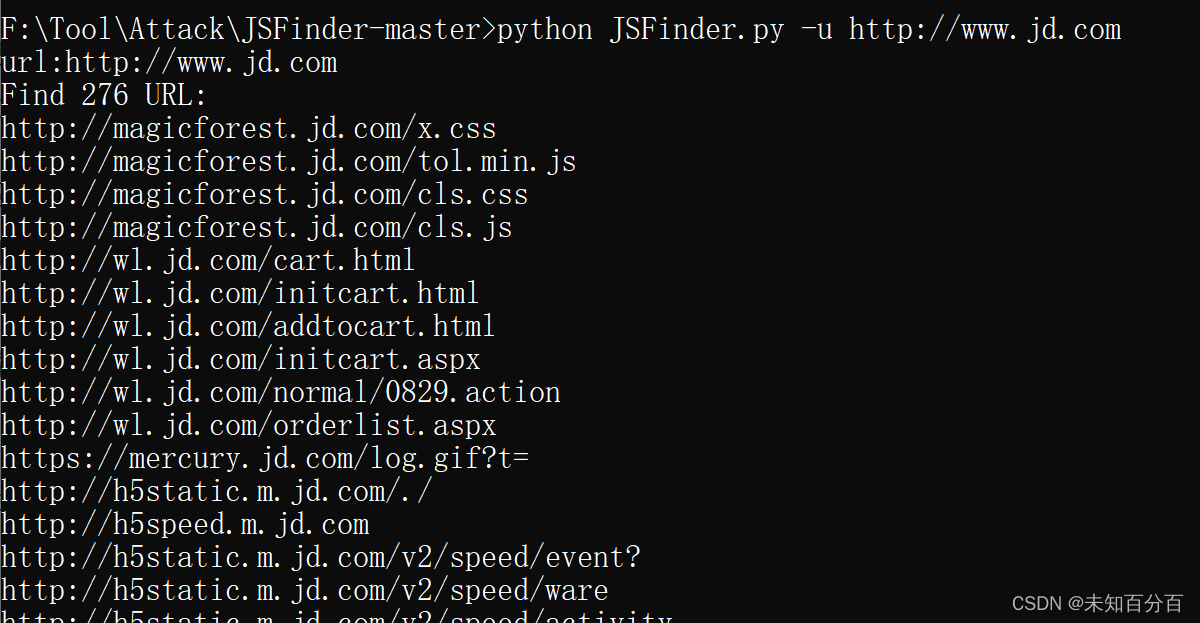
返回示例:
url:http://www.jd.com
Find 276 URL:
http://magicforest.jd.com/x.css
http://magicforest.jd.com/tol.min.js
http://magicforest.jd.com/cls.css
http://magicforest.jd.com/cls.js
http://wl.jd.com/cart.html
http://wl.jd.com/initcart.html
http://wl.jd.com/addtocart.html
http://wl.jd.com/initcart.aspx
http://wl.jd.com/normal/0829.action? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
...已省略 ? ? ? ? ? ? ? ? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
Find 106 Subdomain:
magicforest.jd.com
wl.jd.com
mercury.jd.com
h5static.m.jd.com
h5speed.m.jd.com
h5.m.jd.com
sec.m.jd.com
so.m.jd.com
coupon.m.jd.com
jdcs.m.jd.com
wq.jd.com
plogin.m.jd.com
p.m.jd.com? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
...已省略-
深度爬取
python JSFinder.py -u http://www.jd.com -d ?
?
深入一层页面爬取JS,时间会消耗的更长。
建议使用-ou 和 -os来指定保存URL和子域名的文件名。 例如:
python JSFinder.py -u http://www.jd.com -d -ou jd_url.txt -os jd_subdomain.txt
-
批量指定URL/指定JS
指定URL:
python JSFinder.py -f text.txt指定JS:
python JSFinder.py -f text.txt -j可以用brupsuite爬取网站后提取出URL或者JS链接,保存到txt文件中,一行一个。
指定URL或JS就不需要加深度爬取,单个页面即可。
-
其他
-c 指定cookie来爬取页面 例:
python JSFinder.py -u http://www.jd.com -c "session=xxx"-ou 指定文件名保存URL链接 例:
python JSFinder.py -u http://www.jd.com -ou jd_url.txt-os 指定文件名保存子域名 例:
python JSFinder.py -u http://www.jd.com -os mi_subdomain.txt-
注意
url 不用加引号
url 需要http:// 或 https://
指定JS文件爬取时,返回的URL为相对URL
指定URL文件爬取时,返回的相对URL都会以指定的第一个链接的域名作为其域名来转化为绝对URL。
注:除了以上几种方式来进行子域名查询的方式外还有很多方式可以通过DNS A记录,DNS域传送漏洞,枚举爆破(在线,本地),本地爆破,sonar,dirmap,dirsearch等等方式来查询
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!