对m3u8视频进行批量采集
发布时间:2024年01月19日
一、相关网页(网页链接:https://www.acfun.cn/v/ac36564705)
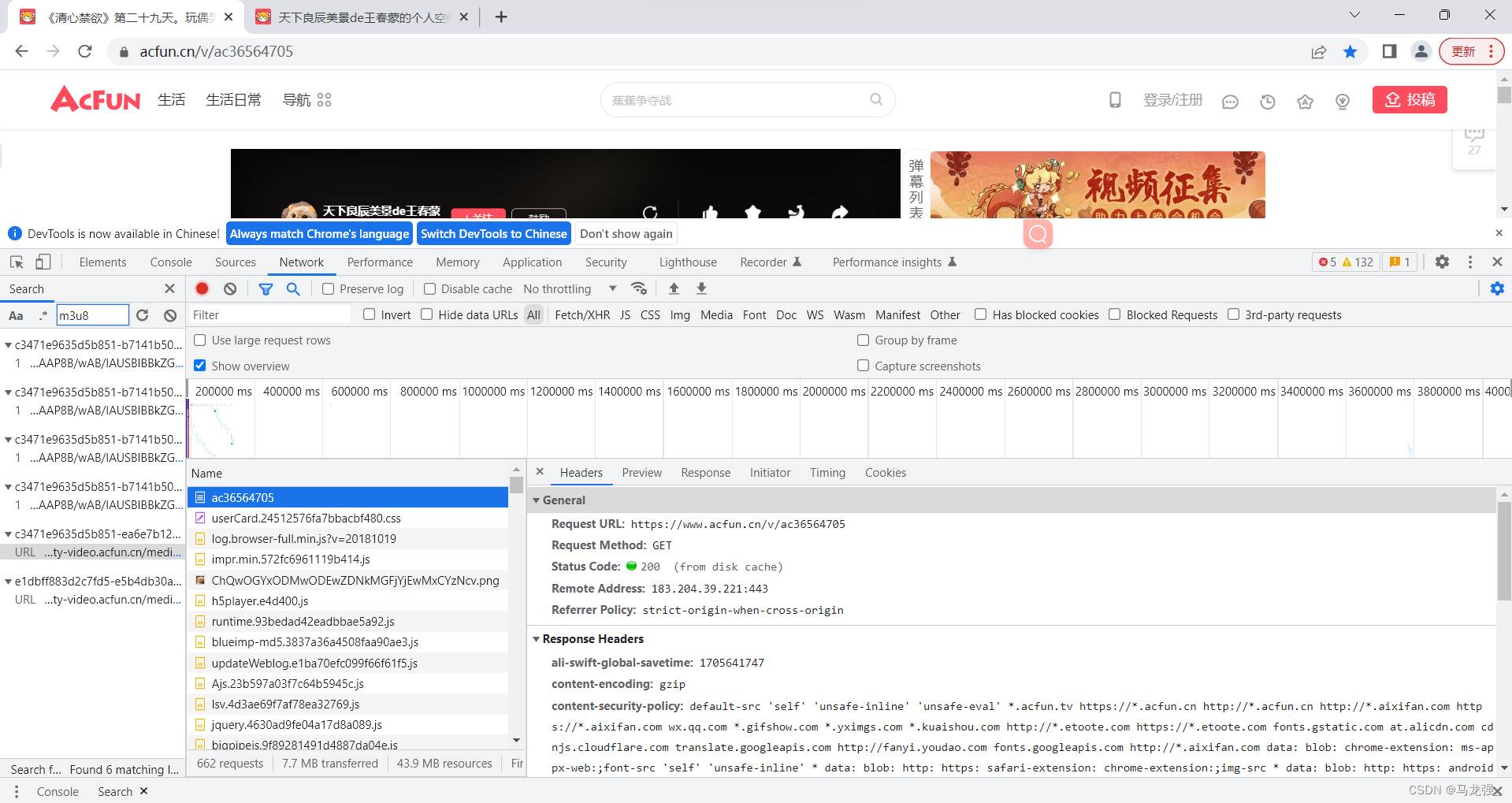 二、多视频采集网页(找出每个视频ID)
二、多视频采集网页(找出每个视频ID)
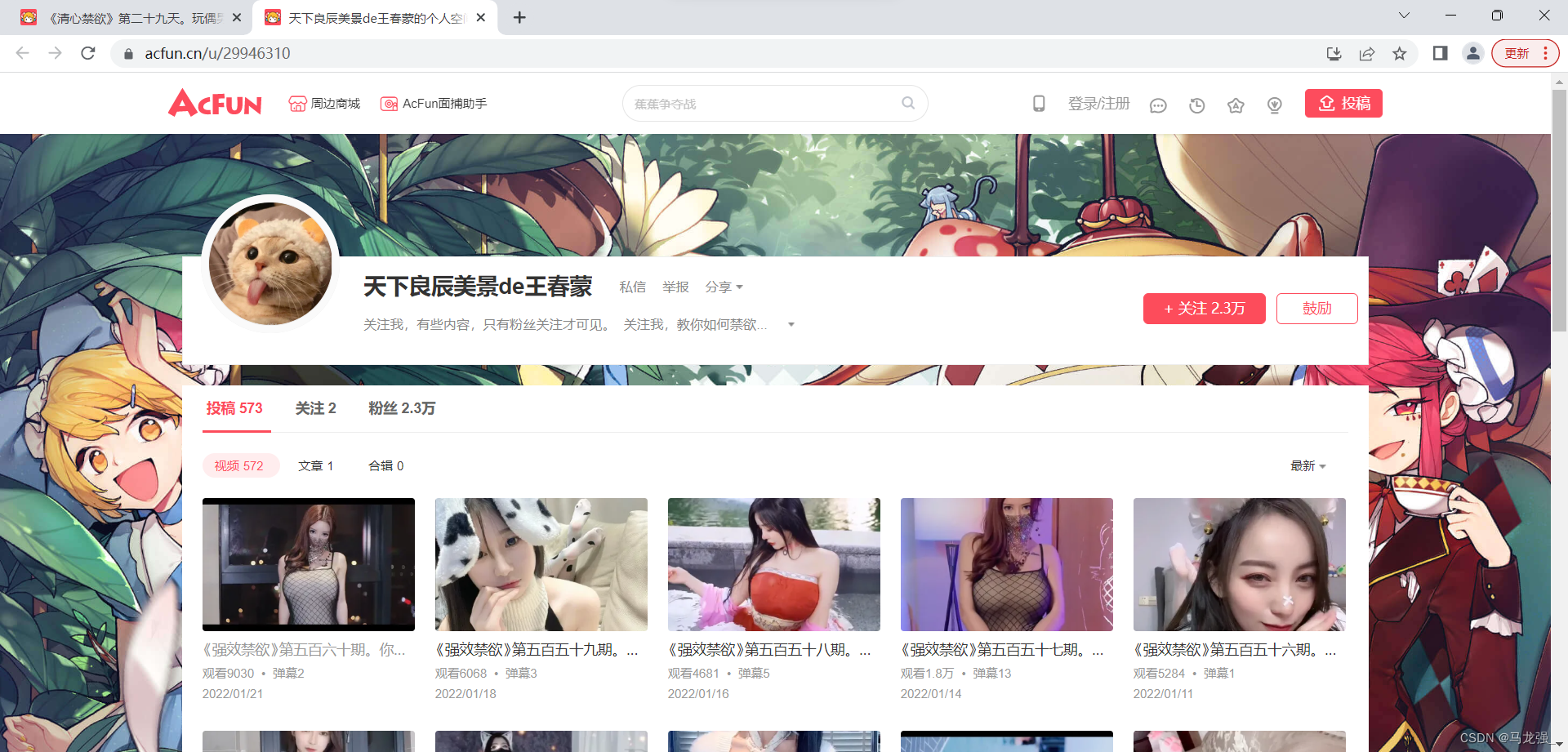
三、相关代码(代码含有注释)
# @Time: 2024/1/18 22:57
# @Author: 马龙强
# @File: 对m3u8视频进行批量采集.py
# @software: PyCharm
"""
网址:https://www.acfun.cn/v/ac36564705
数据:视频内容
数据包地址:https://www.acfun.cn/v/ac36564705(视频详情页)
多个视频采集() ——> 多页视频采集
https://www.acfun.cn/u/29946310
1.分析请求链接变化规律
https://www.acfun.cn/v/ac36564705(视频详情页)
视频ID --> 获取所有视频ID(目录页面获取)
页面链接:
https://www.acfun.cn/u/29946310?quickViewId=ac-space-video-list&reqID=14&ajaxpipe=1&type=video&order=newest&page=2&pageSize=20&t=1705649684246
1.发送请求
2.获取数据
3.解析数据
"""
#url = 'https://tx-safety-video.acfun.cn/mediacloud/acfun/acfun_video/c3471e9635d5b851-ea6e7b122d2d54d64693965aed559baa-hls_360p_hevc_1.m3u8?pkey=ABCFUkjmqkt-agD7xyW6wFIm-mYTdxYRB75ZOyemp5aoFUJNm9DAVYVc5nqQkdQP-FJad2s-yd92ypUuPakRanYHaOFpm0aRsJc5D1rx9p9DgNop9FsUtA1MSBDk6vnM8iiRJn_zzu7rgoUmYhh1vpQ5OF_JaTTlEfIiu-KnqY3TERCMWXPB0ar6eP2oIq3RUKhvYz_Hx-_rKfT2FdxKM3B7ThniqMjFLkXFyYYeCocClw&safety_id=AAL1xBzfE8H4NudKAOEFPJXV'
import requests
import json
import re
from pprint import pprint
#模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# page_link = ''
link = 'https://www.acfun.cn/u/29946310?quickViewId=ac-space-video-list&reqID=14&ajaxpipe=1&type=video&order=newest&page=2&pageSize=20&t=1705649684246'
#发送请求获取数据
link_data = requests.get(url=link,headers=headers).text
# print(link_data)
#提取视频ID
video_id_list = re.findall('"atomid.*?":.*?"(\d+).*?"',link_data)
# pprint(link_data)
# print(video_id_list)
for video_id in video_id_list:
#请求网址
url = f'https://www.acfun.cn/v/ac{video_id}'
#发送请求
response = requests.get(url=url,headers=headers)
#获取数据
html_data = response.text
#打印数据
#提取标题
title = re.findall('"title":"(.*?)",',html_data)[1]
# print(title)
#提取m3u8 json格式 -> 字符串
info = re.findall('window.videoInfo =(.*?);',html_data)[0]
#转成字典 -> 键值对取值(根据冒号左边的内容,提取冒号右边的内容)
# m3u8 = json.loads(json.loads(info)['currentVideoInfo']['ksPlayJson'])['adaptationSet'][0]['representation'][0]['backupUrl'][0]
m3u8 = json.loads(json.loads(info)['currentVideoInfo']['ksPlayJson'])['adaptationSet'][0]['representation'][0]['url']
# print(m3u8)
# print(info)
# pprint(m3u8)
# print(html_data)
"""
二次请求
"""
#发送请求 获取数据
m3u8_data = requests.get(url=m3u8,headers=headers).text
#提取ts链接
ts_list = re.findall(',\n(.*?)\n#',m3u8_data,re.S)
print(title)
# print(title)
# print(m3u8)
# print(m3u8_data)
# print(ts_list)
#for循环遍历
for ts in ts_list:
#https://ali-safety-video.acfun.cn/mediacloud/acfun/acfun_video/
ts_url = 'https://ali-safety-video.acfun.cn/mediacloud/acfun/acfun_video/'+ts
# print(ts_url)
"""
第三次请求:获取视频内容
把所有视频片段合成一个完整的视频内容
"""
ts_content = requests.get(url=ts_url,headers=headers).content
with open('video\\'+ title + '.mp4',mode='ab') as f:
f.write(ts_content)
print('保存完毕!')四、爬取结果(mp4文件)
文章来源:https://blog.csdn.net/m0_74972727/article/details/135701326
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2、内网安全-域防火墙-入站出站规则-不出网隧道上线-组策略对象同步
- 深度学习中的感知机
- 华为云Stack 8.X流量模型分析(五)
- 百度地图通过DrawingManager.js改造绘制电子围栏,圆形、矩形、多边形、行政区域。( 方式2)
- 《Linux系统与网络管理》---题库---简答题
- SWUST-最多苹果数量
- 企业建设网络安全的几种“降本增效”的思考
- CCF编程能力等级认证GESP—C++8级—样题1
- 船的最小载重量-算法
- 热烈庆祝西安大秦时代网络科技有限公司官网上线了!