kafka消费Clock skew too great (37),CPU打爆
No valid credentials provided (Mechanism level: Clock skew too great (37) - PROCESS_TGS)
? 记一次生产事故,springboot消费kafka时于凌晨0~4点频繁报错且整天cpu持续90%以上占用。
项目背景
? 项目背景为:
- jdk1.8
- springboot 2.3.4.RELEASE
- 使用华为MRS-kafka
排查思路
排查思路为
- jstack/arhas分析忙碌cpu线程 =》 找到具体代码 =》 生成火焰图(注意:此时为正常的工作日白天)=》发现问题集中在消息的拉取上但此时数据仍正常在进入
此时数据在正常进入,但cpu占90%以上。为服务器不持续报警。重启服务,此时cpu恢复正常。但是第二天检查服务器时发现cpu继续爆满。怀疑此时为正常现象(数据量很大),但是继续重启之后恢复正常。怀疑为代码问题(批量消费)修改代码后重新部署,第三天cpu继续爆满。(此时还伴随着服务器磁盘空间满了。整理了一下日志输出,此排查处方向有问题)。
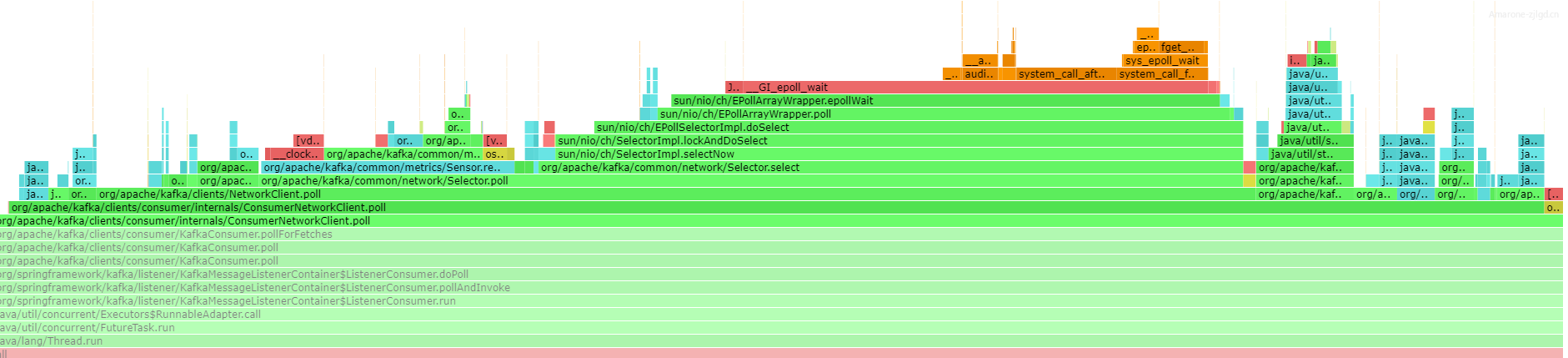
- =》拉取错误日志-》发现错误日志集中在晚0~4点,错误日志为时间相差 >5分钟
发现问题集中时间段为 00:05 1:45 2:45 3:55 因错误日志较多,此处问题时间为节选。日志报错都在描述时间相差过大、但是在此时(白天)在服务器执行
date命令后发现应用服务器、kafka服务器时间相同。推断在0~4点有同步时间服务导致此时间段时间差距较大。怀疑为ntp服务导致。
Caused by: org.ietf.jgss.GSSException: No valid credentials provided (Mechanism level: Clock skew too great (37) - PROCESS_TGS)
at sun.security.jgss.krb5.Krb5Context.initSecContext(Krb5Context.java:772)
at sun.security.jgss.GSSContextImpl.initSecContext(GSSContextImpl.java:248)
at sun.security.jgss.GSSContextImpl.initSecContext(GSSContextImpl.java:179)
at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:192)
... 22 common frames omitted
Caused by: sun.security.krb5.KrbException: Clock skew too great (37) - PROCESS_TGS
at sun.security.krb5.KrbTgsRep.<init>(KrbTgsRep.java:73)
at sun.security.krb5.KrbTgsReq.getReply(KrbTgsReq.java:225)
at sun.security.krb5.KrbTgsReq.sendAndGetCreds(KrbTgsReq.java:236)
at sun.security.krb5.internal.CredentialsUtil.serviceCredsSingle(CredentialsUtil.java:482)
at sun.security.krb5.internal.CredentialsUtil.serviceCreds(CredentialsUtil.java:340)
at sun.security.krb5.internal.CredentialsUtil.serviceCreds(CredentialsUtil.java:314)
at sun.security.krb5.internal.CredentialsUtil.acquireServiceCreds(CredentialsUtil.java:169)
at sun.security.krb5.Credentials.acquireServiceCreds(Credentials.java:490)
at sun.security.jgss.krb5.Krb5Context.initSecContext(Krb5Context.java:695)
Kafka客户端在尝试与Kafka Broker进行SASL认证时,没有提供有效的GSSAPI凭据,服务器和客户端之间的时间戳偏差过大
- =》查询NTP服务配置=》怀疑为ntp服务配置问题=》排除ntp服务问题
排查ntp后发现应用服务器与kafka服务器NTP服务器不一致。且offset偏差也可能导致时间相差5分钟。但是ntp服务在运行期间是持续轮训同步时间,不可能只有0~4点这个固定时间段存在问题。但是也不能排除NTP服务问题。询问后发现两服务器的NTP服务节点虽IP不同但指向的是同一服务器.NTP服务导致时间差距不大可能。
应用服务NTP如下:
# systemctl status ntpd | grep "Active: active"
Active: active (running) since Tue 2023-**-** 10:16:46 CST; ***
kafka服务期NTP如下:

# systemctl status ntpd | grep "Active: active"
Active: active (running) since Tue 2023-**-** 10:16:46 CST; ***
-
=》意外发现有定时任务定时同步硬件时间=》执行定时同步硬件时间脚本=》发现时间相差>5分钟=》删除定时同步硬件时间任务
发现服务器 crontab -l 在部分kafka节点服务上以及业务服务器上有 定时同步硬件时间的服务(huawei-clock -s)。试着执行此脚本后发现 执行前后时间相差5分钟。且在执行此命令后java 消费服务继续cpu高占用。
-
已经有了NTP服务同步时间,为什么还要定时脚本同步硬件时间
NTP服务依赖于网络,如果网络出现问题或者服务器宕机,那么NTP服务就无法正常工作。而硬件时钟是由电池供电的,即使断电也会继续运行,因此它可以在没有网络的情况下提供准确的时间信息。
一些重要的系统操作,如数据库备份、日志切割等,对时间的精确度要求非常高,它们通常不会依赖NTP服务,而是直接使用硬件时钟的时间。如果在这些操作进行时NTP服务出现问题,可能会导致任务执行的时间出错。
对于某些特定的应用,可能还会需要额外的时间同步策略。例如,某些应用程序可能会选择与本地时间源同步,而不是NTP服务器。这时就需要通过定时脚本来手动调整硬件时间。
NTP服务在大多数情况下可以提供准确的时间同步,但在一些特殊情况下,我们仍然需要定时脚本来同步硬件时间,以确保系统的稳定和可靠运行。
-
一个时间段从kafka拉取消息失败为什么不会影响下一时间段且cpu一致在尝试获取没有错误日志产生
Kafka维护了一个时间戳和偏移量映射(映射到.index文件中的索引项),映射到.log文件中的实际字节偏移量。根据时间戳读取数据比根据位移读取数据要复杂一些,因为需要进行额外的数据查找步骤。此外,时间戳也被用于解决日志保存策略,判断依据就是比较日志段文件的最新修改时间。因此,如果两台服务器间的时间不一致,可能会导致读取的数据顺序错误或者对过期日志的判断失误,从而引发各种问题。
在Spring Boot中,监听Kafka topic的轮询频率次数是由配置文件中的
spring.kafka.consumer.poll-interval属性控制的。默认情况下,spring.kafka.consumer.poll-interval的值为500毫秒。这意味着消费者每500毫秒会向Kafka broker发送一次拉取请求,获取新的消息。
-
-
=》排查消费配置
按照kafka客户端与服务端的交互流程来说
-
客户端向Kafka发送连接请求,包括客户端的票据(token)和时间戳。
-
Kafka接收到连接请求后,验证客户端的票据是否有效。Kafka可以通过验证票据中的签名或访问令牌来验证票据的有效性。如果票据无效,Kafka将拒绝连接请求。
-
如果票据有效,Kafka将检查客户端的时间戳与服务器的时间戳是否一致。如果时间戳偏差过大,Kafka将拒绝连接请求,并返回错误信息。
-
如果时间戳一致,Kafka将接受连接请求,并将客户端的时间戳记录在日志中。
-
客户端和Kafka建立连接后,客户端可以发送消息到Kafka。在发送消息时,客户端会携带消息的时间戳。
-
Kafka接收到消息后,会验证消息的时间戳是否与客户端的时间戳一致。如果时间戳不一致,Kafka将拒绝接收该消息,并返回错误信息。
-
如果时间戳一致,Kafka将正常处理消息,并将其存储在相应的分区中。
为了保证消息的顺序性和可靠性,从0.10.0.0版本开始,Kafka在每条消息中都增加了一个timestamp字段。这个时间戳有两种类型:CreateTime和LogAppendTime。CreateTime表示producer创建这条消息的时间;而LogAppendTime则表示leader broker将这条消息写入到log的时间。这样,broker接收到消息后可以根据这个时间戳来判断消息的顺序,并保证相同顺序的消息被同一消费者组内的消费实例消费。
-
我们的配置还是比较变态的的
kafka:
consumer:
properties:
max.poll.interval.ms: 86400000
max-poll-records: 200
properties:
session:
timeout:
ms: 120000
max.poll.records 参数决定了consumer一次从Kafka broker中拉取的最大消息数目默认值是500条.如果单次poll调用返回的消息数(即max.poll.records的值)小于或等于系统的吞吐量,那么处理逻辑就需要足够轻量,这样才能确保在session.timeout.ms这个时间内处理完这max.poll.records条数据。
max.poll.interval.ms指定consumer两次poll操作的最大时间间隔(默认值为5分钟),此处设置为24小时(单位毫秒)。如果某个consumer的处理能力不足,无法在session.timeout.ms规定的时间内处理完max.poll.records条数据,那么broker可能会认为该consumer的处理能力较弱。在这种情况下,broker会将该consumer所在的消费组中的分区分配给其他的consumer进行处理,从而触发rebalance过程。
session.timeout.ms消费者在与broker通信时,如果超过这个时间没有发送心跳包,那么该消费者的会话将被认为已经过期。默认情况下,session.timeout.ms的值是10000毫秒(即10秒)当消费者长时间没有向broker发送心跳包时,broker会认为该消费者已经下线,并释放该消费者所消费的分区。这样,其他消费者就可以重新分配这些分区进行消费。这里设置为两分钟。
网上很多博文描述为 Kafka-Consumer0.10版本的一个Bug ,并不是适用于此处,此处使用的是spring-kafka 2.5.6.RELEASE以及kafka-clients 2.4.0-hw-ei-302002
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024北京眼健康展,护眼灯/护眼仪/视力训练仪,护眼产品展
- 未来医疗的新希望:人工智能与智能器官的奇妙融合
- K8S学习指南(59)-K8S核心组件ETCD简介
- 【面试突击】数据库面试实战(上)
- Python输入输出流学习笔记
- SEO需要多长时间?
- GitHub无法完成推送 的设置选项
- 231217 刷题日报
- 京东数据分析:2023年度厨房小电行业分析(厨房小电市场未来发展趋势)
- 达达集团高管巨震,董事长、CFO被换,京东“接管”下的野心凸显