56、Flink 的Data Source 原理介绍
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
本文简单的介绍了datasource的工作原理、api以及datastream connector的类型等。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
一、Data Source 原理
1、核心组件
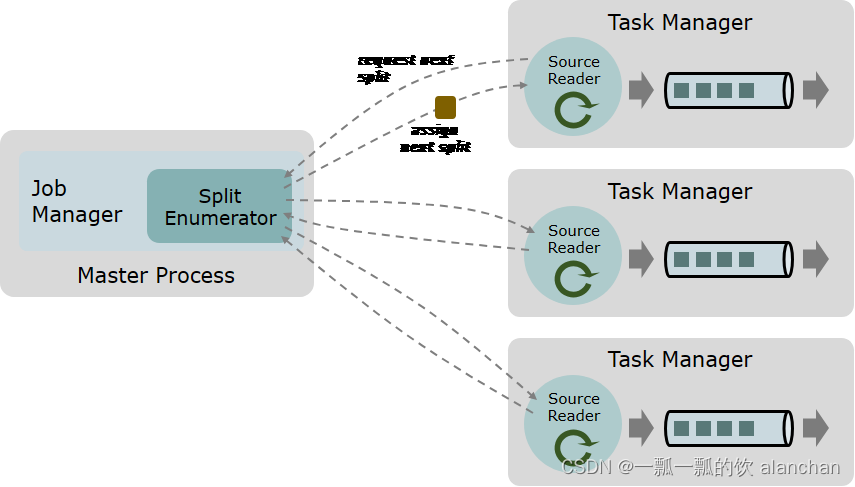
一个数据 source 包括三个核心组件:分片(Splits)、分片枚举器(SplitEnumerator) 以及 源阅读器(SourceReader)。
-
分片(Split) 是对一部分 source 数据的包装,如一个文件或者日志分区。分片是 source 进行任务分配和数据并行读取的基本粒度。
-
源阅读器(SourceReader) 会请求分片并进行处理,例如读取分片所表示的文件或日志分区。SourceReader 在 TaskManagers 上的 SourceOperators 并行运行,并产生并行的事件流/记录流。
-
分片枚举器(SplitEnumerator) 会生成分片并将它们分配给 SourceReader。该组件在 JobManager 上以单并行度运行,负责对未分配的分片进行维护,并以均衡的方式将其分配给 reader。
Source 类作为API入口,将上述三个组件结合在了一起。
package org.apache.flink.api.connector.source;
import org.apache.flink.annotation.Public;
import org.apache.flink.core.io.SimpleVersionedSerializer;
/**
* The interface for Source. It acts like a factory class that helps construct the {@link
* SplitEnumerator} and {@link SourceReader} and corresponding serializers.
*
* @param <T> The type of records produced by the source.
* @param <SplitT> The type of splits handled by the source.
* @param <EnumChkT> The type of the enumerator checkpoints.
*/
@Public
public interface Source<T, SplitT extends SourceSplit, EnumChkT> extends SourceReaderFactory<T, SplitT> {
/**
* Get the boundedness of this source.
*
* @return the boundedness of this source.
*/
Boundedness getBoundedness();
/**
* Creates a new SplitEnumerator for this source, starting a new input.
*
* @param enumContext The {@link SplitEnumeratorContext context} for the split enumerator.
* @return A new SplitEnumerator.
* @throws Exception The implementor is free to forward all exceptions directly. Exceptions
* thrown from this method cause JobManager failure/recovery.
*/
SplitEnumerator<SplitT, EnumChkT> createEnumerator(SplitEnumeratorContext<SplitT> enumContext)
throws Exception;
/**
* Restores an enumerator from a checkpoint.
*
* @param enumContext The {@link SplitEnumeratorContext context} for the restored split
* enumerator.
* @param checkpoint The checkpoint to restore the SplitEnumerator from.
* @return A SplitEnumerator restored from the given checkpoint.
* @throws Exception The implementor is free to forward all exceptions directly. Exceptions
* thrown from this method cause JobManager failure/recovery.
*/
SplitEnumerator<SplitT, EnumChkT> restoreEnumerator(
SplitEnumeratorContext<SplitT> enumContext, EnumChkT checkpoint) throws Exception;
// ------------------------------------------------------------------------
// serializers for the metadata
// ------------------------------------------------------------------------
/**
* Creates a serializer for the source splits. Splits are serialized when sending them from
* enumerator to reader, and when checkpointing the reader's current state.
*
* @return The serializer for the split type.
*/
SimpleVersionedSerializer<SplitT> getSplitSerializer();
/**
* Creates the serializer for the {@link SplitEnumerator} checkpoint. The serializer is used for
* the result of the {@link SplitEnumerator#snapshotState(long)} method.
*
* @return The serializer for the SplitEnumerator checkpoint.
*/
SimpleVersionedSerializer<EnumChkT> getEnumeratorCheckpointSerializer();
}
2、流处理和批处理的统一
Data Source API 以统一的方式对无界流数据和有界批数据进行处理。
事实上,这两种情况之间的区别是非常小的:
在有界/批处理情况中,枚举器生成固定数量的分片,而且每个分片都必须是有限的。
但在无界流的情况下,则无需遵从限制,也就是分片大小可以不是有限的,或者枚举器将不断生成新的分片。
以下是一些简化的概念示例,以说明在流和批处理情况下 data source 组件如何交互。
1)、有界 File Source
Source 将包含待读取目录的 URI/路径(Path),以及一个定义了如何对文件进行解析的 格式(Format)。在该情况下:
-
分片是一个文件,或者是文件的一个区域(如果该文件格式支持对文件进行拆分)。
-
SplitEnumerator 将会列举给定目录路径下的所有文件,并在收到来自 reader 的请求时对分片进行分配。一旦所有的分片都被分配完毕,则会使用 NoMoreSplits 来响应请求。
-
SourceReader 则会请求分片,读取所分配的分片(文件或者文件区域),并使用给定的格式进行解析。如果当前请求没有获得下一个分片,而是 NoMoreSplits,则会终止任务。
2)、无界 Streaming File Source
这个 source 的工作方式与上面描述的基本相同,除了 SplitEnumerator 从不会使用 NoMoreSplits 来响应 SourceReader 的请求,并且还会定期列出给定 URI/路径下的文件来检查是否有新文件。一旦发现新文件,则生成对应的新分片,并将它们分配给空闲的 SourceReader。
3)、无界 Streaming Kafka Source
Source 将具有 Kafka Topic(亦或者一系列 Topics 或者通过正则表达式匹配的 Topic)以及一个 解析器(Deserializer) 来解析记录(record)。
-
分片是一个 Kafka Topic Partition。
-
SplitEnumerator 会连接到 broker 从而列举出已订阅的 Topics 中的所有 Topic Partitions。枚举器可以重复此操作以检查是否有新的 Topics/Partitions。
-
SourceReader 使用 KafkaConsumer 读取所分配的分片(Topic Partition),并使用提供的 解析器 反序列化记录。由于流处理中分片(Topic Partition)大小是无限的,因此 reader 永远无法读取到数据的尾部。
4)、有界 Kafka Source
这种情况下,除了每个分片(Topic Partition)都会有一个预定义的结束偏移量,其他与上述相同。一旦 SourceReader 读取到分片的结束偏移量,整个分片的读取就会结束。而一旦所有所分配的分片读取结束,SourceReader 也就终止任务了。
二、Data Source API
1、Source
Source API 是一个工厂模式的接口,用于创建以下组件。
- Split Enumerator
- Source Reader
- Split Serializer
- Enumerator Checkpoint Serializer
除此之外,Source 还提供了 Boundedness 的特性,从而使得 Flink 可以选择合适的模式来运行 Flink 任务。
Source 实现应该是可序列化的,因为 Source 实例会在运行时被序列化并上传到 Flink 集群。
2、SplitEnumerator
SplitEnumerator 被认为是整个 Source 的“大脑”。SplitEnumerator 的典型实现如下:
- SourceReader 的注册处理
- SourceReader 的失败处理
SourceReader 失败时会调用 addSplitsBack() 方法。SplitEnumerator应当收回已经被分配,但尚未被该 SourceReader 确认(acknowledged)的分片。 - SourceEvent 的处理
SourceEvents 是 SplitEnumerator 和 SourceReader 之间来回传递的自定义事件。可以利用此机制来执行复杂的协调任务。 - 分片的发现以及分配
SplitEnumerator 可以将分片分配到 SourceReader 从而响应各种事件,包括发现新的分片,新 SourceReader 的注册,SourceReader 的失败处理等
SplitEnumerator 可以在 SplitEnumeratorContext 的帮助下完成所有上述工作,其会在 SplitEnumerator 的创建或者恢复的时候提供给 Source。 SplitEnumeratorContext 允许 SplitEnumerator 检索到 reader 的必要信息并执行协调操作。 而在 Source 的实现中会将 SplitEnumeratorContext 传递给 SplitEnumerator 实例。
SplitEnumerator 的实现可以仅采用被动工作方式,即仅在其方法被调用时采取协调操作,但是一些 SplitEnumerator 的实现会采取主动性的工作方式。例如,SplitEnumerator 定期寻找分片并分配给 SourceReader。 这类问题使用 SplitEnumeratorContext 类中的 callAsync() 方法比较方便。下面的代码片段展示了如何在 SplitEnumerator 不需要自己维护线程的条件下实现这一点。
class MySplitEnumerator implements SplitEnumerator<MySplit, MyCheckpoint> {
private final long DISCOVER_INTERVAL = 60_000L;
/**
* 一种发现分片的方法
*/
private List<MySplit> discoverSplits() {...}
@Override
public void start() {
...
enumContext.callAsync(this::discoverSplits, splits -> {
Map<Integer, List<MySplit>> assignments = new HashMap<>();
int parallelism = enumContext.currentParallelism();
for (MySplit split : splits) {
int owner = split.splitId().hashCode() % parallelism;
assignments.computeIfAbsent(owner, new ArrayList<>()).add(split);
}
enumContext.assignSplits(new SplitsAssignment<>(assignments));
}, 0L, DISCOVER_INTERVAL);
...
}
...
}
3、SourceReader
SourceReader 是一个运行在Task Manager上的组件,用于处理来自分片的记录。
SourceReader 提供了一个拉动式(pull-based)处理接口。Flink 任务会在循环中不断调用 pollNext(ReaderOutput) 轮询来自 SourceReader 的记录。pollNext(ReaderOutput) 方法的返回值指示 SourceReader 的状态。
- MORE_AVAILABLE - SourceReader 有可用的记录。
- NOTHING_AVAILABLE - SourceReader 现在没有可用的记录,但是将来可能会有记录可用。
- END_OF_INPUT - SourceReader 已经处理完所有记录,到达数据的尾部。这意味着 SourceReader 可以终止任务了。
pollNext(ReaderOutput) 会使用 ReaderOutput 作为参数,为了提高性能且在必要情况下,SourceReader 可以在一次 pollNext() 调用中返回多条记录。例如,有时外部系统的工作粒度为块。而一个块可以包含多个记录,但是 source 只能在块的边界处设置 Checkpoint。在这种情况下,SourceReader 可以一次将一个块中的所有记录通过 ReaderOutput 发送至下游。
然而,除非有必要,SourceReader 的实现应该避免在一次 pollNext(ReaderOutput) 的调用中发送多个记录。 这是因为对 SourceReader 轮询的任务线程工作在一个事件循环(event-loop)中,且不能阻塞。
在创建 SourceReader 时,相应的 SourceReaderContext 会提供给 Source,而 Source 则会将相应的上下文传递给 SourceReader 实例。SourceReader 可以通过 SourceReaderContext 将 SourceEvent 传递给相应的 SplitEnumerator 。Source 的一个典型设计模式是让 SourceReader 发送它们的本地信息给 SplitEnumerator,后者则会全局性地做出决定。
SourceReader API 是一个底层(low-level) API,允许用户自行处理分片,并使用自己的线程模型来获取和移交记录。为了帮助实现 SourceReader,Flink 提供了 SourceReaderBase 类,可以显著减少编写 SourceReader 所需要的工作量。
强烈建议连接器开发人员充分利用 SourceReaderBase 而不是从头开始编写 SourceReader。
4、Source 使用方法
为了通过 Source 创建 DataStream,需要将 Source 传递给 StreamExecutionEnvironment。例如,
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Source mySource = new MySource(...);
DataStream<Integer> stream = env.fromSource(
mySource,
WatermarkStrategy.noWatermarks(),
"MySourceName");
...
三、SplitReader API
核心的 SourceReader API 是完全异步的, 但实际上,大多数 Sources 都会使用阻塞的操作,例如客户端(如 KafkaConsumer)的 poll() 阻塞调用,或者分布式文件系统(HDFS, S3等)的阻塞I/O操作。为了使其与异步 Source API 兼容,这些阻塞(同步)操作需要在单独的线程中进行,并在之后将数据提交给 reader 的异步线程。
SplitReader 是基于同步读取/轮询的 Source 的高级(high-level)API,例如 file source 和 Kafka source 的实现等。
核心是上面提到的 SourceReaderBase 类,其使用 SplitReader 并创建提取器(fetcher)线程来运行 SplitReader,该实现支持不同的线程处理模型。
1、SplitReader
SplitReader API 只有以下三个方法:
- 阻塞式的提取 fetch() 方法,返回值为 RecordsWithSplitIds 。
- 非阻塞式处理分片变动 handleSplitsChanges() 方法。
- 非阻塞式的唤醒 wakeUp() 方法,用于唤醒阻塞中的提取操作。
SplitReader 仅需要关注从外部系统读取记录,因此比 SourceReader 简单得多。
2、SourceReaderBase
常见的 SourceReader 实现方式如下:
- 有一个线程池以阻塞的方式从外部系统提取分片。
- 解决内部提取线程与其他方法调用(如 pollNext(ReaderOutput))之间的同步。
- 维护每个分片的水印(watermark)以保证水印对齐。
- 维护每个分片的状态以进行 Checkpoint。
为了减少开发新的 SourceReader 所需的工作,Flink 提供了 SourceReaderBase 类作为 SourceReader 的基本实现。 SourceReaderBase 已经实现了上述需求。要重新编写新的 SourceReader,只需要让 SourceReader 继承 SourceReaderBase,而后完善一些方法并实现 SplitReader 。
3、SplitFetcherManager
SourceReaderBase 支持几个开箱即用(out-of-the-box)的线程模型,取决于 SplitFetcherManager 的行为模式。 SplitFetcherManager 创建和维护一个分片提取器(SplitFetchers)池,同时每个分片提取器使用一个 SplitReader 进行提取。它还决定如何分配分片给分片提取器。
例如,如下所示,一个 SplitFetcherManager 可能有固定数量的线程,每个线程对分配给 SourceReader 的一些分片进行抓取。
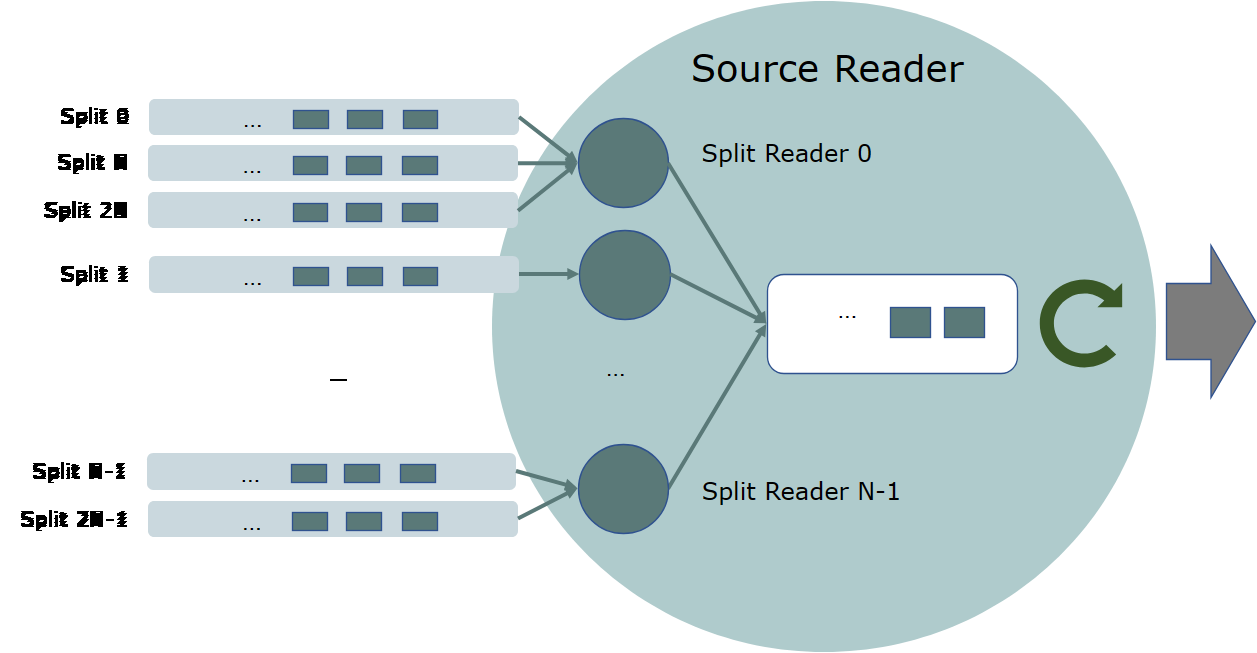
以下代码片段实现了此线程模型。
/**
* 一个SplitFetcherManager,它具有固定数量的分片提取器,
* 并根据分片ID的哈希值将分片分配给分片提取器。
*/
public class FixedSizeSplitFetcherManager<E, SplitT extends SourceSplit>
extends SplitFetcherManager<E, SplitT> {
private final int numFetchers;
public FixedSizeSplitFetcherManager(
int numFetchers,
FutureCompletingBlockingQueue<RecordsWithSplitIds<E>> elementsQueue,
Supplier<SplitReader<E, SplitT>> splitReaderSupplier) {
super(elementsQueue, splitReaderSupplier);
this.numFetchers = numFetchers;
// 创建 numFetchers 个分片提取器.
for (int i = 0; i < numFetchers; i++) {
startFetcher(createSplitFetcher());
}
}
@Override
public void addSplits(List<SplitT> splitsToAdd) {
// 根据它们所属的提取器将分片聚集在一起。
Map<Integer, List<SplitT>> splitsByFetcherIndex = new HashMap<>();
splitsToAdd.forEach(split -> {
int ownerFetcherIndex = split.hashCode() % numFetchers;
splitsByFetcherIndex
.computeIfAbsent(ownerFetcherIndex, s -> new ArrayList<>())
.add(split);
});
// 将分片分配给它们所属的提取器。
splitsByFetcherIndex.forEach((fetcherIndex, splitsForFetcher) -> {
fetchers.get(fetcherIndex).addSplits(splitsForFetcher);
});
}
}
使用这种线程模型的SourceReader可以像下面这样创建:
public class FixedFetcherSizeSourceReader<E, T, SplitT extends SourceSplit, SplitStateT>
extends SourceReaderBase<E, T, SplitT, SplitStateT> {
public FixedFetcherSizeSourceReader(
FutureCompletingBlockingQueue<RecordsWithSplitIds<E>> elementsQueue,
Supplier<SplitReader<E, SplitT>> splitFetcherSupplier,
RecordEmitter<E, T, SplitStateT> recordEmitter,
Configuration config,
SourceReaderContext context) {
super(
elementsQueue,
new FixedSizeSplitFetcherManager<>(
config.getInteger(SourceConfig.NUM_FETCHERS),
elementsQueue,
splitFetcherSupplier),
recordEmitter,
config,
context);
}
@Override
protected void onSplitFinished(Map<String, SplitStateT> finishedSplitIds) {
// 在回调过程中对完成的分片进行处理。
}
@Override
protected SplitStateT initializedState(SplitT split) {
...
}
@Override
protected SplitT toSplitType(String splitId, SplitStateT splitState) {
...
}
}
SourceReader 的实现还可以在 SplitFetcherManager 和 SourceReaderBase 的基础上编写自己的线程模型。
四、事件时间和水印
Source 的实现需要完成一部分事件时间分配和水印生成的工作。离开 SourceReader 的事件流需要具有事件时间戳,并且(在流执行期间)包含水印。
旧版 SourceFunction 的应用通常在之后的单独的一步中通过 stream.assignTimestampsAndWatermarks(WatermarkStrategy) 生成时间戳和水印。这个函数不应该与新的 Sources 一起使用,因为此时时间戳应该已经被分配了,而且该函数会覆盖掉之前的分片(split-aware)水印。
1、API
在 DataStream API 创建期间, WatermarkStrategy 会被传递给 Source,并同时创建 TimestampAssigner 和 WatermarkGenerator 。
environment.fromSource(
Source<OUT, ?, ?> source,
WatermarkStrategy<OUT> timestampsAndWatermarks,
String sourceName);
TimestampAssigner 和 WatermarkGenerator 作为 ReaderOutput(或 SourceOutput)的一部分透明地运行,因此 Source 实现者不必实现任何时间戳提取和水印生成的代码。
2、事件时间戳
事件时间戳的分配分为以下两步:
-
SourceReader 通过调用 SourceOutput.collect(event, timestamp) 将 Source 记录的时间戳添加到事件中。 该实现只能用于含有记录并且拥有时间戳特性的数据源,例如 Kafka、Kinesis、Pulsar 或 Pravega。 因此,记录中不带有时间戳特性的数据源(如文件)也就无法实现这一步了。 此步骤是 Source 连接器实现的一部分,不由使用 Source 的应用程序进行参数化设定。
-
由应用程序配置的 TimestampAssigner 分配最终的时间戳。 TimestampAssigner 会查看原始的 Source 记录的时间戳和事件。分配器可以直接使用 Source 记录的时间戳或者访问事件的某个字段获得最终的事件时间戳。
这种分两步的方法使用户既可以引用 Source 系统中的时间戳,也可以引用事件数据中的时间戳作为事件时间戳。
注意: 当使用没有 Source 记录的时间戳的数据源(如文件)并选择 Source 记录的时间戳作为最终的事件时间戳时,默认的事件时间戳等于 LONG_MIN (=-9,223,372,036,854,775,808)。
3、水印生成
水印生成器仅在流执行期间会被激活。批处理执行则会停用水印生成器,则下文所述的所有相关操作实际上都变为无操作。
数据 Source API 支持每个分片单独运行水印生成器。这使得 Flink 可以分别观察每个分片的事件时间进度,这对于正确处理事件时间偏差和防止空闲分区阻碍整个应用程序的事件时间进度来说是很重要的。
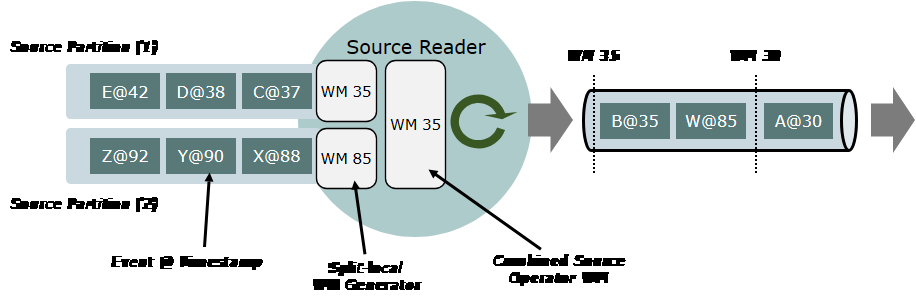
使用 SplitReader API 实现源连接器时,将自动进行处理。所有基于 SplitReader API 的实现都具有开箱即用(out-of-the-box)的分片水印。
为了保证更底层的 SourceReader API 可以使用每个分片的水印生成,必须将不同分片的事件输送到不同的输出(outputs)中:局部分片(Split-local) SourceOutputs。通过 createOutputForSplit(splitId) 和 releaseOutputForSplit(splitId) 方法,可以在总 ReaderOutput 上创建并发布局部分片输出。有关详细信息,请参阅该类和方法的 Java 文档。
4、Split Level Watermark Alignment
尽管source operator watermark alignment由Flink运行时处理,但source 需要额外实现SourceReader#pauseOrResumeSplits和SplitReader#pouseOrResueSplits,以实现split level watermark alignment。当有多个splits 分配给source reader时,Split level watermark alignment非常有用。
默认情况下,当分配了多个split ,并且分割超过WatermarkStrategy配置的watermark alignment阈值时,这些实现将抛出UnsupportedOperationException,pipeline.watermark-alignment.allow-unaligned-source-splits设置为false。SourceReaderBase包含SourceReader#pauseOrResumeSplits的实现,因此继承源只需要实现SplitReader#pouseOrResueSplits。
五、DataStream Connectors
1、预定义的 Source 和 Sink
一些比较基本的 Source 和 Sink 已经内置在 Flink 里。
预定义 data sources 支持从文件、目录、socket,以及 collections 和 iterators 中读取数据。
预定义 data sinks 支持把数据写入文件、标准输出(stdout)、标准错误输出(stderr)和 socket。
2、附带的连接器
连接器可以和多种多样的第三方系统进行交互。目前支持以下系统:
- Apache Kafka (source/sink)
- Apache Cassandra (sink)
- Amazon DynamoDB (sink)
- Amazon Kinesis Data Streams (source/sink)
- Amazon Kinesis Data Firehose (sink)
- DataGen (source)
- Elasticsearch (sink)
- Opensearch (sink)
- FileSystem (sink)
- RabbitMQ (source/sink)
- Google PubSub (source/sink)
- Hybrid Source (source)
- Apache Pulsar (source)
- JDBC (sink)
- MongoDB (source/sink)
在使用一种连接器时,通常需要额外的第三方组件,比如:数据存储服务器或者消息队列。
要注意这些列举的连接器是 Flink 工程的一部分,包含在发布的源码中,但是不包含在二进制发行版中。
3、Apache Bahir 中的连接器
Flink 还有些一些额外的连接器通过 Apache Bahir 发布, 包括:
- Apache ActiveMQ (source/sink)
- Apache Flume (sink)
- Redis (sink)
- Akka (sink)
- Netty (source)
4、连接Flink的其他方法
1)、异步 I/O
使用connector并不是唯一可以使数据进入或者流出Flink的方式。 一种常见的模式是从外部数据库或者 Web 服务查询数据得到初始数据流,然后通过 Map 或者 FlatMap 对初始数据流进行丰富和增强。 Flink 提供了异步 I/O API 来让这个过程更加简单、高效和稳定。
2)、可查询状态
当 Flink 应用程序需要向外部存储推送大量数据时会导致 I/O 瓶颈问题出现。在这种场景下,如果对数据的读操作远少于写操作,那么让外部应用从 Flink 拉取所需的数据会是一种更好的方式。 可查询状态 接口可以实现这个功能,该接口允许被 Flink 托管的状态可以被按需查询。
以上,本文简单的介绍了datasource的工作原理、api以及datastream connector的类型等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第二节-数据封装+传输介质
- Windows下使用C++操作SQLite
- 「Verilog学习笔记」加减计数器
- 解决:AttributeError: module ‘scipy.misc’ has no attribute ‘imread’
- 二叉树基础oj练习(对称二叉树、翻转二叉树、另一棵树的子树二叉树的构建及遍历)
- Golang 切片
- JAVA并发编程入门之-闭锁、信号量、栅栏
- java并发编程十三 线程池
- 如何系统性学习机器视觉中的光学知识
- 顺序表(C/C++)