学习AIGC大模型必知的强化学习RL的核心代码示例,速进!!!
在人工智能的发展历程中,强化学习(RL)已成为推动技术突破的关键动力,尤其在自动化内容生成(AIGC)和大型语言模型(LLM)的领域中。但是,什么使得强化学习在这些先进模型中发挥了如此关键的作用呢?
其关键在于,强化学习通过与环境的互动学习策略,它可以不依赖大量标记数据,使智能体能够在实验和错误中找到最优路径。在大型语言模型如GPT和BERT背后,强化学习不仅仅是优化策略的工具,它在序列决策和奖励信号的处理方面发挥了至关重要的作用。
接下来的内容我们将深入介绍强化学习的核心算法,并通过具体的应用的实例,揭示强化学习如何提高智能系统的适应性和精确度。
在AI大模型训练中,RL通过理解用户反馈和互动,为内容推荐提供了个性化的精确度。

多年来,研究人员提出了各种强化学习算法,其中主要算法包括:
1. 价值迭代 (Value Iteration)
价值迭代是一种基于动态规划的方法,用于解决马尔可夫决策过程(MDP)。在每一轮迭代中,它更新状态的价值函数,直至收敛到最优价值函数。
示例:假设在一个简单的迷宫游戏中,智能体的目标是找到从起点到终点的最短路径。价值迭代会为每个格子分配一个值,代表到达该格子后,达到目标的期望奖励。通过迭代更新这些值,智能体能够学习到每个格子的最优价值,并据此决策每一步的走向。
2. Q-learning
Q-learning是一种无模型、基于价值的强化学习算法,通过迭代更新其基于观察到的过渡和奖励的估计值来学习最佳的Q-function
举个例子:在一个贪吃蛇游戏中,Q-learning可以被用来训练一条蛇自动寻找食物。算法会维护一个Q-table来记录每个状态-动作对的价值。在每次移动时,智能体会根据Q-table选择最优的动作,并根据结果更新Q-table,逐渐学习到最优策略。
核心代码示例
import numpy as np
# 初始化Q-table
Q = np.zeros([state_space_size, action_space_size])
# 设置超参数
alpha = 0.1 # 学习率
gamma = 0.6 # 折扣因子
epsilon = 0.1 # 探索率
for episode in range(total_episodes):
state = env.reset()
for step in range(max_steps):
if np.random.uniform(0, 1) < epsilon:
# 探索:随机选择动作
action = env.action_space.sample()
else:
# 利用:选择当前状态下Q值最高的动作
action = np.argmax(Q[state,:])
new_state, reward, done, info = env.step(action)
# Q-table更新规则
Q[state, action] = Q[state, action] + alpha * (reward + gamma * np.max(Q[new_state, :]) - Q[state, action])
state = new_state
if done:
break
3. SARSA
SARSA(State-Action-Reward-State-Action)是一种无模型的策略性算法,与Q-learning类似,但它是在一个完全基于策略的框架内进行更新的。
假设在跳棋游戏中,智能体在每一步根据当前策略选择动作,并在执行动作后观察到新状态和奖励。然后智能体再次根据当前策略选择下一个动作,并使用这些信息来更新其Q值。
4. 深度Q网络 (DQN)
深度Q网络(DQN)将Q-learning与深度学习结合起来,使用深度神经网络来近似Q-function,特别适用于处理高维状态空间的问题。
比如在玩《超级马里奥》游戏时,状态空间非常大,可能的屏幕图像组合几乎是无限的。DQN通过使用卷积神经网络来处理这些图像,并输出每个可能动作的价值,使得智能体能够在这种复杂环境中做出决策。
6. 策略梯度算法 (Policy Gradient Methods)
策略梯度方法直接在策略空间上进行搜索,通过梯度上升(或下降)来优化策略,从而最大化累积奖励。
举个例子:在一个股票交易模拟器中,智能体需要决定何时买入或卖出。通过使用策略梯度方法,智能体可以学习一个策略,该策略直接预测在当前市场条件下执行每种交易动作的概率,并根据实际收益不断优化这个策略。
核心代码示例
import tensorflow as tf
# 策略网络模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(observation_space,)),
tf.keras.layers.Dense(action_space, activation='softmax')
])
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-2)
huber_loss = tf.keras.losses.Huber()
action_probs_history = []
critic_value_history = []
rewards_history = []
running_reward = 0
episode_count = 0
while True: # 运行循环直到解决问题
state = env.reset()
episode_reward = 0
with tf.GradientTape() as tape:
for timestep in range(1, max_steps_per_episode):
# 获取当前策略对应于当前状态的行动概率
action_probs = model(state)
action = np.random.choice(num_actions, p=np.squeeze(action_probs))
action_probs_history.append(tf.math.log(action_probs[0, action]))
# 应用选定的动作到环境中,观察下一状态和奖励
state, reward, done, _ = env.step(action)
rewards_history.append(reward)
episode_reward += reward
if done:
break
# 计算每一步的期望回报
returns = []
discounted_sum = 0
for r in rewards_history[::-1]:
discounted_sum = r + gamma * discounted_sum
returns.insert(0, discounted_sum)
# 计算损失
history = zip(action_probs_history, returns)
actor_losses = []
for log_prob, ret in history:
actor_losses.append(-log_prob * ret) # actor loss
actor_loss_value = sum(actor_losses)
# 反向传播更新策略网络
grads = tape.gradient(actor_loss_value, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# 清空历史
action_probs_history.clear()
rewards_history.clear()
episode_count += 1
if episode_count % 10 == 0:
print(f'Episode {episode_count}: reward = {episode_reward}')
6. 演员评判方法 (Actor-Critic Methods)
演员-评判方法将策略梯度方法与价值函数的优势结合起来,使用两个模型:一个是策略模型(演员),另一个是价值函数模型(评判者)。
示例:在一个复杂的机器人导航任务中,演员模型负责生成导航动作,评判者模型则评估这些动作。两个模型协同工作,演员根据评判者的评估不断调整策略,评判者则基于演员的表现不断更新价值判断。
7. 近端策略优化 (PPO)
近端策略优化(Proximal Policy Optimization, PPO)是一种策略梯度方法,它通过使用一种特殊的目标函数来解决策略更新过快导致的训练不稳定问题。
示例:在一个虚拟的环境中,一个机器人需要学习如何在多样化的地形上行走。PPO通过在每一步限制策略更新的幅度,确保学习过程的稳定性,同时鼓励探索,最终使机器人能够学会在不同地形上稳定行走。
下面是一个PPO的算法代码示例,使用TensorFlow和Keras实现。但是大家注意!这个代码块示例只是为了展示PPO的基本思想,没有办法独立运行,更多详情可以参考Github和Deeplearning.ai网站。
import tensorflow as tf
import numpy as np
# 假设一个环境,其中状态和动作的维度已经定义
state_dim = env.observation_space.shape
n_actions = env.action_space.n
# 构建演员网络(策略网络)
actor_model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=state_dim),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(n_actions, activation='softmax')
])
# 构建评判者网络(价值网络)
critic_model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=state_dim),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
# 优化器
optimizer = tf.keras.optimizers.Adam(lr=0.001)
# PPO 参数
eps_clip = 0.2
gamma = 0.99
# 训练循环
for update in range(n_updates):
# 收集数据
states, actions, rewards, dones, next_states = env.collect_data()
# 计算折扣回报和优势
discounted_rewards = compute_discounted_rewards(rewards, gamma)
values = critic_model.predict(states)
advantages = discounted_rewards - values
# 更新演员网络
with tf.GradientTape() as tape:
probs = actor_model(states)
old_probs = tf.stop_gradient(probs)
action_masks = tf.one_hot(actions, n_actions)
selected_action_probs = tf.reduce_sum(action_masks * probs, axis=1)
old_selected_action_probs = tf.reduce_sum(action_masks * old_probs, axis=1)
ratio = selected_action_probs / old_selected_action_probs
surr1 = ratio * advantages
surr2 = tf.clip_by_value(ratio, 1 - eps_clip, 1 + eps_clip) * advantages
actor_loss = -tf.reduce_mean(tf.minimum(surr1, surr2))
actor_grads = tape.gradient(actor_loss, actor_model.trainable_variables)
optimizer.apply_gradients(zip(actor_grads, actor_model.trainable_variables))
# 更新评判者网络
with tf.GradientTape() as tape:
values = critic_model(states)
critic_loss = tf.reduce_mean((discounted_rewards - values) ** 2)
critic_grads = tape.gradient(critic_loss, critic_model.trainable_variables)
optimizer.apply_gradients(zip(critic_grads, critic_model.trainable_variables))
在这个代码中:
- 演员网络输出动作概率,用于指导智能体的动作选择。
- 评判者网络输出状态价值,用于计算优势函数。
- 优化器用于更新网络权重。
- eps_clip是PPO算法中的超参数,用于限制策略更新的幅度,防止更新过快。
- gamma是未来奖励的折扣因子
该代码片段是PPO的核心,实际使用时还需要定义环境、计算折扣回报的函数compute_discounted_rewards等。此外,为了提高算法的性能和稳定性,实践中可能还需要添加更多的特性,如梯度裁剪、熵正则化等。
想要了解更多RL核心算法的相关内容,以及训练你的专属AI大模型,我们近屿智能OJAC推出的《AIGC星辰大海:大模型工程师和产品专家深度训练营》就是学习这部分知识的最好选择。我们的课程是一场结合了线上与线下的双轨合流式学习体验。
别人教您使用AIGC产品,例如ChatGPT和MidJourney,我们教您增量预训练,精调大模型,和创造属于自己的AI产品!
您是否想利用AIGC为您打破职业与薪资的天花板?您是否想成为那个在行业里脱颖而出的AI专家?我们的培训计划,将是您实现这些梦想的起点。
让我带您了解一下近屿智能OJAC如何帮您开启AI的大门。
首先,为了让零基础的您也能轻松上手,我们特别设计了“Python强化双周学”这个先修课程。在两周的时间里,我们将通过在线强化学习,把大模型相关的Python编程技术娓娓道来。就算您现在对编程一窍不通,也不要担心,我们会带您一步步走进编程的世界。
然后,是我们的“AIGC星辰大海:大模型工程师与AIGC产品经理启航班”。这个课程包含6节精彩的直播课,不仅能让您深入了解ChatGPT等大模型的奥秘,还会带您领略至少20个来自全球的成功AIGC产品案例。想象一下,未来您同样有机会利用这些先进技术打造出热门AI产品!
更深层次的学习,则在“AIGC星辰大海:大模型工程师和产品专家深度训练营”中进行。这个深度训练营覆盖了从理论基础到实际操作的全过程,让您不仅学会理论,更能将知识应用到实际项目中。如果您想要深挖大模型的秘密?这里就是您的实验室!
如果您选择加入我们的OJAC标准会员,我们的"AI职场导航"项目,还将为您提供量身定制的职业机会,这些职位来自于我们广泛的行业网络,包括初创企业、中型企业以及全球知名公司。我们会根据您的技能、经验和职业发展愿景,为您筛选合适的机会。此外,我们也提供简历修改建议、面试准备指导和职业规划咨询,帮助您在竞争激烈的市场中脱颖而出。
同时您也可以享受到未来景观AI讲座暨每月技术洞见”系列讲座,获得最新的技术洞见。这不仅是一个学习的机会,更是一个与行业顶尖大咖直接交流的平台。
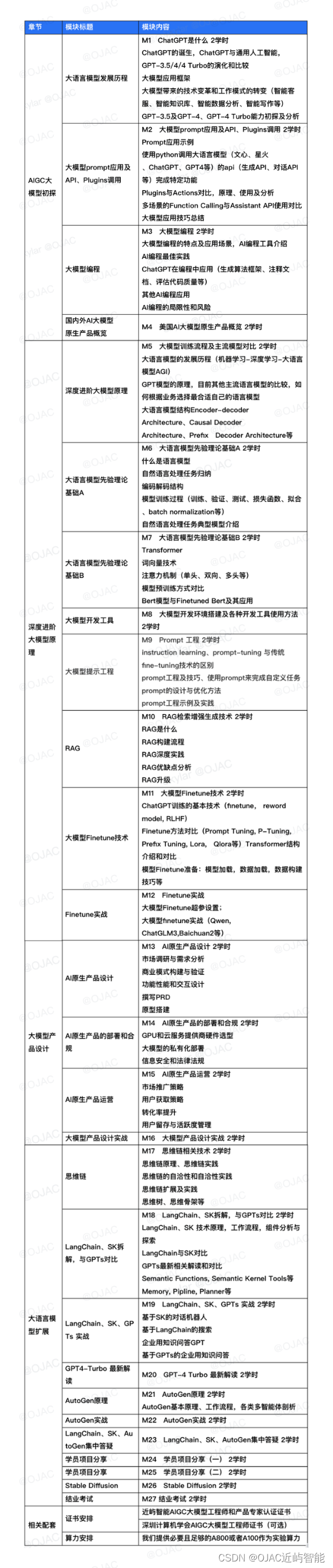
以下是我们大模型工程师和产品专家深度训练营的课程内容:
除此之外,现在报名我们即将开班的第六期AIGC星辰大海大模型工程师和产品经理训练营,您将可以参与到以下三个创新实战项目中的任意一个,这些项目不仅能够锻炼您的实战能力,还能让您在AIGC领域脱颖而出。
项目1:企业级知识问答GPT
这个项目将教您如何打造一个智能机器人,它能够接入企业内部的知识库,如技术文档、HR政策、销售指南等。您将学会如何使其具备强大的自然语言处理能力,进行复杂查询的理解和精确答案的提供。此外,该项目还包括教您如何让机器人保持对话上下文、支持多语言交流,并具备反馈学习机制,以不断提升服务质量。
项目2:行业级AI Agent
在这个项目中,您将学习如何为特定行业定制化AI Agent。您将被指导如何让它理解行业专有术语和工作流程,并训练它自动执行任务,如预约设置、数据输入和报告生成。这个项目不仅帮助您构建一个决策支持系统,还教您如何进行用户行为预测和性能监控与优化。
项目3:论文翻译
如果您对语言学习和学术研究有浓厚兴趣,这个项目将是您的理想选择。您将探索如何实现从英语到中文或其他目标语言的精准学术翻译,确保保留学术文献的深层含义。本项目还包括学术格式定制、专业词汇精确匹配以及广泛语言选项的训练,最后通过翻译效果评价系统,您将能够持续提升翻译质量。
无论您选择哪个项目,都将是您职业生涯中不可多得的实战经历。
我们诚邀您继续与我们携手前行。在未来的职业道路上,让我们共同探索AI的更多奥秘,共创辉煌。如果您还有任何疑问或者想要深入了解更多课程内容,请随时联系我们。我们期待着与您共同开启下一阶段的AI探索之旅。
加入我们的“AIGC星辰大海”训练营,让我们一起在AI的世界里创造不凡!立刻加入我们,开启您的AI大模型旅程,将梦想转变为现实。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- java 多线程面试
- 用于智驾车辆的相机-IMU外参监控
- 【unity】如何让Unity应用在退出时关闭某些服务
- SpringBoot原理(@Conditional)—三种自动配置方法、步骤详解
- 华为机试真题实战应用【赛题代码篇】-最多等和不相交连续子序列(附Java和C++代码)
- ipv6-ipv4隧道和bgp全网通小实验
- 消费者选择 | 收入效应和替代效应
- 测试不拘一格——掌握Pytest插件pytest-random-order
- UCB Data100:数据科学的原理和技巧:第十三章到第十五章
- C++11教程:C++11新特性大汇总(第六部分)